Task 1: Build H2O Driverless AI model
Import dataset
This tutorial will utilize the following renowned dataset: Default of Credit Card Clients. The dataset is a comprehensive collection of information regarding credit card clients, their payment behaviors, and whether they defaulted on payments in the subsequent month. It originates from a study conducted in Taiwan and is commonly utilized in machine learning and data analysis tasks. In H2O Driverless AI, let's import the dataset.
- Conditional step: If you already know how to access H2O Driverless AI v1.10.7 in the H2O AI Cloud, skip to step 2.
- In the H2O AI Cloud navigation menu, click MY AI ENGINES.
- Click Create AI Engine.
- Click the Driverless AI card.
- In the Display Name box, enter a name for the AI Engine.
- In the Version list, select 1.10.7.
- Click Create.
- In the My AI Engines list, find your AI Engine, and when the Status shows Running, click Visit.
- Click + ADD DATASET (OR DRAG & DROP).
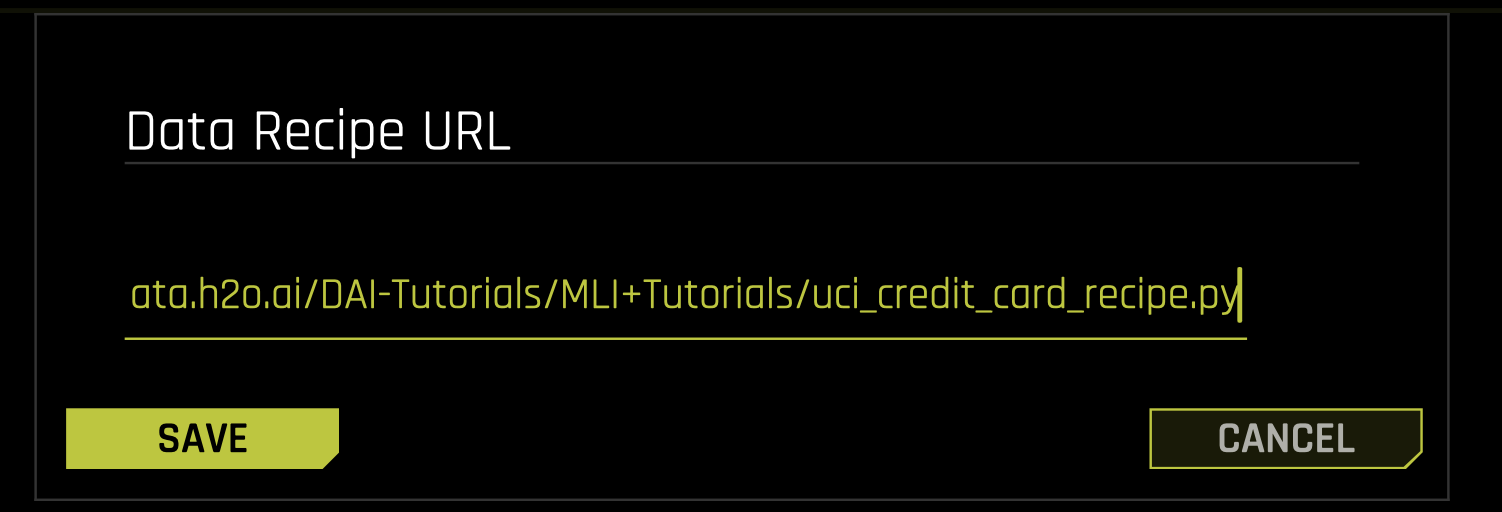
- Select DATA RECIPE URL.
- In the Data Recipe URL box, enter:
https://s3.amazonaws.com/data.h2o.ai/DAI-Tutorials/MLI+Tutorials/uci_credit_card_recipe.py - Click Save.
Explore dataset
Now, let's better understand the dataset.
- In the Datasets table, click UCI_Credit_card.csv.
- Select DETAILS.
| Column | Description |
|---|---|
| ID | This column represents a unique identifier for each individual in the dataset, allowing for distinction between different persons, typically assigned sequentially. |
| LIMIT_BAL | This column denotes the credit limit assigned to each individual, representing the maximum amount of credit they are permitted to borrow from the credit card issuer. |
| SEX | This column indicates the gender of each individual, with values representing male (1) or female (2). |
| EDUCATION | This column represents the education level of each individual, categorized into different levels such as graduate school (1), university (2), high school (3), or others (4). |
| MARRIAGE | This column denotes the marital status of each individual, categorized as married (1), single (2), or others (3). |
| AGE | This column represents the age of each individual in years. |
| PAY_1 to PAY_6 | These columns represent the history of past payments, tracking monthly payment records from April to September 2005. In other words, these columns represent each individual's repayment status over six consecutive months, from April 2005 (PAY_6) to September 2005 (PAY_1). The repayment status is categorized on a scale where -1 indicates payment made duly, and values from 1 to 9 indicate payment delays of one month up to nine months or more. |
| BILL_AMT1 to BILL_AMT6 | These columns indicate the amount of bill statements for each individual over six consecutive months, from April 2005 (BILL_AMT6) to September 2005 (BILL_AMT1). |
| PAY_AMT1 to PAY_AMT6 | These columns represent the amount of previous payments made by each individual over six consecutive months, from April 2005 (PAY_AMT6) to September 2005 (PAY_AMT1). |
| default payment next month | This column indicates whether a client defaulted on their next payment. As observed in the dataset, we possess a feature indicating whether a client defaulted on their payment for the following month. This feature, known as "default payment next month," essentially corresponds to whether PAY_7 defaulted (PAY_7 is not a column in our dataset). As specified in the Introduction section, our aim is to develop a classification model to predict whether an individual will default on their next payment, specifically on PAY_7. In this context, a value of 1 in the "default payment next month" feature typically signifies default, indicating the individual failed to pay their credit card bill on time, while a value of 0 suggests no default, representing timely payment. |
Build model
Now that we better understand the dataset let's develop a classification model capable of predicting the probability of a credit card client defaulting on their upcoming credit card payment.
