Create a Collection
Overview
To create a Collection, you only need to specify the following required setting: Collection name.
There are many strategies for importing and creating Collections so that you get the best responses for your use case. For guidance on how to use Collections, see Collections usage overview.
Instructions
The following steps describe how to create a Collection.
You can select an embedding model for the Collection only once and that is during the process of creating a new Collection. In other words, you can utilize the default selected embedding model or change it to one of the available options. You can not change this setting after it is defined during the creation process of the Collection.
- On the Enterprise h2oGPTe navigation menu, click Collections.
- Click + New collection.
- In the Collection name box, enter a name for the Collection.
- Click + Create.
- You can modify/define the other Collection settings when creating the Collection or after its creation. For example, you can add documents to the Collection during or after its creation.
- To learn about each of the Collection settings, see Collection settings.
Collection settings
The Collection settings section includes the following settings:
General
Collection name
This setting defines the name of the Collection.
Description
This setting defines the description of the Collection.
If the Description box is left empty, the system will auto-generate a description based on the uploaded documents, configurable prompts, and the number of chunks of the Collection.
Configuration
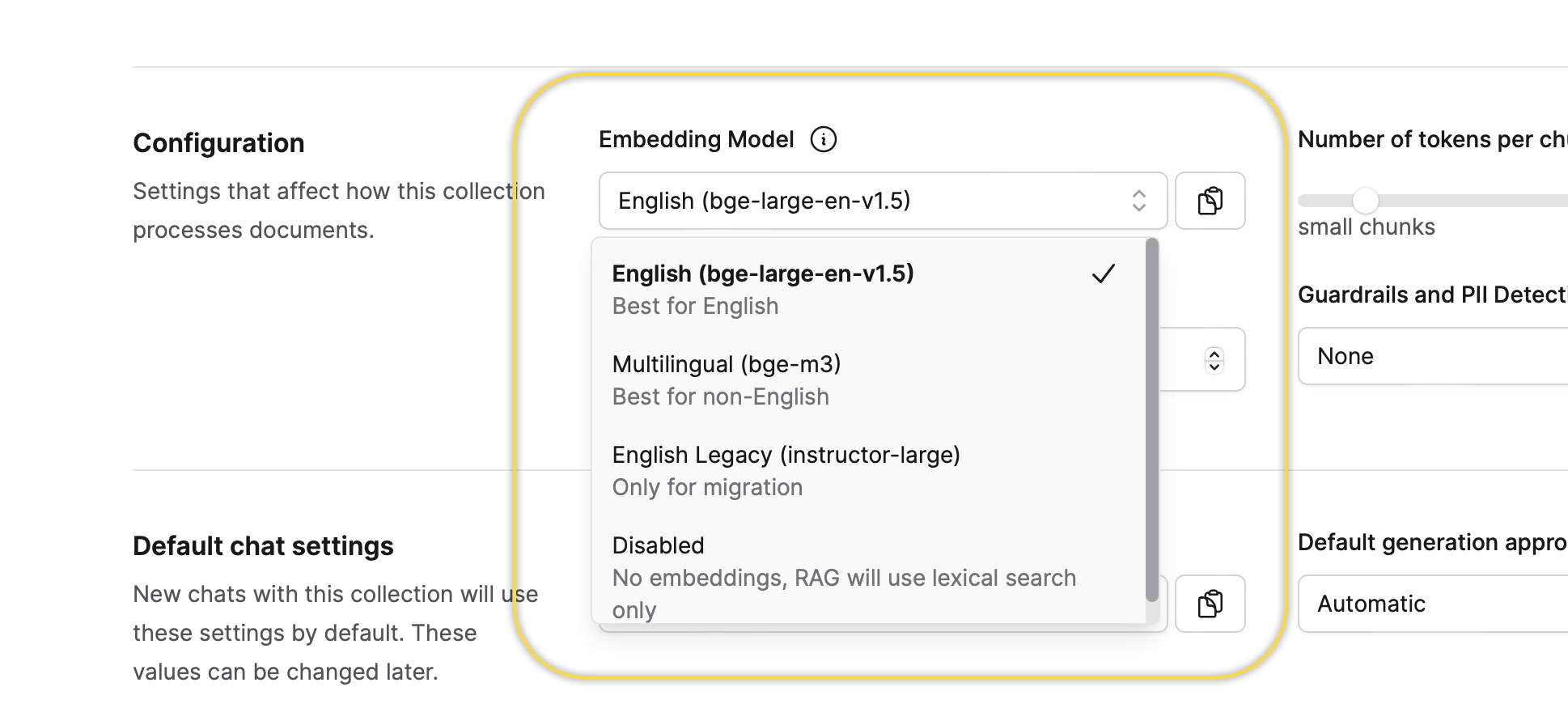
Embedding model
This setting defines the embedding model for the Collection. You can select an embedding model only once when creating a new Collection. In other words, you can utilize the default selected embedding model or change it to one of the available options.
