Driverless AI의 유전 알고리즘¶
Driverless AI는 데이터 세트를 위한 best pipeline 을 목표로 합니다. 여기에는 데이터 변환, 변수 가공, 모델 하이퍼 파라미터 튜닝, 채점, 앙상블이 포함됩니다.
genetic algorithm 프로세스는 시행착오 선택 프로세스이지만 재현할 수 있습니다. Driverless AI에서 genetic algorithm 은 실험의 Feature Evolution stage 도중에 수행됩니다. Feature Evolution은 최고의 individuals 를 찾기 위해 천천히 변하는 매개변수 간의 경쟁입니다. Feature Evolution 은 완전한 무작위가 아니며 모델링 알고리즘의 variable importance 상호작용 표에서 알 수 있습니다. Driverless AI Brain 은 집단에서 최고의 유전자 세트, 상호 작용 및 매개변수에 대한 정보와 이전 실험(활성화된 경우)의 정보를 캐시에 저장하여 유전 알고리즘 뮤테이션 중에 사용할 수 있습니다.
Driverless AI는 또한 모델 하이퍼 파라미터 검색을 위해 Bayesian optimization technique 을 사용하는 Optuna 를 통합합니다. 변수 가공을 위한 유전 알고리즘과 결합하여 모델 하이퍼 파라미터 튜닝을 활성화할 수 있습니다. Custom code 를 다음과 같이 작성하여 내장 뮤테이션 전략을 토글합니다. 관련 정보는 additional information 섹션을 참조하십시오.
모델 구축 및 기능 튜닝 프로세스에서 overfitting 은 부트스트랩 및 교차 검증을 수행하여 방지하고 underfitting 은 유전 알고리즘에서 이용(exploitation )과 탐색(exploration )의 균형을 조정하여 방지합니다.
Understanding Genetic Algorithm 및 이에 상응하는 Driverless AI
The Full Picture : Driverless AI의 엔드투엔드 파이프라인
Reading the logs : 실험 로그에서 보이는 워크플로우
유전 알고리즘의 이해¶
Genetic Algorithm 은 자연 선택 프로세스에서 영감을 얻은 탐색 휴리스틱으로, 가장 적합한 개체를 선택하여 다음 세대를 위한 자손을 생산합니다.
철저한 분석 전에 고려해야 할 몇 가지 Driverless AI에 상응하는 정의:
gene은 feature transformation 에 대한 유형 및 매개변수에 대한 정보를 저장합니다. 단백질을 만들기 위한 정보가 존재하는 실제 유전자와 개념적으로 같습니다.
transformer는 유전자에 적용되는 실제 코드입니다.
Individual은 genes 세트를 포함하는 게놈으로 구성됩니다. 즉, 어떤 변환과 매개변수로 수행할 것인지에 대한 정보입니다. 여기에는 model hyperparameters 및 적용된 대상 변환 등과 같은 일부 additional information 도 포함됩니다.개체는 무작위로 선택한 쌍별 tournament process 를 거치는
population을 생성하여 우승자를 결정합니다.개체에 대한
Fitness score는 채점 메트릭를 기반으로 한 모델 평가 또는 점수입니다.
유전 알고리즘 및 이에 상응하는 Driverless AI와 관련된 단계가 아래에 있습니다.
Initialization
주어진 문제에 대한 가능한 모든 솔루션을 고려합니다. 이것이 모집단을 생성합니다. 초기화에 가장 많이 사용하는 기술은 임의의 이진 문자열 사용입니다.
Driverless AI : Tuning Phase 개체가 유전 알고리즘을 통한 기능 진화를 위한 임의의 가능한 솔루션으로 제공됩니다.
Fitness Assignment
모든 개체에 적합도 점수를 부여하면 재현에 선택될 확률을 추가로 결정하며, 적합도 점수가 높으면 재현에 선택될 확률이 높아집니다.
Driverless AI : 개체에 대한 적합도 점수는 채점 메트릭을 기반으로 한 모델 평가합니다.
Selection
자손의 재현을 위해 개체를 선택합니다. 선택한 개체를 둘씩 짝을 어 배열하여 재현을 향상합니다, 이러한 개체는 다음 세대에 유전자를 전달합니다. 유전 알고리즘은 적합도 비례 선택 기술을 사용하여 재조합을 위한 유용한 솔루션을 사용하도록 합니다.
Driverless AI : A tournament 은 모집단 내에서 수행하여 모집단에서 최고의 서브세트(subset)를 찾습니다.
Reproduction : crossover mutation
이 단계에는 자식 모집단의 생성이 포함됩니다. 알고리즘은 부모 모집단에 적용되는 변형 오퍼레이터를 사용합니다. 이 단계의 두 가지 주요 오퍼레이터에는 크로스오버 및 뮤테이션이 포함됩니다.
뮤테이션: 이 오퍼레이터는 새로운 자식 모집단에 새로운 유전 정보를 추가합니다. 이는 염색체에서 일부 비트를 뒤집어서 달성합니다. 뮤테이션은 Local 최소값 문제를 해결하고 다양성를 향상합니다.
크로스오버: 두 부모의 유전 정보를 교환하여 자손을 번식하는 오퍼레이터로, 무작위로 선택한 부모 쌍에 대해 수행하여 부모 모집단과 동일한 크기의 자식 모집단을 생성합니다.
Driverless AI : 최우선 하위 모집단의 유전자, 특징 및 모델 하이퍼파라미터는 새로운 자손으로 뮤테이션됩니다(무성 번식). Mutation 에는 genes 의 adding, perturbing, or pruning 이 포함됩니다.
유전자 추가 전략은 원래 변수의 중요성 이용과 탐색의 균형을 바탕으로 하며, 중요성이 높은 원래 변수를 위한 추가 변형을 탐색하는 유전자를 추가합니다.
이전 우승자의 최고의 유전자기 후손들 사이에서 사용 및 공유될 수 있는 훌륭한 유전자 풀의 일부가 됩니다.
특정한 출력 기능을 잘라낼 수 있습니다. 변수의 중요성이 특정 임계값 미만(해석 가능성 설정 기반)일 때 기능을 잘라냅니다. 유전자는 대부분의 모델을 위한 정보 획득 변수의 중요성(즉, 모델별 변수의 중요성)을 기반으로 정리합니다. CUML RF와 같은 일부의 경우 Shapley 순열 중요성을 바탕으로 합니다.
Replacement
세대교체가 이 단계에서 이루어지며, 이는 기존 모집단을 새로운 자식 모집단으로 교체하는 단계입니다. 새로운 모집단은 기존 모집단보다 더 높은 적합도 점수로 구성됩니다.
Driverless AI : 최우선 하위 모집단의 유전자(추가, 잘라내기 및 교란), 기능, 모델 하이퍼파라미터를 뮤테이션하여 모집단을 토너먼트 전 크기로 다시 채웁니다.
Termination
교체가 완료된 후 중단 기준을 사용하여 종료를 기초를 제공합니다. 알고리즘은 임계값 적합도 솔루션에 도달한 후 종료됩니다. 모집단에서는 이 솔루션을 최고의 솔루션으로 식별합니다.
Driverless AI : 개체에 점수를 부여하고 중단 기준에 도달하면 진화를 종료하거나 선택 프로세스를 계속합니다.
전체 그림¶
여기에서 Driverless가 데이터 세트에 대한 최고의 파이프라인을 출력하기 위한 실험 중에 순서대로 수행하는 다른 단계의 작업을 자세히 설명합니다.
Accuracy, Time and Interpretabilty knob 설정을 반복 및 구축할 모델의 수로 전환합니다.
