Driverless AI의 비지도(unsupervised) 알고리즘(실험적)¶
버전 1.10에서 Driverless AI는 비지도 모델 구축에 사용할 수 있는 비지도 트랜스포머를 노출하며 이는 다음과 같습니다.
개념적으로 비지도 실험의 전체 파이프라인은 몇 가지 주목할 만한 차이점을 제외하고 일반 지도 실험의 파이프라인과 유사합니다.
하나의 비지도 알고리즘(모델, 파이프라인)만 선택할 수 있습니다(예: 클러스터링 또는 이상 감지 중 하나, 둘 다는 아님). 다시 말해, 유전 알고리즘의 모든 개체는 동일한 모델 유형이지만 다른 매개변수(예: 클러스터 수, 클러스터링에 사용하는 열)를 가질 수 있습니다.
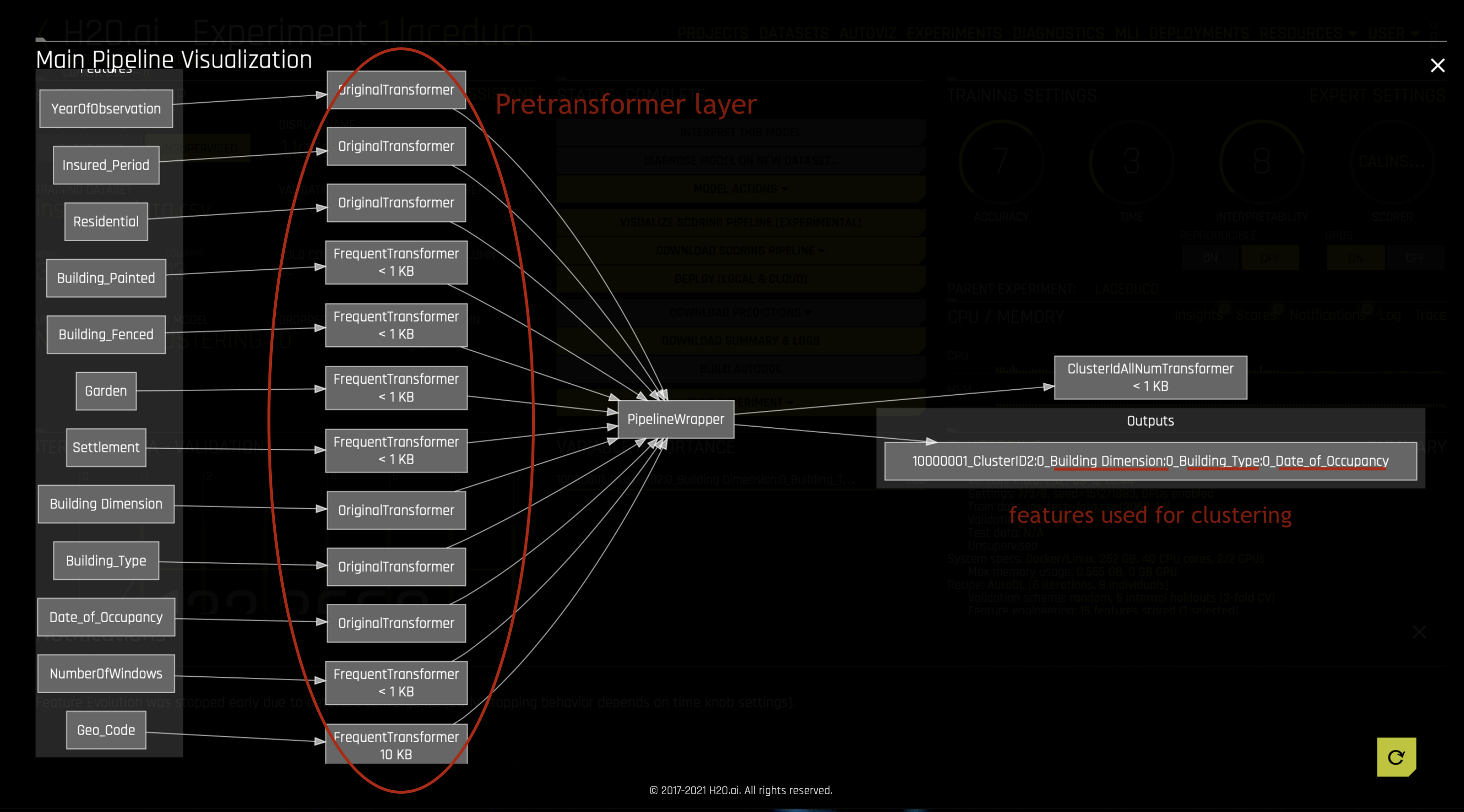
이러한 각각의 비지도 모델링 파이프라인은 정확히 하나의 사전 트랜스포머, 하나의 트랜스포머 및 하나의 모델로 구성됩니다. 레이블(y)은 필요하지 않습니다.
비지도 모델에는 포함된 사전 트랜스포머, 포함된 트랜스포머 및 적용 가능한 스코어러를 나열하는 하나의 기능만 있습니다. 모델 자체는 순수한 통과 함수이며, models.predict() 메서드는 트랜스포머 파이프라인(트랜스포머가 만드는 모든 기능)의 출력을 반환합니다. 이는 또한 모델의 변수의 중요성이 잘못 정의되고 기능 전반에 균일하게 퍼져 있음을 의미합니다. 클러스터링에는 하나의 기능(할당된 클러스터 레이블)만 있으며 변수의 중요성은 1.0입니다.
자동 머신 러닝은 score(X, actual=None, predicted=transformed_X) 를 통해 변환 품질을 평가하는 메트릭(스코어러)이 있는 경우에만 가능합니다. 예를 들어, K-평균 클러스터링 알고리즘에 의해 생성된 레이블의 품질은 주어진 데이터 세트, 주어진 레이블 및 메트릭에 대해 평가할 수 있습니다. 스코어러를 적용할 수 없는 경우 UNSUPERVISEDSCORER 를 사용하며 모든 입력에 대해 0을 반환합니다. 이 값은 무시할 수 있으며 첫 번째 반복 후에 Driverless AI에 실험이 수렴되었다는 신호를 보냅니다.
