Models
Overview
The Models page allows you to run self-tests on the large language models (LLMs) used across Enterprise h2oGPTe. On the Models page, you can observe a range of metrics associated with a model on the LLMs tab. In the Charts tab, you can compare various models across several selected metrics by adjusting the x and y axes to these different metrics. Additionally, in the Usage and performance tab, you can get an overview of your estimated LLM usage in the last 24 hours, including details on quotas, cost estimates, and usage breakdown by specific LLMs.
Run self-tests
Overview
A self-test enables you to evaluate the LLMs used across Enterprise h2oGPTe to generate a response to a query and process and summarize a Document.
Instructions
To run a self-test, consider the following steps:
- In the Enterprise h2oGPTe navigation menu, click Models.
- Click Run self-tests.
- In the Run self-tests list, select a self-test.
options
- Quick test (chat-like short query): This self-test evaluates the model's ability to respond to brief, conversational queries accurately and contextually.
- RAG test (large context query): This self-test evaluates the model's ability to understand and respond accurately to queries that require it to process and maintain a long context or multiple pieces of information over an extended conversation.
- Full test (full context query): This self-test evaluates the model's ability to understand, retain, and use the information provided across a conversation to respond to complex, multi-part queries. It requires the model to keep track of various details and offer responses that synthesize all the given information.
noteThis option is only available to an admin.
- Stress test (repeated full test): This self-test evaluates the model's consistency, accuracy, and contextual awareness over multiple interactions on the same topic. It ensures the model can handle information continuity over several sessions, maintaining the context and providing accurate responses.
:::noteThis option is only available to an admin.
- (Conditional step) If you selected Full test or Stress test, consider the following steps:
- Full test
- In the Run full tests box, click Run tests.
- Stress test
- In the Run stress tests box, click Run tests.
- Full test
Tabs
LLMs
Overview
The LLMs tab contains a table of large language models (LLMs) utilized to generate responses to user queries and summarize and process Documents.

Instructions
To access the LLMs tab, consider the following steps:
- In the Enterprise h2oGPTe navigation menu, click Models.
- Click the LLMs tab.
Charts
Overview
The chart in the Charts tab allows you to compare various models across several selected metrics by adjusting its x and y axes to these metrics. These models generate responses to user queries and summarize and process Documents.
