NLP in Driverless AI
This section describes NLP (text) processing capabilities of Driverless AI. The Driverless AI platform has the ability to support both standalone text and text with other column types as predictive features. TensorFlow based and PyTorch Transformer Architectures (for example, BERT) are used for Feature Engineering and Model Building.
For details, see:
Note
For detailed per-tab Expert Settings, see Training Settings, Experiment Documentation Settings, System Settings, and Extra Settings.
Note
NLP and image use cases in Driverless benefit significantly from GPU usage.
To download pretrained NLP models, visit http://s3.amazonaws.com/artifacts.h2o.ai/releases/ai/h2o/pretrained/bert_models.zip. You can use the
pytorch_nlp_pretrained_models_dirconfiguration option to specify a path to pretrained PyTorch NLP models. This can be either a path in the local file system (/path/on/server/to/bert_models_folder), a URL, or an S3 location (s3://). For example, you can set this option as follows: pytorch_nlp_pretrained_models_dir=/path/on/server/to/bert_models_folder.You can use the Driverless AI Experiment Setup Wizard to guide you through the process of setting up NLP experiments. For more information, see H2O Driverless AI Experiment Setup Wizard.
The Co-Occurrence matrix method are used only when
force_enable_text_comatrix_preprocessset to be true.The TextCNN, TextBiGRU and TextCharCNN are deprecated in 2.3.0 and will be removed in future release. TextCNNV2, TextBiGRUV2 and TextCharCNNV2 are the updated version of these transformers implemented in PyTorch, see Text Transformers (String).
NLP Feature Engineering and Modeling
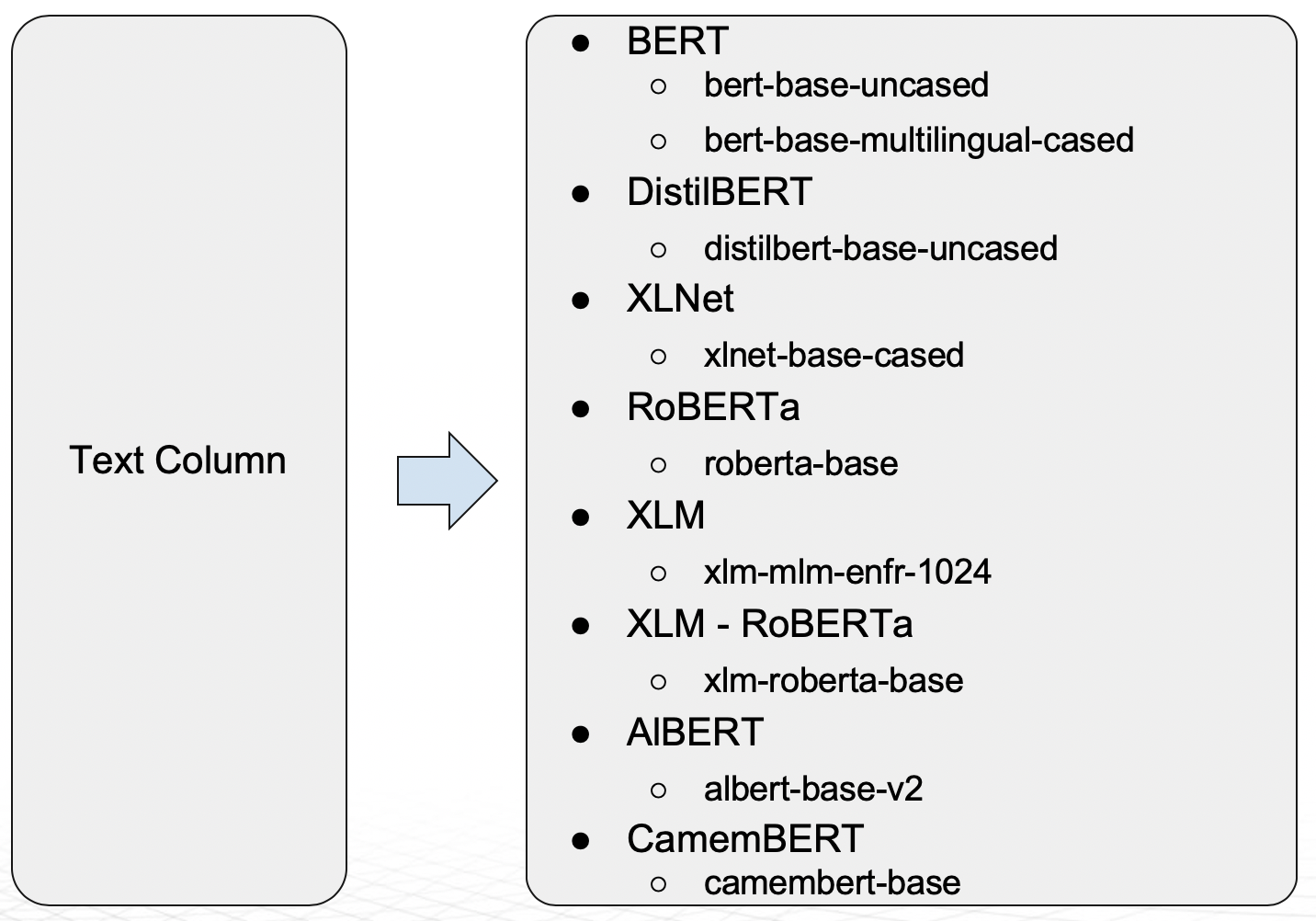
Pretrained PyTorch Models in Driverless AI
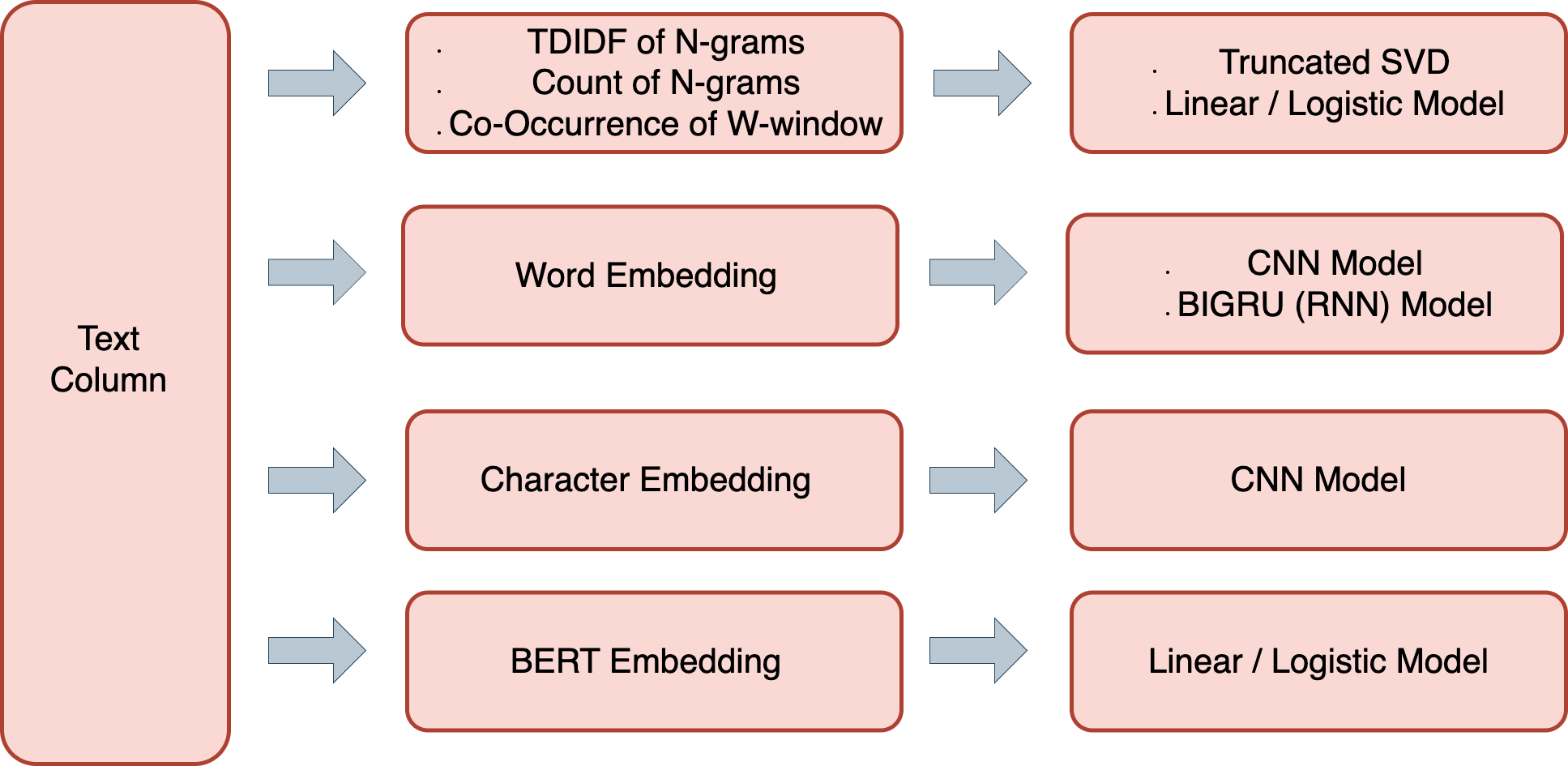