Target Tuning 수행: 마주한 문제에 대한 대상 변수의 최고 표현을 찾습니다. 이는 허용되는 간단한 기능 변환 및 모델 매개변수(내부 레시피 풀에서 선택)를 사용하여 모델을 구축(사용 가능한 경우 LightGBM)하고 점수가 가장 높은 대상 변환을 선택하여 달성합니다. 요약 zip 또는 실험 GUI의
target_transform_tuning_leaderboard_simple.json파일은 점수 및 매개변수로 구축한 모델을 나열합니다.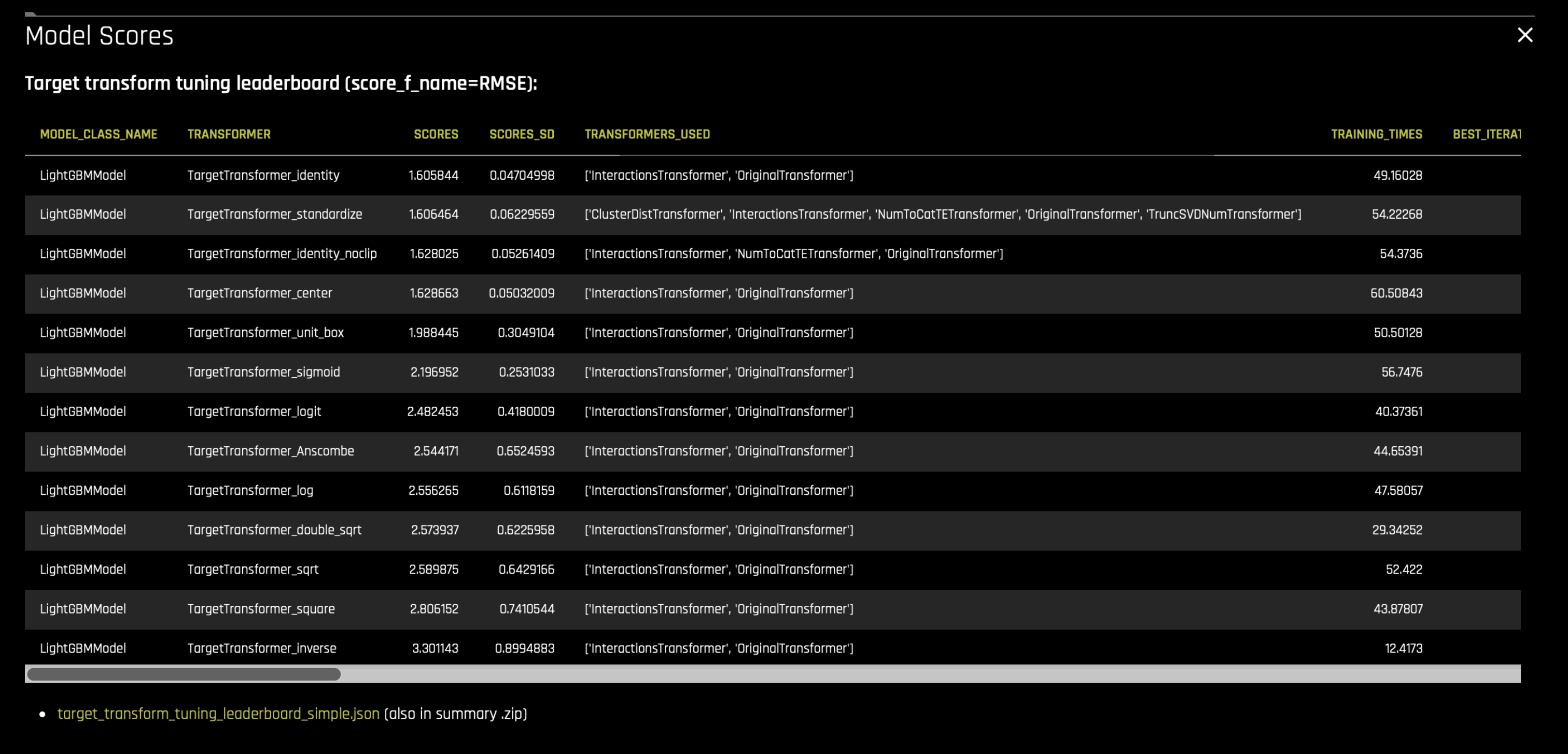
Data Leakage and Shift Detection:
Leakage Detection: 데이터 누출을 감지하기 위해 Driverless AI는 모델(사용 가능한 경우 LightGBM)을 실행하여 변수의 중요성 표(대상 변수에 대한 각 기능의 예측력을 결정함)를 얻습니다. 그 다음 중요한 변수의 중요성을 가진 각 기능에 대해 간단한 모델을 구축합니다. AUC(분류용) 또는 R2 점수(회귀분석)가 높은 모델이 잠재적 누출 기능으로 사용자에게 보고됩니다.
Shift Detection: 훈련, 검증 또는 데이터 세트 시험 간의 분포 변화를 감지하기 위해 Driverless AI는 이항 모델을 훈련하여 행이 속한 데이터 세트를 예측합니다. 즉, 특정한 기능만을 예측 변수로 사용하여 구축한 모델이 AUC가 0.9라고 하는 높은 정확도로 훈련 데이터와 테스트 데이터를 분리할 수 있는 경우 이는 훈련 및 데이터 시험에서 해당 기능의 분포에 드리프트가 있음을 나타냅니다. 이동한 기능은 드롭합니다. 또는 레이블/빈으로 사용하여 더 의미 있는 집계 기능을 만들도록 합니다.
이러한 기능은 사용자에게 알림으로 보고되며 임계값이 설정되면 드롭됩니다.
모델 및 기능 Tuning Phase : 튜닝은 최고의 individuals 를 찾기 위해 무작위로 선택한 매개변수입니다.
Driverless는 다양한 개체 세트를 생성합니다. 먼저 모델(허용된 알고리즘 기반)의 《SEQUENCE》를 생성하고 간단한 기능 변환 및 모델 매개변수로 추가합니다. 이러한 허용된 알고리즘 및 기능 변환은 실험 미리 보기에 표시됩니다. DEFAULT에는 원래 숫자, 날짜, 텍스트 데이터를 위한 tfidf 또는 BERT 임베딩, 대상 인코딩, 빈도 인코딩, 증거 가중치 인코딩, 클러스터링, 상호 작용 등과 같은 단순 유전자가 포함됩니다. 이러한 기본 기능은 단순하먀 MOJO 생성을 지원합니다. 이러한 모델 매개변수 목록 및 기능 변환은 주어진 데이터 세트에 적합하먀 실험 설정에서 허용하는 Driverless AI 전문가 데이터 과학자 레시피에 따라 내부적으로 선택합니다.
그 다음 모집단에 더 많은 개체가 필요한 경우 《RANDOM》 모델을 추가합니다. 이는 SEQUENCE와 동일한 모델 유형(알고리즘)을 갖지만, random hyper parameters and (default + extra) random features 를 얻기 위해 모델에 대해 뮤테이션한 매개변수를 갖습니다.
《GLM ONE HOT ENCODED》 모델을 평가하며, 데이터 세트에서 잘 수행하는 것으로 보이는 경우 개별로 추가합니다.
reference individual 《CONSTANT MODEL” 은 혼합물에 추가되어 최고 상수 예측(입력 데이터와 상관없이 동일한 것을 예측)이 점수를 위해 무엇을 제공할지 알 수 있습니다.
이렇게 diverse population of individuals 를 생성합니다.
모든 개체에 점수를 매깁니다.
모든 튜닝 반복에 대해 개체의 배치(주어진 하드웨어)에 점수를 매깁니다.
더 높은 정확도에서 원래 기능 세트가 다시 생성되고 각 배치가 기능 중요성을 다음 배치로 전달하므로 더 나은 기능을 생성하기 위해 중요성을 exploit 할 수 있습니다.