- Click DATASET ACTIONS.
- Select PREDICT.
- In the DISPLAY NAME box, enter:
model-to-h2o-mlops - Click Select target column.
- Select default payment next month.
- Adjust the ACCURACY setting by clicking the + button until the accuracy reaches 6.
- Adjust the INTERPRETABILITY setting by clicking the + button until the accuracy reaches 7.
- Click LAUNCH EXPERIMENT.
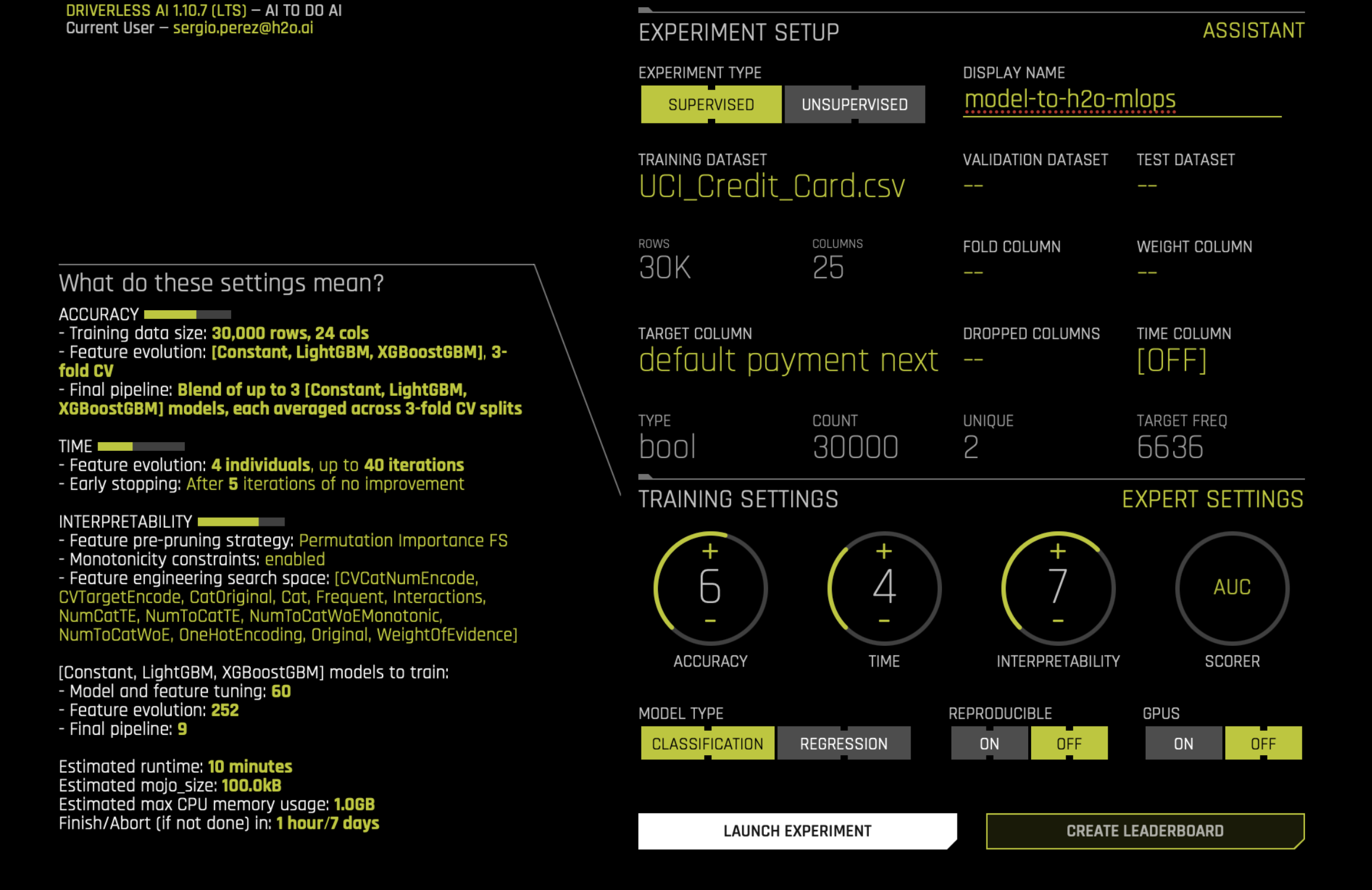
Scorer (AUC): H2O Driverless AI automatically chooses the optimal scorer, considering the problem type and other factors. In binary classification tasks, the default scorer is AUC (Area Under the ROC Curve). Nevertheless, you can manually select an alternative scorer if necessary.
- Submit and view feedback for this page
- Send feedback about H2O Driverless AI | Tutorials to cloud-feedback@h2o.ai