Driverless AI: Credit Card Demo
This notebook provides an H2OAI Client workflow, of model building and scoring, that parallels the Driverless AI workflow.
Here is the Python Client Documentation.

Workflow Steps
Build an Experiment with Python API:
Sign in
Import train & test set/new data
Specify experiment parameters
Launch Experiment
Examine Experiment
Download Predictions
Build an Experiment in Web UI and Access Through Python:
Get pointer to experiment
Score on New Data:
Score on new data with H2OAI model
Model Diagnostics on New Data:
Run model diagnostics on new data with H2O AI model
Run Model Interpretation
Run model interpretation on the raw features
Run Model Interpretation on External Model Predictions
Build Scoring Pipelines
Build Python Scoring Pipeline
Build MOJO Scoring Pipeline
Build an Experiment with Python API
1. Sign In
Import the required modules and log in.
Pass in your credentials through the Client class which creates an authentication token to send to the Driverless AI Server. In plain English: to sign into the Driverless AI web page (which then sends requests to the Driverless Server), instantiate the Client class with your Driverless AI address and login credentials.
[2]:
import driverlessai
import matplotlib.pyplot as plt
import pandas as pd
[3]:
address = 'http://ip_where_driverless_is_running:12345'
username = 'username'
password = 'password'
dai = driverlessai.Client(address = address, username = username, password = password)
# make sure to use the same user name and password when signing in through the GUI
2. Upload Datasets
Upload training and testing datasets from the Driverless AI /data folder.
You can provide a training, validation, and testing dataset for an experiment. The validation and testing dataset are optional. In this example, we will provide only training and testing.
[4]:
train_path = 's3://h2o-public-test-data/smalldata/creditcard/CreditCard_Cat-train.csv'
test_path = 's3://h2o-public-test-data/smalldata/creditcard/CreditCard_Cat-test.csv'
train = dai.datasets.create(data=train_path, data_source='s3')
test = dai.datasets.create(data=test_path, data_source='s3')
Complete 100.00% - [4/4] Computing column statistics
Complete 100.00% - [4/4] Computing column statistics
Equivalent Steps in Driverless: Uploading Train & Test CSV Files

3. Set Experiment Parameters
We will now set the parameters of our experiment. Some of the parameters include:
Target Column: The column we are trying to predict.
Dropped Columns: The columns we do not want to use as predictors such as ID columns, columns with data leakage, etc.
Weight Column: The column that indicates the per row observation weights. If
None, each row will have an observation weight of 1.Fold Column: The column that indicates the fold. If
None, the folds will be determined by Driverless AI.Is Time Series: Whether or not the experiment is a time-series use case.
For information on the experiment settings, refer to the Experiment Settings.
For this example, we will be predicting ``default payment next month``. The parameters that control the experiment process are: accuracy, time, and interpretability. We can use the get_experiment_preview_sync function to get a sense of what will happen during the experiment.
We will start out by seeing what the experiment will look like with accuracy, time, and interpretability all set to 5.
[5]:
target = "DEFAULT_PAYMENT_NEXT_MONTH"
exp_preview = dai.experiments.preview(train_dataset=train,
task='classification',
target_column=target,
accuracy=5,
time=5,
interpretability=5,
config_overrides=None)
exp_preview
ACCURACY [5/10]:
- Training data size: *23,999 rows, 25 cols*
- Feature evolution: *[Constant, LightGBM, XGBoostGBM]*, *1/4 validation split*
- Final pipeline: *Ensemble (8 models), 4-fold CV*
TIME [5/10]:
- Feature evolution: *4 individuals*, up to *66 iterations*
- Early stopping: After *10* iterations of no improvement
INTERPRETABILITY [5/10]:
- Feature pre-pruning strategy: None
- Monotonicity constraints: disabled
- Feature engineering search space: [CVCatNumEncode, CVTargetEncode, CatOriginal, Cat, ClusterDist, ClusterTE, Frequent, Interactions, NumCatTE, NumToCatTE, NumToCatWoE, Original, TextLinModel, Text, TruncSVDNum, WeightOfEvidence]
[Constant, LightGBM, XGBoostGBM] models to train:
- Model and feature tuning: *16*
- Feature evolution: *104*
- Final pipeline: *8*
Estimated runtime: *minutes*
Auto-click Finish/Abort if not done in: *1 day*/*7 days*
With these settings, the Driverless AI experiment will train about 124 models: * 16 for model and feature tuning * 104 for feature evolution * 8 for the final pipeline
When we start the experiment, we can either:
specify parameters
use Driverless AI to suggest parameters
Driverless AI can suggest the parameters based on the dataset and target column. Below we will use the ``get_experiment_tuning_suggestion`` to see what settings Driverless AI suggests.
