Driverless AI의 Time Series¶
time series 예측은 비즈니스 분석에서 가장 일반적이고 중요한 태스크 중 하나입니다. 판매, 날씨, 주식 시장, 에너지 수요 등 실생활에 적용되는 분야가 다양합니다. H2O는 자동화를 통해 사용자가 신속하게 비즈니스 가치를 제공할 수 있음을 잘 알고 있습니다. 그에 따라 최신 time series 분석과 Kaggle Grand Master time series 레시피를 Driverless AI로 통합하였습니다.
자동화를 가능하게 만드는 핵심 특성/레시피는 다음과 같습니다.
시간 그룹의 자동 처리(다양한 저장소 및 부서)
탄탄한 time series 검증
Gap 및 forecast horizon 고려
과거 정보만 사용(데이터 누출이 없음)
time series별 변수 가공 레시피
요일, 일자 등의 날짜 특성
AutoRegressive 특성(최적 지연 및 지연-특성 상호 작용 등)
다양한 유형의 지수 가중 이동 평균
과거 정보의 집계(다양한 시간 그룹 및 시간 간격)
목표값 변환 및 차별화
기존 변수 가공 함수(레시피 및 최적화)의 통합
Test-time Augmentation 또는 리핏(re-fit)을 사용하여 time series 실험에 대해 롤링 윈도우 기반 예측
자동 파이프라인 생성 ( 《From Kaggle Grand Masters〉 Recipes to Production Ready in a Few Clicks》 블로그 포스트 참조.)
time series의 이해¶
다음은 Driverless AI의 time series에 대한 자세한 설명입니다. time series 실험을 실행하는 모범 사례에 대한 설명은 Time Series 모범 사례 를 참조하십시오.
모델링 방식¶
Driverless AI는 time series별 변수 가공에 초점을 두고 GBM, GLM, 신경망을 사용합니다. 변수 가공에는 다음이 포함됩니다.
자가 회귀 요소: 지연 변수 생성
지연된 변수에 대해 집계된 특성: 이동 평균, 지수 평활 기술 통계, 상관 관계
날짜별 특성: 주 수, 요일, 일자, 월, 년
목표값 변환: 통합/차별화, 단일 변량 변환(로그, 제곱근 등)
이 접근 방식은 유전 알고리즘의 일부로 AutoDL 특성과 결합됩니다. 선택은 검증 accuracy를 기반으로 합니다. 즉, 동일한 변환/유전자가 적용됩니다. 또한 time series에서 비롯된 새로운 변환이 있습니다. 일부 변환(대상 인코딩 등)은 비활성화됩니다.
time series 실험을 실행할 때 Driverless AI는 검증 창을 제 시간에 롤백하여(잠재적으로 점점 더 적은 학습 데이터를 사용하여) 여러 모델을 구축합니다.
사용자 구성 가능 옵션¶
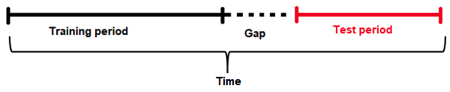
Gap¶
time series 예측 문제를 올바르게 모델링하는 기본 원칙은 스코어링 시점에 데이터/정보 환경을 모방하도록 모델 학습 데이터 세트의 과거 데이터를 사용하는 것입니다(즉, 배포된 예측값). 특히, 1) 예측 시 모델에 사용할 수 있는 정보 및 2) 예측을 위해 모델을 최적화해야 하는 단위 수를 고려하여 학습 세트를 분할합니다.
학습 데이터 세트가 주어졌을 때, Gap과 forecast horizon은 학습 데이터 세트를 학습 샘플과 검증 샘플로 분할하는 방법을 결정하는 매개변수입니다.
Gap 은 학습 세트의 끝과 테스트 세트의 시작 사이에 누락된 시간 bin의 양입니다(시간 측면에서). 예를 들면 다음과 같습니다.
2020/1/1, 2020/1/2, 2020/1/3, 2020/1/4일의 일별 데이터가 있다고 가정합니다. 교육 기간은 총 4일입니다.
또한, 테스트 데이터는 2020/1/6일부터 시작합니다. 테스트 데이터에는 1일만 있습니다.
이전 날짜(2020/1/5)는 교육 데이터에 속하지 않습니다. 이는 학습에 사용할 수 없는 날짜입니다(해당 날짜의 정보는 스코어링 시간에 사용할 수 없기 때문). 이 날짜는 테스트 데이터의 정보 추출(과거 지연 등)에도 사용할 수 없습니다.
여기서 시간 bin(또는 시간 단위)은 1일입니다. 이는 데이터에서 다양한 샘플/행을 분리하는 시간 간격입니다.
요약하면, 학습 데이터에는 4개의 시간 bin/단위가 있고, 테스트 데이터 + Gap에는 1개의 시간 bin/단위가 있습니다.
학습 데이터의 끝과 테스트 데이터의 시작 사이의 Gap을 추정하려면 다음 공식을 적용합니다.
Gap = min(시간 bin 테스트) - max(시간 bin 학습) - 1.
이 경우 ` min(시간 bin 테스트)` 은 6(또는 2020/1/6)입니다. 이는 테스트 데이터의 가장 이른(및 유일한) 날짜입니다.
Max(시간 bin 학습) 는 4(또는 2020/1/4)입니다. 이는 학습 데이터의 가장 늦은(또는 가장 최근) 날짜입니다.