1.10.0에서는 MLI를 지원하지 않지만 향후 릴리스에서는 지원할 예정입니다.
비지도 실험 최종 모델에 대한 앙상블 및 교차 검증이 없습니다(
fixed_ensemble_level=0을 시행). 그 결과로서 학습 홀드아웃 예측을 생성할 수 없습니다(모든 데이터는 최종 모델에 사용됨). 학습 데이터에 대해 클러스터 할당과 같은 예측이 필요한 경우 fit() 및 predict()가 동일한 데이터로 수행되므로 과적합(AutoML 도중 과도한 튜닝으로 인함)의 일반적 경고 사항과 함께 학습 데이터에 대한 예측을 수행하십시오.
Isolation Forest 이상 감지¶
Isolation forest 는 의사 결정 트리를 무작위로 분할하여 이상 항목을 격리 또는 식별합니다. 아이디어는 outlier 가 특색 공간의 일반 관측치에서 더 멀리 떨어져 있으므로 트리의 터미널 노드로 격리하는 데 더 적은 무작위 분할이 필요하다는 것입니다. 알고리즘은 포리스트의 경로 길이(루트 노드에서 터미널 노드까지)를 기반으로 각 관찰에 이상 점수를 할당합니다. 점수가 낮으면 행이 이상일 가능성이 큽니다. 내부적으로 Driverless AI는 sklearn의 Isolation Forest 구현을 실행합니다.
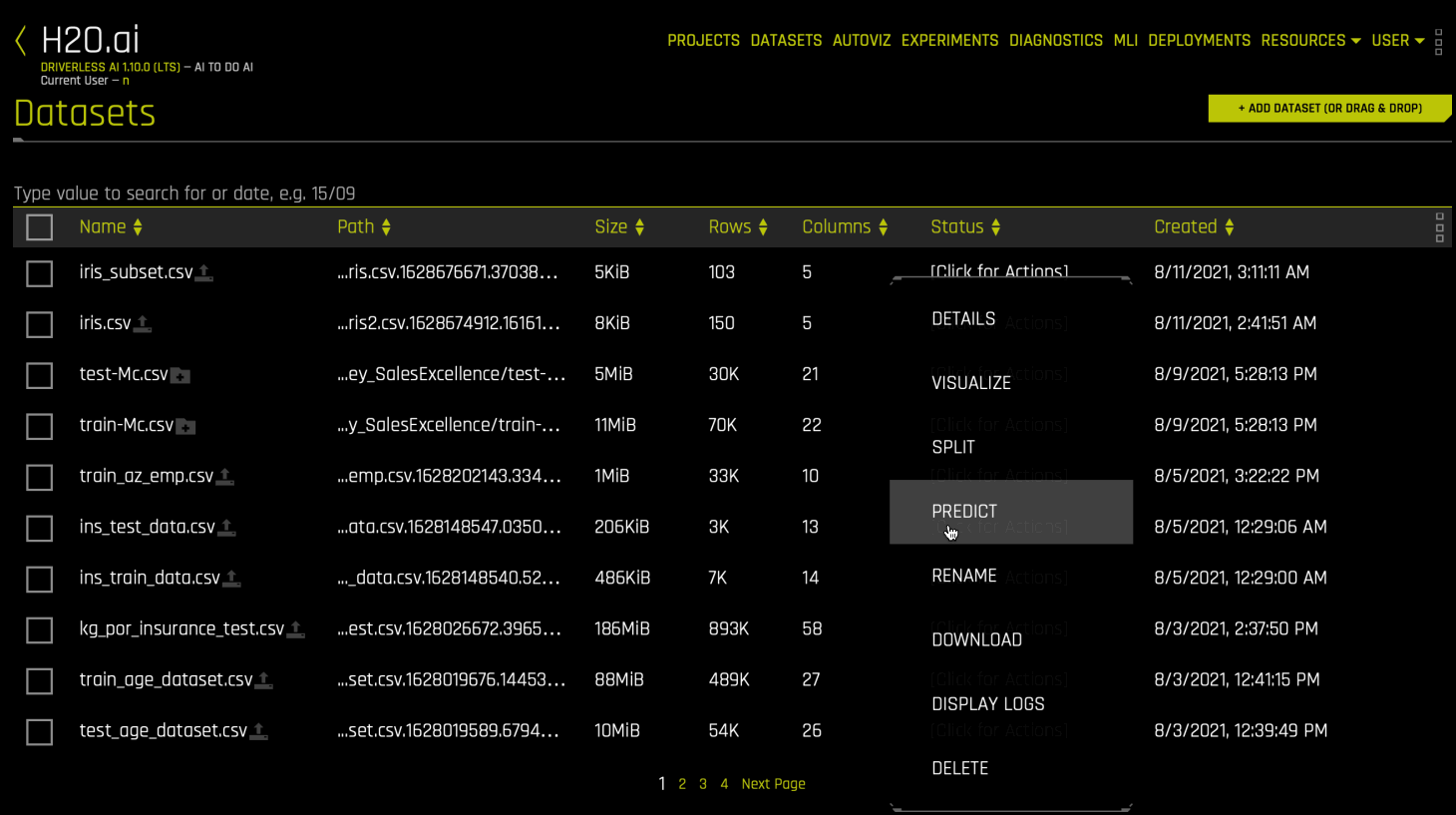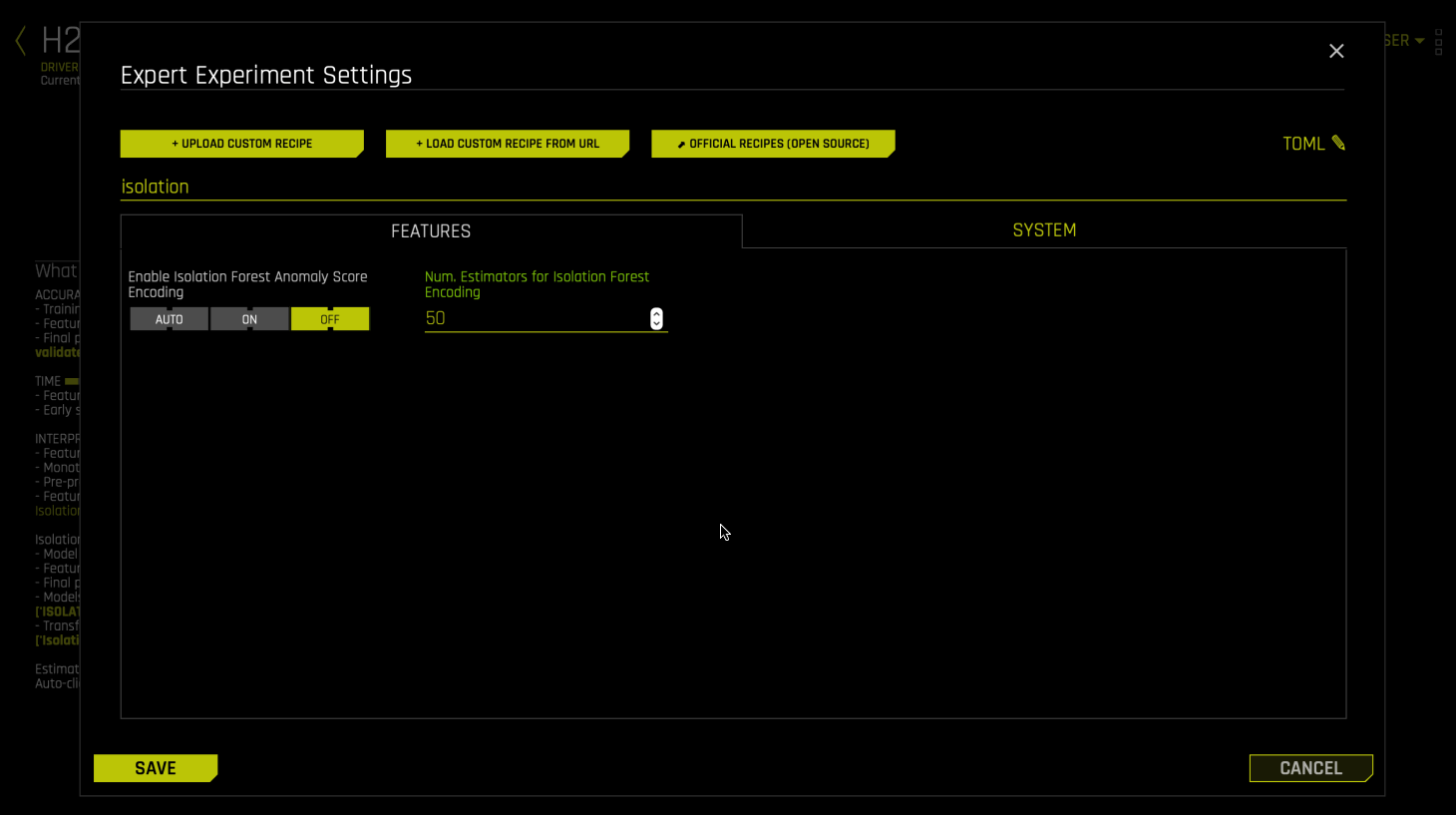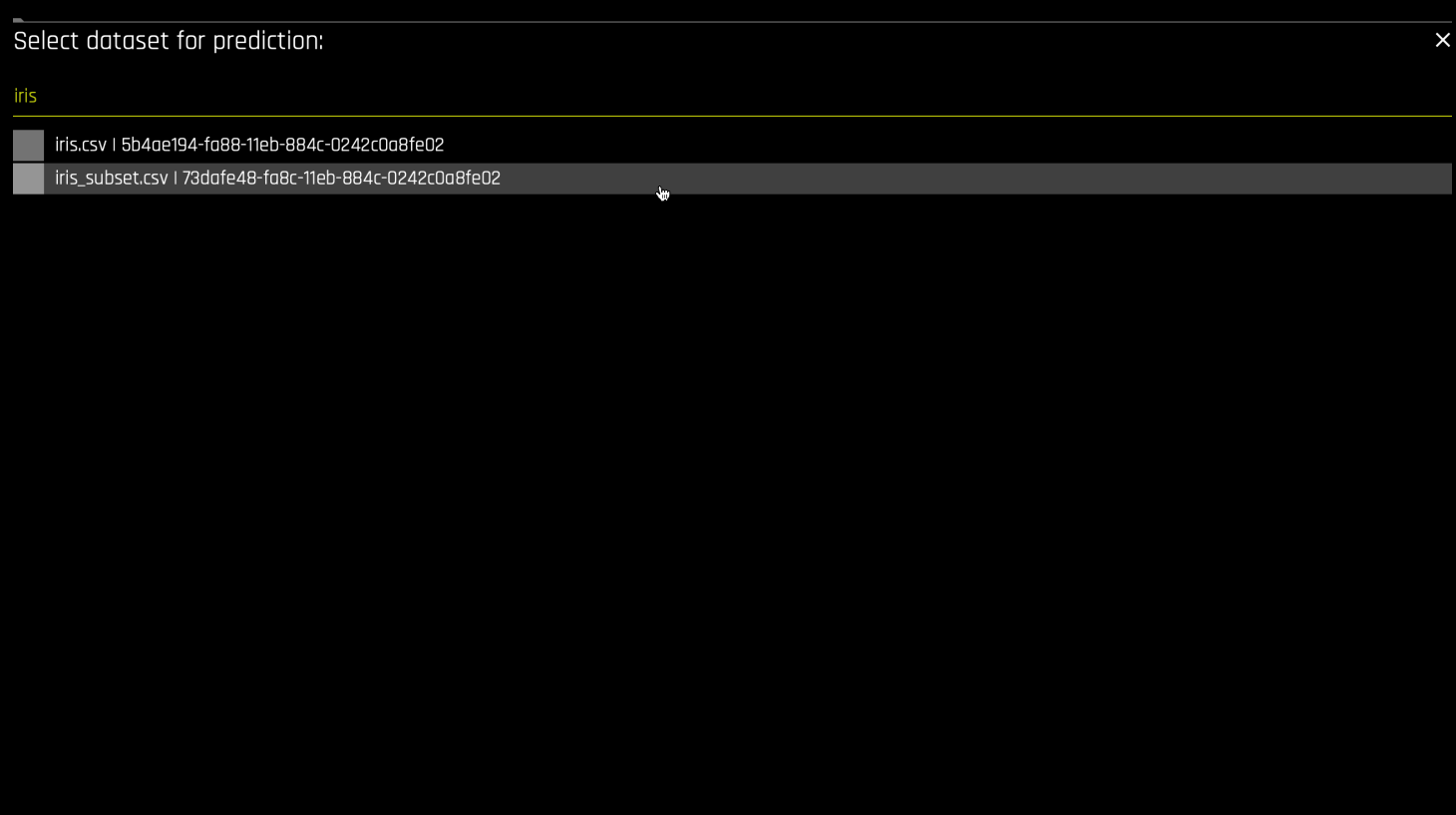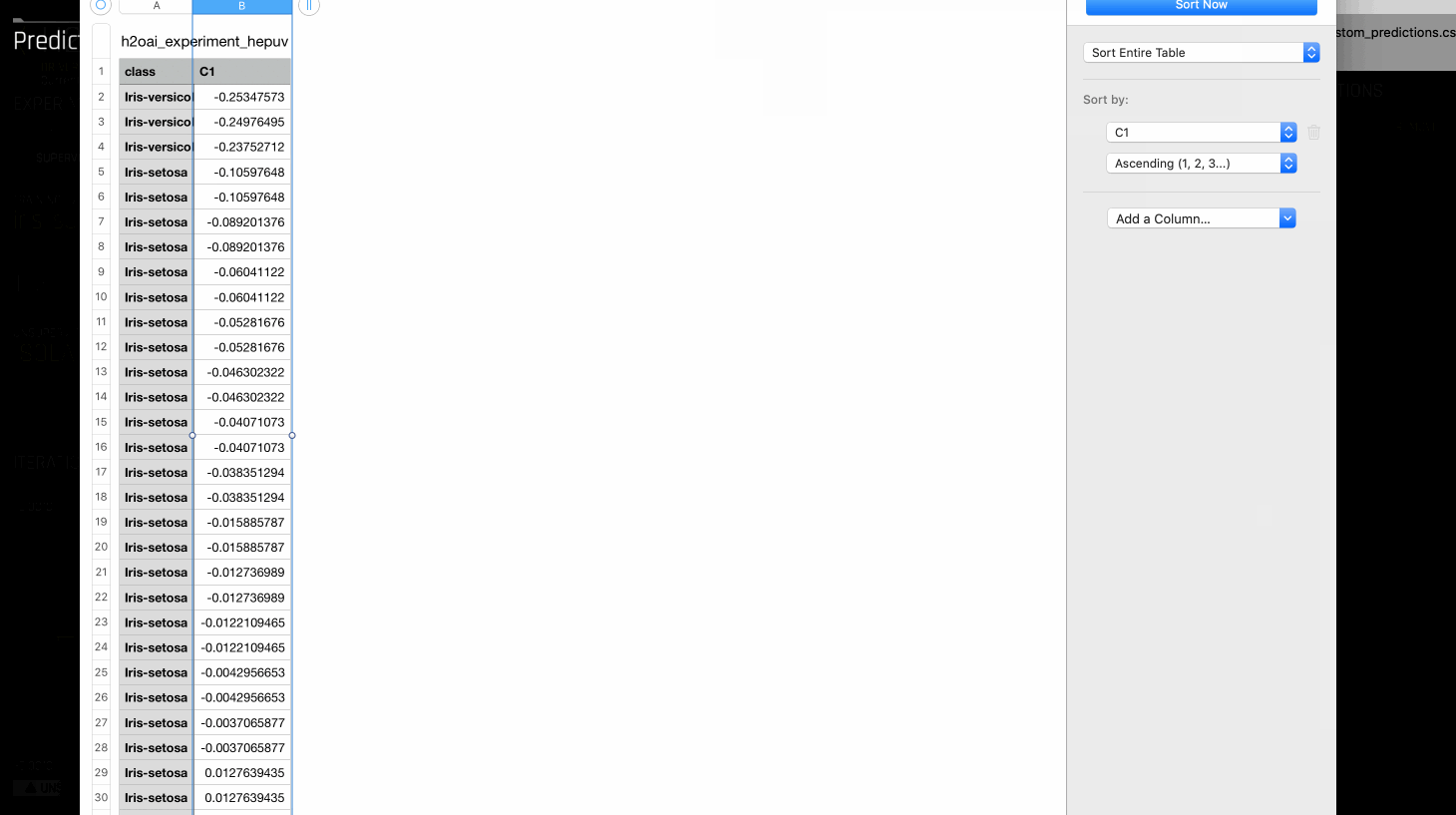
모델 구축 시 Driverless AI의 정확성 및 시간 노브를 토글하여 모델 튜닝에 소요하는 노력을 조정할 수 있지만 현재 Isolation Forest에 사용되는 스코어러가 없기 때문에 유전 알고리즘 을 수행할 때 모델은 즉시 수렴하고 튜닝 단계 의 모델 중 하나를 최종 모델로 사용합니다. 기본 설정에서는 해석력 노브를 무시합니다. Isolation Forest 모델에 대한 트리 또는 n_estimators의 수는 isolation_forest_nestimators 상세 설정 매개변수로 조정할 수 있습니다.
모델 구축 후 scores 는 동일한 데이터 세트에서 예측하여 얻을 수 있습니다. 행의 점수가 낮으면 모델에 의한 이상치 또는 이상일 가능성이 커집니다. Visualize Scoring Pipeline 옵션 은 모델 구축에 사용한 기능 및 적용된 변환을 요약합니다.
이 점수에서 labels 를 만드려면 분위수 값을 임계값으로 사용할 수 있습니다. 예를 들어 데이터 세트에서 행의 5%가 비정상이라는 것을 알고 있는 경우 이를 사용하여 점수의 95번째 분위수를 계산할 수 있습니다. 이 분위수는 각 행을 이상 여부로 분류하는 임계값 역할을 할 수 있습니다.
Python scoring pipeline 은 Isolation Forest 모델은 생산에 배포하는 데 사용할 수 있습니다(현재 MOJO 지원 없음).