Driverless AI has found that the best parameters are to set ``accuracy = 5``, ``time = 4``, ``interpretability = 6``. It has selected ``AUC`` as the scorer (this is the default scorer for binomial problems).
Equivalent Steps in Driverless: Set the Knobs, Configuration & Launch
4. Launch Experiment: Feature Engineering + Final Model Training
Launch the experiment using the parameters that Driverless AI suggested along with the testset, scorer, and seed that were added. We can launch the experiment with the suggested parameters or create our own.
[7]:
ex = dai.experiments.create(train_dataset=train,
test_dataset=test,
target_column=target,
task='classification',
accuracy=5,
time=4,
interpretability=6,
scorer="AUC")
Experiment launched at: http://localhost:12345/#experiment?key=b7aba0d4-e235-11ea-9088-0242ac110002
Complete 100.00% - Status: Complete
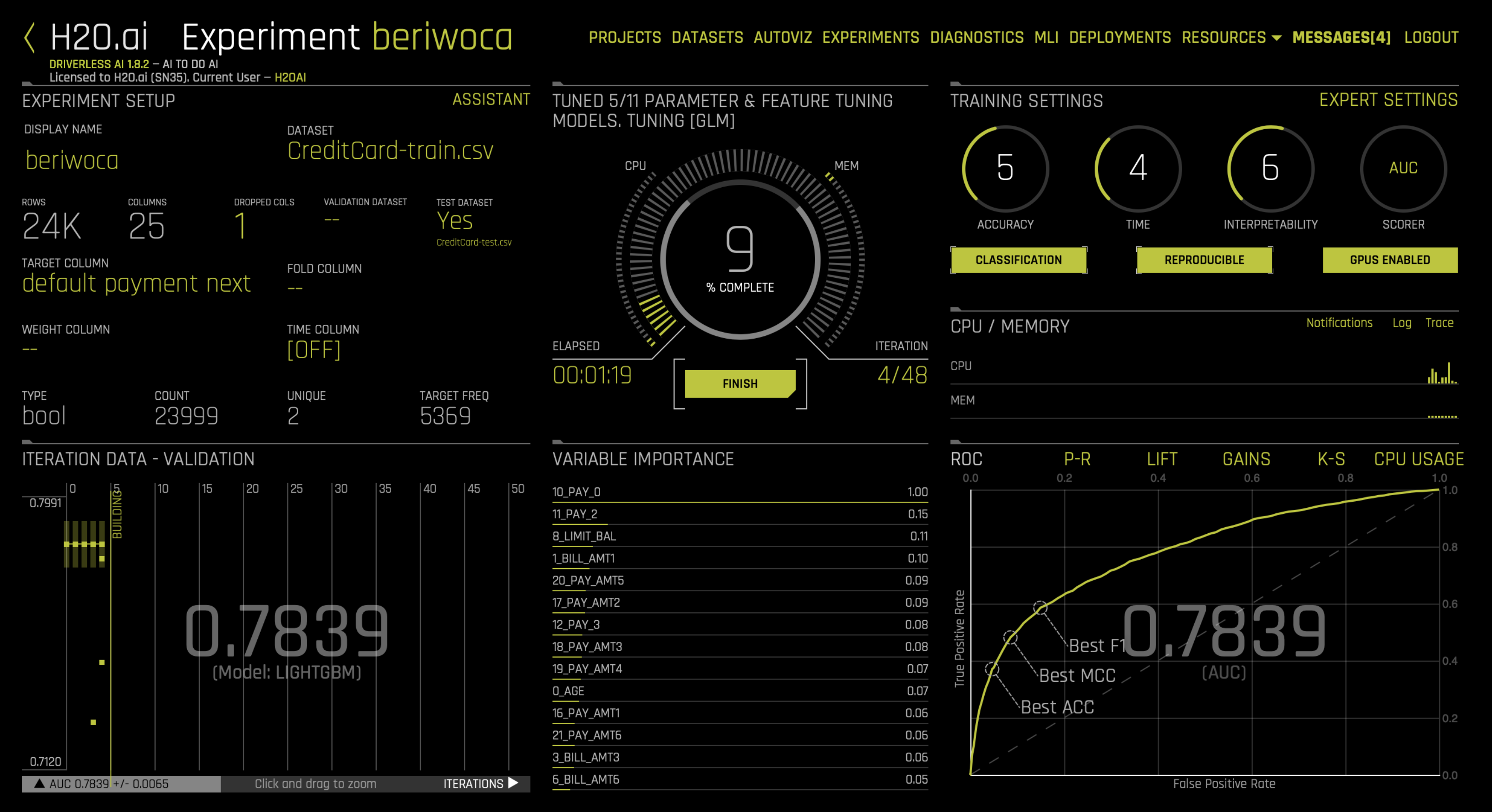
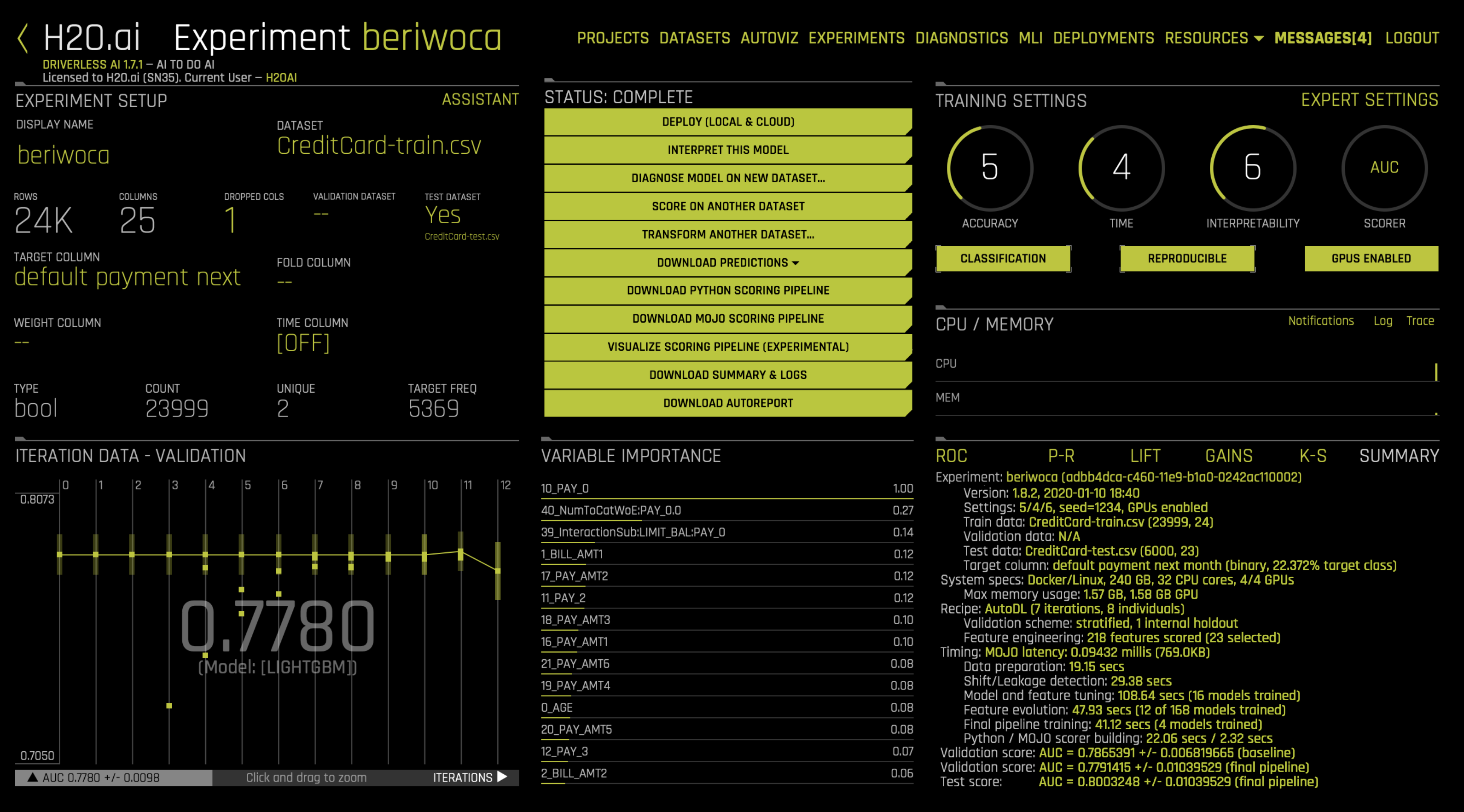
5. Examine Experiment