The following NLP recipes are available for a text column. A full list of NLP Transformers is available here.
n-gram frequency/TF-IDF/Co-Occurrence followed by Truncated SVD
n-gram frequency/TF-IDF/Co-Occurrence followed by Linear/Logistic regression
Word embeddings followed by CNN model (TensorFlow)
Word embeddings followed by BiGRU model (TensorFlow)
Character embeddings followed by CNN model (TensorFlow)
BERT/DistilBERT based embeddings for Feature Engineering (PyTorch)
Support for multiple Transformer Architectures (eg.BERT) as modeling algorithms (PyTorch)
n-gram
An n-gram is a contiguous sequence of n items from a given sample of text or speech.
n-gram Frequency
Frequency-based features represent the count of each word from a given text in the form of vectors. These are created for different n-gram values. For example, a one-gram is equivalent to a single word, a two-gram is equivalent to two consecutive words paired together, and so on. Words and n-grams that occur more often will receive a higher weightage. The ones that are rare will receive a lower weightage.
TF-IDF of n-grams
Frequency-based features can be multiplied with the inverse document frequency to get term frequency–inverse document frequency (TF-IDF) vectors. Doing so also gives importance to the rare terms that occur in the corpus, which may be helpful in certain classification tasks.

Co-Occurrence of w-window
An w-window is a sliding window of w items from a given sample of text or speech. It is used to compute the frequency of a pair of target word paired with its context words in both forward and backward directions within the window.
PPMI of Co-Occurrence matrix
The PPMI algorithm (Positive Pointwise Mutual Information) is a technique used in text processing to enhance a Co-Occurrence matrix by highlighting statistically significant word associations.