따라서, Gap = 6 - 4 - 1 또는 Gap = 1 이므로, GAP은 1개의 시간 bin(또는 이 경우 1일)이 됩니다.
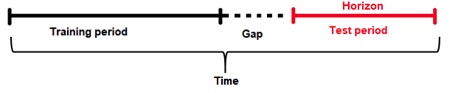
Forecast Horizon¶
모델을 적용할 때 최신 데이터를 사용할 수 없는 경우가 종종 있습니다(또는 데이터 테이블을 너무 자주 업데이트하려면 비용이 높습니다). 따라서 《미래 Gap》을 고려하여 일부 모델을 빌드해야 합니다. 예를 들면, 특정 데이터 테이블을 업데이트하는 데 일주일이 걸리는 경우, 오늘인 데이터로 7일 먼저 예측을 하는 것이 좋습니다. 따라서 7일 Gap을 권장합니다. Gap을 지정하지 않고 그 상태의 데이터로 7일 앞서 예측하는 것은 현실성이 없습니다(또한 이 경우 매주 데이터가 업데이트되므로 일어날 수 없음). 마찬가지로, 미리 더 많이 예측하려고 하는 경우 Gap을 사용할 수 있습니다. 예를 들어, 향후 7일 동안 일어날 일을 예측하려는 경우라면 Gap을 7일로 설정하게 됩니다.
Forecast Horizon (또는 예측 길이)는 테스트 데이터가 지속되는 기간입니다(1일, 1주 등). 즉, 모델이 예측할 수 있는 미래의 기간(또는 예측을 위해 모델을 최적화해야 하는 단위의 수)입니다. forecast horizon은 특성 선택 및 엔지니어링과 모델 선택에 사용됩니다. forecast horizon은 예측의 수와 동일하지 않을 수 있습니다. 실제 예측값은 테스트 데이터 세트로 결정됩니다.
데이터를 주기적으로 업데이트하려면 미래의 상당한 시간을 설명하는 모델 예측이 필요할 수 있습니다. 데이터를 매우 빠르게 업데이트할 수 있는 이상적인 세계에서는 항상 최신 데이터를 사용하여 예측할 수 있습니다. 이런 시나리오에서는 모델을 사용해 미래까지 이어지는 사례를 예측할 필요가 없고, 그보다는 단기 예측 기능을 극대화하는 데 초점을 둡니다. 단, 이것도 항상 해당되는 것은 아니며, 매일 데이터 업데이트 후에 예측을 수행하려면 비용이 너무 높을 수 있으므로 하나의 모델로 먼 미래까지 예측할 수 있어야 합니다.
또한, 각 미래 데이터 포인트는 동일하지 않습니다. 예를 들어 오늘의 데이터로 내일을 예측하는 것은 오늘의 데이터로 이틀 앞을 예측하는 것보다 쉽습니다. 따라서 forecast horizon을 지정하면 이러한 미래 시간 간격에 대한 예측 accuracy를 최적화하는 모델을 쉽게 구축할 수 있습니다.
예측 간격¶
회귀 분석 문제의 경우, prediction_intervals 상세 설정을 활성화하여 Driverless AI가 예측 프레임에 있는 두 개의 추가 열 y.lower 및 y.upper 를 제공하도록 합니다. 예측된 샘플에 대한 실제 목표값 y 는 특정 확률로 [y.lower, y.upper] 내에 있을 것으로 예상됩니다. 이 신뢰 수준의 기본값은 prediction_intervals_alpha 상세 설정을 사용하여 지정할 수 있으며, 기본값은 0.9입니다.
Driverless AI는 홀드아웃 예측을 사용하여 경험적으로 간격을 결정합니다(Williams, W.H. and Goodman, M.L. 《A Simple Method for the Construction of Empirical Confidence Limits for Economic Forecasts.》 Journal of the American Statistical Association, 66, 752-754. 1971). 이 방법은 기본 모델이나 오류 분포에 대한 가정을 하지 않으며, 다른 여러 접근 방식보다 결과가 나은 것으로 나타났습니다(Lee, Yun Shin and Scholtes, Stefan. 《Empirical prediction intervals revisited.》 International Journal of Forecasting, 30, 217-234. 2014).
Notes:
이 특성은 회귀 분석 태스크에 적용됩니다(i.i.d. 및 time series).
이 특성은 모든 모델 유형에 효과가 있습니다.
MOJO 지원은 현재 이 특성에 구현되지 않습니다.
예측 간격은 각 개별 시간 그룹별로 계산됩니다.
time_period_in_seconds¶
Note: time_period_in_seconds 은 Python 및 R 클라이언트에서만 사용할 수 있습니다. UI에서 시간(초)을 지정할 수 없습니다.
Driverless AI에서 forecast horizon(즉, num_prediction_periods)는 기간이어야 하며, 크기는 알 수 없습니다. 이를 극복하려면, start_experiment_sync (Python) 또는 train (R)을 실행할 때 매개변수 time_period_in_seconds 를 선택적으로 사용할 수 있습니다. 이를 사용해 실시간 단위로 forecast horizon을 지정합니다(Gap에 대한 지정 포함). 이 매개변수를 지정하지 않는 경우 Driverless AI는 실험의 기간 크기를 자동으로 감지하고 forecast horizon은 이 기간을 따릅니다. 즉, 확실하게 데이터의 기간이 1주일이라면, num_prediction_periods=14 이라고 할 수 있으며, 그렇지 않을 경우 모델이 올바르게 작동하지 않을 수 있습니다.