점수가 매겨진 모든 개체는 기능 변환, 모델 학습, 예측 수행 및 메트릭 채점을 거쳤습니다.
그 다음 tournament 를 개체 사이에서 수행하여 최고의 개인이 evolution phase 로 넘어갈 수 있게 합니다.
《EXTRA_FS》 모델은 《FS》 전략(기능 선택 전략)을 선택하는 경우에 (높은 해석 가능성 설정을 위해) 추가하고, 위의 비참조 개체 중 하나를 replaces 합니다. 이 특별한 개체는 데이터 세트의 permutation importance 을 바탕으로 사전에 잘라내는 기능을 가지고 있습니다.
실험의 튜닝 단계 리더보드에는 모든 최우수 개체가 나열됩니다(예: 토너먼트에서 가장 높은 점수를 받은 모델). 이는 요약 zip 아티팩트에
tuning_leaderboard_simple.json또는 txt 파일로 포함됩니다.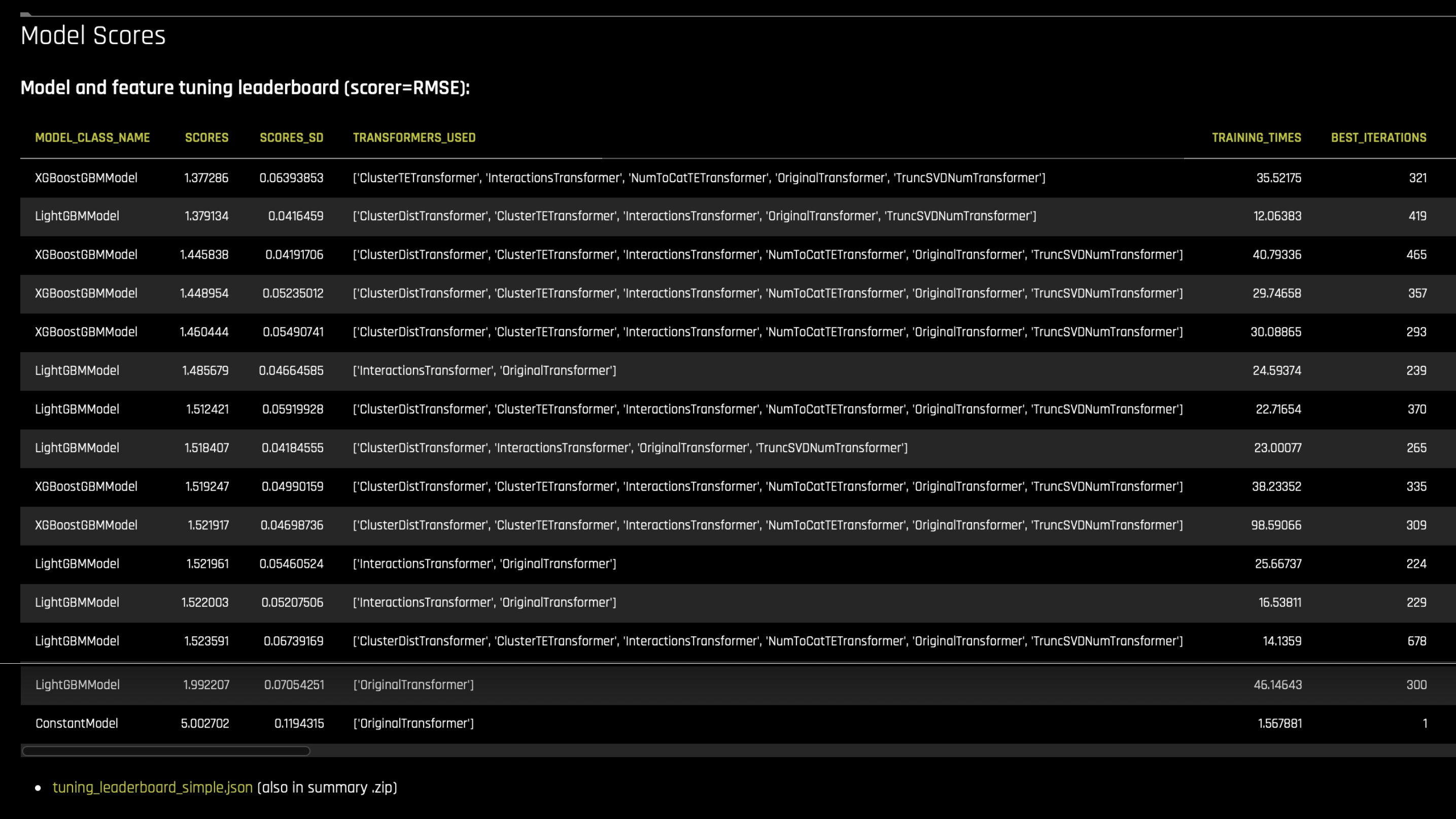
기능 Evolution Phase: 진화는 최고의 individuals 를 찾기 위해 천천히 뮤테이션하는 매개변수 간의 경쟁입니다. 진화 단계 동안 tuning phase 에서 최고의 개체(가장 높은 점수)로 시작합니다. 튜닝 단계 모집단에 필요한 것보다 많거나 적은 개체를 생성할 수 있습니다. 따라서 첫 번째 단계에서는 원하는 모집단 크기를 생성하기 위해 새로운 개체를 잘라내거나 추가합니다.
evolution_begin_leaderboard_simple.json파일에서 이러한 개체가 나열됩니다(점수를 매기지 않 개체는 인구를 올바른 크기로 가져오기 위해 새로 추가된 개체입니다).실험을 반복할 때마다 각 개체는 유전자를 바탕으로 새로운 모델을 생성합니다.
개체의 모집단은 훈련 데이터에 대해 훈련되며 가능한 경우 조기 종료됩니다.
모집단은 주어진 메트릭에 따라 점수가 매겨지며 선택한 경우 부트스트랩을 사용합니다(기본값).
선택한 전략을 바탕으로 개체 사이에서 Tournament 를 수행하여 모집단의 최우수 서브세트를 결정합니다.
최상위 하위 모집단의 유전자, 기능, 모델을 뮤테이션하여 모집단을 토너먼트 전 크기로 다시 채웁니다(무성 번식). 유전 알고리즘에서 뮤테이션에는 유전자를 추가, 잘라내기 또는 교란하는 것이 포함됩니다. 특정한 출력 기능을 잘라낼 수도 있습니다. 유전자를 추가하는 전략은 원래 변수의 중요성에 대한 이용 및 탐색의 균형을 바탕으로 합니다. 중요성이 높은 원래 변수에 대한 추가 변환을 탐색하는 유전자를 추가합니다. 유전자는 대부분의 모델의 경우 정보 획득 변수의 중요성을 바탕으로 잘라내며, CUML RF와 같은 일부 모델의 경우 Shapley 순열 중요성을 바탕으로 잘라냅니다. 변수의 중요성이 특정 임계값(해석 가능성 설정 기반) 아래일 때 기능을 정리합니다. Mutation strategies 를 참조하십시오.
