Driverless AI에서의 NLP¶
이 섹션에서는 Driverless AI의 NLP(텍스트) 처리 능력에 관해 설명합니다. Driverless AI 플랫폼은 예측 기능으로 기타 열 유형을 포함한 독립형 텍스트 및 텍스트를 모두 지원할 수 있습니다. Tensorflow 기반 및 PyTorch 트랜스포머 아키텍처(예: BERT)는 변수 가공 및 모델 구축에 사용됩니다.
자세한 내용은 다음을 참조하세요;
참고
Driverless의 NLP 및 이미지 사용 사례는 GPU usage 에서 상당한 이점을 얻습니다.
NLP 변수 가공 및 모델링¶
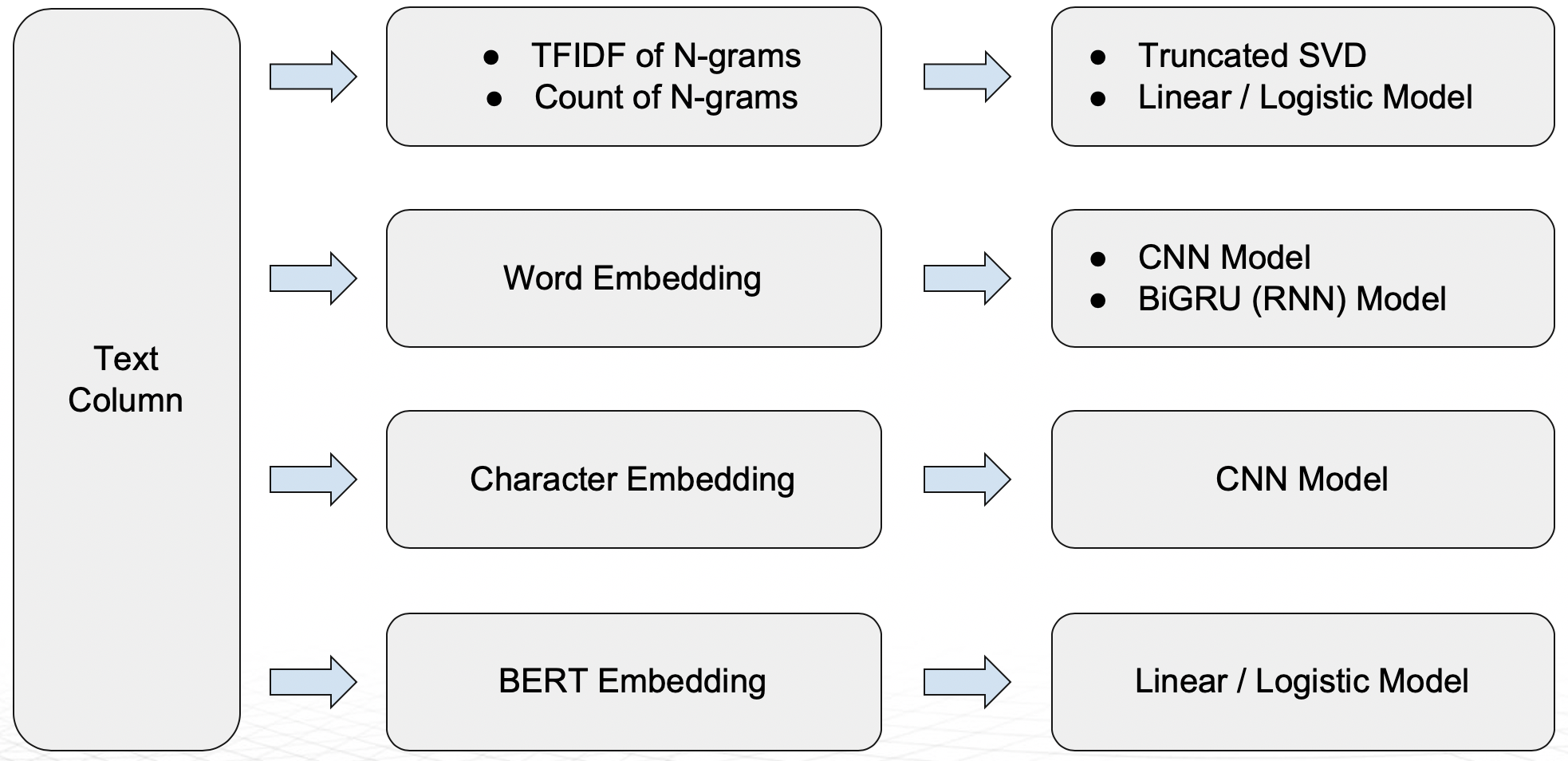
Driverless AI에서 사전 학습된 Pytorch 모델
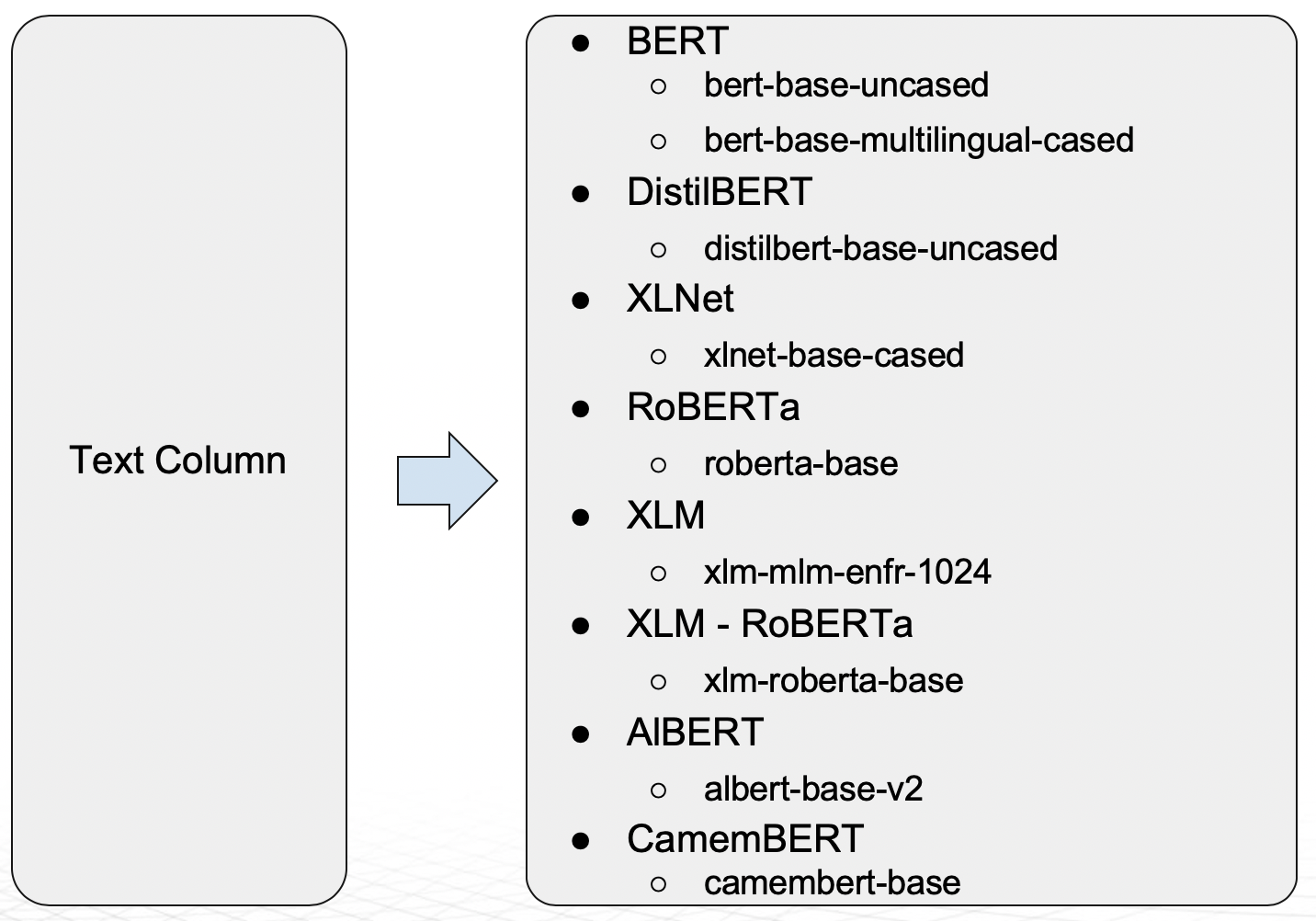
다음 NLP Recipes를 문자열에 사용할 수 있습니다. NLP Transformers 의 전체 목록은 here 에서 확인할 수 있습니다.
n-gram 빈도/TF-IDF에 뒤따른 Truncated SVD
n-gram 빈도/TF-IDF에 뒤따른 Linear/Logistic regression
Word embeddings에 뒤따른 CNN model(TensorFlow)
Word embeddings에 뒤따른 BiGRU model(TensorFlow)