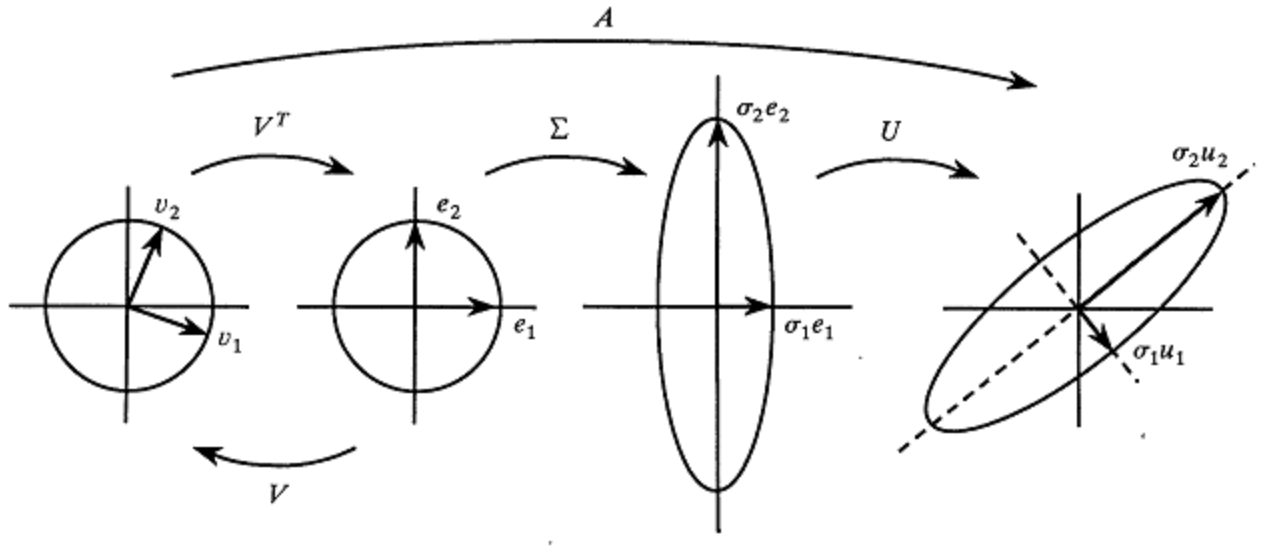
Truncated SVD Features
TF-IDF and the frequency of n-grams both result in higher dimensions of the representational vectors. To counteract this, Truncated SVD is commonly used to decompose the vectorized arrays into lower dimensions.
Linear Models for TF-IDF Vectors
Linear models are also available in the Driverless AI NLP recipe. These capture linear dependencies that are crucial to the process of achieving high accuracy rates and are used as features in the base DAI model.
Word Embeddings
Word embeddings is the term for a collective set of feature engineering techniques for text where words or phrases from the vocabulary are mapped to vectors of real numbers. Representations are made so that words with similar meanings are placed close to or equidistant from one another. For example, the word “king” is closely associated with the word “queen” in this kind of vector representation.
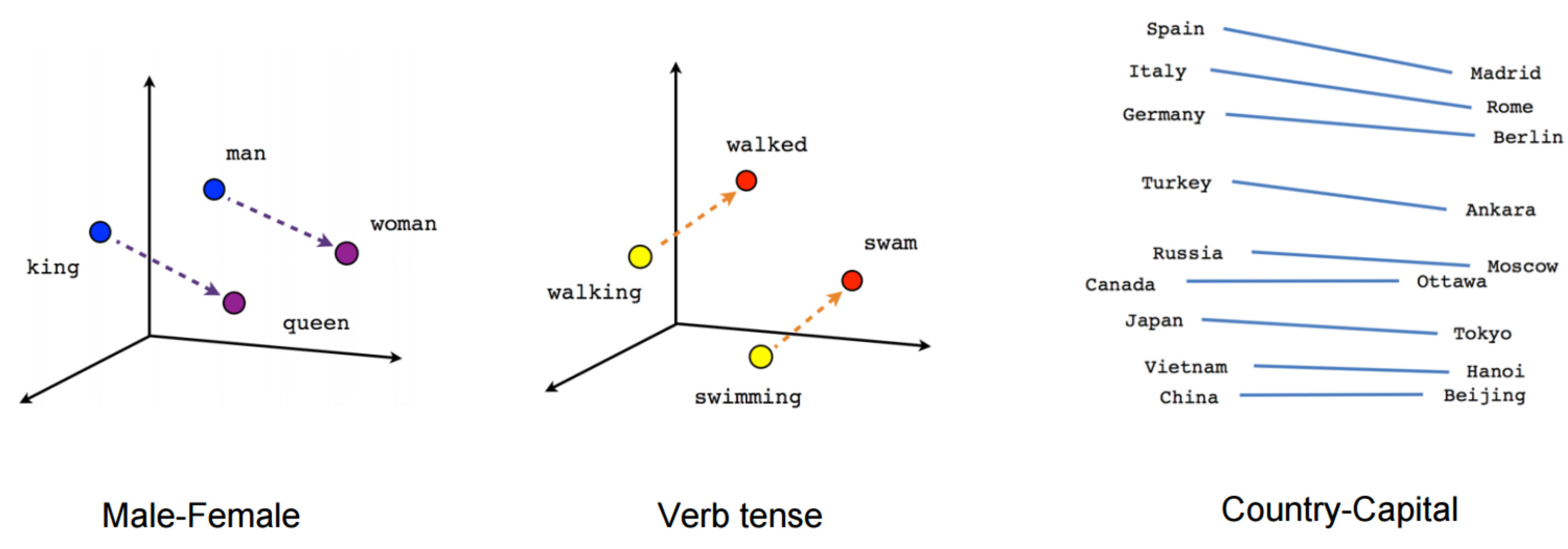
TF-IDF and frequency-based models represent counts and significant word information, but they lack the semantic context for these words. Word embedding techniques are used to make up for this lack of semantic information.
CNN Models for Word Embedding
Although Convolutional Neural Network (CNN) models are primarily used on image-level machine learning tasks, their use case on representing text as information has proven to be quite efficient and faster compared to RNN models. In Driverless AI, we pass word embeddings as input to CNN models, which return cross validated predictions that can be used as a new set of features.
