Task 4: Configure training settings
Let's explore the settings that will enable us to run an effective NLP experiment and adjust them accurately.

a. Accuracy - accuracy stands for relative accuracy, i.e., higher values should lead to higher confidence in model performance (accuracy). The accuracy setting impacts which algorithms are considered, level of assembling, and types of feature engineering.
- Therefore, set the Accuracy value to 5
b. Time - time is the relative time for completing the experiment. Higher values will lead to experiments taking longer.
- Therefore, set the Time value to 2
c. Interpretability - interpretability is the degree to which a human can understand the cause of the decision. It controls the complexity of the models and features allowed within the experiments (e.g., higher interpretability will generally block complicated features, feature engineering, and models).
- Therefore, set the Interpretability value to 5
d. Scorer - the scorer is the metric used to evaluate the machine learning algorithm. The scorer used for this experiment is the LogLoss or logarithmic loss metric, which is used to evaluate the performance of a binomial or multinomial classifier. Unlike AUC, which looks at how well a model can classify a binary target, log loss evaluates how close a model’s predicted values (uncalibrated probability estimates) are to the actual target value. The lower the Logloss value, the better the model can predict the sentiment.
- Therefore, set the scorer to LOGLOSS
e. Expert Settings - several configurable settings are available for NLP experiments in Driverless AI, which can be tuned according to the experiment type. To tune the NLP settings, click on the Expert Settings, and navigate to the NLP tab:
- In the NLP section under Feature Engineering tab, note the following particular settings that users can use for any NLP experiment:
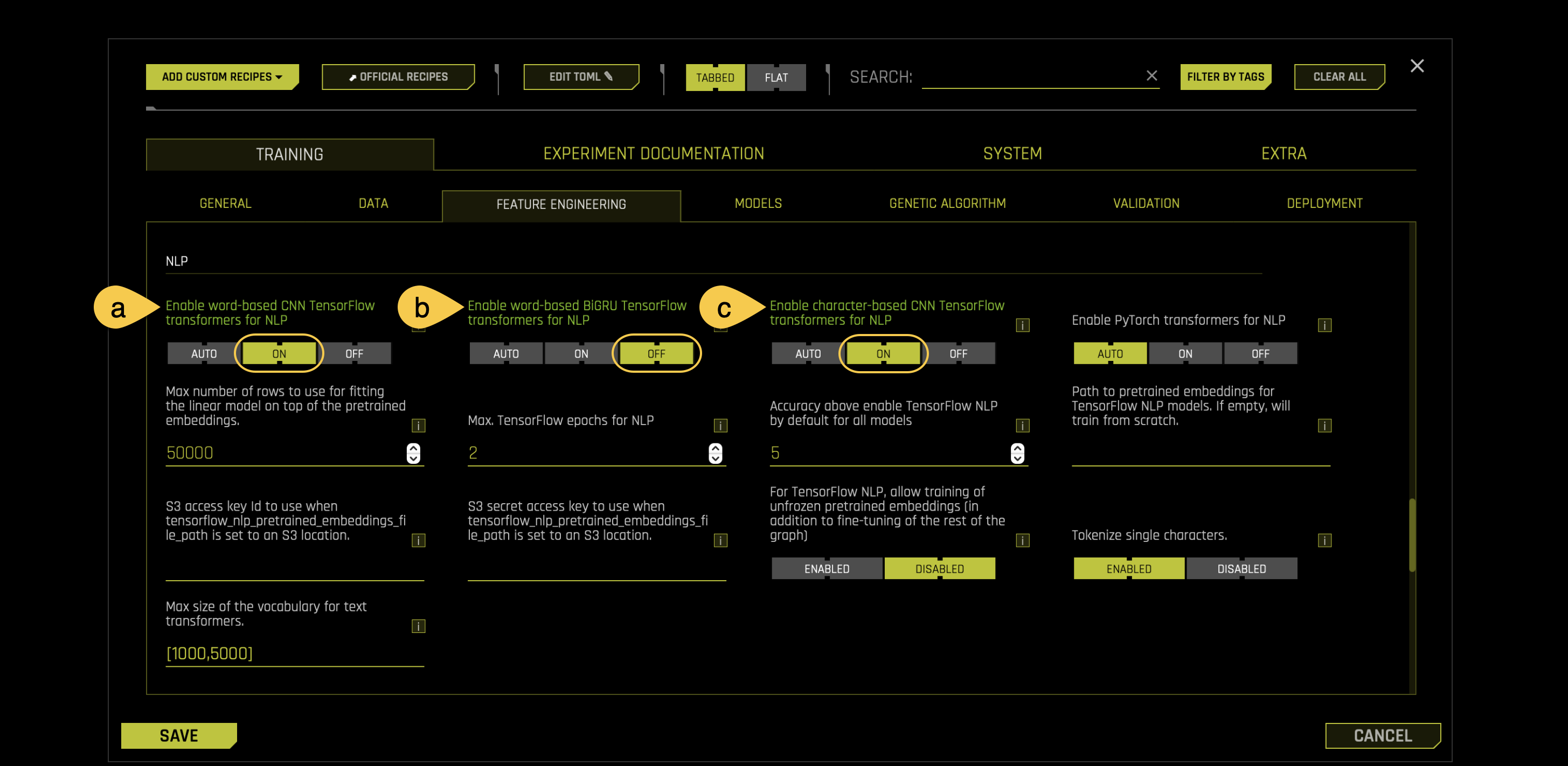
a. Word-Based CNN TensorFlow transformers for NLP: Specify whether to use Word-based CNN(Convolutional Neural Network) TensorFlow models for NLP. This option is ignored if TensorFlow is disabled. We recommend that you disable this option on systems that do not use GPUs.
- For this experiment set this setting ON
b. Word-Based BiGRU TensorFlow transformers for NLP: Specify whether to use Word-based BiGRU TensorFlow models for NLP. This option is ignored if TensorFlow is disabled. We recommend that you disable this option on systems that do not use GPUs.
- For this experiment set this setting OFF
c. Character-Based CNN TensorFlow transformers for NLP: Specify whether to use Character-level CNN TensorFlow models for NLP. This option is ignored if TensorFlow is disabled. We recommend that you disable this option on systems that do not use GPUs.
- For this experiment set this setting ON
- In the NLP section, under Models, note the following particular settings that users can use for any NLP experiment:
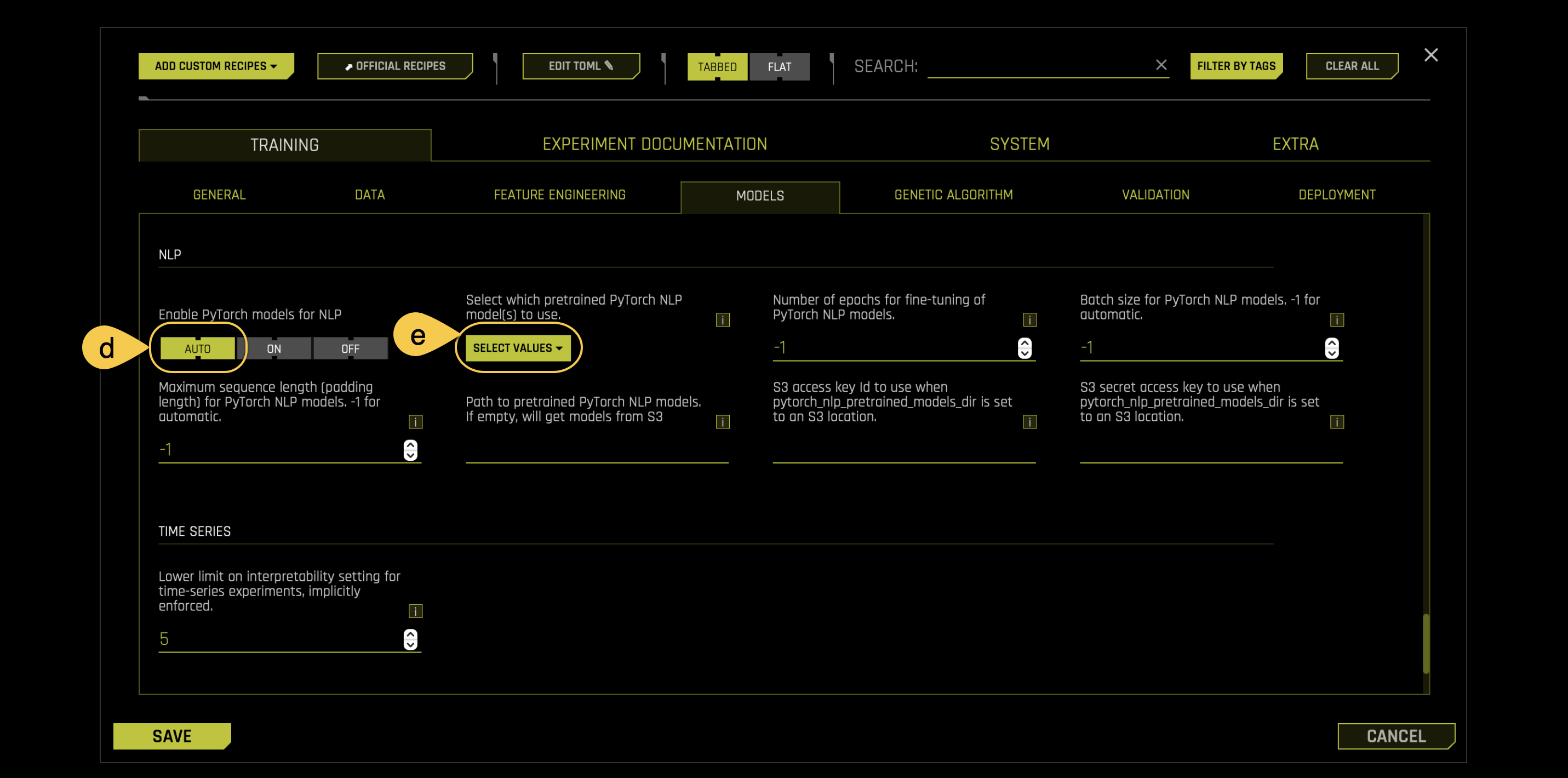
d. PyTorch Models for NLP (Experimental):
Specify whether to enable pre-trained PyTorch models and fine-tune them for NLP tasks. This is set to AUTO by default. You need to set this to ON if you want to use the PyTorch models like BERT for feature engineering or for modeling. We recommend that you use GPUs to speed up execution when this option is used.
- For this experiment set this setting to AUTO
e. Select which pretrained PyTorch NLP Model(s) to use: This setting is to be used if you enable the Pytorch Models. When you click on Select which pretrained PyTorch NLP Model(s) to use, you can specify one or more pretrained PyTorch NLP models to use from the following list:
- bert-base-uncased
- distillery-base-uncased