사용 사례 개념: 이상 감지 실험이 주어지는 경우 모든 원래 열을 포함하여 학습 데이터 세트에 대한 예측을 생성하고 Driverless AI에 다시 업로드하여 지도 실험을 실행할 수 있습니다. 주어진 유사한 데이터 세트(생산 중)에는 이제 각 행의 이상 점수를 알려주는 비지도 스코어러와 Shapley가 기능별 기여 이유 코드를 작성하여 각 행의 이상 여부를 설명하는 지도 채점이 있습니다.
KMeans 클러스터링¶
클러스터링 알고리즘은 관측치를 클러스터로 분할합니다. Driverless AI는 sklearn KMeans 클러스터링 알고리즘을 사용하여 관측값을 분할하고 가장 가까운 평균(클러스터의 중심)이 있는 클러스터에 속하게 합니다.
Driverless AI는 숫자 및 범주형 열에서 실행하는 다음과 같은 비지도 models 를 노출하여 K-Means 클러스터링 모델을 구축합니다. 데이터 세트의 특성을 바탕으로 모델 유형을 선택하거나 모두(하나씩) 실행하여 데이터 세트에 가장 적합한 모델을 결정할 수 있습니다.
KMeans : 이는 숫자 열에서만 K-Means 클러스터링을 수행합니다.
KMeansFreq : 이는 숫자 및 주파수 변형 범주에 대한 K-Means 클러스터링을 수행합니다(정수 열은 숫자로만 처리됨)
KMeansOHE : 이는 숫자 및 원-핫(one-hot) 인코딩 변형 범주형 열에 대한 K-Means 클러스터링을 수행합니다.
Driverless는 다음 scorer 를 제공하여 자동 비지도 클러스터링을 활성화합니다.
CALINSKI HARABASZ : Calinski-Harabasz 지수는 분산 비율 기준이라고도 하며, 모든 클러스터에 대한 클러스터 간 분산(between-clusters dispersion) 및 클러스터 간 분산(inter-cluster dispersion)의 합계 비율입니다. 이 점수가 higher 할수록 성능이 좋습니다.
DAVIES BOULDIN : Davies-Bouldin Index는 클러스터 간 평균 〈유사성’을 나타내며, 유사성은 클러스터 간 거리를 클러스터 자체 크기와 비교하는 척도입니다. lower Davies-Bouldin 지수는 클러스터 간 분리가 더 나은 모델과 관련이 있습니다.
SILHOUETTE : 실루엣 계수는 각각의 샘플에 대해 정의되며 두 점수로 구성됩니다. 샘플과 동일한 클래스의 다른 모든 점 사이의 평균 거리입니다. 이 점수는 동일한 클러스터에 있는 포인트의 밀착도를 측정합니다. 그리고 샘플과 다음으로 가장 가까운 클러스터의 다른 모든 점 사이의 평균 거리입니다. 이 점수는 서로 다른 클러스터의 포인트 거리를 측정합니다. higher 실루엣 계수 점수는 더 잘 정의된 클러스터가 있는 모델과 관련됩니다. 이 스코어러는 더 큰 데이터 세트에서 느릴 수 있습니다. Ref
클러스터링 모델을 구축하는 동안 Accuracy 및 Time 노브를 전환하여 모델 튜닝 및 검증에 소요되는 노력을 조정할 수 있습니다. Interpretability 노브는 현재 지원하는 비지도 모델에 대해서는 즉시 무시되지만, 사용자 정의 레시피는 모델 구축 중 매개변수 뮤테이션을 제어하기 위해 해석 가능성 설정을 수신하도록 작성할 수 있습니다. 전문가 패널에서 unsupervised_clustering_min_clusters 및 unsupervised_clustering_max_clusters 매개변수를 사용하여 구축할 클러스터 수의 상한 및 하한을 설정할 수 있습니다.
모델 구축 중에 Driverless AI는 기능의 서브세트에 대해 KMeans 클러스터링 모델을 생성합니다 (2에서 5 사이). 기능 서브세트 크기, 클러스터링에 사용할 열 및 매개변수 튜닝은 genetic algorithm 프로세스 중에 결정됩니다. 사용자는 상세 설정의 fixed_interaction_depth 매개변수로 기능 서브세트 크기(클러스터에 대한 공간의 차원)를 설정할 수 있습니다. 값은 2에서 5 사이여야 합니다. Fixed_interaction_depth=4 인 경우 클러스터링을 4D로 수행합니다. 데이터 세트에 4개 이상의 기능이 있는 경우(또는 원-핫 인코딩과 같은 사전 변환을 고려한 후), 유전 알고리즘 수행 시 DAI는 입력 기능 및 모델 매개변수(내부 트레인/유효 분할 기반)를 선택하여 4가지 기능의 가능한 최고 서브세트와 매개변수를 결정하고 점수를 최적화하는 모델을 구축합니다.
Scorer 는 full dataset (모든 기능으로 사전 변환됨)와 (기능 서브세트) 클러스터링 모델로 생성한 행에 대한 labels 를 사용하여 점수를 부여합니다. 이는 비지도 트랜스포머의 출력을 입력과 비교합니다.
실험의 Insights 탭에서는 최고의 모델 구축을 위한 기능 서브세트에 대한 트랜스포머 클러스터링 작업을 보여줍니다. 이는 클러스터의 기능에 대한 클러스터 크기 및 중심을 나열합니다. 플롯은 클러스터 분리를 2차원으로 표시하고 색상 코드로 구분하여 쉽게 시각화합니다. 집계 알고리즘은 플롯의 데이터 크기를 줄이는 데 사용됩니다. 이것은 곧 DAI에 제공될 사용자 정의 시각화 기능(Vega 사용)의 미리보기입니다.
모델 구축 후 Visualize Scoring Pipeline option 을 사용하여 (기능의 서브세트에서) 모델을 구축하고 (전체 세트에서) 채점을 수행하기 전에 기능에 적용된 pre transformations 을 검사할 수 있습니다. 이는 클러스터링 모델을 구축하는 데 사용되는 기능을 검사하는 데에도 사용할 수 있습니다. 클러스터 labels 는 데이터 세트에 대한 예측을 수행하여 생성할 수 있습니다.