그룹¶
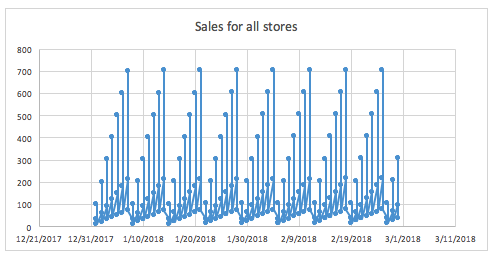
그룹은 데이터의 범주형 열로, time series 문제에서 목표 변수 예측에 크게 도움이 될 수 있습니다. 예를 들어, 매장과 제품에 대한 정보에 기반하여 판매를 예측할 수 있습니다. 대형 매장이나 인기 있는 제품은 작은 상점이나 비인기 제품보다 매출액이 더 높기 때문에, 매장과 제품의 조합으로 인해 판매 결과가 다르게 나타날 수 있음을 파악하는 능력은 목표 변수 예측의 핵심입니다.
예를 들어, 데이터에 매장이 있는지 알 수 없고 시간에 따른 매출 분포를 파악하려고 하는 경우(모든 매장이 혼합된 상태에서), 다음과 같이 나타날 수 있습니다.
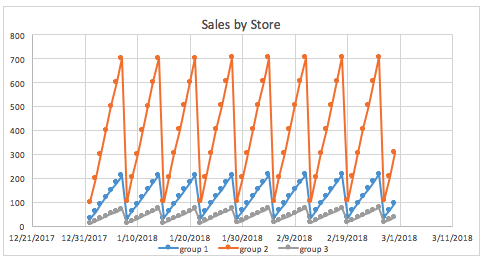
매장별로 그룹화된 동일 그래프는 여러 매장의 매출액을 훨씬 더 명확하게 보여줍니다.
지연(Lag)¶
생성된 기본 time series 특성은 변수의 과거 값인 지연 특성입니다. 타임 스탬프 \(t\) 가 있는 주어진 샘플에서는, 과거의 시차 \(T\) (지연)에서의 특성이 고려됩니다. 예를 들어, 오늘의 매출이 300이고 어제의 매출이 250인 경우, 매출의 하루 지연은 250입니다. 지연은 대상뿐만 아니라 모든 특성에 대해 생성될 수 있습니다.
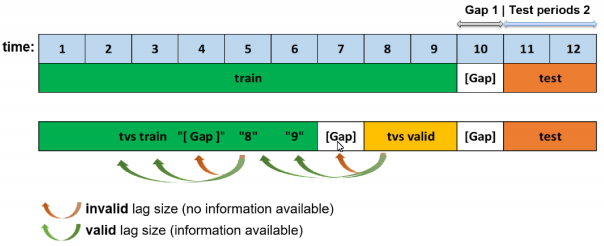
앞서 언급한 대로, 학습 데이터 세트는 검증 데이터 샘플의 양이 테스트 데이터 세트 샘플의 양과 같도록 적절하게 분할됩니다. 유효한 지연을 결정하려면, 테스트 데이터 세트에서 모델을 평가할 때 무슨 현상이 발생하는지 고려해야 합니다. 기본적으로 최소 지연 크기는 gap 크기보다 커야 합니다.
최소한의 사용 가능 지연 외에, Driverless AI는 자동 상관(auto-correlation)을 기반으로 예측 지연 크기를 찾으려고 시도합니다.
과거의 다양한 시간대에 발생한 현상을 파악하면 미래에 대한 예측이 상당히 용이해질 수 있기 때문에 《래깅(Lagging)》 변수는 time series에서 중요합니다. 1일과 2일의 지연을 보려면 다음 예제를 고려하십시오.
날짜 |
매출액 |
Lag1 |
Lag2 |
|---|---|---|---|
2020/1/1 |
100 |
- |
- |
2020/1/2 |
150 |
100 |
- |
2020/1/3 |
160 |
150 |
100 |
2020/1/4 |
200 |
160 |
150 |
2020/1/5 |
210 |
200 |
160 |
2020/1/6 |
150 |
210 |
200 |
2020/1/7 |
160 |
150 |
210 |
2020/1/8 |
120 |
160 |
150 |
2020/1/9 |
80 |
120 |
160 |
2020/1/10 |
70 |
80 |
120 |
Driverless AI에 의해 결정되는 설정¶
윈도우/이동 평균¶
위 Lag 테이블을 사용하면, 이동 평균 2는 Lag1 및 Lag2의 평균이 됩니다.
날짜 |
매출액 |
Lag1 |
Lag2 |
MA2 |
|---|---|---|---|---|
2020/1/1 |
100 |
- |
- |
- |
2020/1/2 |
150 |
100 |
- |
- |
2020/1/3 |
160 |
150 |
100 |
125 |
2020/1/4 |
200 |
160 |
150 |
155 |
2020/1/5 |
210 |
200 |
160 |
180 |
2020/1/6 |
150 |
210 |
200 |
205 |
2020/1/7 |
160 |
150 |
210 |
180 |
2020/1/8 |
120 |
160 |
150 |
155 |
2020/1/9 |
80 |
120 |
160 |
140 |
2020/1/10 |
70 |
80 |
120 |
100 |
여러 지연(한 지연이 아니라)을 집계하면 목표 변수 정의의 안정성을 높일 수 있습니다. 여기에는 다양한 지연 값이 포함될 수 있습니다(예: Lag [1-30] 또는 Lag [20-40] 또는 Lag [7-70 x 7]).