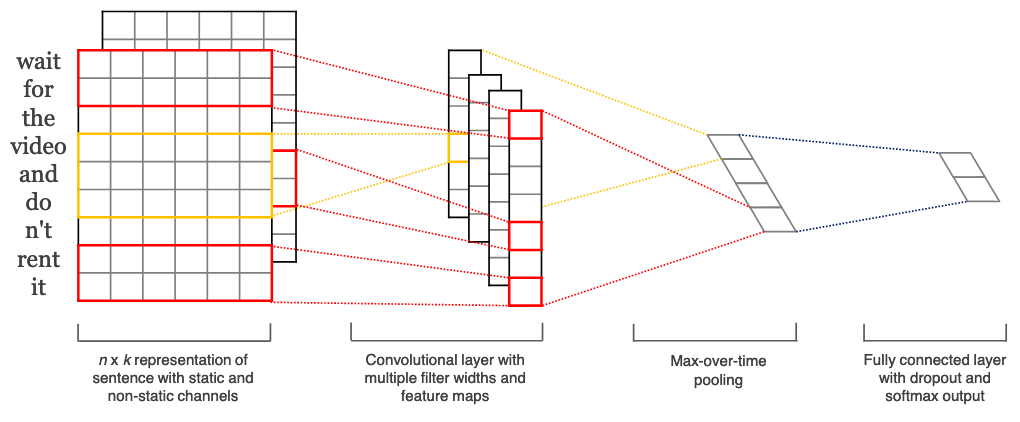
Bi-directional GRU Models for Word Embedding
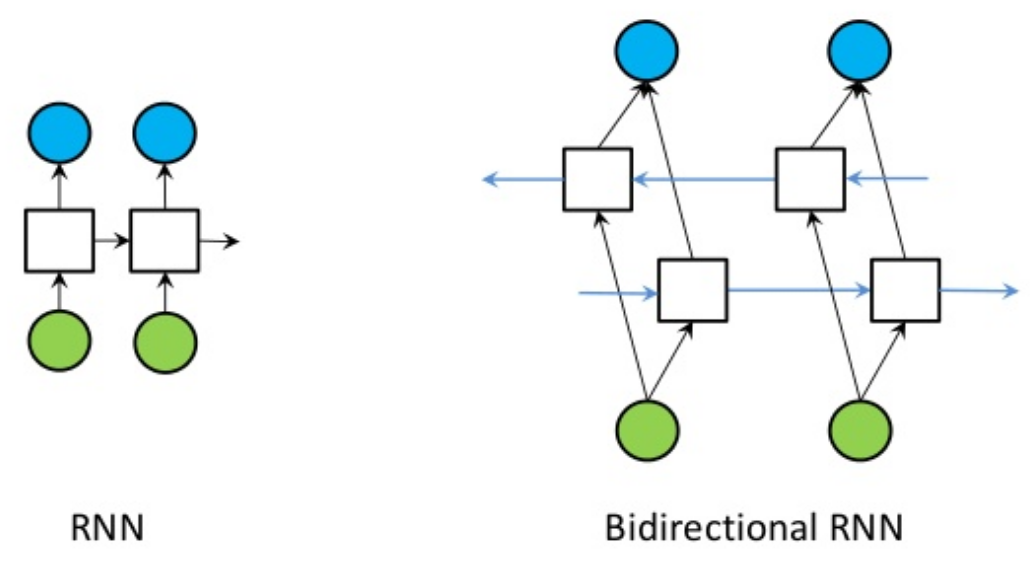
Recurrent neural networks, like long short-term memory units (LSTM) and gated recurrent units (GRU), are state-of-the-art algorithms for NLP problems. In Driverless AI, we implement bi-directional GRU features for previous word steps and for later steps to predict the current state. For example, in the sentence “John is walking on the golf course,” a unidirectional model would represent states that represent “golf” based on “John is walking on,” but would not represent “course.” Using a bi-directional model, the representation would also account the later representations, giving the model more predictive power.
In simple terms, a bi-directional GRU model combines two independent RNN models into a single model. A GRU architecture provides high speeds and accuracy rates similar to a LSTM architecture. As with CNN models, we pass word embeddings as input to these models, which return cross validated predictions that can be used as a new set of features.
CNN Models for Character Embedding
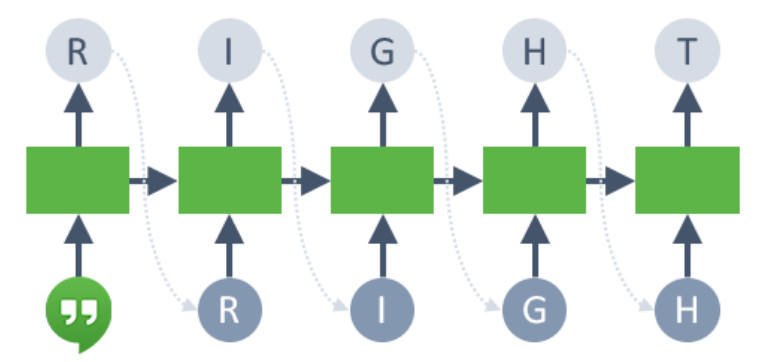
For languages like Japanese and Mandarin Chinese, where characters play a major role, character level embedding is available as an NLP recipe.
In character embedding, each character is represented in the form of vectors rather than words. Driverless AI uses character level embedding as the input to CNN models and later extracts class probabilities to feed as features for downstream models.
The image below represents the overall set of features created by this NLP recipe:
BERT/DistilBERT Models for Feature Engineering
Transformer based language models like BERT are state-of-the-art NLP models that can be used for a wide variety of NLP tasks. These models capture the contextual relation between words by using an attention mechanism. Unlike directional models that read text sequentially, a Transformer-based model reads the entire sequence of text at once, allowing it to learn the context of the word based on all of its surrounding words. The embeddings obtained by these models show improved results in comparison to earlier embedding approaches.