학습 (또는 모든) 데이터 세트에 대한 클러스터 레이블 할당을 얻으려면 모든 지도 모델과 마찬가지로 피팅된 모델을 사용하여 예측을 수행할 수 있습니다. 과적합은 동일한 데이터 세트에 대한 적합 및 예측 수행 시 언제든지 발생할 수 있습니다.
클러스터링 모델은 MOJOs 및 Python scoring pipelines 을 생성하여 production 에 배포합니다.
또한 고유한 사전 트랜스포머(즉, 클러스터링에 어떤 인코딩으로 어떤 열을 제공하는지 여부), 클러스터링 트랜스포머 및 스코어러를 정의하여 사용자 정의 클러스터링 레시피를 작성할 수 있습니다. 예제를 보려면 공식 Driverless AI 레시피 저장소에서 KMeans Clustering Using RAPIDS.ai recipe 를 참조하십시오. (최상의 결과를 얻으려면 Driverless AI 버전에 해당하는 릴리스 분기를 사용하십시오.)
Truncated SVD(차원 축소)¶
Truncated SVD 는 차원 축소 방법이며 데이터 세트에 적용하여 지도 알고리즘을 실행하기 전에 기능 수를 줄일 수 있습니다. 이는 열 수가 지정된 절단과 동일한 데이터 행렬을 인수분해합니다. sparse 데이터가 권장 시스템처럼 생성되거나 tfidf와 같은 텍스트 처리에서 생성되는 사용 사례에 유용합니다. 내부적으로 Driverless AI는 sklearn Truncated SVD 구현을 실행합니다.
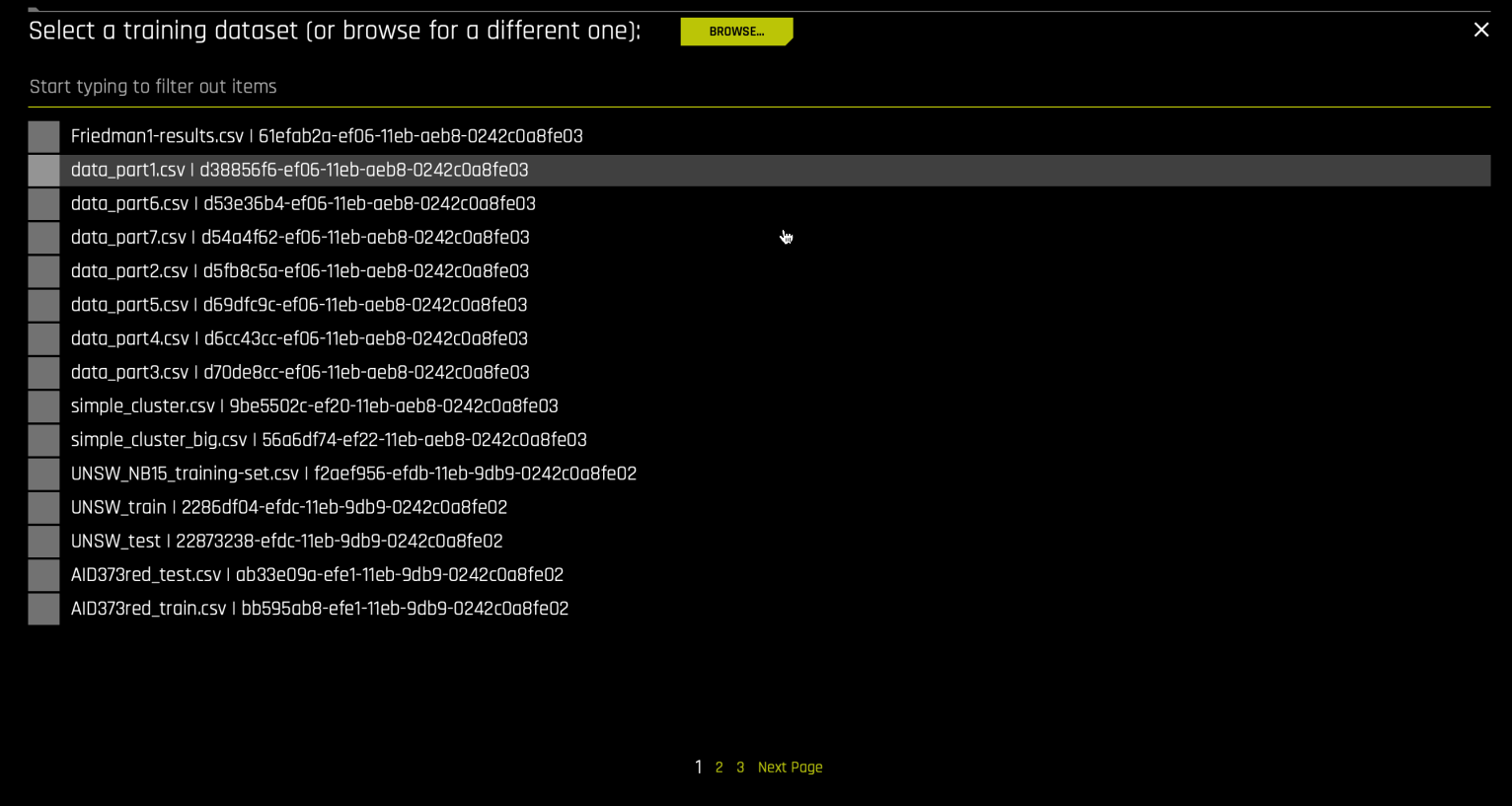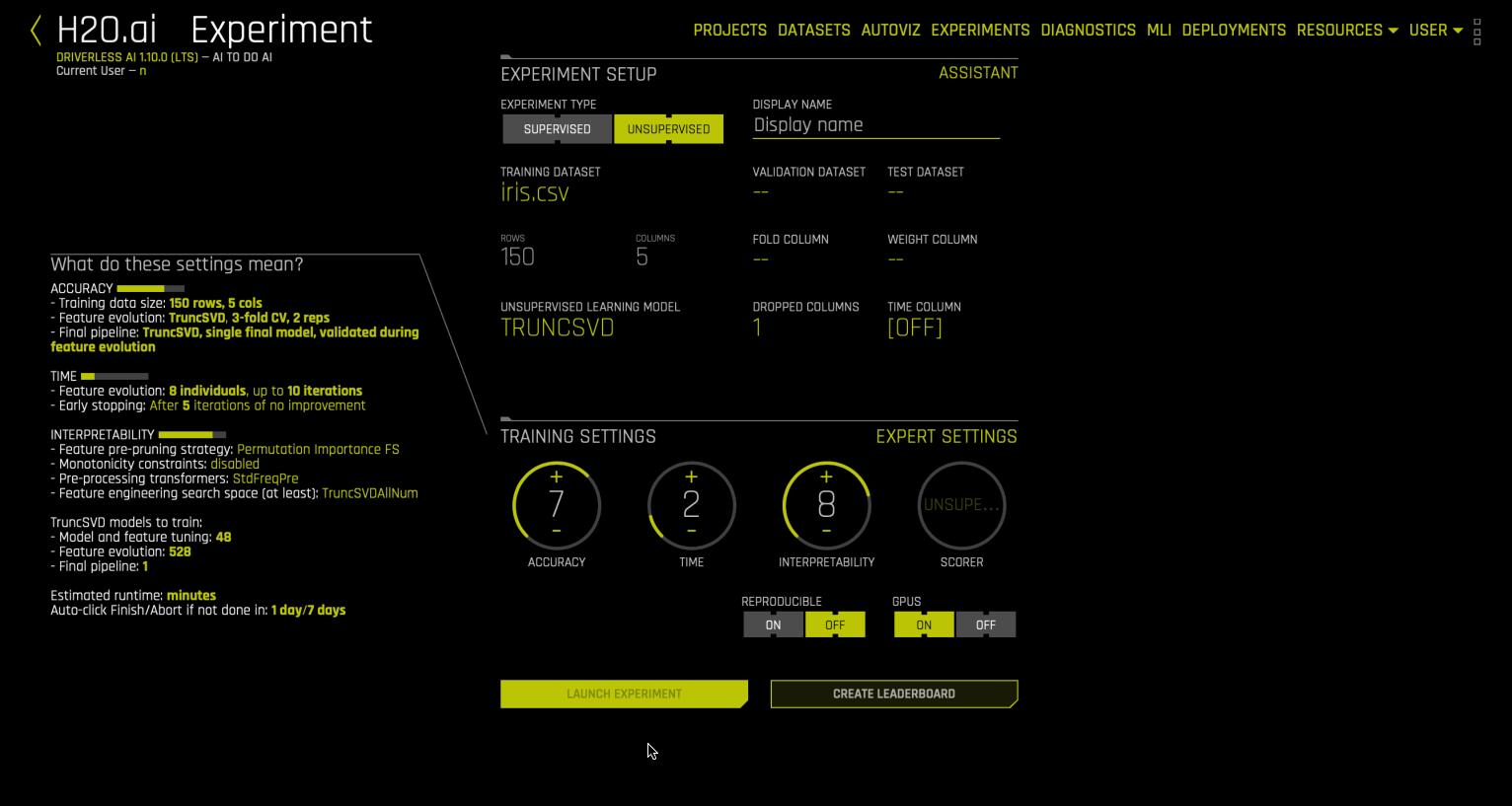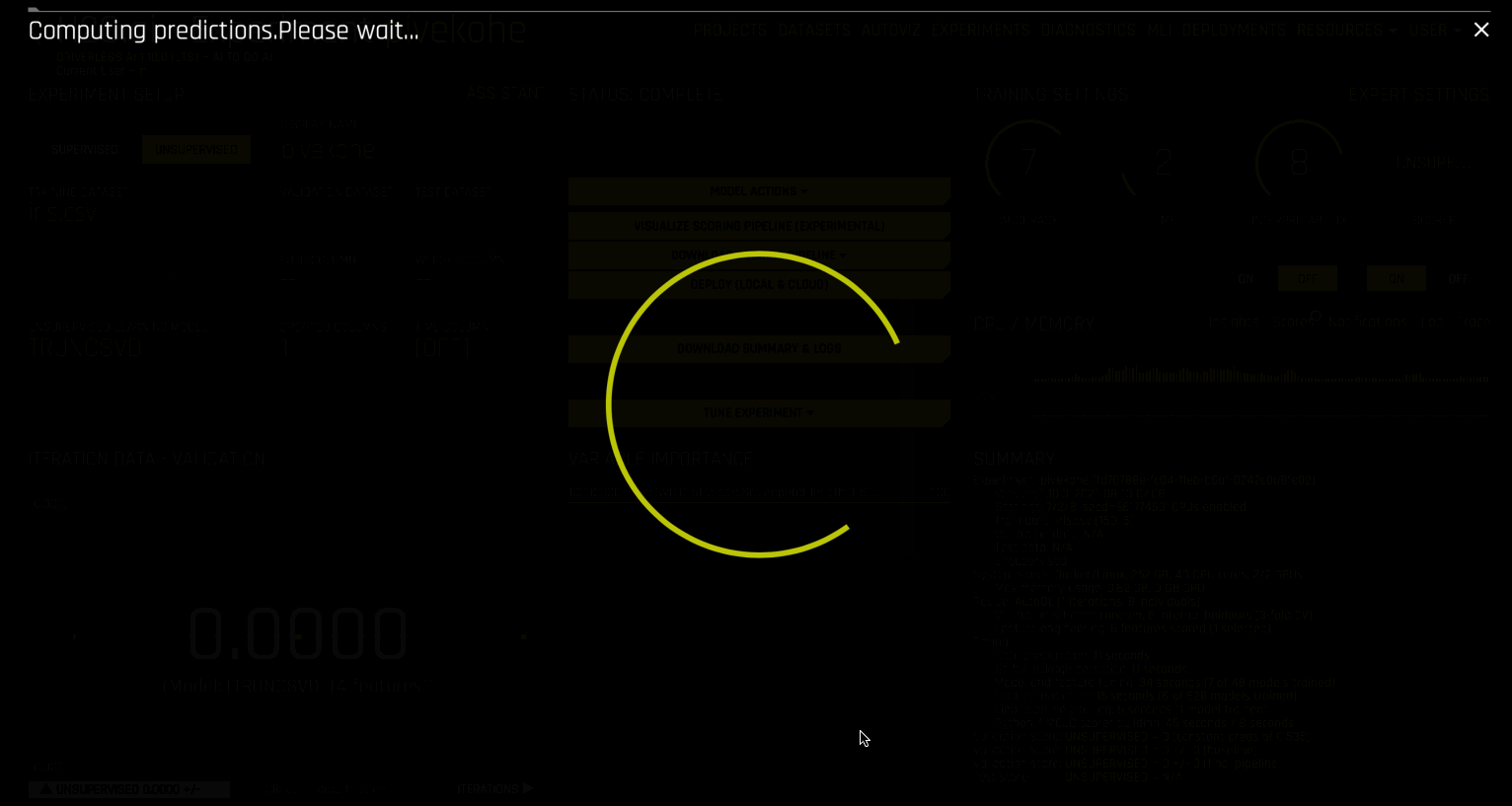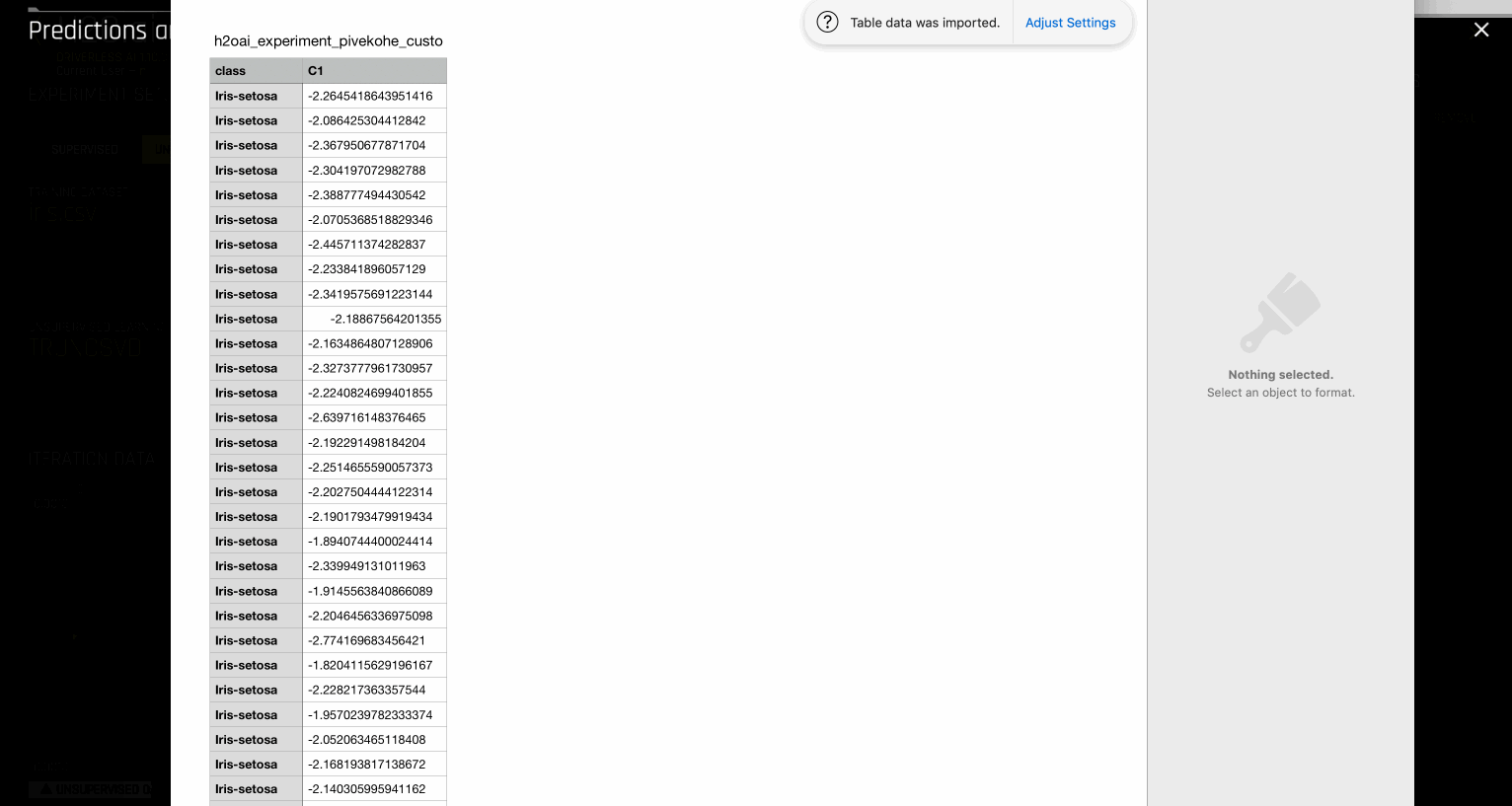
Driverless AI는 TRUNCSVD 트랜스포머를 노출하여 기능의 수를 줄입니다. 현재는 사용자가 어떤 매개변수도 토글할 수 없습니다. TRUNCSVD 트랜스포머에 의해 생성된 n_components는 1에서 5 사이의 범위를 갖습니다. (이는 임의 뮤테이션으로 간주됩니다.) 모델 구축 후 Visualizing scoring pipeline 를 사용하여 생성된 구성 요소 수를 검사할 수 있습니다. 또한 차원 축소 데이터 세트는 데이터 세트에 대한 예측을 통해 얻을 수 있습니다. 현재 SVD 실험에 사용되는 스코어러가 없으므로 genetic algorithm 수행 시 모델이 즉시 수렴하고 tuning phase 의 모델 중 하나를 최종 모델로 사용합니다.
차원 축소 모델은 MOJOs 및 Python 스코어링 파이프라인을 생성하여 production 에 배포합니다.
비지도 사용자 정의 레시피¶
Driverless AI는 비지도 학습을 위한 사용자 정의 Python 레시피 를 지원합니다. 고유한 사전 트랜스포머, 트랜스포머 및 스코어러를 정의하여 사용자 정의 비지도 레시피를 작성할 수 있습니다. 예시를 보려면 공식 Driverless AI 레시피 저장소 를 참조하십시오. (최고의 결과를 얻으려면 Driverless AI 버전에 해당하는 릴리스 분기를 사용하십시오.)