지수 가중치¶
지수 가중치(Exponential weighting)는 더 최근의 값이 덜 최근의 값보다 가중치가 높은 가중 이동 평균의 한 형태입니다. 이 가중치는 (하이퍼)매개변수 alpha (a) (0,1)를 기준으로 시간이 지남에 따라 기하급수적으로 감소하며, 일반적으로 [0.9 - 0.99]의 범위 내에 있습니다. 그 예는 다음과 같습니다.
지수 가중치 = a** (시간)
1일 전 매출 = 3.0, 2일전 매출 =4.5, a=0.95인 경우
지수 평활 = 3.0*(0.95**1) + 4.5*(0.95**2) / ((0.95**1) + (0.95**2)) =3.73 approx.
롤링 윈도우 기반 예측¶
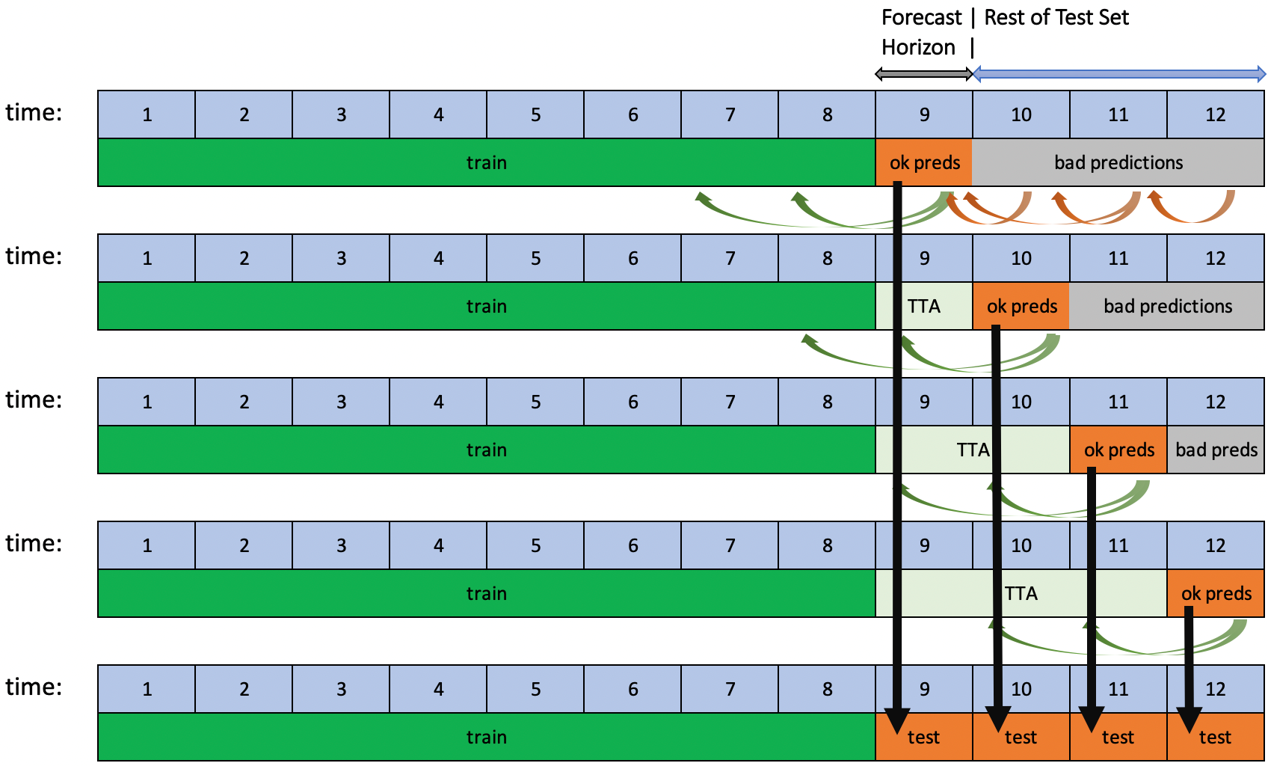
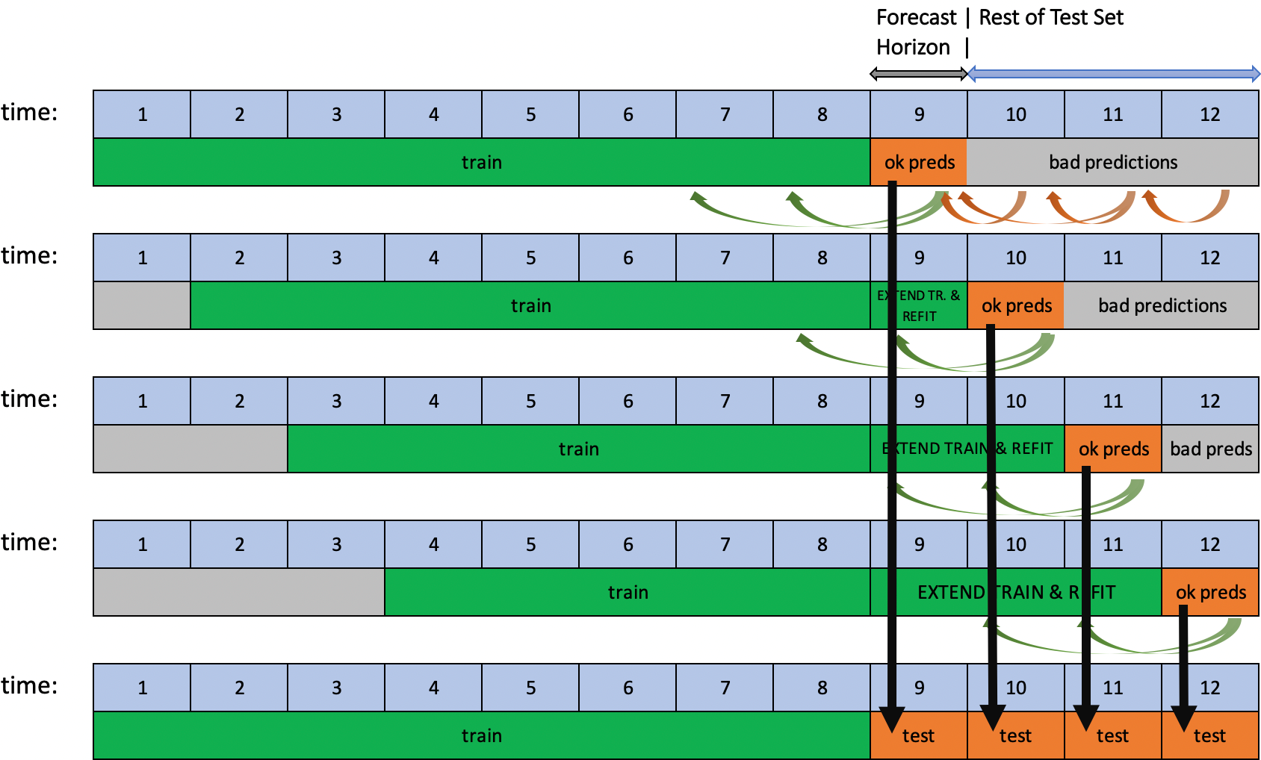
Driverless AI는 다음 두 가지 옵션으로 time series 실험에 대한 롤링 윈도우 기반 예측을 지원합니다. TTA(Test Time Augmentation ) 또는 리핏(re-fit).
두 옵션 모두 단일 forecast horizon뿐 아니라 다량의 연속적인 범위를 예측할 때 파이프라인의 성능 평가에 효과가 있습니다. TTA는 모델은 동일하지만 새로운 데이터를 사용하여 특성을 새로 고치는 프로세스를 시뮬레이션합니다. 리핏은 새로운 데이터가 있을 때 전체 파이프라인(모델 포함)을 다시 피팅하는(re-fitting) 프로세스를 시뮬레이션합니다.