You can not change this setting after it is defined during the creation process of the Collection.
Number of tokens per chunk
This setting defines the desired target size of document context chunks in a number of tokens. Larger values improve the retrieval of large, contiguous pieces of information, while smaller values improve the retrieval of fine-grained details. Text extracted from large images will generally stay together in one chunk, no matter the value of this setting.
Chunk overlap tokens
This setting defines (or controls) the number of overlapping tokens between consecutive document context chunks. Increasing this value results in greater overlap, providing more context for challenging questions and leading to more duplicated data. The default (and recommended) value of 0 ensures that chunks have no overlapping tokens.
Guardrails and PII Detection
This setting establishes guardrails for prompts and the detection and redaction of personally identifiable information (PII). Options:
-
None
This option does not apply guardrails for prompts and the detection and redaction of PII. In other words, Enterprise h2oGPTe does not redact PII when it is detected in the document during ingestion, input to the LLM, or output from the LLM.
-
Enable guardrails, allow PII
This option enables guardrails for prompts but does not address PII. In other words, Enterprise h2oGPTe does not redact PII when it is detected in the document during ingestion, input to the LLM, or output from the LLM.
-
Enable guardrails, redact sensitive PII
This option enables guardrails for prompts and the detection and redaction of sensitive PII. In other words, Enterprise h2oGPTe redacts sensitive PII when it is detected in the document during ingestion, input to the LLM, or output from the LLM.
Sensitive: PII is data that, if improperly disclosed or accessed, could potentially lead to substantial harm for an individual. Due to its sensitive nature, this data is highly susceptible to misuse, such as identity theft, fraud, or discrimination. For example, Social Security Numbers (SSNs).
-
Enable guardrails, redact any PII
This option enables guardrails for prompts and the detection and redaction of any PII. In other words, Enterprise h2oGPTe redacts any PII when it is detected in the document during ingestion, input to the LLM, or output from the LLM.
Any: Any PII refers to any information that can be used to identify an individual, either directly or indirectly. It includes both sensitive and non-sensitive information. For example, email addresses or Social Security Numbers (SSNs).
-
Customize guardrails and PII settings
This option enables you to view/edit all guardrails for prompts and the detection and redaction of PII.
Prompt guard
This setting specifies the entities that Enterprise h2oGPTe should identify in all user prompts, including prompt templates and queries. The Prompt Guard model determines the available options for this setting. If a prompt template triggers a JAILBREAK detection, adjust it as necessary. Jailbreaks are harmful instructions intended to bypass the safety and security mechanisms of the model.
This setting is displayed when you select the following option for the Guardrails and PII Detection setting:
Guardrails
This setting specifies the entities to flag in all user prompts. The available options are based on the Llama Guard 3 model. If no custom guardrails are configured, the same LLM used to perform the query will also handle the guardrails task.
This setting is displayed when you select the following option for the Guardrails and PII Detection setting:
Disallowed Regex patterns
This setting specifies regular expression patterns that are prohibited from appearing in user inputs. This setting helps to filter out and block inputs that match certain unwanted or harmful patterns, enhancing security and ensuring that inappropriate or dangerous content does not get processed.
This setting is displayed when you select the following option for the Guardrails and PII Detection setting:
Presidio labels
This setting defines the entities to label as personally identifiable information (PII). The available choices are based on the Presidio model.
Presidio labels refer to the classification tags used by Microsoft's Presidio, a privacy and data protection tool. Presidio helps in identifying and protecting sensitive information within text data by applying various labels. These labels are used to classify types of sensitive data such as PII.
This setting is displayed when you select the following option for the Guardrails and PII Detection setting:
PII Labels
This setting defines the entities to label as personally identifiable information (PII). The available options are based on a DeBERTa based classifier model fine-tuned for PII detection.
This setting is displayed when you select the following option for the Guardrails and PII Detection setting:
Parse Action
This toggle defines what Enterprise h2oGPTe should do when personally identifiable information (PII) is detected in the document at the time of ingestion.
- "Allow" does nothing.
- "Redact" will redact the document and put censor bars over detected PII in the resulting document, and the original PII content will not be visible to any parts of the system.
- "Fail" will abort the document ingestion process with an error message.
This setting is displayed when you select the following option for the Guardrails and PII Detection setting:
LLM Input Action
This toggle defines what Enterprise h2oGPTe should do when personally identifiable information (PII) is detected in the input to the LLM. This can be either document context or user prompts, including prompt templates.
- "Allow" does nothing.
- "Redact" will redact the input to the LLM. For example, it replaces PII with either "XXXXXXX" or US_SSN, effectively removing PII.
