Task 3: Launch Sentiment Analysis Experiment
Now that we have a better understanding of the dataset, let's build the experiment from scratch.
In the DATASETS page, click on the
AmazonFineFoodReviews-train-26k.csvdataset, and select the PREDICT option.As soon as you select the Predict option, you are asked if you want to take a tour of the Driverless AI environment. Skip it for now by clicking Not Now.
Feed the following information into Driverless AI:
 note
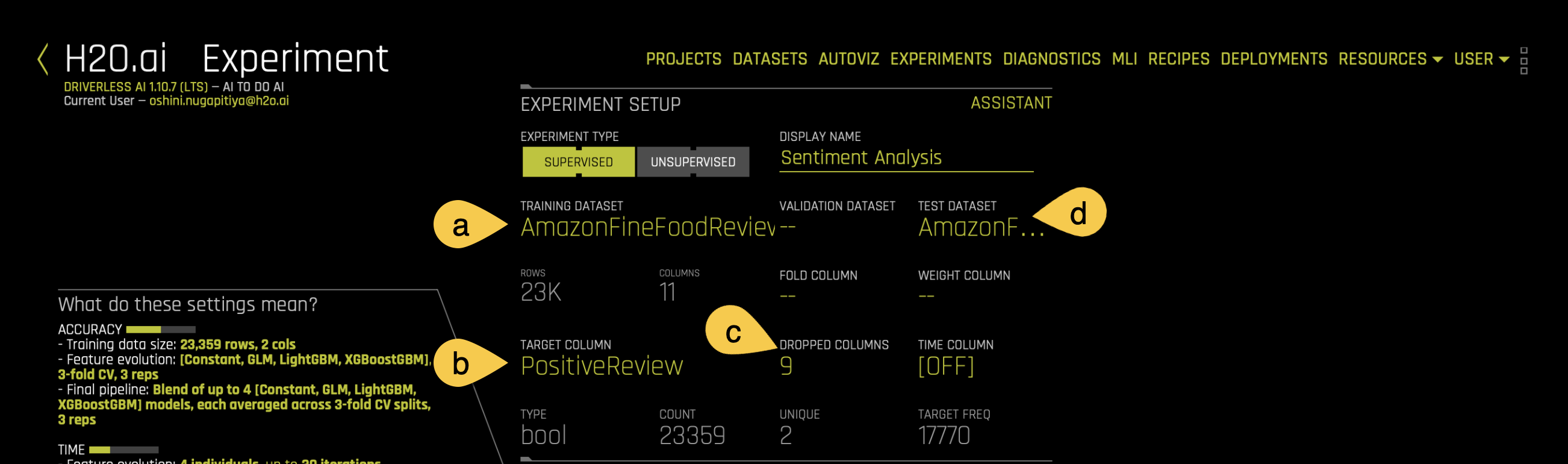
notea. Display Name - Name the current experiment:
Sentiment Analysis.b. Target Column - Select PositiveReview as the target column. The aim of the experiment is to try to predict whether a given review is positive or negative, hence the PositiveReview is selected as the target column. The column has only two values, i.e Positive and Negative.
c. Dropped Columns - For this experiment, only text columns are selected. Therefore we only use the text columns. Drop all columns that are not in the text format and keep only the Description column. Please note that if you decide to keep the non-text columns, the NLP algorithms will still work on the non-text columns.
d. Test Dataset - The Test dataset is a dataset used to provide an unbiased evaluation of a
finalmodel fit on the training dataset. It is not used during training of the model. Select theAmazonFineFoodReviews.csv.testdataset for the test dataset option.
In Task 4: Configure training settings, let's continue editing the experiment settings.
- Submit and view feedback for this page
- Send feedback about H2O Driverless AI | Tutorials to cloud-feedback@h2o.ai