테스트 세트가 forecast horizon보다 더 긴 기간에 걸쳐 있고 테스트 세트의 목표값이 알려진 경우 이 프로세스는 자동화됩니다. 실험 완료 후 사용자가 이 조건을 충족하는 테스트 세트를 채점하는 경우, TTA를 사용한 롤링 예측이 적용됩니다. 반면에 리핏은 실험 중에 제공된 테스트 세트에만 적용됩니다.
TTA는 기본 옵션이며 롤링 테스트 세트 예측 생성 방법 상세 설정으로 변경할 수 있습니다.
Time Series 제약 사항¶
데이터 세트 크기¶
일반적으로, forecast horizon(예측 길이) \(H\) 에 있는 기간의 수치와 동일합니다(즉, \(N_{TEST} = H\)). 테스트 데이터 세트에 대한 채점을 잘 하려면 충분한 학습 데이터 기간 \(N_{TRAIN}\) 이 필요합니다. 최소한, 학습 데이터 세트에는 테스트 데이터 세트보다 3배 이상 많은 기간이 포함되어야 합니다(즉, \(N_{TRAIN} >= 3 × N_{TEST}\)). 이렇게 되어야 학습 데이터 세트를 테스트 데이터 세트와 동일한 기간의 검증 세트로 분할하는 동시에 변수 가공을 위한 충분한 과거 데이터를 유지할 수 있습니다.
Time Series 사용 사례: 매출 예측¶
다음은 Kaggle 월마트 매출 분석 대회 를 바탕으로 한 매출 예측의 전형적인 예입니다. 이를 기계학습 문제로 구성하기 위해, 과거 매출 데이터와 추가 속성을 다음과 같이 수식화합니다.