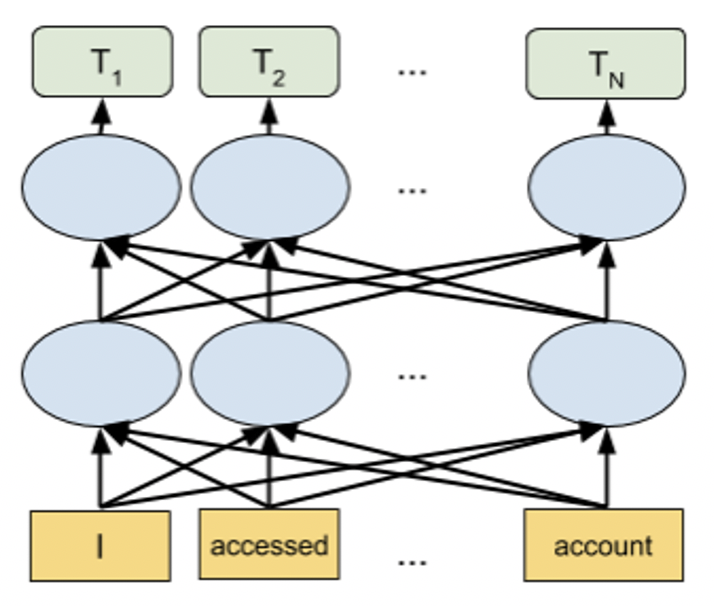
BERT and DistilBERT models can be used for generating embeddings for any text columns. These pretrained models are used to get embeddings for the text followed by Linear/Logistic Regression to generate features that can then be used for any downstream models in Driverless AI. Refer to nlp-settings in the Expert Settings topic for more information on how to enable these models for feature engineering. We recommend using GPU(s) to leverage the power of these models and accelerate the feature engineering process.
PyTorch Transformer Architecture Models (eg. BERT) as Modeling Algorithms
Starting with Driverless AI 1.9 release, the Transformer-based architectures shown in the diagram below is supported as models in Driverless AI.
The BERT model support multiple languages. DistilBERT is a distilled version of BERT that has fewer parameters compared to BERT (40% less) and it is faster (60% speedup) while retaining 95% of BERT level performance. The DistilBERT model can be useful when training time and model size is important. Refer to nlp-settings in the Expert Settings topic for more information on how to enable these models as modeling algorithms. We recommend using GPU(s) to leverage the power of these models and accelerate the model training time.
In addition to these techniques, Driverless AI supports custom NLP recipes using, for example, PyTorch or Flair.
NLP Feature Naming Convention
The naming conventions of the NLP features help to understand the type of feature that has been created.
The syntax for the feature names is as follows:
[FEAT TYPE]:[COL].[TARGET_CLASS]
[FEAT TYPE] represents one of the following:
Txt – Frequency / TF-IDF of n-grams followed by Truncated SVD
TxtTE - Frequency / TF-IDF of n-grams followed by a Linear model
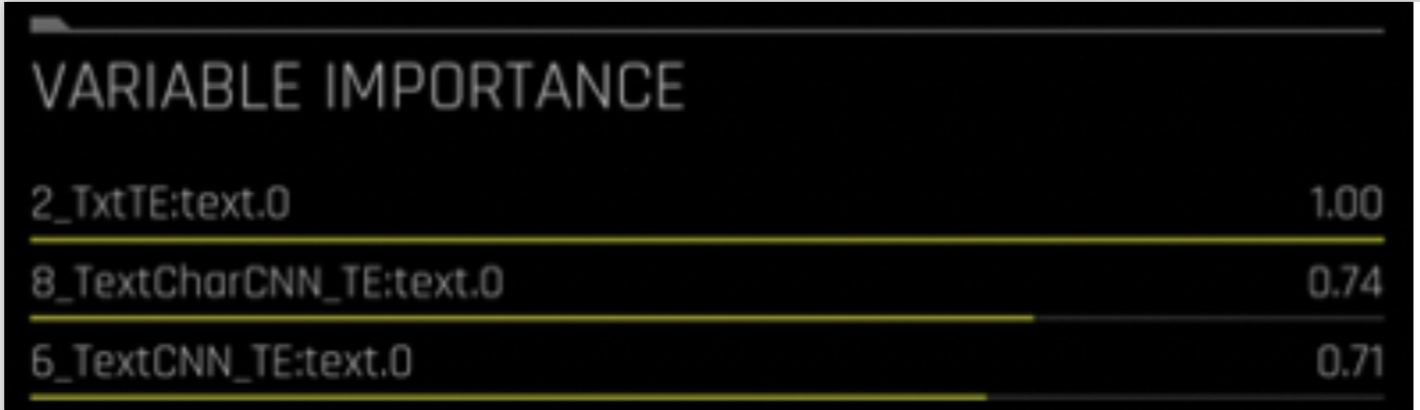
TextCNN_TE – Word embeddings followed by CNN model
TextBiGRU_TE – Word embeddings followed by Bi-directional GRU model
TextCharCNN_TE – Character embeddings followed by CNN model
[COL] represents the name of the text column.
[TARGET_CLASS] represents the target class for which the model predictions are made.
For example, TxtTE:text.0 equates to class 0 predictions for the text column “text” using Frequency / TF-IDF of n-grams followed by a linear model.
NLP Explainers
The following is a list of available NLP explainers. For more information, refer to Explainer Recipes and NLP Plots.
Default explainers
The following NLP explainers are run by default for NLP experiments.
NLP LOCO Explainer: The NLP LOCO plot applies a leave-one-covariate-out (LOCO) styled approach to NLP models by removing a specific token from all text features in a record and predicting local importance without that token. The difference between the resulting score and the original score (token included) is useful when trying to determine how specific changes to text features alter the predictions made by the model.