A로 돌아가기
최종 진화 리더보드 모집단은
evolution_end_leaderboard_simple.json파일에 나열되어 있습니다.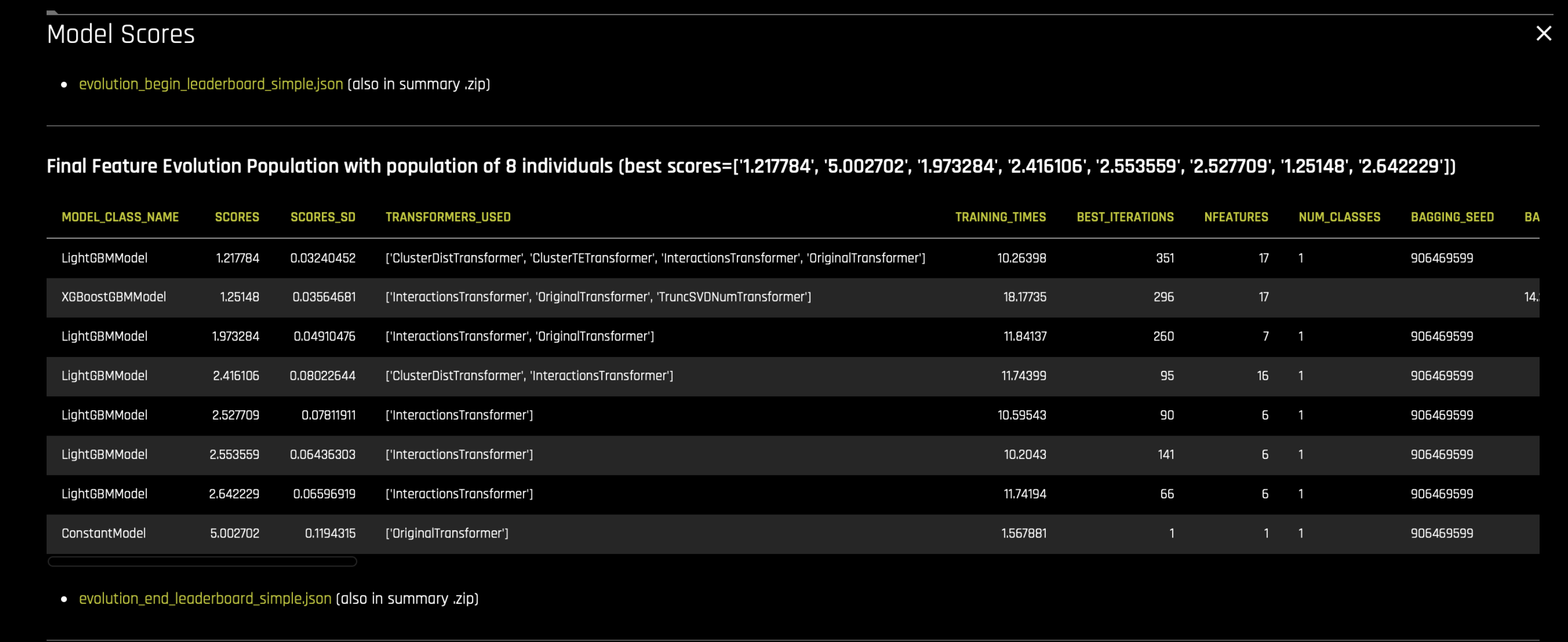
앙상블에 대한 진화 종료 리더보드에서 최종 모델을 선택합니다. 이러한 모델은 요약 zip의
final_leaderboard_simple.json파일에 나열됩니다.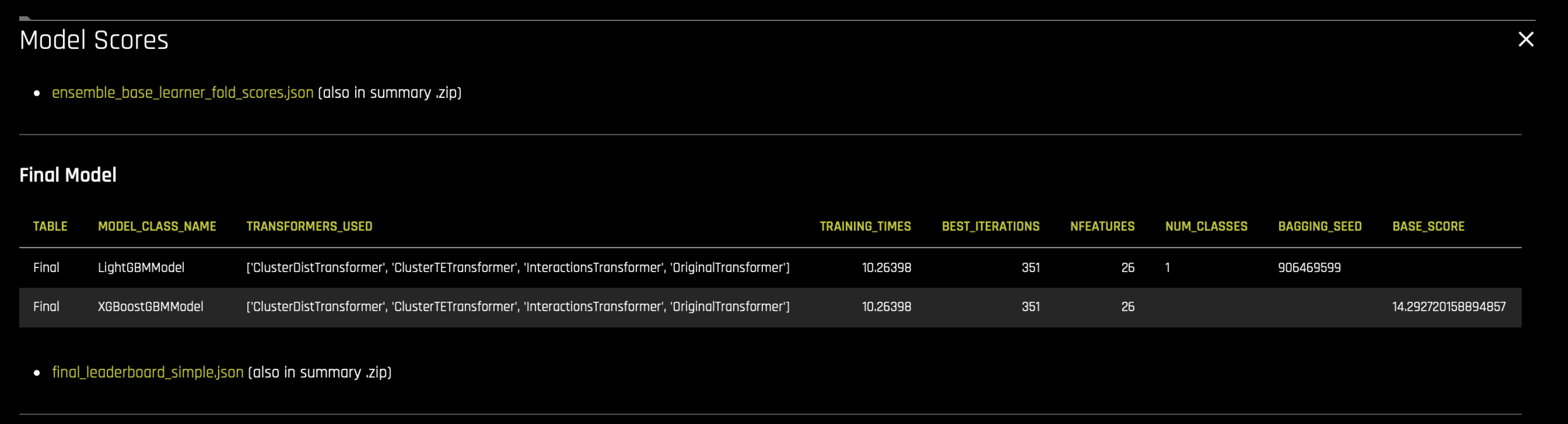
all_leaderboard_simple.json,파일에는 모든 리더보드 모델의 점수와 매개변수, 및 이들이 속한 단계의 전체 여정이 나열됩니다.
앙상블 및 최종 스코어링 파이프라인 생성: MOJO 및/또는 Python scoring pipelines 으로 최종 모델을 앙상블하고 생산용 최종 파이프라인을 구축합니다.