View the final model score for the validation datasets. When feature engineering is complete, an ensemble model can be built depending on the accuracy setting. The experiment object also contains the score on the validation and test data for this ensemble model. In this case, the validation score is the score on the training cross-validation predictions.
[11]:
metrics = ex.metrics()
print("Final model Score on Validation Data: " + str(round(metrics['val_score'], 3)))
Final model Score on Validation Data: 0.774
6. Download Results
Once an experiment is complete, we can see that the UI presents us options of downloading the:
predictions
on the (holdout) train data
on the test data
experiment summary - summary of the experiment including feature importance
We will show an example of downloading the test predictions below. Note that equivalent commands can also be run for downloading the train (holdout) predictions.
[12]:
ex.artifacts.download(only=['test_predictions'], dst_dir='', overwrite=True,)
Downloaded 'test_preds.csv'
[12]:
{'test_predictions': 'test_preds.csv'}
[13]:
test_preds = pd.read_csv("./test_preds.csv")
test_preds.head()
[13]:
| DEFAULT_PAYMENT_NEXT_MONTH.0 | DEFAULT_PAYMENT_NEXT_MONTH.1 | |
|---|---|---|
| 0 | 0.299739 | 0.700261 |
| 1 | 0.862815 | 0.137185 |
| 2 | 0.958172 | 0.041828 |
| 3 | 0.599148 | 0.400852 |
| 4 | 0.882068 | 0.117932 |
Build an Experiment in Web UI and Access Through Python
It is also possible to use the Python API to examine an experiment that was started through the Web UI using the experiment key.
1. Get pointer to experiment
You can get a pointer to the experiment by referencing the experiment key in the Web UI.
[14]:
# Get list of experiments
experiment_list = dai.experiments.list()
experiment_list
[14]:
[<class 'driverlessai._experiments.Experiment'> b7aba0d4-e235-11ea-9088-0242ac110002 nivufeke,
<class 'driverlessai._experiments.Experiment'> aed84080-e234-11ea-9088-0242ac110002 sewateru]
[12]:
# Get pointer to experiment
exp = experiment_list[0]
exp
Score on New Data
You can use the Python API to score on new data. This is equivalent to the SCORE ON ANOTHER DATASET button in the Web UI. The example below scores on the test data and then downloads the predictions.