Character embeddings에 뒤따른 CNN model(TensorFlow)
변수 가공의 BERT/DistilBERT 기반 임베딩(PyTorch)
모델링 알고리즘(PyTorch)으로 다중 Transformer 아키텍처(예: BERT) 지원
n-gram
N-gram 은 주어진 문자 또는 음성 샘플에서 n 항목의 연속된 시퀀스입니다.
n-gram Frequency
빈도 기반 기능은 벡터 형태로 주어진 문자에서 각 단어의 수를 나타냅니다. 이들은 서로 다른 n-gram 값에 대해 생성됩니다. 예를 들어, one-gram은 단어 한 개와 같고 two-gram은 함께 쌍을 이루는 연속된 두 개의 단어와 같습니다. 더 자주 발생하는 단어와 n-gram은 더 높은 가중치를 받습니다. 희귀할수록 더 낮은 가중치를 받게 됩니다.
TF-IDF of n-grams
빈도-기반 기능을 역 문서 빈도에 곱해서 단어 빈도-역 문서 빈도(TF-IDF) 벡터를 얻을 수 있습니다. 이를 통해, 말뭉치에서 생기는 희귀 용어에 중요도가 부여되며 특정 분류 작업에 도움이 될 수 있습니다.

Truncated SVD Features
TF-IDF와 n-gram의 빈도 모두 더 높은 차원의 구상적 벡터를 생성합니다. 이에 해결하기 위해 일반적으로 벡터화된 배열을 더 낮은 차원으로 분해하는 데 Truncated SVD 를 사용합니다.