Driverless AI는 스태킹 및 블렌딩 앙상블 기술을 모두 지원합니다. 이는 실험을 시작할 때 ensemble_meta_learner 매개변수를 사용하여 활성화할 수 있습니다. 힐 클라이밍 알고리즘이 있는 선형 블렌더를 사용하여 앙상블의 모델을 위한 블렌딩 비율 또는 가중치를 결정합니다. 그리고 추가 트리 알고리즘을 사용하여 스태킹을 수행합니다. 앙상블에 사용한 가중치 및 기타 매개변수와 최종 모델의 점수기 실험 요약 zip 아카이브의
ensemble_model_description.json및ensemble_scores.json파일에 나열됩니다.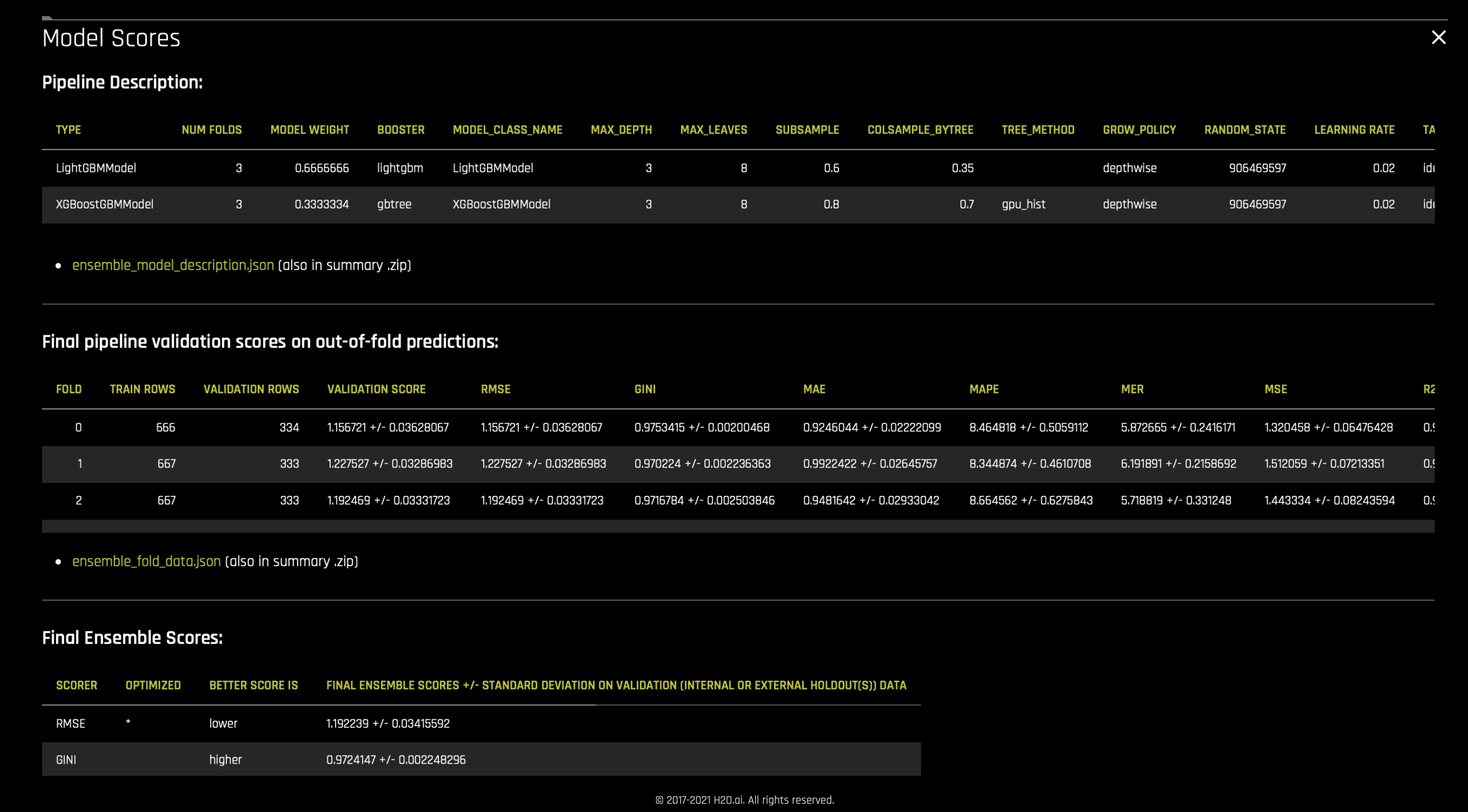
참고:
Feature and Model Tuning leaderboard table 에는 모델의 feature cost 라는 매개변수가 나열됩니다. 기능 비용은 모델에 사용된 기능의 수와 같지 않지만 사용한 변환/적용된 상호 작용/소요된 시간과 같은 복잡성(또는 해석 가능성)을 바탕으로 합니다. 예를 들어 저비용 모델은 고비용 모델보다 해석 가능한 기능을 더 많이 가질 수 있습니다(예: 비용 번호 != 사용된 기능 수). 이 매개변수는 유전 알고리즘 동안 워크 플로우에서 사용되어 실험의 해석 가능성 다이얼 설정에서 주어진 기능 수를 줄여야 하는지를 결정합니다.
Evolution Begin leaderboard table 의 특정 개체에는 점수를 매기지 않습니다. 이는 다음과 같은 경우에 발생할 수 있습니다.
이는 해석 가능성 설정의 주어진 선택을 위해 부과된 기능 수에 대한 일부 제약을 위반하여 변경되었으며 점수가 더 이상 적용되지 않습니다.
이는 모집단의 필요한 총 개체 수를 채우기 위해 마지막에 추가되었기 때문에 아직 점수가 매겨지지 않았습니다.
additional details 도 참고하십시오.
로그 읽기¶
실험 미리보기는 실험의 다양한 단계에서 구축한 반복 횟수 및 총 모델 수(교차 검증 모델 포함)의 추정치를 제공합니다. 예(로그에서) -
here 를 클릭하여 이 예제에서 사용한 샘플 로그를 다운로드하고 확인하십시오.
INFO | Number of individuals: 8
INFO | Estimated target transform tuning iterations: 2
INFO | Estimated model and feature parameter tuning iterations: 4
INFO | Estimated total (tuning + feature evolution) number of iterations: 16
INFO | Estimated total (backend + tuning + feature evolution + final) number of models to train: 598
INFO | Backend tuning: 0 model(s)
INFO | Target transform tuning: 18 model(s)
INFO | Model and feature tuning: 48 model(s)
INFO | Feature pre-pruning: 0 model(s)
INFO | Feature evolution: 528 model(s)
INFO | Final pipeline: 3 model(s)
INFO | ACCURACY [7/10]:
INFO | - Training data size: *1,000 rows, 11 cols*
INFO | - Feature evolution: *LightGBM*, *3-fold CV**, 2 reps*
INFO | - Final pipeline: *LightGBM, averaged across 3-fold CV splits*
INFO |
INFO | TIME [2/10]:
INFO | - Feature evolution: *8 individuals*, up to *10 iterations*
INFO | - Early stopping: After *5* iterations of no improvement
INFO |
INFO | INTERPRETABILITY [8/10]:
INFO | - Feature pre-pruning strategy: Permutation Importance FS
INFO | - Monotonicity constraints: enabled
INFO | - Feature engineering search space: [Interactions, Original]
INFO |
INFO | LightGBM models to train:
INFO | - Target transform tuning: *18*
INFO | - Model and feature tuning: *48*
INFO | - Feature evolution: *528*
INFO | - Final pipeline: *3*
이 실험에서는 LightGBM 모델만을 생성합니다. 나열한 모델 개수 추정치는 각 nfold 모델을 개수로 고려합니다.
이는 회귀분석 문제이므로 대상 튜닝을 수행히고 18개의 모델을 생성하여 데이터 세트에 대한 최상의 target transformation 을 결정합니다. 이렇게 하여 각각 2회 반복, 즉 데이터 세트(학습/유효한 분할)의 2개의 서로 다른 보기가 있는 3폴드 교차 검증을 갖는 3개의 모델을 생성합니다. 이는 두 번 반복하여 수행합니다.
다음 4회 반복은 모델 및 기능 매개변수 튜닝에 사용됩니다. 여기에는 약 8*3*2(개체*폴드*반복)~48개의 모델이 생성됩니다.
튜닝 단계의 출력 모델은 유전 알고리즘에 따른 Feature Evolution 과정을 거칩니다. 유전 알고리즘은 8명의 개체(모집단 크기)에 대해 수행합니다. 다음 10회 반복은 기능 진화에 사용되며 약 (10 * 8/2[모집단 서브세트] * (3*2) (폴드cv*반복)~240개의 새로운 모델에 점수를 매깁니다. 이에 대한 상한은 528개의 모델입니다. 5회 반복 후에도 점수가 향상하지 않는 경우 조기 종료를 수행합니다.
최종 파이프라인은 3폴드 교차 검증으로 단일 개체로 생성됩니다.
이 추정치는 정확성/시간/해석 가능성 다이얼 설정, 선택한 모델 유형 및 실험에 대한 기타 상세 설정을 바탕으로 합니다.
그 후 트랜스포머에서 실험을 위해 탐색 공간을 허용하고 기능이 매핑됩니다.
WARNING| - Feature engineering search space: [CVCatNumEncode, CVTargetEncode, Frequent, Interactions, NumCatTE, OneHotEncoding, Original]
DATA | LightGBMModel *default* feature->transformer map
DATA | X_0 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer', 'InteractionsTransformer']
DATA | X_1 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer', 'InteractionsTransformer']
DATA | X_2 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer']
DATA | X_3 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer']
DATA | X_4 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer']
DATA | X_5 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer']
DATA | X_6 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer']
DATA | X_7 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer']
DATA | X_8 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer']
DATA | X_9 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer']
Validation splits 생성. 데이터 세트가 모델 구축 및 튜닝을 위한 교차 검증 폴드를 생성하기 위해 내부적으로 분할됩니다. 이 예에서는 기능 진화 단계에서 교차 검증을 위한 3개의 폴드가 필요하고 데이터 보기를 수행하는 두 번의 반복이 필요합니다. 최종 파이프라인에 대한 3개의 폴드 cv도 수행합니다. 내부 검증을 위해 데이터 세트를 폴드로 분할한 후, Kolmogorov-Smirnov 통계를 계산하여 폴드가 유사한 데이터 분포를 갖는지 확인합니다.