NLP Partial Dependence Plot Explainer: NLP partial dependence (yellow) portrays the average prediction behavior of the Driverless AI model when an input text token is left in its respective text and not included in its respective text along with +/- 1 standard deviation bands. ICE (grey) displays the prediction behavior for an individual row of data when an input text token is left in its respective text and not included in its respective text. The text tokens are generated from TF-IDF.
Legacy explainers
The following legacy NLP explainers are not run by default for NLP experiments. You can run legacy NLP explainers by using config variables.
NLP Tokenizer Explainer: NLP tokenizer plot shows both the global and local importance values of each token in a corpus (a large and structured set of texts). The corpus is automatically generated from text features used by Driverless AI models prior to the process of tokenization. Local importance values are calculated by using the term frequency-inverse document frequency (TF-IDF) as a weighting factor for each token in each row. The TF-IDF increases proportionally to the number of times a token appears in a given document and is offset by the number of documents in the corpus that contain the token.
NLP Vectorizer + Linear Model (VLM) Text Feature Importance Explainer: NLP Vectorizer + Linear Model (VLM) text feature importance uses TF-IDF of individual words as features from a text column of interest and builds a linear model (currently GLM) using those features and fits it to either the predicted class (binary classification) or the continuous prediction (regression) of the Driverless AI model. The coefficients of the linear model give the importance of the words. Note that by default, this explainer uses the first text column based on alphabetical order.
NLP Expert Settings
A number of configurable settings are available for NLP in Driverless AI. For more information, refer to nlp-settings in the Expert Settings topic. Also see nlp model and nlp transformer in pipeline building recipes under experiment settings.
An NLP Example: Sentiment Analysis
The following section provides an NLP example. This information is based on the Automatic Feature Engineering for Text Analytics blog post. A similar example using the Python Client is available in Python Client.
This example uses a classic example of sentiment analysis on tweets using the US Airline Sentiment dataset. Note that the sentiment of each tweet has been labeled in advance and that our model will be used to label new tweets. We can split the dataset into training and test (80/20) with the random split in Driverless AI. We will use the tweets in the ‘text’ column and the sentiment (positive, negative or neutral) in the ‘airline_sentiment’ column for this demo. Here are some samples from the dataset:

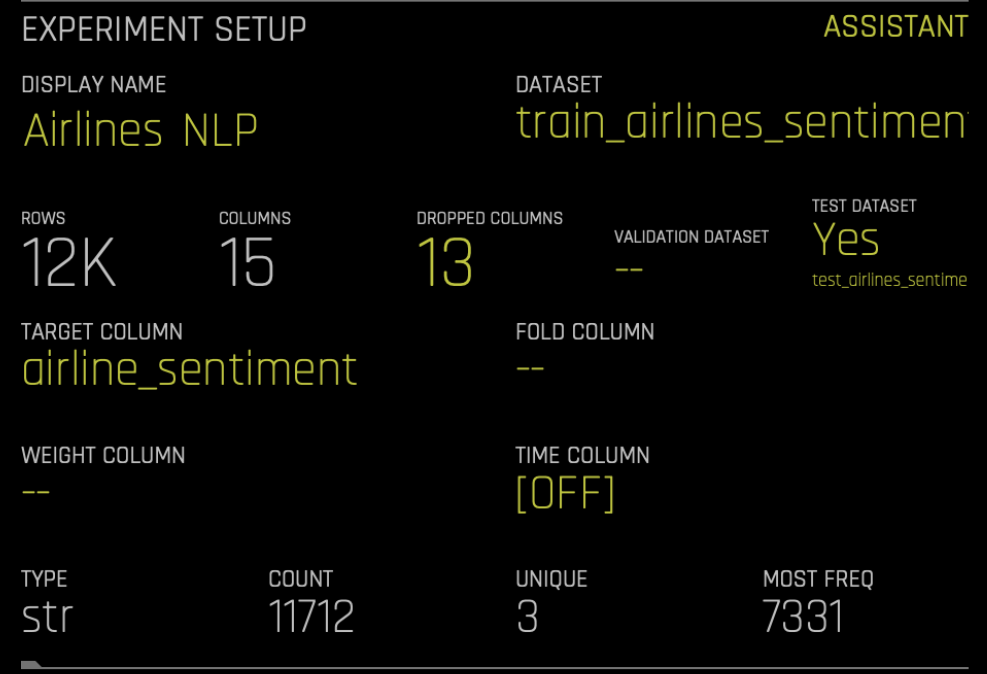
Once we have our dataset ready in the tabular format, we are all set to use the Driverless AI. Similar to other problems in the Driverless AI setup, we need to choose the dataset, and then specify the target column (‘airline_sentiment’).