Linear Models for TF-IDF Vectors
Driverless AI NLP recipe에서 선형 모델을 사용할 수 있습니다. 이는 높은 accuracy 비율을 달성하는 프로세스에 결정적인 선형 종속을 캡처하며 기본 DAI 모델의 기능으로 사용됩니다.
Word Embeddings
Word embeddings는 용어의 단어 또는 구절이 실수 벡터에 매핑되는 문자에 대한 변수 가공 기술의 집합을 가리키는 용어입니다. 유사한 의미를 가진 단어가 서로 인접하거나 등거리에 배치되도록 표현이 만들어집니다. 한 예로, 단어 《king》은 이러한 종류의 벡터 표현에서 《queen》이라는 단어와 밀접하게 관련이 있습니다.
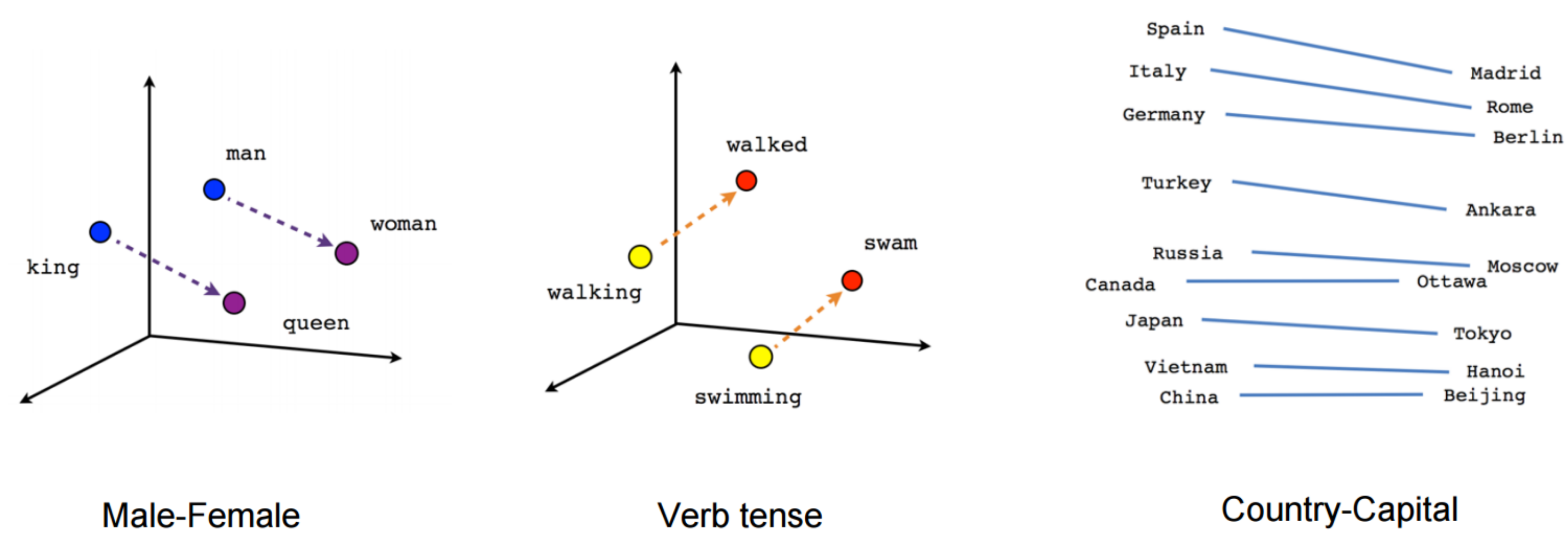
TF-IDF 및 빈도-기반 모델은 개수 및 중요한 단어 정보를 나타내지만, 이러한 단어에 대한 의미론적인 맥락이 부족합니다. 이러한 의미론적인 정보 부족의 보완을 위해 Word embeddings 기술이 사용됩니다.
CNN Models for Word Embedding
콘볼루션 신경망(CNN) 모델은 주로 이미지 수준의 기계 학습 작업에 사용되지만, 문자를 정보로 표현하는 유스케이스는 RNN 모델에 비해 휠씬 빠르고 효율적인 것으로 입증되었습니다. Driverless AI에서는 Word embeddings를 CNN model에 대한 입력으로 패스하여, 새로운 기능 세트로 사용할 수 있는 교차 검증된 예측을 반환합니다.

Bi-directional GRU Models for Word Embedding
장단기 기억 유닛(LSTM) 및 게이트 순환 유닛(GRU)과 같은 순환 신경망은 NLP 문제를 해결하기 위한 최신 알고리즘입니다. Driverless AI에서 우리는 현재 상태를 예측하기 위해 이전 단어 단계와 이후 단계에 양방향 GRU 기능을 실행합니다. 예를 들어, 《존이 골프 코스를 걷고 있습니다.》라는 문장에서 단일 방향 모델은 《존이 걷고 있습니다.》를 기반으로 《골프》를 표현하는 상태를 나타내지만 《코스》를 표현하지는 않습니다. 하지만 《양방향 모델을 사용하면, 이 표현은 이후의 표현도 고려하기 때문에 모델의 예측력이 더욱 향상됩니다.