INFO | Preparing validation splits...
INFO | [Feature evolution (repeat 1)] Optimized fold splits: Target fold mean (target transformed) stddev: 0.01329 | means: [14.346849, 14.358292, 14.362315, 14.327351, 14.342845, 14.366349]
INFO | Kolmogorov-Smirnov statistics for splits of fold 0: KstestResult(statistic=0.02176727625829422, pvalue=0.9998424722802827)
INFO | Kolmogorov-Smirnov statistics for splits of fold 1: KstestResult(statistic=0.025154089621855738, pvalue=0.9981216923269776)
INFO | Kolmogorov-Smirnov statistics for splits of fold 2: KstestResult(statistic=0.02074638356497427, pvalue=0.9999414082418556)
INFO | [Feature evolution (repeat 2)] Optimized fold splits: Target fold mean (target transformed) stddev: 0.01793 | means: [14.3447695, 14.362441, 14.366518, 14.318932, 14.340719, 14.370607]
INFO | Kolmogorov-Smirnov statistics for splits of fold 0: KstestResult(statistic=0.024698351045656434, pvalue=0.9985813106473687)
INFO | Kolmogorov-Smirnov statistics for splits of fold 1: KstestResult(statistic=0.027531279405342373, pvalue=0.9937850958604381)
INFO | Kolmogorov-Smirnov statistics for splits of fold 2: KstestResult(statistic=0.02358730544637591, pvalue=0.9993204937887651)
INFO | [Final pipeline ] Optimized fold splits: Target fold mean (target transformed) stddev: 0.01329 | means: [14.346849, 14.358292, 14.362315, 14.327351, 14.342845, 14.366349]
INFO | Kolmogorov-Smirnov statistics for splits of fold 0: KstestResult(statistic=0.02176727625829422, pvalue=0.9998424722802827)
INFO | Kolmogorov-Smirnov statistics for splits of fold 1: KstestResult(statistic=0.025154089621855738, pvalue=0.9981216923269776)
INFO | Kolmogorov-Smirnov statistics for splits of fold 2: KstestResult(statistic=0.02074638356497427, pvalue=0.9999414082418556)
INFO | Feature engineering training / validation splits:
INFO | split #1: 666 / 334 - target min -1.264726 / 0.766517, target mean: 14.346850 / 14.358292, target max: 27.710434 / 26.761804, target std: 4.981032 / 5.059986
INFO | split #2: 667 / 333 - target min -1.264726 / 2.914631, target mean: 14.362315 / 14.327350, target max: 26.761804 / 27.710434, target std: 4.999868 / 5.022746
INFO | split #3: 667 / 333 - target min 0.766517 / -1.264726, target mean: 14.342844 / 14.366349, target max: 27.710434 / 25.879954, target std: 5.037666 / 4.946448
INFO | split #4: 666 / 334 - target min -1.264726 / 1.490552, target mean: 14.344769 / 14.362441, target max: 27.710434 / 25.997716, target std: 5.026847 / 4.968671
INFO | split #5: 667 / 333 - target min -1.264726 / 1.101135, target mean: 14.366518 / 14.318931, target max: 26.492384 / 27.710434, target std: 4.981698 / 5.058766
INFO | split #6: 667 / 333 - target min 1.101135 / -1.264726, target mean: 14.340719 / 14.370606, target max: 27.710434 / 26.492384, target std: 5.010135 / 5.002203
INFO | Doing backend tuning on data of shape (666, 11) / (334, 11)
INFO | Maximum number of rows (train or valid) for feature evolution: 667
INFO | Final ensemble training / validation splits:
INFO | split #1: 666 / 334 - target min -1.264726 / 0.766517, target mean: 14.346850 / 14.358292, target max: 27.710434 / 26.761804, target std: 4.981032 / 5.059986
INFO | split #2: 667 / 333 - target min -1.264726 / 2.914631, target mean: 14.362315 / 14.327350, target max: 26.761804 / 27.710434, target std: 4.999868 / 5.022746
INFO | split #3: 667 / 333 - target min 0.766517 / -1.264726, target mean: 14.342844 / 14.366349, target max: 27.710434 / 25.879954, target std: 5.037666 / 4.946448
INFO | Maximum number of rows (train or valid) for final model/ensemble: 667
변형 및 적용 가능한 유전자, 기능 진화를 위한 유전 알고리즘에 대한 tournament style 이 등록되어 있습니다.
INFO | Transformers used (accuracy=7, time=2, interpretability=8, num_classes=1): ['InteractionsTransformer', 'OriginalTransformer']
INFO | Genes used (accuracy=7, time=2, interpretability=8, num_classes=1): ['InteractionsGene', 'OriginalGene']
INFO | Tournament style: model
Backend tuning 작업을 실행하여 모든 것이 예상대로 작동하는지 확인합니다.
INFO | Auto-tuning modeling backend: start.
INFO | Backend candidate Job# 0 Name: LightGBMModel using GPU (if applicable) with Booster: lightgbm
INFO | Backend candidate Job# 1 Name: LightGBMModel using CPU with Booster: lightgbm
...
INFO | Auto-tuning modeling backend: end : Duration: 299.8936 s
Leakage detection 모델을 실행하여 대상에 대한 각 기능의 예측력을 결정합니다. 그 다음 중요한 변수의 중요성을 가진 각 기능에 대해 간단한 모델을 구축합니다. AUC(분류용) 또는 R2 점수(회귀분석)가 높은 모델이 잠재적 누출 기능으로 사용자에게 보고됩니다.
INFO | Checking for leakage...
...
INFO | Time for leakage check for training and None: 30.6861 [secs]
INFO | No significant leakage detected in training data ( R2: 0.7957284 )
목표 변수의 최적 분포(로그, 단위 상자, 제곱근 등)를 찾기 위해 회귀 문제에 대한 대상 튜닝을 수행하여 스코어러에 최적화합니다. 2번의 반복에서 6폴드 교차 검증을 하는 3개의 모델입니다. 각 모델은 다른 대상 변환을 시도합니다.
INFO | Tuned 18/18 target transform tuning models. Tuned [LIGHTGBM] Tuning []
INFO | Target transform search: end : Duration: 389.6202 s
INFO | Target transform: TargetTransformer_identity_noclip
Parameter and feature tuning stage 는 3번째 반복부터 시작하며 48개의 모델(8*3*2)을 구축하는 데 4회의 반복이 소요됩니다.
8개의 개체를 구축하고 모델에 포함된 기능이 해석 가능성 조건을 충족하는지 확인합니다(nfeatures_max 및 ngenes_max 참조). 또한 6번째 반복 동안 추가 FS 개체를 추가합니다. tuning phase 를 참고하십시오. 따라서 이 단계에서 48개의 모델 이상을 구축합니다.