- xlnet-base-cased
- xlm-mlm-enfr-1024
- roberta-base
- Albert-base-v2
- camembert-base
- xlm-roberta-base
This setting requires an internet connection. Using BERT-like models may result in a longer experiment completion time. We will change nothing from this setting.
Additionally, there are three more buttons located beneath the experimental settings knob which stand for the following:
- Classification or Regression: Driverless AI automatically determines the problem type based on the response column. Though not recommended, you can override this setting by clicking this button. Our current problem is that of Classification.
- Make sure this setting is set to Classification
- Reproducible: This button allows you to build an experiment with a random seed and get reproducible results. If this is disabled (default), the results will vary between runs.
- Don't enable this setting
- GPUS Enable: Specify whether to enable GPUs. (Note that this option is ignored on CPU-only systems).
- Make sure this setting is enable
We selected the above settings to generate a model with sufficient accuracy in the H2O Driverless AI Test Drive environment.
- After configuring the above settings click Launch experiment.
The amount of time this experiment will take to complete will depend on on the memory, availability of GPU in a system, and the expert settings a user might select. If the system does not have a GPU, it might run for a longer time. You can Launch Experiment and wait for it to finish, or you can access a pre-build version in the Experiment section. After discussing few NLP concepts in the upcoming two tasks, we will discuss how to access this pre-built experiment right before analyzing its performance.
- Submit and view feedback for this page
- Send feedback about H2O Driverless AI | Tutorials to cloud-feedback@h2o.ai