원시 데이터
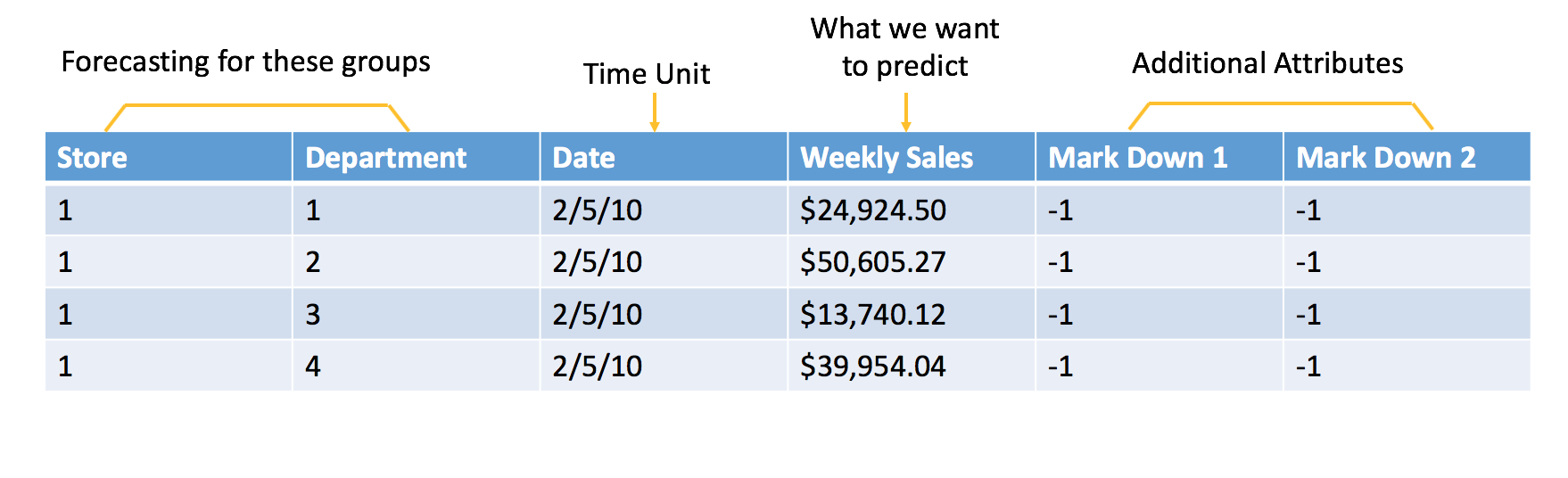
기계학습을 위해 수식화된 데이터
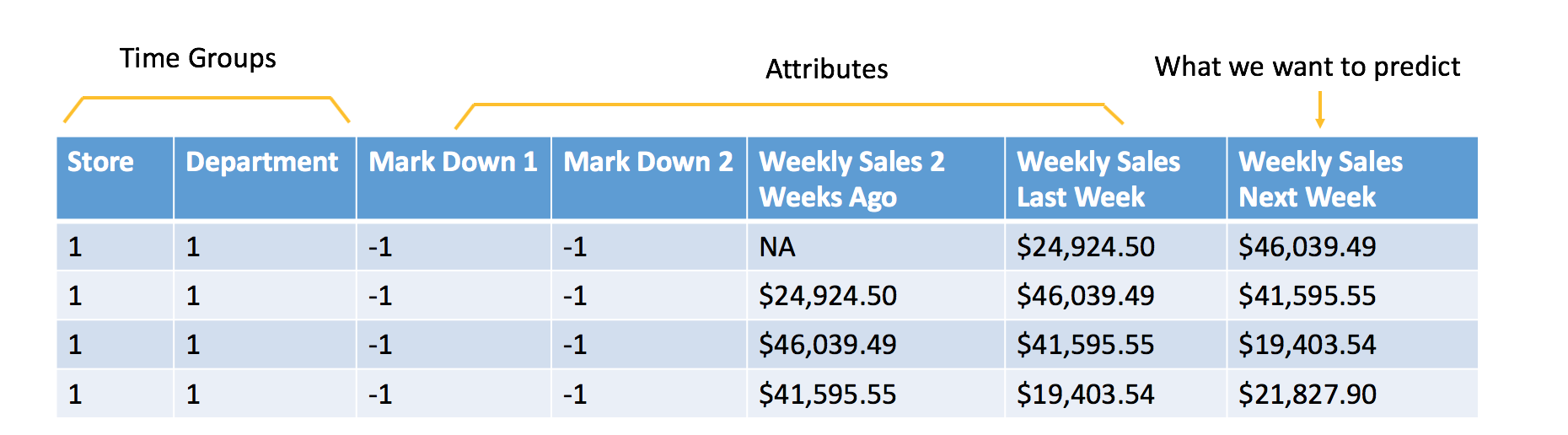
추가 속성은 채점 시에 알게 되는 속성입니다. 이 예에서 목표는 다음 주 매출을 예측하는 것입니다. 따라서 데이터에 포함된 모든 속성은 최소 1주일 전에 알아야 합니다. 이 경우, 매장과 부서가 판촉 할인을 시행하는지 여부를 알게 될 것으로 가정할 수 있습니다. 채점 시에 해당 정보가 없으므로 주간 기온과 같은 특성은 사용하지 않습니다.
데이터를 테이블 형식으로 구성하면(위의 원시 데이터 참조), Driverless AI가 기계학습에 맞게 이를 수식화하고 나머지를 정리할 수 있습니다. 최초의 세션에서는 Driverless AI 도우미가 과정을 안내합니다.
이전 Driverless AI 예시와 마찬가지로 학습/테스트에 대한 데이터 세트를 선택하고 목표를 정의해야 합니다. time series의 경우 시간 열을 정의해야 합니다(AUTO를 선택하거나 수동으로 날짜 열을 선택). 가중 채점이 필요한 경우(Kaggle 월마트 매출 분석 대회 등), 다양한 샘플에 대해 특정 가중치가 있는 열을 선택할 수 있습니다.

시간 그룹의 자동 처리를 원하는 경우, 시간 그룹 열의 설정을 AUTO로 두거나 특정 시간 그룹을 정의할 수 있습니다. 또한 예측 시 사용할 수 없는 열(자세한 내용은 아래의 예측 시 사용할 수 없는 열에 대한 추가 정보 참조), forecast horizon(주 단위), 학습 기간과 테스트 기간 사이의 Gap(주 단위)을 지정할 수도 있습니다.