INFO | Model and feature tuning scores (RMSE, less is better):
INFO | Individual 0 : 1.638517 +/- 0.04910973 [Tournament: 1.638517 Model: LIGHTGBM Feature Cost: 17]
INFO | Individual 1 : 1.638517 +/- 0.04910973 [Tournament: 1.638517 Model: LIGHTGBM Feature Cost: 17]
INFO | Individual 2 : 1.638517 +/- 0.04910973 [Tournament: 1.638517 Model: LIGHTGBM Feature Cost: 17]
INFO | Individual 3 : 1.643672 +/- 0.06142867 [Tournament: 1.643672 Model: LIGHTGBM Feature Cost: 14]
INFO | Individual 4 : 1.66976 +/- 0.04171555 [Tournament: 1.66976 Model: LIGHTGBM Feature Cost: 13]
INFO | Individual 5 : 1.683212 +/- 0.06572724 [Tournament: 1.683212 Model: LIGHTGBM Feature Cost: 14]
INFO | Individual 6 : 1.690918 +/- 0.05417363 [Tournament: 1.690918 Model: LIGHTGBM Feature Cost: 16]
INFO | Individual 7 : 1.692052 +/- 0.04037833 [Tournament: 1.692052 Model: LIGHTGBM Feature Cost: 17]
INFO | Individual 8 : 2.080228 +/- 0.03523514 [Tournament: 2.080228 Model: LIGHTGBM Feature Cost: 13]
INFO | Applying nfeatures_max and ngenes_max limits to tuning population
INFO | Parameter tuning: end : Duration: 634.5521 s
INFO | Prepare Feature Evolution
INFO | Feature evolution has 0 brain cached individuals out of 8 individuals
INFO | Making 1 new individuals during preparation for evolution
INFO | Pre-pruning 1 gene(s) from 12 active base genes
INFO | Starting search for statistically relevant features (FS scheme)
INFO | FS Permute population of size 1 has 2 unique transformations that include: ['InteractionsTransformer', 'OriginalTransformer']
INFO | Transforming FS train
INFO | Using 2 parallel workers (1 parent workers) for fit_transform.
INFO | Submitted 2 and Completed 2 non-identity feature engineering tasks out of 12 total tasks (including 10 identity)
INFO | Transforming FS valid
INFO | Submitted 2 and Completed 2 non-identity feature engineering tasks out of 12 total tasks (including 10 identity)
INFO | 10 features created during FS Permute
INFO | Using model LIGHTGBM for FS
유전 알고리즘을 사용하는 Feature evolution 은 7번째 반복에서 시작하며 다음 10회 반복에 대한 각 반복에서 대략 (8/2)(하위 모집단) *(3*2) = 24개의 새로운 모델에 점수를 매깁니다.
16회 반복 종료 시 실험이 수렴되지 않아 기능 진화가 중단되었습니다. 모델에 포함된 기능이 해석 조건을 충족하고 최대 허용 한계보다 작은지 확인합니다 (nfeatures_max 및 ngenes_max 참조). 최고 개체 및 모집단은 Driverless AI 두뇌에 저장되어 실험을 다시 시작하거나 재조정합니다. 최고 개체는 다음 단계를 진행합니다.
INFO | Scored 283/310 models on 31 features. Last Scored [LIGHTGBM]
INFO | Scores (RMSE, less is better):
INFO | Individual 0 : 1.540669 +/- 0.07447481 [Tournament: 1.540669 Model: LIGHTGBM Feature Cost: 10]
INFO | Individual 1 : 1.541396 +/- 0.07796533 [Tournament: 1.541396 Model: LIGHTGBM Feature Cost: 9]
INFO | Individual 2 : 1.542085 +/- 0.07796533 [Tournament: 1.542085 Model: LIGHTGBM Feature Cost: 9]
INFO | Individual 3 : 1.543484 +/- 0.07796533 [Tournament: 1.543484 Model: LIGHTGBM Feature Cost: 9]
INFO | Individual 4 : 1.547386 +/- 0.08567484 [Tournament: 1.547386 Model: LIGHTGBM Feature Cost: 10]
INFO | Individual 5 : 1.557151 +/- 0.08078833 [Tournament: 1.557151 Model: LIGHTGBM Feature Cost: 8]
INFO | Individual 6 : 3.961817 +/- 0.08480774 [Tournament: 3.961817 Model: LIGHTGBM Feature Cost: 4]
INFO | Individual 7 : 4.052189 +/- 0.05662354 [Tournament: 4.052189 Model: LIGHTGBM Feature Cost: 1]
INFO | Best individual with LIGHTGBM model has 7 transformers creating 10 total features and 10 features for model: 1.540669 RMSE
DATA | Top 10 variable importances of best individual:
DATA | LInteraction LGain
DATA | 0 3_X_3 1.000000
DATA | 1 10_InteractionMul:X_0:X_1 0.570066
DATA | 2 4_X_4 0.264919
DATA | 3 10_InteractionAdd:X_0:X_1 0.225805
DATA | 4 2_X_2 0.183059
DATA | 5 0_X_0 0.130161
DATA | 6 1_X_1 0.124281
DATA | 7 10_InteractionDiv:X_0:X_1 0.032255
DATA | 8 10_InteractionSub:X_0:X_1 0.013721
DATA | 9 7_X_7 0.007424
INFO | Experiment has not yet converged after 16 iteration(s). Last few scores: ['1.63849', '1.63852', '1.63852', '1.61909', '1.61909', '1.56956', '1.56956', '1.54208', '1.54208', '1.54067', '1.54067', '1.54067']
INFO | Completed all expected evolution iterations: 17
INFO | Final Feature Evolution Population with population of 8 individuals (best scores=['1.547386', '1.540669', '4.052189', '1.557151', '1.542085', '3.961817', '1.541396', '1.543484'])
...
INFO | Applying nfeatures_max and ngenes_max limits to final individual 0 layer 0
INFO | Applying nfeatures_max and ngenes_max limits to final individual 1 layer 0
INFO | Applying nfeatures_max and ngenes_max limits to final individual 2 layer 0
INFO | Applying nfeatures_max and ngenes_max limits to final individual 3 layer 0
INFO | Applying nfeatures_max and ngenes_max limits to final individual 4 layer 0
INFO | Applying nfeatures_max and ngenes_max limits to final individual 5 layer 0
INFO | Applying nfeatures_max and ngenes_max limits to final individual 6 layer 0
INFO | Applying nfeatures_max and ngenes_max limits to final individual 7 layer 0
INFO | Exporting best individual pickle /opt/h2oai/dai/tmp/n/h2oai_experiment_59939c96-0150-11ec-a7e1-0242c0a8fe02/best_individual.pickle
INFO | Exporting best population for model-feature caching to /opt/h2oai/dai/tmp/n/h2oai_experiment_59939c96-0150-11ec-a7e1-0242c0a8fe02/best_population.pickle
INFO | Final population size before sampling: 8. After sampling expected population size: 1.
INFO | Final population size after sampling: 1 (0 reference) with models_final=3 and num_ensemble_folds=3
INFO | Final Model sampled population with population of 8 individuals (best scores=['1.540669'])
반복 17에서는 최종 ensemble 모델에 대한 3폴드 교차 검증을 수행하고, 사용한 기능에 대한 몇 가지 검사를 수행하며, 예측과 python 및 MOJO scoring pipelines 이 생성됩니다. 로그 및 요약 artifacts 가 수집됩니다.
INFO | Completed 3/3 final ensemble models.
INFO | Model performance:
INFO | fold: 0, model name: LightGBM, model iterations: 500, model transformed features: 10, total model time: 2.4198, fit+predict model time: 0.376, total pipeline time: 0.48786, fit pipeline time: 0.29738
INFO | fold: 1, model name: LightGBM, model iterations: 500, model transformed features: 10, total model time: 3.343, fit+predict model time: 0.34681, total pipeline time: 0.43664, fit pipeline time: 0.24267
INFO | fold: 2, model name: LightGBM, model iterations: 473, model transformed features: 10, total model time: 2.1446, fit+predict model time: 0.38534, total pipeline time: 0.41979, fit pipeline time: 0.23152
INFO | Checking for shift in tuning model -> final model variable importances
DATA | New features created only in final pipeline: Count: 0 List: []
DATA | Extra features created in final pipeline compared to genetic algorithm population: Count: 0 List: []
DATA | Missing features from final StackedEnsemble pipeline compared to genetic algorithm population: Count: 0 List: []
INFO | Completed training of the final scoring pipeline
INFO | Predictions and Scoring final pipeline...