Pass in any dataset that has the same columns as the original training set. If you passed a test set during the H2OAI model building step, the predictions already exist.
1. Score Using the H2OAI Model
The following shows the predicted probability of default for each record in the test.
[15]:
# Get unlabeled data to make predictions on
data = dai.datasets.create(data='s3://h2o-public-test-data/smalldata/creditcard/CreditCard_Cat-test.csv',
data_source='s3',
force=True)
target = "DEFAULT_PAYMENT_NEXT_MONTH"
prediction = ex.predict(data, [target])
pred_path = prediction.download('.')
pred_table = pd.read_csv(pred_path)
pred_table.head()
Complete 100.00% - [4/4] Computing column statistics
Complete
Downloaded './b7aba0d4-e235-11ea-9088-0242ac110002_preds_01963cda.csv'
[15]:
| DEFAULT_PAYMENT_NEXT_MONTH.0 | DEFAULT_PAYMENT_NEXT_MONTH.1 | |
|---|---|---|
| 0 | 0.299739 | 0.700261 |
| 1 | 0.862815 | 0.137185 |
| 2 | 0.958172 | 0.041828 |
| 3 | 0.599148 | 0.400852 |
| 4 | 0.882068 | 0.117932 |
We can also get the contribution each feature had to the final prediction by setting pred_contribs = True. This will give us an idea of how each feature effects the predictions.
[16]:
prediction = ex.predict(data, [target], include_shap_values=True)
pred_contributions_path = prediction.download('.')
pred_contributions_table = pd.read_csv(pred_contributions_path)
pred_contributions_table.head()
Complete
Downloaded 'b7aba0d4-e235-11ea-9088-0242ac110002_preds_e92e68d4.csv'
[16]:
| DEFAULT_PAYMENT_NEXT_MONTH.0 | DEFAULT_PAYMENT_NEXT_MONTH.1 | contrib_0_AGE | contrib_10_PAY_3 | contrib_11_PAY_4 | contrib_12_PAY_5 | contrib_13_PAY_6 | contrib_14_PAY_AMT1 | contrib_15_PAY_AMT2 | contrib_16_PAY_AMT3 | ... | contrib_45_CVTE:PAY_1:PAY_2:PAY_4.0 | contrib_46_WoE:AGE:LIMIT_BAL:PAY_1:PAY_2:PAY_3:PAY_5.0 | contrib_47_WoE:PAY_3:PAY_5:PAY_6.0 | contrib_48_ClusterTE:ClusterID20:PAY_1:PAY_4:PAY_5:PAY_AMT1:PAY_AMT6.0 | contrib_4_BILL_AMT4 | contrib_5_BILL_AMT5 | contrib_6_BILL_AMT6 | contrib_7_LIMIT_BAL | contrib_8_PAY_1 | contrib_bias | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.299739 | 0.700261 | -0.051685 | 0.017082 | -0.012476 | -0.023556 | -0.007033 | 0.016873 | 0.062995 | -0.037905 | ... | 1.314687 | 0.019138 | -0.039752 | -0.004087 | 0.043153 | -0.014567 | -0.024331 | 0.024522 | 0.526365 | -1.34867 |
| 1 | 0.862815 | 0.137185 | 0.044812 | 0.017206 | 0.001976 | 0.002324 | -0.001514 | 0.030999 | -0.087150 | -0.092674 | ... | -0.437666 | -0.079960 | -0.119075 | 0.008777 | 0.052826 | 0.019449 | 0.061261 | 0.138121 | -0.015459 | -1.34867 |
| 2 | 0.958172 | 0.041828 | -0.054909 | 0.003906 | -0.003241 | 0.002495 | -0.003469 | 0.087790 | -0.315745 | -0.047180 | ... | -0.455067 | 0.007856 | -0.103681 | 0.036041 | -0.032951 | 0.021452 | -0.060518 | -0.161278 | -0.015956 | -1.34867 |
| 3 | 0.599148 | 0.400852 | -0.003953 | 0.016077 | 0.002315 | 0.040801 | 0.007007 | 0.024191 | -0.020707 | 0.147297 | ... | 1.342796 | 0.066763 | 0.025450 | 0.003859 | -0.020837 | -0.050288 | 0.019743 | -0.096786 | 0.371450 | -1.34867 |
| 4 | 0.882068 | 0.117932 | 0.000450 | -0.038284 | -0.013007 | -0.001538 | -0.003652 | 0.036131 | 0.219968 | 0.124056 | ... | -0.519380 | -0.006065 | -0.109650 | -0.029302 | -0.116205 | 0.007022 | 0.004275 | 0.031202 | -0.016736 | -1.34867 |
5 rows × 53 columns
We will examine the contributions for our first record more closely.