실험이 완료되면 다른 Driverless AI 실험과 마찬가지로 새로운 예측을 수행하고 스코어링 파이프라인을 다운로드할 수 있습니다.
Driverless AI Time Series 모델을 사용한 예측¶
실험의 Forecast Horizon을 설정하는 것은 Driverless AI 실험에 이 모델이 예측할 날짜를 알려주는 것입니다. 월마트 매출 예시에서는 Driverless AI Forecast Horizon을 1(미래의 1주일)로 설정했습니다. 즉, Driverless AI는 학습 종료 후 이 모델이 1주일을 예측할 것으로 예상합니다. 학습 데이터가 2020-10-26에 종료되므로 이 모델은 2020-11-02 주간의 채점에 사용됩니다.
2020-11-02 주간이 지나면 사용자는 어떻게 해야 할까요?
다음 두 가지 옵션이 있습니다.
옵션 1: forecast horizon이 끝나는 대로 Driverless AI 실험의 학습을 트리거합니다. 매주 다시 Driverless AI 실험을 학습시켜야 합니다.
옵션 2: 동일한 모델을 사용하여 forecast horizon 밖에서 예측할 수 있도록 TTA( Test Time Augmentation )를 사용해 과거 특성을 업데이트합니다.
TTA( Test Time Augmentation )란 모델은 그대로 유지하면서 최신 데이터를 사용하여 특성을 새로 고치는 프로세스를 말합니다. 월마트 매출 예측 예에서 매우 중요한 특성은 이전 주의 주간 매출입니다. forecast horizon을 벗어나면 모델은 더 이상 이전 주의 주간 매출을 알 수 없습니다. 새로운 데이터가 제공되는 경우 Driverless AI는 TTA를 수행하여 이러한 과거 특성을 자동으로 생성합니다.
옵션 1에서는 최신 데이터로 매주 새로운 Driverless AI 실험을 시작하고 결과 모델을 사용하여 다음 주를 예측합니다. 옵션 2에서는 TTA를 사용하여 forecast horizon 밖에서 동일한 Driverless AI 실험을 계속 사용합니다.
두 옵션 모두 장점과 단점이 있습니다. 최신 데이터로 실험을 다시 학습시킴으로써, Driverless AI는 사용된 특성을 변경하고, 다른 알고리즘을 선택하며, 다른 매개변수를 선택하여 모델을 개선할 수 있습니다. 예를 들어 시간이 지나면서 데이터가 변경될 때, Driverless AI는 해당 사용 사례의 최적 알고리즘이 변경되었음을 알 수 있습니다.
forecast horizon 이후에 매번 실험을 재학습시키거나 TTA를 사용하는 명확한 이점이 있을 것입니다. Driverless AI 서버에서 예측 엔드포인트를 사용하는 대신 스코어링 파이프라인을 사용하여 미래 데이터를 예측하는 방법을 보려면 this example 을 참조하십시오.
TTA를 사용하여 더 긴 기간 동안 같은 실험을 계속 사용하면 모델 검토 프로세스를 계속 반복할 필요가 없습니다. 단, 해당 모델은 최신 상태를 유지할 수 없습니다.
다음 표는 몇 가지 스코어링 방법과 TTA 지원 여부를 나타내고 있습니다.
스코어링 방법 |
Test Time Augmentation 지원 |
|---|---|
Driverless AI scorer |
지원됨 |
Python Scoring Pipeline |
지원됨 |
MOJO Scoring Pipeline |
지원되지 않음 |
다양한 사용 사례에서, forecast horizon 이후에 매번 실험을 재학습시키거나 TTA를 사용하는 명확한 이점이 있을 것입니다. 다음 페이지에서는 두 가지 방법을 수행하고 그 성능을 비교하는 내용을 설명합니다: Time Series 모델 롤링 윈도우.
Notes:
scorer는 모델을 리핏하거나 재학습시킬 수 없습니다.
롤링 테스트 세트 예측을 생성하는 방법을 지정하려면 this expert setting 을 사용하십시오. 이 상세 설정으로 수행한 리핏은 실험 중에 사용자가 제공한 테스트 세트에만 적용됩니다. 최종 스코어링 파이프라인은 항상 TTA를 사용합니다.
Test Time Augmentation 트리거¶
Test Time Augmentation을 수행하려면, 학습 데이터 종료 후 예측하려는 날짜까지 발생하는 모든 데이터가 예측 데이터에 포함되도록 설정합니다. Driverless AI가 예측할 날짜에는 목표 열에 누락 값(NA)이 있어야 합니다. 나머지 날짜의 목표값은 채워져 있어야 합니다.
다음은 나머지 날짜를 TTA에 사용하여 2020-11-23 및 2020-11-30에 대해 예측한 예입니다.
날짜 |
매장 |
부서 |
할인 1 |
할인 2 |
주간 매출 |
|---|---|---|---|---|---|
2020-11-02 |
1 |
1 |
-1 |
-1 |
$35,000 |
2020-11-09 |
1 |
1 |
-1 |
-1 |
$40,000 |
2020-11-16 |
1 |
1 |
-1 |
-1 |
$45,000 |
2020-11-23 |
1 |
1 |
-1 |
-1 |
NA |
2020-11-30 |
1 |
1 |
-1 |
-1 |
NA |
Notes:
TTA는 미래의 기간까지 얼마든지 늘릴 수 있으나, 예측되는 날짜는 범위를 초과할 수 없습니다.