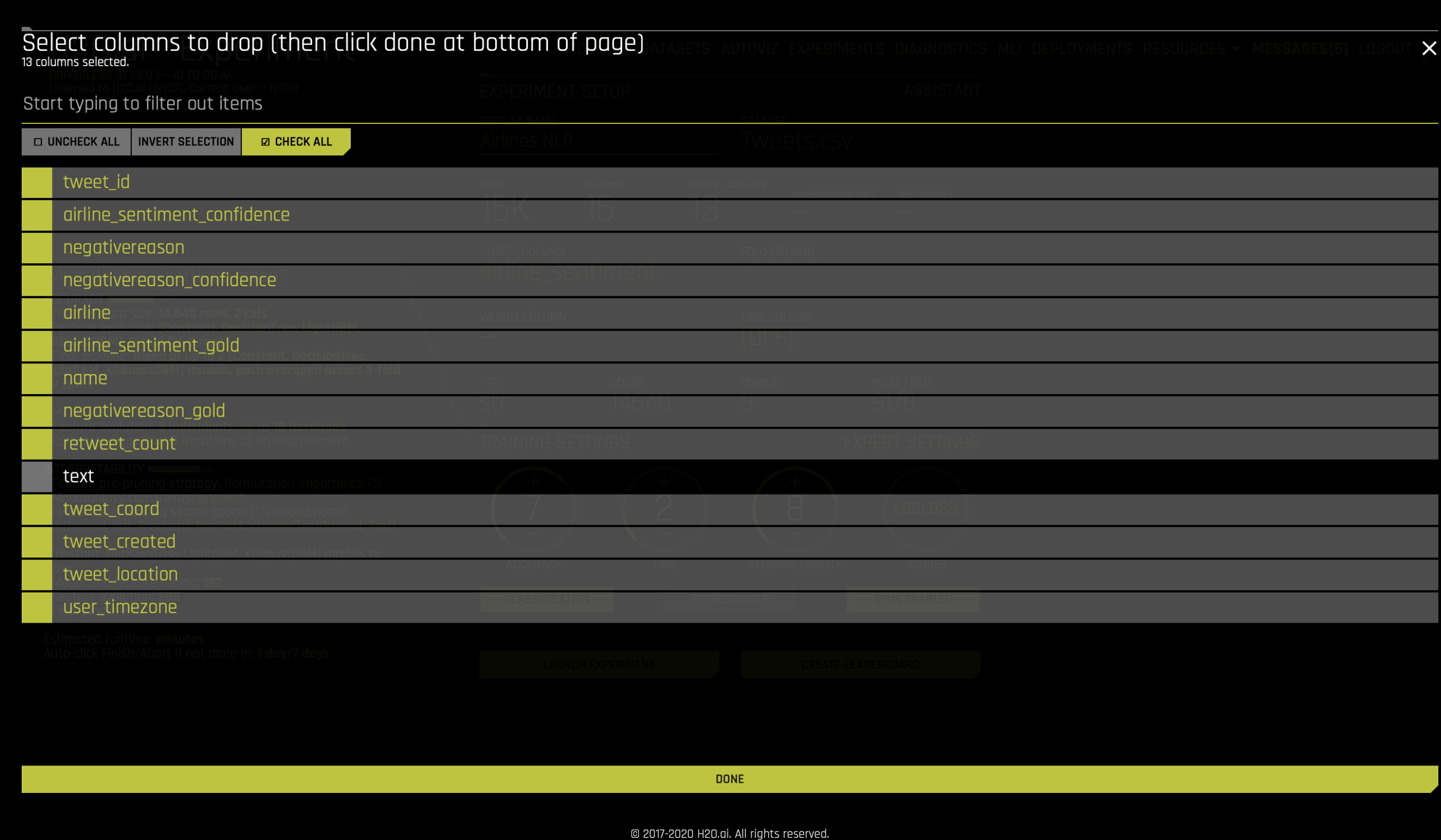
Because we don’t want to use any other columns in the dataset, we need to click on Dropped Cols, and then exclude everything but text as shown below:
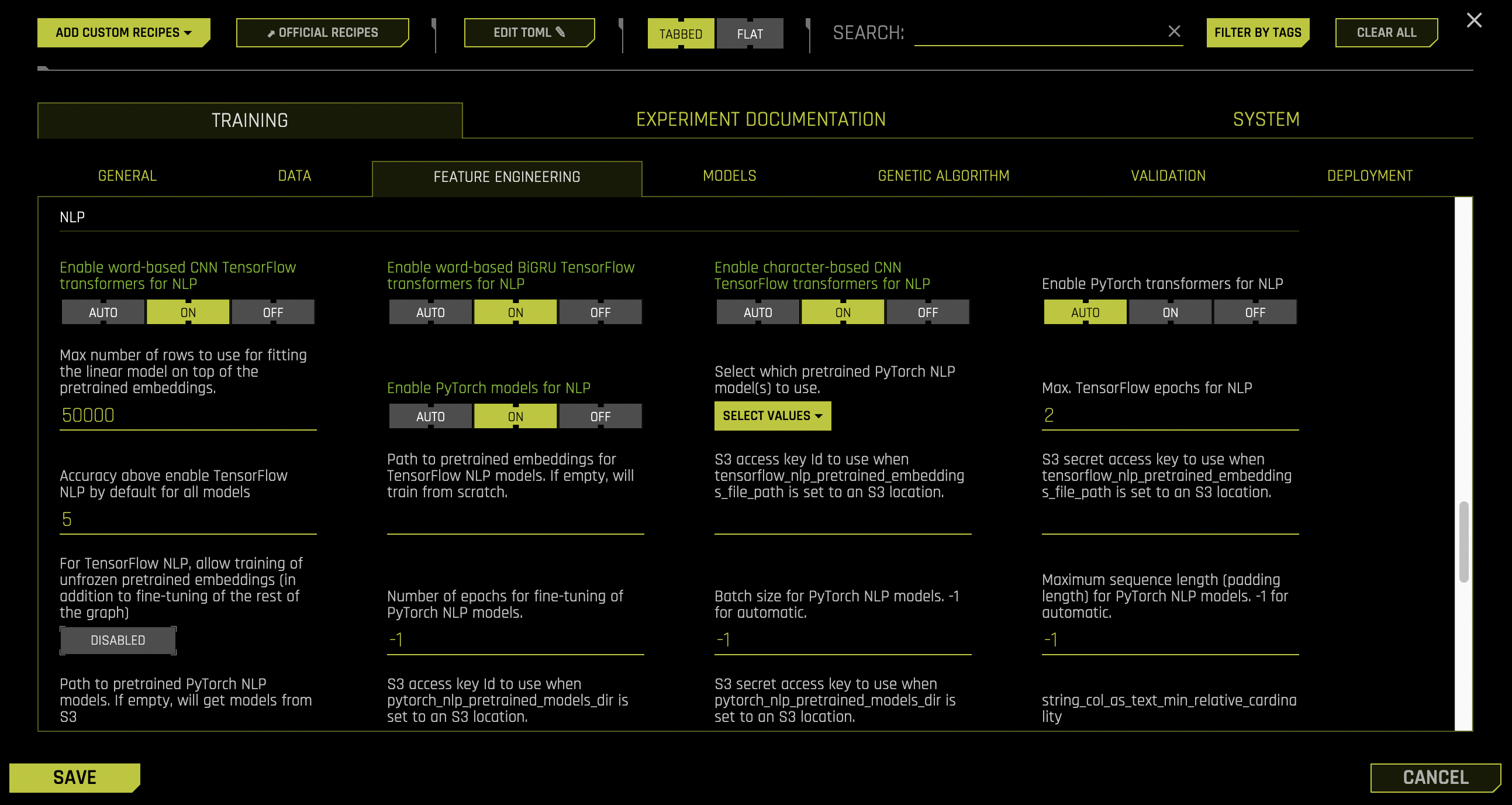
Next, we will turn on our TensorFlow NLP recipes. We can go to the Expert Settings window, NLP and turn on the following: CNN TensorFlow models, BiGRU TensorFlow models, character-based TensorFlow models or pretrained PyTorch NLP models.