For example, in the image below, the chart compares the performance and usage characteristics of various large language models (LLMs). The x-axis shows the estimated typical cost per query (in USD), while the y-axis displays the RAG benchmark accuracy percentage.
The chart includes several data points representing different LLMs, such as GPT-4, Meta-Llama, and Mistral. Each data point is labeled with the model name and some additional information, such as the version number or specific capabilities.
In this example, the top right of the chart indicates models with higher accuracy and higher cost per query, while the bottom left shows models with lower accuracy and lower cost per query.
The chart can be useful for researchers, developers, or users to compare the performance and cost-effectiveness of different large language models. This can help them select the most appropriate model for their needs or applications.
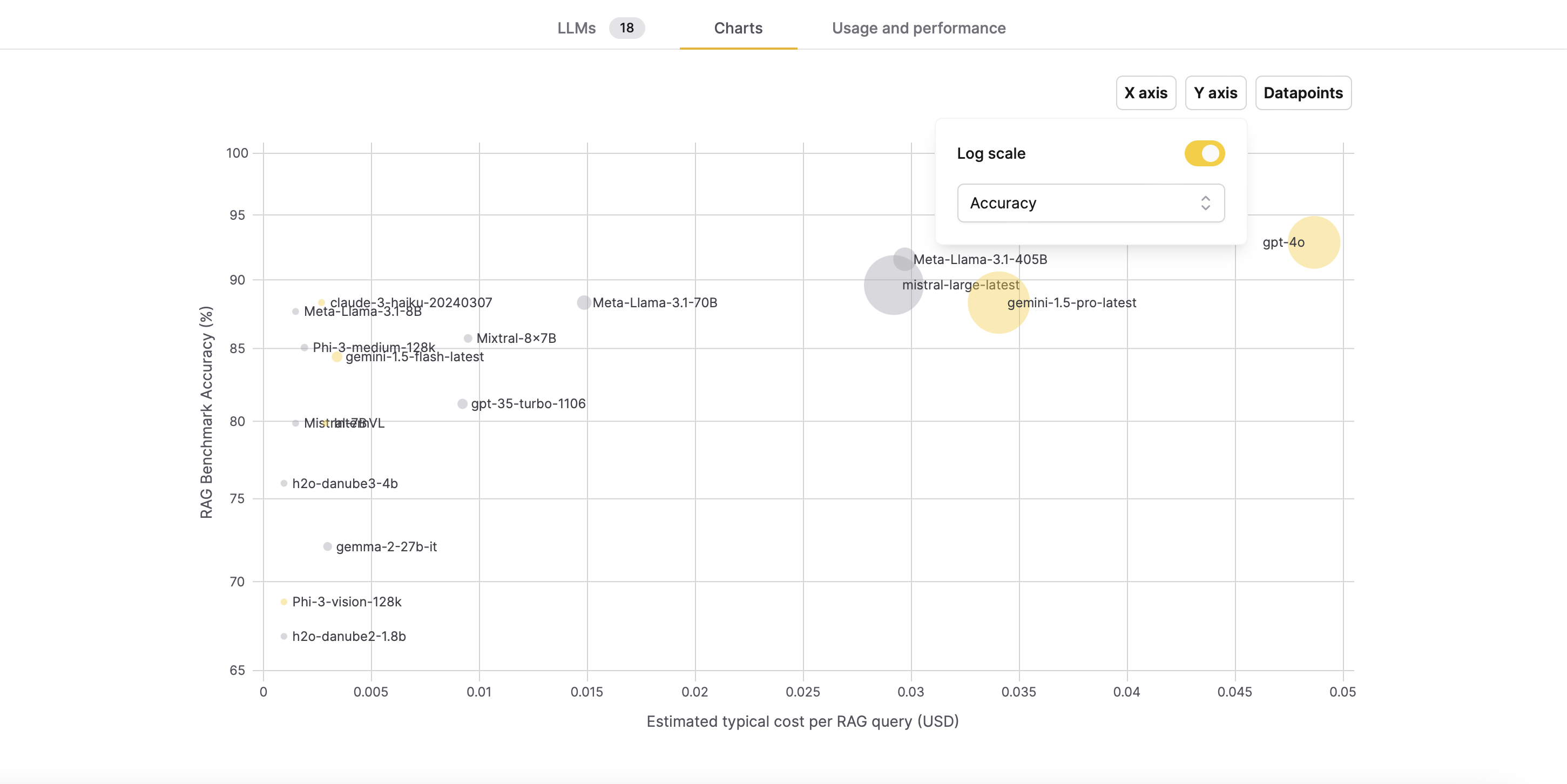
Log-scaling the x/y axis of the graph means transforming the x/y axis values using a logarithmic function. This transformation is particularly useful when dealing with data that spans several orders of magnitude, as it can help visualize the data more clearly by compressing the scale of large values and expanding the scale of small values.
Instructions
To access the Charts tab, consider the following steps:
- In the Enterprise h2oGPTe navigation menu, click Models.
- Click the Charts tab.
Usage and performance
Overview
The Usage and performance tab provides an overview of your approximated large language model (LLM) usage in the last 24 hours. The section includes details on quotas, cost estimates, and usage breakdown by specific LLMs.
The daily quotas and cost estimates are configured by administrators.
Instructions
To access the Usage and performance tab, consider the following steps:
- On Enterprise h2oGPTe navigation menu, click Models.
- Click the Usage and performance tab.
- Daily quota: The daily allocation for LLM usage.
- Percentage used: The percentage of the daily quota that has been utilized.
- Usage: The cost incurred for LLM usage within the last 24 hours.
- [Cost], [Speed], or [Latency] by LLM: This section covers the cost, speed, or latency of each LLM incurred in a given timeframe.
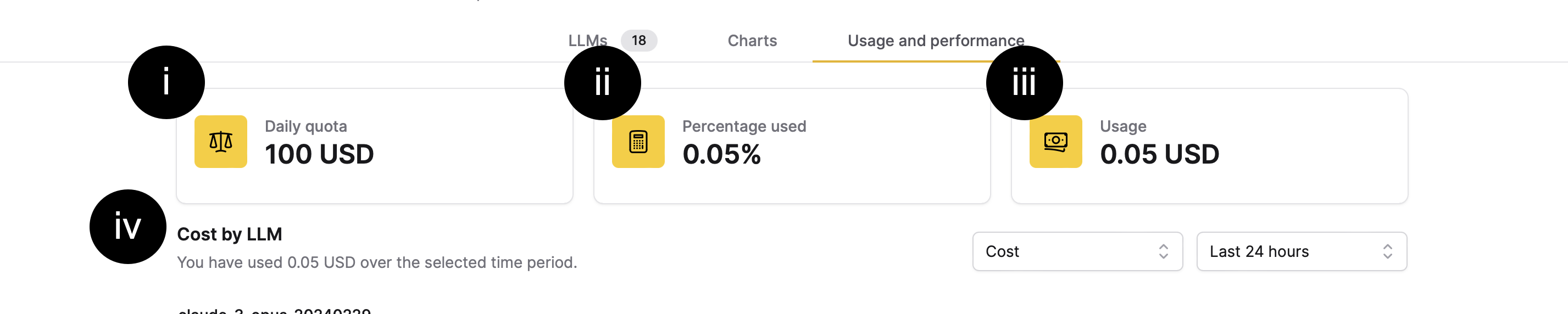
The [Cost], [Speed], or [Latency] by LLM section defaults to displaying usage within the last 24 hours. However, you can choose different time frames to see usage information within the Last hour, Last 24 hours, Last week, Last month, or All time.
- Submit and view feedback for this page
- Send feedback about Enterprise h2oGPTe to cloud-feedback@h2o.ai