예측되는 날짜의 목표 열에 비누락(non-missing) 값이 포함되어 있는 경우, 해당 행에 대해 TTA가 트리거되지 않습니다.
미래 날짜 예측¶
미래 날짜를 예측하려면, 해당 미래 날짜가 포함된 데이터 세트를 업로드하고, 그룹 ID 또는 미래의 알려진 특성 등 추가 정보를 제공합니다. 그러면 데이터 세트를 사용하여 예측을 실행하고 채점할 수 있습니다.
다음은 2020-05-31까지 학습된 모델의 예시입니다.
날짜 |
Group_ID |
Known_Feature_1 |
Known_Feature_2 |
|---|---|---|---|
2020-06-01 |
A |
3 |
1 |
2020-06-02 |
A |
2 |
2 |
2020-06-03 |
A |
4 |
1 |
2020-06-01 |
B |
3 |
0 |
2020-06-02 |
B |
2 |
1 |
2020-06-03 |
B |
4 |
0 |
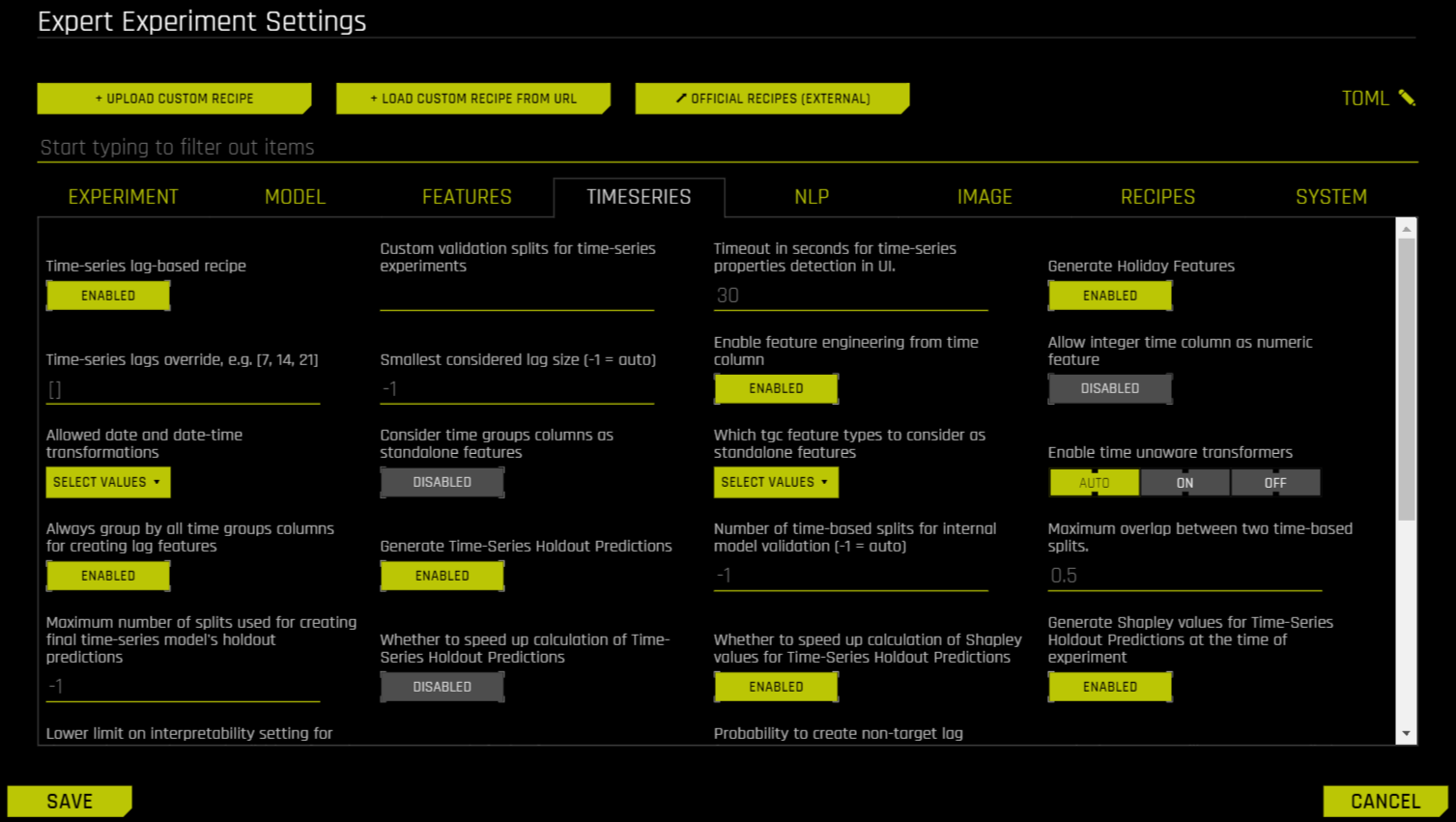
Time Series 상세 설정¶
사용자는 Expert Settings 패널에 있는 전용 옵션을 사용하여 time series 실험을 추가로 구성할 수 있습니다. 이 패널은 Scorer 노브 바로 위의 실험 페이지에 있습니다.
이 옵션에 대한 자세한 내용은 Time Series 설정 을 참조하십시오.
추가 리소스¶
Driverless AI의 Time Series 예시 실행 방법을 보여주는 예는 다음 문서를 참조하십시오.