INFO | Scored 286/310 models on 31 features. Last Scored []
...
INFO | Experiment: buvobamu (59939c96-0150-11ec-a7e1-0242c0a8fe02)
INFO | Version: 1.10.0, 2021-08-20 01:48
INFO | Settings: 7/2/8, seed=1037348886, GPUs enabled
INFO | Train data: [XXXXX] (1000, 11)
INFO | Validation data: N/A
INFO | Test data: N/A
INFO | Target column: [XXXXX] (regression, identity_noclip-transformed)
INFO | System specs: Docker/Linux, 252 GB, 40 CPU cores, 2/2 GPUs
INFO | Max memory usage: 0.849 GB, 0.279 GB GPU
INFO | Recipe: AutoDL (16 iterations, 8 individuals)
INFO | Validation scheme: random, 6 internal holdouts (3-fold CV)
INFO | Feature engineering: 31 features scored (10 selected)
INFO | Timing: MOJO latency 0.0571 millis (512.7kB), Python latency 110.0896 millis (1.1GB)
INFO | Data preparation: 310.14 secs
INFO | Shift/Leakage detection: 30.75 secs
INFO | Model and feature tuning: 1027.26 secs (61 of 66 models trained)
INFO | Feature evolution: 2102.52 secs (222 of 528 models trained)
INFO | Final pipeline training: 17.77 secs (3 models trained)
INFO | Python / MOJO scorer building: 49.86 secs / 19.75 secs
INFO | Validation score: RMSE = 5.002508 (constant preds of 14.35)
INFO | Validation score: RMSE = 1.638517 +/- 0.04910973 (baseline)
INFO | Validation score: RMSE = 1.543872 +/- 0.04469455 (final pipeline)
INFO | Test score: RMSE = N/A
INFO |
INFO |
INFO | Final validation scores (internal holdout, bootstrap on folds) +/- stddev:
INFO | optimized: RMSE = 1.543872 +/- 0.04469455 (less is better)
INFO | GINI = 0.9528597 +/- 0.001413133 (more is better)
INFO | MAE = 1.148299 +/- 0.02813014 (less is better)
...
INFO |
2021-08-20 01:48:09,475 C: 14% D:935.5GB M:249.9GB NODE:LOCAL1 7646 INFO | Collecting logs
추가 정보¶
Upfront Feature Selection: 실험 설정에 따라 기능 축소를 모든 모델에 적용할 수 있거나 유전 알고리즘 시작 전에 원래 열이 축소된 하나의 특수 FS(기능 선택) 개체를 추가할 수 있습니다.all models 의 기능 수 감축은 다음 중 하나를 충족하는 경우에만 적용됩니다.
열의 개수가 max_orig_cols_selected 보다 큰 경우, 또는
숫자가 아닌 열의 개수가 max_orig_nonnumeric_cols_selected보다 큰 경우, 또는
열의 개수가 max_orig_numeric_cols_selected 보다 큰 경우
모든 모델에 대한 위의 요구 사항이 충족되지 않는 경우 FS individual (EXTRA_FS)에 대한 기능 수 감축(아래 중 하나가 충족되는 경우)에만 적용됩니다.
열의 개수가 fs_orig_cols_selected 보다 큰 경우, 또는
숫자가 아닌 열의 개수가 fs_orig_numeric_cols_selected보다 큰 경우, 또는
열의 개수가 fs_orig_nonnumeric_cols_selected 보다 큰 경우
tuning phase 및 permutation importance 를 참고하십시오.
Tuning Phase Model Origins:SEQUENCE 및 DefaultIndiv: 기능 변환 및 모델 하이퍼 매개변수를 내부 독점 데이터 과학 레시피에서 제안한 대로 기본 변환 세트 및 매개변수 목록에서 무작위로 선택합니다. 이 세트는 단순하며 파이프라인 생산을 위한 MOJO 생성을 지원합니다.
RANDOM으로서의 model_origin은 기능 및 모델 하이퍼 매개변수가 모두 뮤테이션 목록 또는 기능을 호출할 수 있게 합니다.
EXTRA_FS로서의 model_origin은 순열 중요성 기반 기능 선택(Feature Selection, FS)를 통해 추가된 추가 개체를 위한 것입니다.
REF_#로서의 model_origin은 기준으로 제공된 참조 개체를 나타냅니다(예: 상수 모델).
GLM_OHE로서의 model_origin은 GLM + OHE에 의해 생성된 기능을 나타냅니다.
Driverless AI Brain: 실험을 구축하는 동안 두뇌는 최고의 반복, 매개변수, 모델, 유전자 및 모집단을 캐시에 저장합니다. 이는 정보에 입각한 조회, 뮤테이션 중 교차, restarts and refits 에 사용됩니다. 관련 정보는 feature_brain_level 을 참조하십시오.Mutation strategy: transformers 에 대한 뮤테이션을 수행할 때 적용하는 전략:샘플 모드가 기본이며 트랜스포머 매개변수를 샘플링하는 경향이 있습니다.
일괄 처리 모드는 같은 변환의 여러 유형을 함께 수행하는 경향이 있습니다.
전체 모드는 더 많은 유형의 같은 변환을 함께 수행합니다.
다른 관련 상세 설정은 다음과 같습니다. 트랜스포머를 추가하는 확률(prob_add_genes), 최고의 공유 트랜스포머를 추가하는 확률(prob_addbest_genes), 트랜스포머를 잘라내는 확률(prob_prune_genes), 모델 매개변수를 뮤테이션하는 확률(prob_perturb_xgb), 약한 기능을 잘라내는 확률(prob_prune_by_features). 기본 Driverless AI 설정은 대부분의 경우 가장 잘 수행되며 이러한 설정은 기본값으로 두어야 합니다.
Mutation via custom recipe: 사용자는 자신만의 맞춤형 파이썬 코드를 작성하고 내장된 Driverless AI 유전 알고리즘에 연결하여 자신의 뮤테이션 전략 및 뮤테이션할 매개변수 목록을 제어하고 지정할 수 있습니다. 여기에 그러한 레시피의 example 이 있습니다.get_one함수는 해당 매개변수에 대한 값 목록을 유전 알고리즘 또는 Optuna에 전달합니다. custom recipies 를 작성하는 데 도움이 더 필요한 경우 support@h2o.ai 로 연락해주십시오.Optuna: Driverless AI는 실험의 Tuning phase 동안 모델 하이퍼파라미터 튜닝을 위한 Optuna 를 지원합니다. Optuna는 하이퍼파라미터 최적화를 위해 Tree-structured Parzen Estimator라는 베이지안 최적화 알고리즘을 사용합니다. 관련 정보는 enable_genetic_algorithm 및 tournament_style 을 참조하십시오. 그 후 Optuna를 선택하면 모델 하이퍼파라미터가 Optuna 로 튜닝되고 유전 알고리즘이 변수 가공에 사용됩니다. 베이지안 최적화는 데이터의 구조를 이용합니다. Optuna가 베이지안 기법을 사용하므로 검색 공간 매우 복잡하지 않을 때 사용하는 것을 권장합니다. here 에서 시작하는 Optuna 대한 토글 가능한 매개변수 목록을 참조하십시오.Leaderboard: 실험을 구축하는 동안 Driverless에게 간단하고 복잡한 모델을 즉시 구축하기 위해 다양한 접근 방식을 시도하는 다양한 실험을 구축하도록 지시할 수 있습니다.