Introduction to H2O Driverless AI
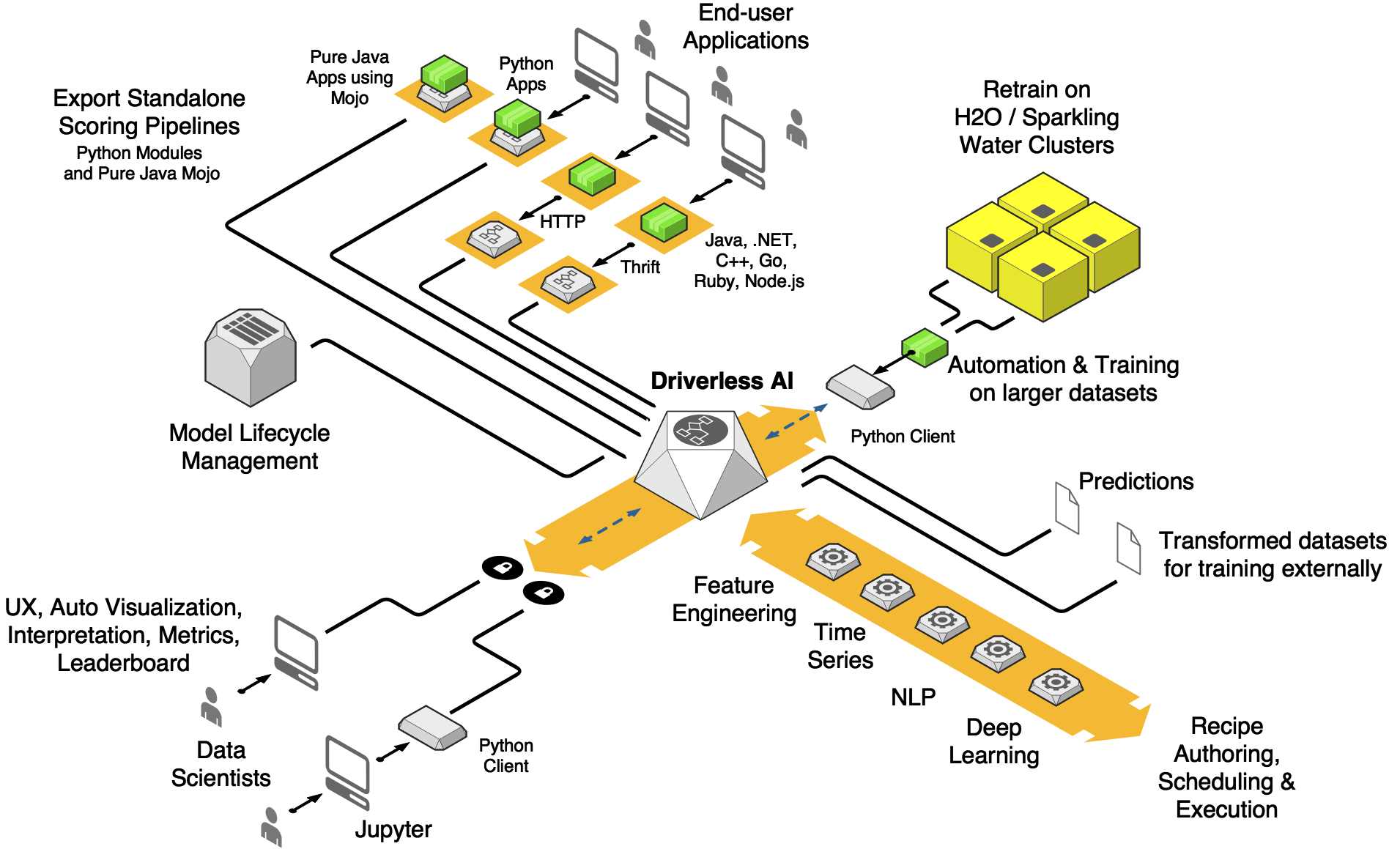
H2O Driverless AI (DAI) is a high-performance, GPU-enabled, client-server application for the rapid development and deployment of state-of-the-art predictive analytics models. It reads tabular data from various sources and automates data visualization, grand-master level automatic feature engineering, model validation (overfitting and leakage prevention), model parameter tuning, model interpretability, and model deployment. DAI is currently targeting common regression, binomial classification, and multinomial classification applications, including loss-given-default, probability of default, customer churn, campaign response, fraud detection, anti-money-laundering, and predictive asset maintenance models. It also handles time-series problems for individual or grouped time-series, such as weekly sales predictions per store and department, with time-causal feature engineering and validation schemes. DAI can also handle image and text data (NLP) use cases.
You can access DAI through H2O AI Engine Manager, a core service of H2O AI Cloud.
High-level capabilities:
Client/server application for rapid experimentation and deployment of state-of-the-art supervised machine learning models
User-friendly GUI
Python and R client API
Automatically creates machine learning modeling pipelines for the highest predictive accuracy
Automates data cleaning, feature selection, feature engineering, model selection, model tuning, ensembling
Automatically creates a standalone batch scoring pipeline for in-process scoring or client/server scoring via HTTP or TCP protocols in Python
Automatically creates stand-alone (MOJO) low latency scoring pipeline for in-process scoring or client/server scoring via HTTP or TCP protocols, in C++ (with R and Python runtimes) and Java (runs anywhere)
Multi-GPU and multi-CPU support for powerful workstations and NVidia DGX supercomputers
Machine Learning model interpretation module with global and local model interpretation
Automatic Visualization module
Multi-user support
Backward compatibility
Problem types supported:
Regression (continuous target variable like age, income, price or loss prediction, time-series forecasting)
Binary classification (0/1 or “N”/”Y”, for fraud prediction, churn prediction, failure prediction, etc.)
Multinomial classification (“negative”/”neutral”/”positive” or 0/1/2/3 or 0.5/1.0/2.0 for categorical target variables, for prediction of membership type, next-action, product recommendation, sentiment analysis, etc.)
Data types supported:
Tabular structured data, rows are observations, columns are fields/features/variables
Numeric, categorical and textual fields
Images
Missing values are allowed
i.i.d. (identically and independently distributed) data
Time-series data with a single time-series (time flows across the entire dataset, not per block of data)
Grouped time-series (e.g., sales per store per department per week, all in one file, with 3 columns for store, dept, week)
Time-series problems with a gap between training and testing (i.e., the time to deploy), and a known forecast horizon (after which model has to be retrained)
Data types supported via custom recipes:
Video
Audio
Graphs
Data sources supported:
Local file system or NFS
File upload from browser or Python client
S3 (Amazon)
Hadoop (HDFS)
Azure Blob storage
Blue Data Tap
Google BigQuery
Google Cloud storage
kdb+
MinIO
Snowflake
JDBC
Custom Data Recipe BYOR (Python, bring your own recipe)
File formats supported:
Plain text formats of columnar data (.csv, .tsv, .txt)
Compressed archives (.zip, .gz, .bz2)
Excel
Parquet
Feather
Python datatable (.jay)