다시 말해서 양방향 GRU 모델은 두 개의 독립적인 RNN 모델을 단일 모델로 결합합니다. GRU 아키텍처는 LSTM 아키텍처와 유사한 고속 그리고 높은 비율의 accuracy를 제공합니다. CNN model처럼, Word embeddings를 이러한 모델에 입력으로 패스하여 새로운 기능 세트로 사용될 수 있는 교차 검증된 예측을 반환합니다.
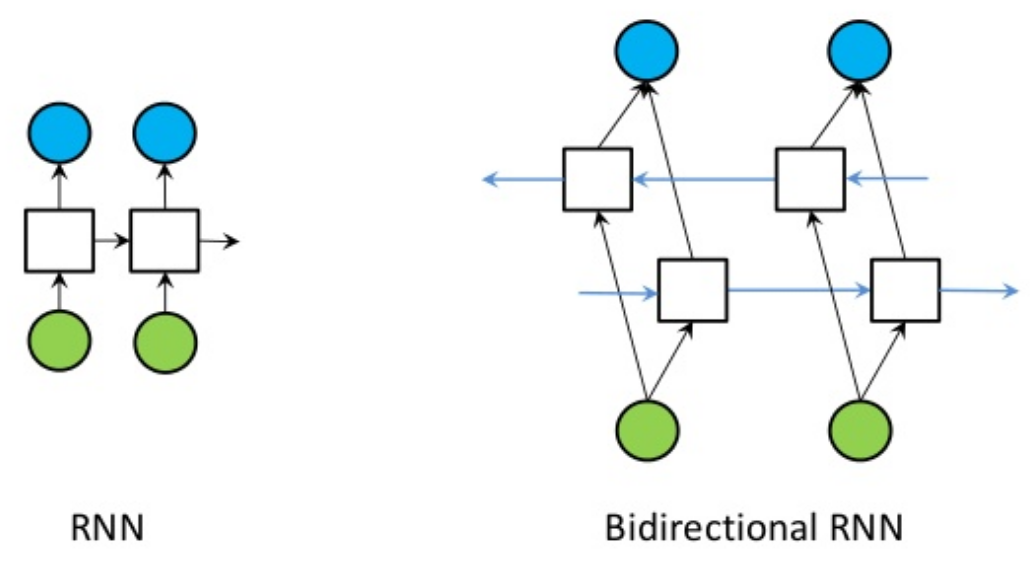
CNN Models for Character Embedding
문자가 중요한 역할을 하는 일본어 및 중국어의 경우, 문자 수준 임베딩을 NLP recipe로 사용할 수 있습니다.
Character embeddings에서 각 문자는 단어보다는 벡터의 형태로 표현됩니다. Driverless AI는 문자 수준의 임베딩을 CNN model에 대한 입력으로 사용하고, 차후 클래스 확률을 추출하여 다운스트림 모델의 기능으로 제공합니다.
아래 이미지는 해당 NLP recipe로 생성한 전체 기능 집합을 나타냅니다.
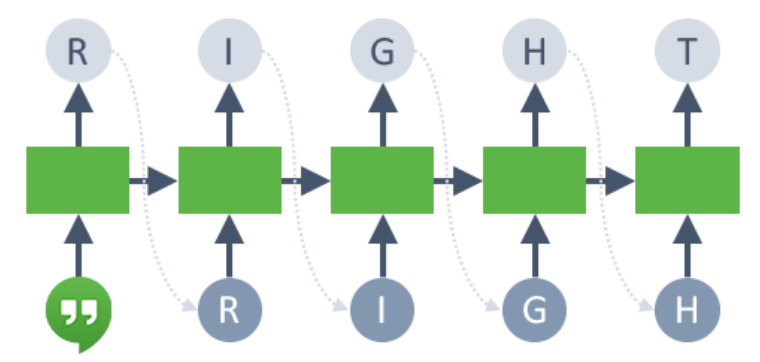
BERT/DistilBERT Models for Feature Engineering
BERT와 같은 Transformer 기반 언어 모델은 다양한 NLP 작업에 사용할 수 있는 최첨단 NLP 모델입니다. 이 모델은 어텐션 메커니즘을 사용하여 단어 간의 맥락 내 관계를 포착합니다. 문자를 순서대로 읽는 방향성 모델과 달리 Transformer 기반 모델은 문자의 전체적인 순서를 한 번에 읽기 때문에 모든 주변 단어를 기반으로 하여 단어의 맥락을 학습할 수 있습니다.
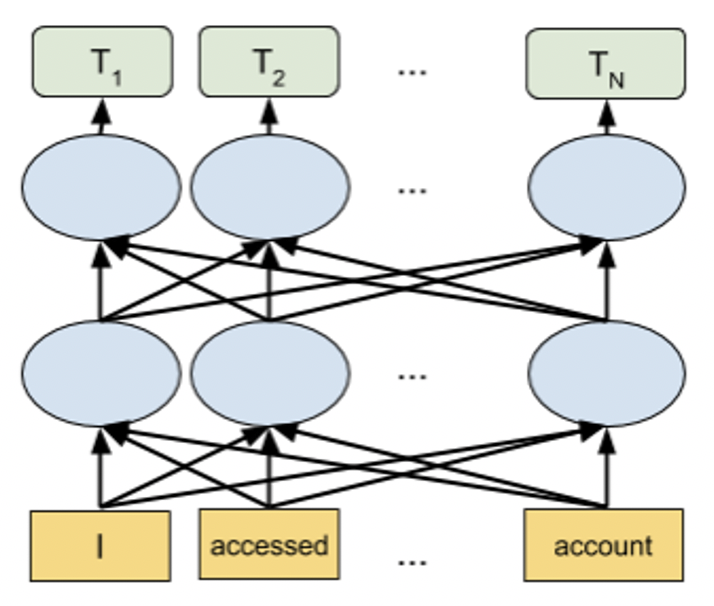
BERT 및 DistilBERT 모델은 모든 문자열의 임베딩 생성에 사용할 수 있습니다. 이러한 사전 학습 모델은 Linear/Logistic regression이 뒤따르는 문자의 임베딩을 사용하여 Driverless AI의 모든 다운스트림 모델에서 사용될 수 있는 기능을 생성하는 데 사용됩니다. 해당 모델을 활성화하여 변수 가공에 적용하는 방법에 대한 자세한 내용은 전문가 설정 항목의 NLP 설정 을 참조하십시오. 해당 모델의 성능을 활용하고 변수 가공 프로세스를 가속화하려면 GPU를 사용하도록 권장합니다.
PyTorch Transformer Architecture Models (eg. BERT) as Modeling Algorithms
Driverless AI 1.9 릴리스를 시작으로, 아래 다이어그램에 나타낸 Transformer 기반 아키텍처는 Driverless AI의 모델로 지원됩니다.
BERT 모델은 다양한 언어를 지원합니다. DistilBERT는 BERT에 비해 매개변수가 적고(40% 적음) BERT 성능의 95%를 유지하면서 속도는 더 빠른(60% 속도 향상) BERT의 정제된 버전입니다. DistilBERT 모델은 학습 시간과 모델 크기가 중요한 경우에 유용합니다. 이 모델을 모델링 알고리즘으로 활용하는 방법에 대한 자세한 내용은 전문가 설정 항목의 NLP 설정 을 참조하십시오. 이 모델의 성능을 활용하고 모델의 학습 시간을 가속화하려면 GPU를 사용하도록 권장합니다.
이러한 기술뿐만 아니라, Driverless AI는 PyTorch 또는 Flair를 사용하여 custom NLP recipes 를 지원합니다.
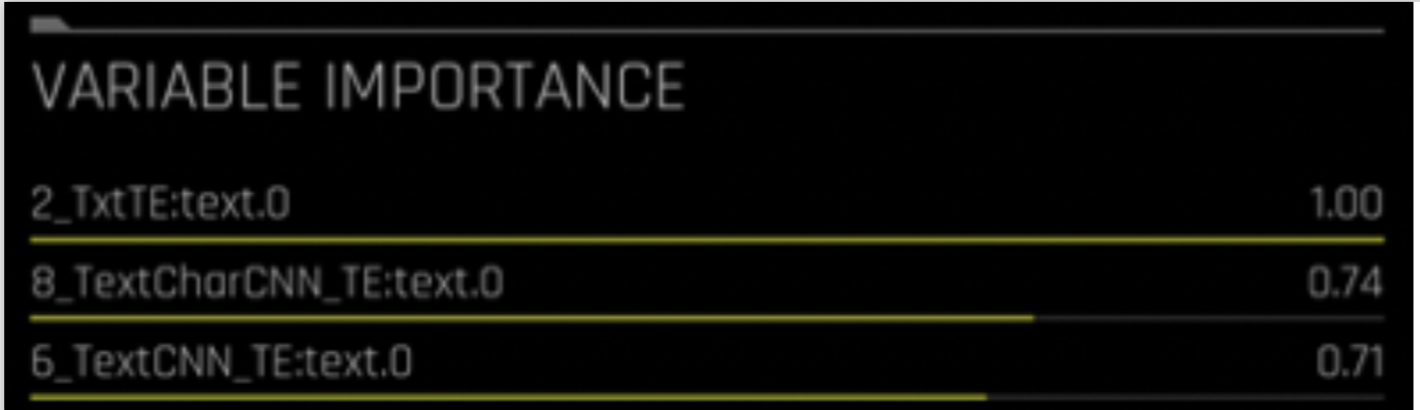
NLP 기능 명명 규약¶
NLP 기능 명명 규약은 생성된 기능의 유형 파악에 도움이 됩니다.
기능 이름의 구문은 다음과 같습니다.
[FEAT TYPE]:[COL].[TARGET_CLASS]
[FEAT TYPE] 은 다음 중 하나를 나타냅니다:
n-gram의 Txt – 빈도 / TF-IDF에 뒤따른 Truncated SVD
n-gram의 TxtTE - 빈도 / TF-IDF에 뒤따른 선형 모델
TextCNN_TE – Word embeddings에 뒤따른 CNN model
TextBiGRU_TE – Word embeddings에 뒤따른 양방향 GRU 모델
TextCharCNN_TE – Character embeddings에 뒤따른 CNN model
[COL] 은 문자열의 이름을 나타냅니다.
[TARGET_CLASS] 는 모델 예측이 만들어지는 대상 클래스를 나타냅니다.
예를 들면, TxtTE:text.0은 선형 모델이 뒤따르는 n-gram의 빈도 / TF-IDF를 사용하여 문자열 《text》에 대한 클래스 0 예측과 동일시됩니다.
NLP Explainers¶
다음은 사용 가능한 NLP explainer 목록입니다. 자세한 내용은 Explainer Recipes 및 NLP 플롯 를 참조하십시오.
NLP LOCO Explainer: NLP LOCO 플롯은 레코드의 모든 텍스트 기능에서 특정 토큰을 제거하고 해당 토큰 없이 로컬 중요성을 예측하여 NLP 모델에 LOCO(leave-one-covariate-out) 스타일 접근 방식을 적용합니다. 결과 점수와 원래 점수(토큰 포함)의 차이는 텍스트 특성에 대한 특정 변경 사항이 모델에 의해 만들어진 예측을 어떻게 바꾸는지 확인하고자 할 때 유용합니다.
NLP Partial Dependence Plot Explainer: NLP 부분 종속성(노란색)은 입력 텍스트 토큰이 해당 텍스트에 남아 있고 +/- 1 표준 편차 밴드와 함께 해당 텍스트에 포함되지 않은 경우 Driverless AI 모델의 평균 예측 동작을 나타냅니다. ICE(회색)는 입력 텍스트 토큰이 해당 텍스트에 남아 있고 해당 텍스트에 포함되지 않은 경우 데이터의 개별 행에 대한 예측 동작을 표시합니다. 텍스트 토큰은 TF-IDF에서 생성됩니다.
NLP Tokenizer Explainer: NLP 토크나이저 플롯은 말뭉치(대규모의 구조화된 텍스트 세트)에 있는 각 토큰의 전역 및 로컬 중요성 값을 모두 보여줍니다. 말뭉치는 토큰화 프로세스에 앞서 Driverless AI 모델에서 사용하는 텍스트 기능에서 자동으로 생성됩니다. 로컬 중요성 값은 빈도-역 문서 빈도(TF-IDF)라는 용어를 각 행의 각 토큰에 대한 가중치 요인으로 사용하여 계산합니다. TF-IDF는 주어진 문서에 토큰이 등장하는 횟수에 비례하여 증가하며 토큰을 포함하는 말뭉치의 문서 수에 의해 오프셋됩니다.
NLP Vectorizer + Linear Model (VLM) Text Feature Importance Explainer: NLP 벡터라이저 + 선형 모델(VLM) 텍스트 기능 중요성은 개별 단어의 TF-IDF를 관심 있는 텍스트 열의 기능으로 사용하고 이러한 기능을 사용하여 선형 모델(현재 GLM)을 구축하며 이를 예측된 클래스(이진 분류) 또는 Driverless AI 모델의 연속 예측(회귀분석) 중 하나에 맞춥니다. 선형 모델의 계수는 단어의 중요성을 나타냅니다. 기본적으로 이 explainer는 알파벳 순서를 바탕으로 첫 번째 텍스트 열을 사용합니다.
NLP 전문가 설정¶
Driverless AI의 NLP에 대해 몇 가지 구성 가능한 설정을 이용할 수 있습니다. 더 자세한 내용은 상세 설정 주제의 NLP 설정 를 참조하십시오. 또한 실험 설정의 pipeline building recipes 에서 nlp model 및 nlp transformer 를 참조하십시오.

NLP 예제: 감성 분석¶
다음 섹션은 NLP 예제에 대한 내용입니다. 이 정보는 문자 분석을 위한 자동 변수 가공 블로그 게시물을 기초로 합니다. Python client를 사용하는 유사한 예제는 Python Client 에 있습니다.
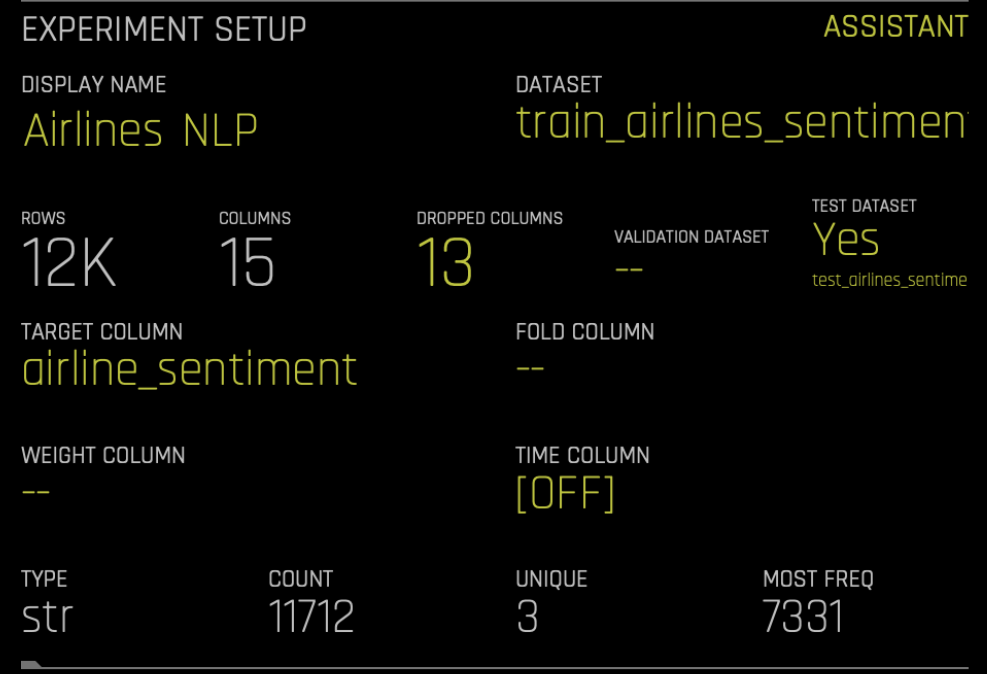
이 예제는 US Airline Sentiment dataset 를 사용한 트윗에 대한 감성 분석의 고전적인 사례를 이용합니다. 각 트윗의 감성에는 미리 라벨이 지정되어 있으며 우리 모델은 새로운 트윗을 라벨링 하는 데 사용됩니다. Driverless AI에서 무작위 분할을 사용하여 데이터 세트를 훈련 및 테스트(80/20)로 분할할 수 있습니다. 이 데모에서는 ‘문자’ 열의 트윗과 ‘airline_sentiment’ 열의 감성(긍정적, 부정적 또는 중립적)을 사용합니다.

데이터 세트가 표 포맷으로 준비되면, 모두 Driverless AI를 사용하도록 설정됩니다. Driverless AI 설정의 다른 문제와 비슷하게, 데이터 세트를 선택한 후 대상 열 (‘airline_sentiment’) 을 지정해야 합니다.
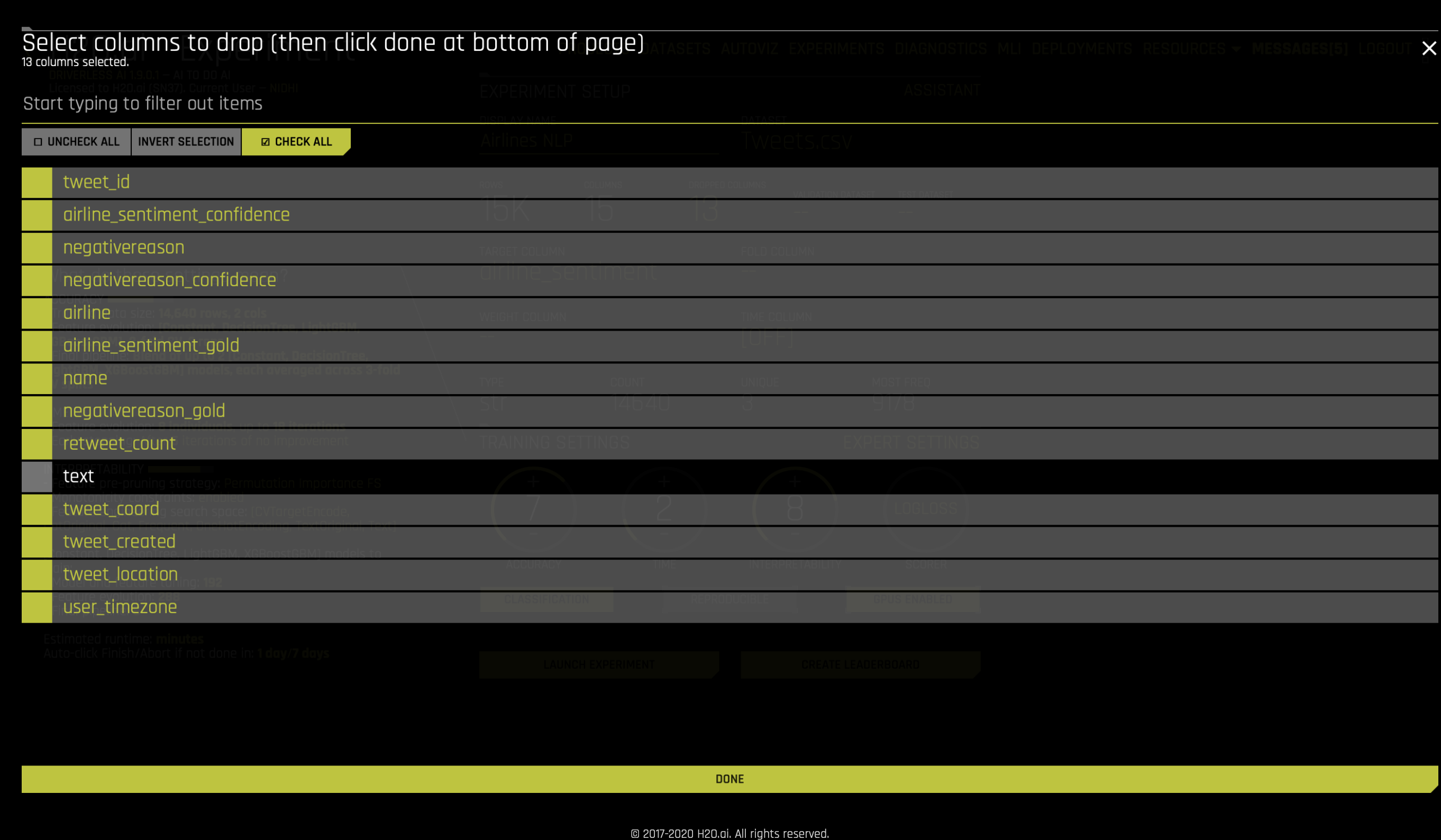
데이터 세트에서 다른 열의 사용을 피하기 위해, Dropped Cols 를 클릭한 후 아래와 같이 text 를 뺀 나머지 모든 항목을 제외해야 합니다.
다음으로, TensorFlow NLP recipes를 켭니다. Expert Settings, NLP 로 이동한 후, 다음을 켭니다: CNN TensorFlow models, BiGRU TensorFlow models, character-based TensorFlow models 또는 pretrained PyTorch NLP models
이 시점에서 실험을 시작할 준비가 되었습니다. 문자 기능은 변수 가공 프로세스 중에 자동으로 생성되고 평가됩니다. TextCNN과 같은 일부 기능은 TensorFlow 모델에 의존한다는 것을 참고하십시오. GPU(들)를 사용하여 TensorFlow 또는 PyTorch Transformer 모델의 성능을 활용하고 변수 가공 프로세스를 가속화하는 것을 권장합니다.
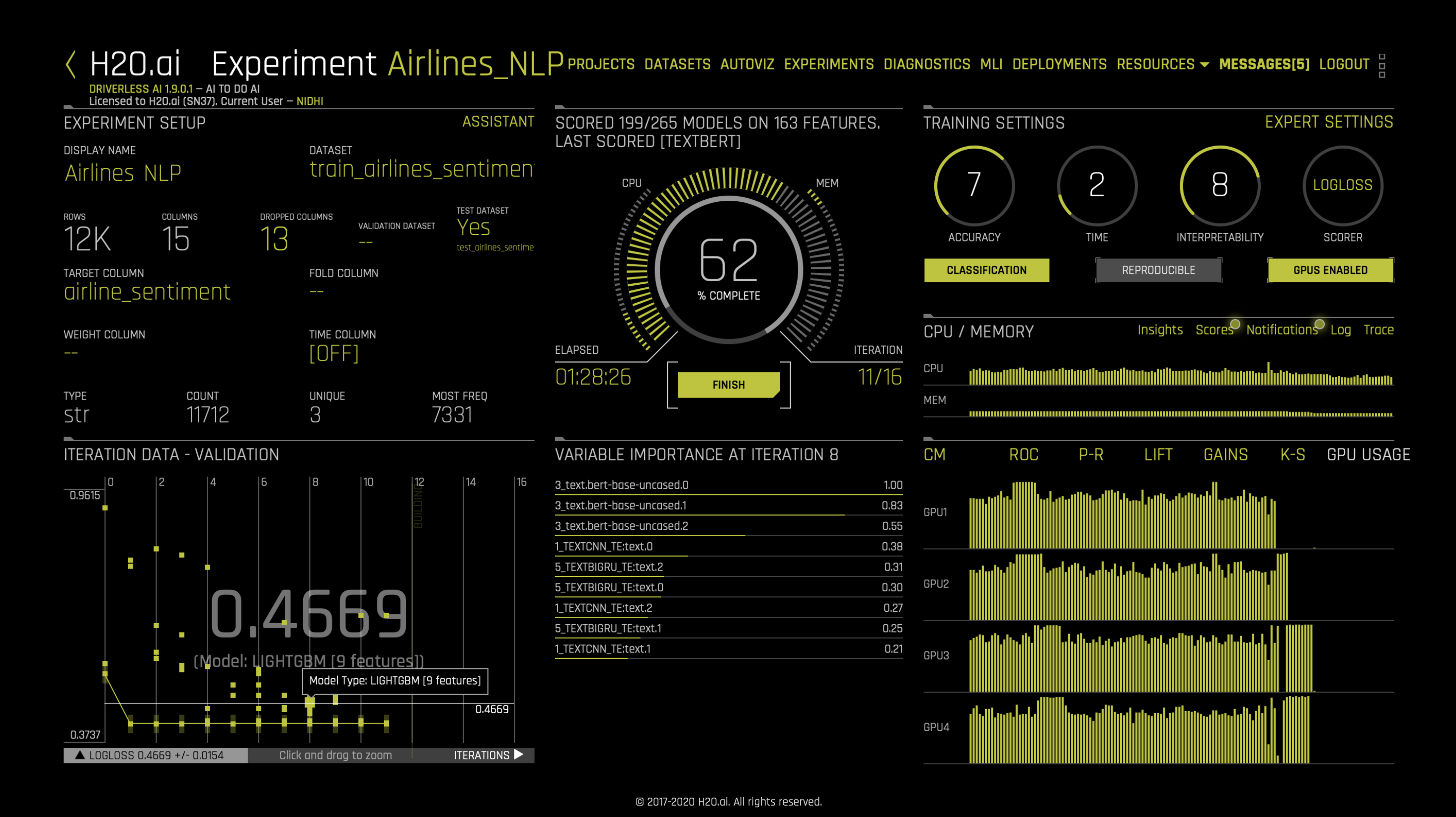
실험이 종료되면 사용자는 기타 Driverless AI 실험과 마찬가지로 새로운 예측을 만들고 스코어링 파이프 라인을 다운로드할 수 있습니다.
Resources:
fastText: https://fasttext.cc/
생산에 대한 NLP 모델¶
Python scoring 및 C++ MOJO scoring 은 TensorFlow 및 BERT 모델(변수 가공 및 모델링에 사용)에서 지원됩니다. GPU에서 모델 배포를 활성화하려면 config.toml 에서 tensorflow_nlp_have_gpus_in_production 매개변수를 활성화합니다.