- "Fail" will abort the generation process with an error message, before the context is sent to the LLM.
This setting is displayed when you select the following option for the Guardrails and PII Detection setting:
LLM Output Action
This toggle defines what Enterprise h2oGPTe should do when personally identifiable information (PII) is detected in the output coming from the LLM.
- "Allow" does nothing.
- "Redact" will redact the LLM output. For example, it replaces PII with either "XXXXXXX" or US_SSN, effectively removing PII from the generated output.
- "Fail" will abort the output generation process with an error message.
This setting is displayed when you select the following option for the Guardrails and PII Detection setting:
Default chat settings
Default prompt template
This setting defines the prompt template to customize the prompts utilized within the Collection. You can create your prompt template on the Prompts page and apply it to your Collection.
Default generation approach
This setting defines the generation approach for responses. Enterprise h2oGPTe offers the following methods to generate responses to answer user's queries (Chats):
-
Automatic
This option is the automatic selection of the generation approach. LLM Only (no RAG) type is not considered for Chats with Collections.
-
LLM Only
This option generates a response to answer the user's query solely based on the Large Language Model (LLM) without considering supporting Document contexts from the Collection.
-
RAG (Retrieval Augmented Generation)
This option utilizes a neural/lexical hybrid search approach to find relevant contexts from the Collection based on the user's query for generating a response. Applicable when the prompt is easily understood and the context contains enough information to come up with a correct answer.
RAG first performs a vector search for similar chunks limited by the number of chunks sorted by distance metric. By default, Enterprise h2oGPTe chooses the top 25 chunks using lexical distance and top 25 using neural distance. The distance metric is calculated by the cross entropy loss from the BAAI/bge-reranker-large model. These chunks are passed to the selected LLM to answer the user's query. Note that Enterprise h2oGPTe lets you view the exact prompt passed to the LLM.
-
LLM Only + RAG composite
This option extends RAG with neural/lexical hybrid search by utilizing the user's query and the LLM response to find relevant contexts from the Collection to generate a response. It requires two LLM calls. Applicable when the prompt is somewhat ambiguous or the context does not contain enough information to come up with a correct answer.
HyDE (Hypothetical Document Embeddings) is essentially the same as RAG except that it does not simply search for the embeddings with the smallest distance to the query. Instead, it first asks an LLM to try to answer the question. It then uses the question and the hypothetical answer to search for the nearest chunks.
Example question: What are the implications of high interest rate?
-
RAG: Searches for chunks in the document with a small distance to the embedding of the question: "What are the implications of high interest rate?"
-
LLM Only + RAG composite:
- Asks an LLM: "What are the implications of high interest rate?"
- LLM answers: "High interest rates can have several implications, including: higher borrowing cost, slower economic growth, increased savings rate, higher returns on investment, exchange rate fluctuation, ..."
- RAG searches for chunks in the document with a small distance to the embedding of the question AND the answer from step b. This effectively increases the potentially relevant chunks.
-
-
HyDE + RAG composite
This option utilizes RAG with neural/lexical hybrid search by using both the user's query and the HyDE RAG response to find relevant contexts from the Collection to generate a response. It requires three LLM calls. Applicable when the prompt is very ambiguous or the context contains conflicting information and it's very difficult to come up with a correct answer.
-
Summary RAG
This option utilizes RAG (Retrieval Augmented Generation) with neural/lexical hybrid search using the user's query to find relevant contexts from the Collection to generate a response. It uses the recursive summarization technique to overcome the LLM's context limitations. The process requires multiple LLM calls. Applicable when the prompt is asking for a summary of the context or a lengthy answer such as a procedure that might require multiple large pieces of information to process.
The vector search is repeated as in RAG but this time k neighboring chunks are added to the retrieved chunks. These returned chunks are then sorted in the order they appear in the document so that neighboring chunks stay together. The expanded set of chunks is essentially a filtered sub-document of the original document, but more pertinent to the user's question. Enterprise h2oGPTe then summarizes this sub-document while trying to answer the user's question. This step uses the summary API, which applies the prompt to each context-filling chunk of the sub-document. It then takes the answers and joins 2+ answers and subsequently applies the same prompt, recursively reducing until only one answer remains.
The benefit of this additional complexity is that if the answer is throughout the document, this mode is able to include more information from the original document as well as neighboring chunks for additional context.
-
All Data RAG
This option is similar to summary RAG, but includes all document chunks, no matter how large the collection. It uses the recursive summarization technique to overcome the LLM's context limitations. The process requires multiple LLM calls and can be very computationally expensive, but will guarantee that no part of the document is excluded.
- Submit and view feedback for this page
- Send feedback about Enterprise h2oGPTe to cloud-feedback@h2o.ai