At this point, we are ready to launch an experiment. Text features will be automatically generated and evaluated during the feature engineering process. Note that some features such as TextCNN rely on TensorFlow models. We recommend using GPU(s) to leverage the power of TensorFlow or the PyTorch Transformer models and accelerate the feature engineering process.
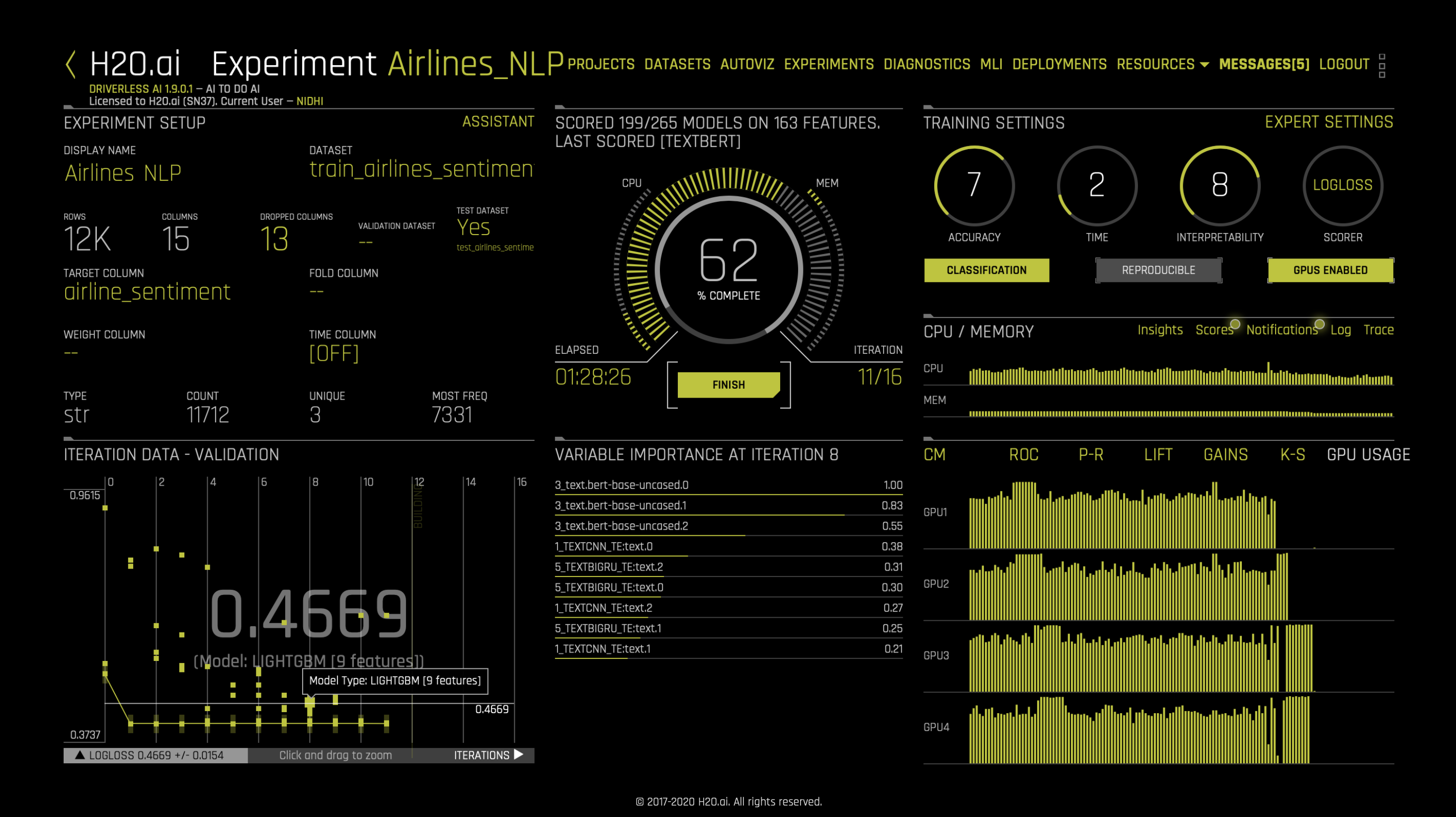
Once the experiment is done, users can make new predictions and download the scoring pipeline just like any other Driverless AI experiments.
Resources:
fastText: https://fasttext.cc/
NLP Models to Production
Python scoring and C++ MOJO scoring are supported for TensorFlow and BERT models (used for feature engineering and modeling). Enable tensorflow_nlp_have_gpus_in_production parameter in config.toml to enable model deployment on GPUs.