[17]:
contrib = pd.DataFrame(pred_contributions_table.iloc[0][1:])
contrib.columns = ["contribution"]
contrib["abs_contribution"] = contrib.contribution.abs()
contrib.sort_values(by="abs_contribution", ascending=False)[["contribution"]].head()
[17]:
| contribution | |
|---|---|
| contrib_bias | -1.348670 |
| contrib_45_CVTE:PAY_1:PAY_2:PAY_4.0 | 1.314687 |
| DEFAULT_PAYMENT_NEXT_MONTH.1 | 0.700261 |
| contrib_8_PAY_1 | 0.526365 |
| contrib_21_CVTE:EDUCATION.0 | 0.140235 |
The clusters from this customer’s: PAY_0, PAY_2, and LIMIT_BAL had the greatest impact on their prediction. Since the contribution is positive, we know that it increases the probability that they will default.
Build Scoring Pipelines
In our last section, we will build the scoring pipelines from our experiment. There are two scoring pipeline options:
Python Scoring Pipeline: requires Python runtime
MOJO Scoring Pipeline: requires Java runtime
Documentation on the scoring pipelines is provided here: http://docs.h2o.ai/driverless-ai/latest-stable/docs/userguide/python-mojo-pipelines.html.
The experiment screen shows two scoring pipeline buttons: Download Python Scoring Pipeline or Build MOJO Scoring Pipeline. Driverless AI determines if any scoring pipeline should be automatically built based on the config.toml file. In this example, we have run Driverless AI with the settings:
# Whether to create the Python scoring pipeline at the end of each experiment
make_python_scoring_pipeline = true
# Whether to create the MOJO scoring pipeline at the end of each experiment
# Note: Not all transformers or main models are available for MOJO (e.g. no gblinear main model)
make_mojo_scoring_pipeline = false
Therefore, only the Python Scoring Pipeline will be built by default.
1. Build Python Scoring Pipeline
The Python Scoring Pipeline has been built by default based on our config.toml settings, but we can built it again if we wish - this is useful if the ``make_python_scoring_pipeline`` option was set to false.
[18]:
ex.artifacts.create('python_pipeline')
Building Python scoring pipeline...
Now we will download the scoring pipeline zip file.
[19]:
ex.artifacts.download(only='python_pipeline',
dst_dir='.',
overwrite=True)
Downloaded './scorer.zip'
[19]:
{'python_pipeline': './scorer.zip'}
2. Build MOJO Scoring Pipeline
The MOJO Scoring Pipeline has not been built by default because of our config.toml settings. We can build the MOJO Scoring Pipeline using the Python client. This is equivalent to selecting the Build MOJO Scoring Pipeline on the experiment screen.
[61]:
ex.artifacts.create('mojo_pipeline')
Now we can download the scoring pipeline zip file.
[63]:
ex.artifacts.download(only='mojo_pipeline', dst_dir='.', overwrite=True)
[63]:
'./mojo.zip'
Once the MOJO Scoring Pipeline is built, the Build MOJO Scoring Pipeline changes to Download MOJO Scoring Pipeline.

[ ]: