Register models in the MLflow Model Registry
In order to register H2O Driverless AI (DAI) and H2O-3 models in the MLflow Model Registry, you must download the Python H2O.ai MLflow Custom Flavor wheel file and install it in your MLflow cluster. You can download the required wheel file from the H2O MLOps downloads page. The Python H2O.ai MLflow Custom Flavor wheel file saves the DAI or H2O-3 model as a MLflow custom flavor that's compatible with the MLflow model specification and supported as part of the H2O MLOps model ingestion process.
Install the H2O MLflow wheel file
Download the Python H2O.ai MLflow Custom Flavor wheel file from the H2O MLOps downloads page.
In Azure Databricks, go to the Compute page, and then select an existing compute instance or create and select a new one.
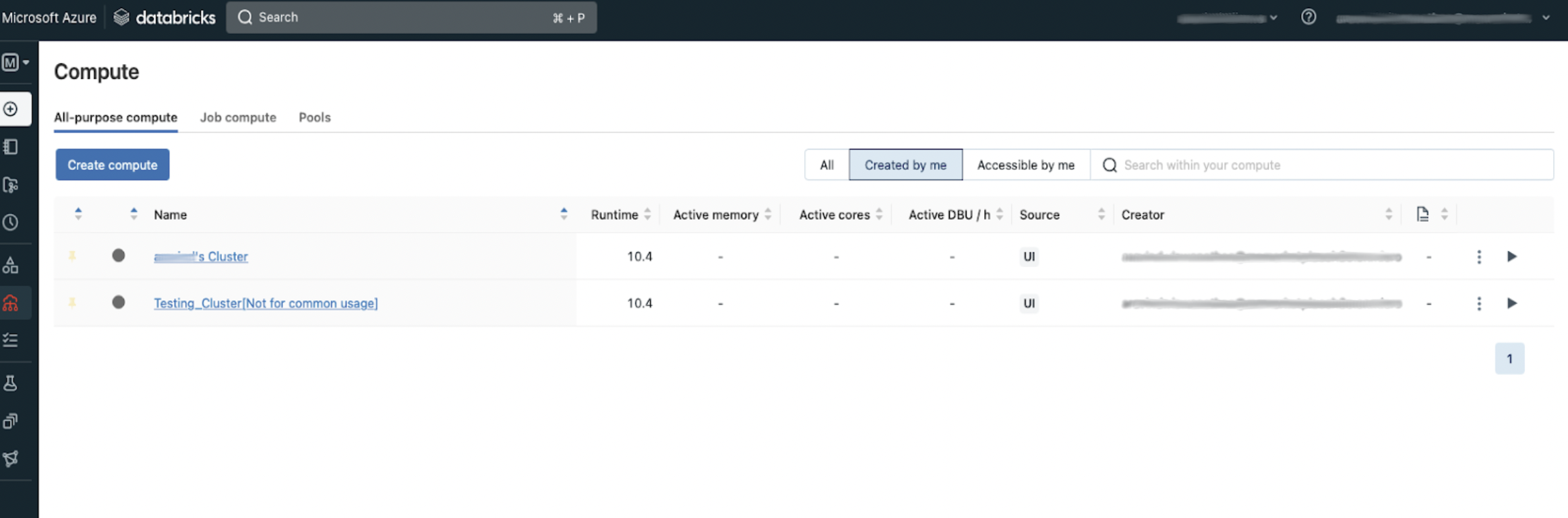
Click the Libraries tab.
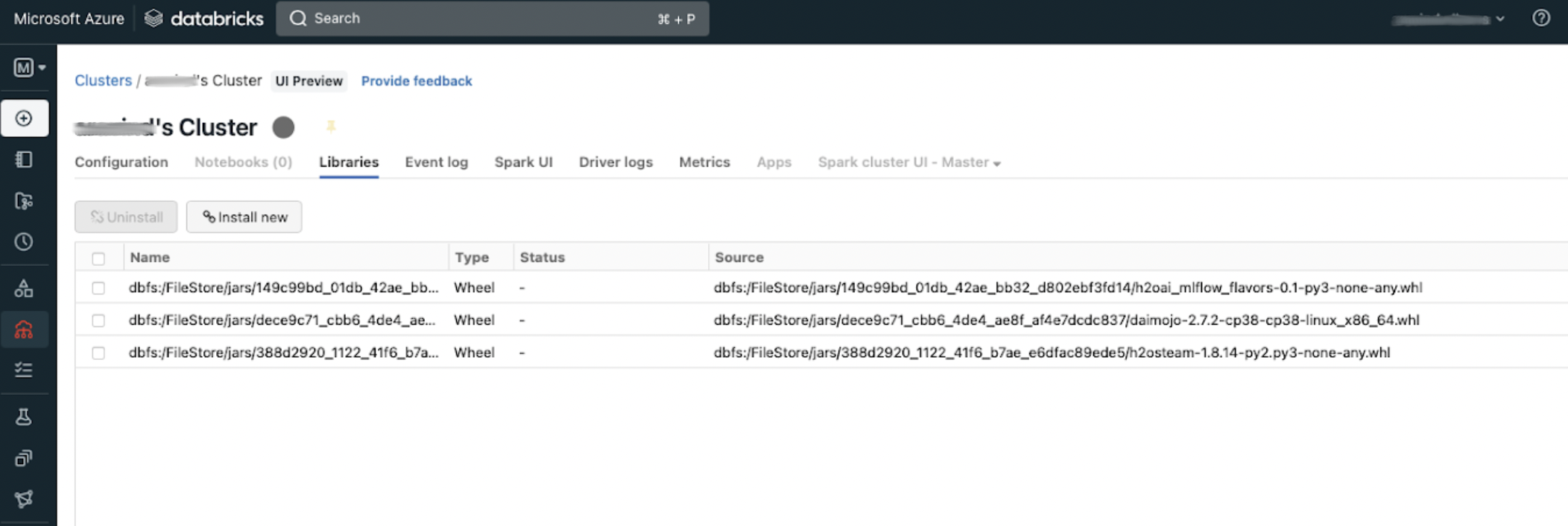
Click the Install New button.
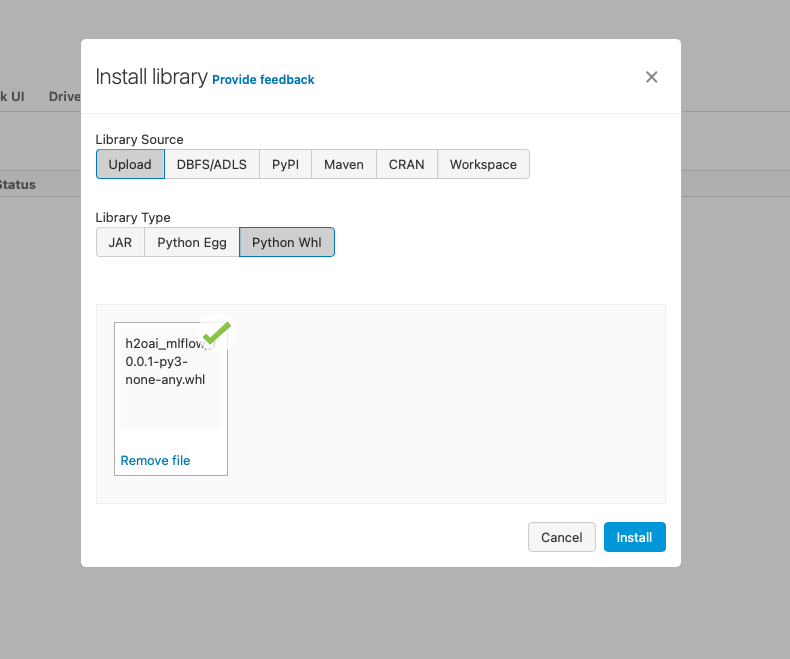
Select the Python H2O.ai MLflow Custom Flavor wheel file that you downloaded in step one.
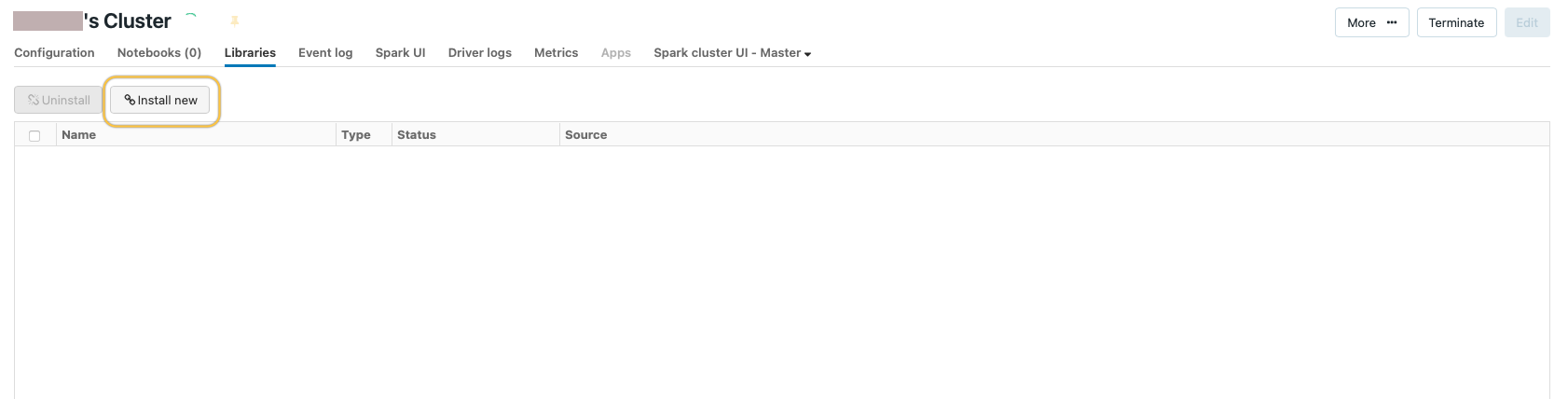
When the installation is finished, click More > Restart.
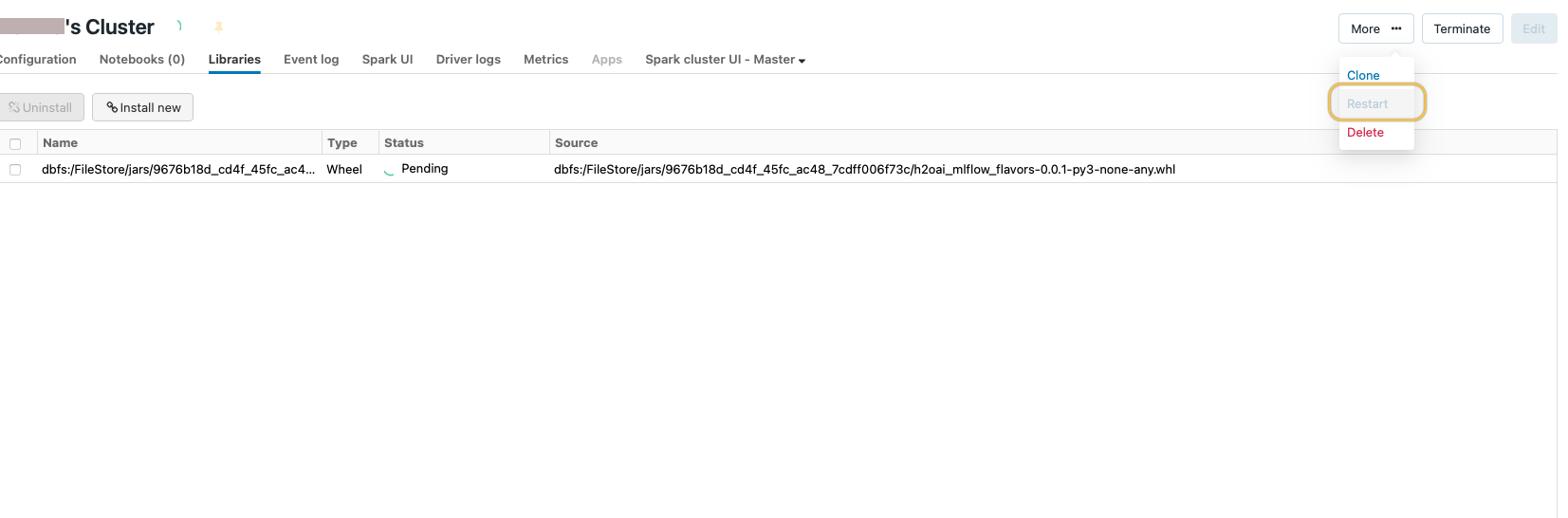
If you don't have the level of access necessary to install the wheel file, contact your administrator for assistance.
Register DAI models in the MLflow Model Registry
To register DAI models in the MLflow Model Registry, run the following Python commands.
# Ensure that driverlessai, h2osteam and the DAI MLflow flavor are installed in your cluster.
# Install the DAI MLflow flavor.
pip install h2oai_mlflow_flavors
# Import the required libraries.
import driverlessai
import os
import h2osteam
from h2osteam.clients import DriverlessClient
# Connect to an existing DAI instance.
Name='<dai_instance>'
h2osteam.login(url="<steam_url>", username="<user_id>", password="steam_token>", verify_ssl=True)
instance = DriverlessClient.get_instance(name=Name)
instance.start()
# instance=DriverlessClient().get_instance(name="query")
# instance=DriverlessClient().get_instance(name="Dai_test")
instance.details()
# Get the DAI instance details.
import h2osteam
from h2osteam.clients import DriverlessClient
name='mw-dai-mlflow-test'
h2osteam.login(url="<steam_url>", username="<user_id>", password="steam_token>", verify_ssl=True)
instance = DriverlessClient().get_instance(name=Name)
client = instance.connect(use_own_client=True)
instance.details()
dai=client
# Get all experiments from the DAI instance.
experiment_list = dai.experiments.list()
experiment_list
# Select an experiment.
exp = experiment_list[0]
exp
# Download the experiment MOJO and Python pipeline.
import os
exp.artifacts.create('python_pipeline')
exp.artifacts.download(only='python_pipeline', dst_dir='/dbfs/FileStore/DAI_Experiments/', overwrite=True)
exp.artifacts.download(only='mojo_pipeline', dst_dir='/dbfs/FileStore/DAI_Experiments/', overwrite=True)
# Import the log_model function
from h2o_mlflow_flavors.driverless import log_model
# Log an experiment in MLflow.
# Use scorer.zip for a Python pipeline.
# Use mojo.zip for a MOJO.
log_model(h2o_dai_artifact_location="/dbfs/FileStore/DAI_Experiments/scorer.zip", artifact_path ="<name_of_model>")
# Alternatively, manually create a registered model or version.
log_model(h2o_dai_artifact_location="/dbfs/FileStore/DAI_Experiments/scorer.zip", artifact_path ="<name_of_model>")
Register H2O-3 models in the MLflow Model Registry
To register H2O-3 models in the MLflow Model Registry, run the following Python commands.
# Install and import the required libraries.
pip install h2o
pip install h2oai_mlflow_flavors
import h2o
import mlflow
import h2osteam
from h2osteam.clients import H2oClient
from h2osteam.clients import H2oKubernetesClient
from h2o.estimators import H2ODeepLearningEstimator
from h2o_mlflow_flavors.h2o3 import log_model
# Log in to Steam and create H2O-3 clusters.
h2osteam.login(url="https://steam.cloud-qa.h2o.ai/", username="<username>",password="<steam_token>", verify_ssl=True)
h2osteam.print_profiles()
h2osteam.print_python_environments()
H2oKubernetesClient().get_clusters()
cluster_name="<name_chosen_for_cluster>"
try:
cluster = H2oKubernetesClient.get_cluster(cluster_name)
cluster.connect()
except:
print("Cluster is not running")
cluster = H2oKubernetesClient.launch_cluster(name=cluster_name,
profile_name="default-h2o-kubernetes",
version="3.38.0.3",
node_count=4,
cpu_count=1,
gpu_count=0,
memory_gb=4,
max_idle_h=2,
max_uptime_h=8,
timeout_s=600
# Connect to the cluster.
while 1:
if cluster.is_running():
cluster.connect()
break
h2o.ls()
# Ensure that the dataset is available in the location you specify.
# If necessary, modify the path to the location of the dataset file.
insurancePath="/dbfs/FileStore/tables/insurance.csv"
insurance = h2o.upload_file(insurancePath)
# Preprocess your data.
insurance["offset"] = insurance["Holders"].log()
insurance["Group"] = insurance["Group"].asfactor()
insurance["Age"] = insurance["Age"].asfactor()
insurance["District"] = insurance["District"].asfactor()
# Build and train the model.
distribution="tweedie"
hidden=[1]
epochs=1000
train_samples_per_iteration=-1
reproducible=True
activation="Tanh"
single_node_mode=False
balance_classes=False
force_load_balance=False
seed=23123
tweedie_power=1.5
score_training_samples=0
score_validation_samples=0
stopping_rounds=0
dl = H2ODeepLearningEstimator(distribution=distribution,
hidden=hidden,
epochs=epochs,
train_samples_per_iteration=train_samples_per_iteration,
reproducible=reproducible,
activation=activation,
single_node_mode=single_node_mode,
balance_classes=balance_classes,
force_load_balance=force_load_balance,
seed=seed,
tweedie_power=tweedie_power,
score_training_samples=score_training_samples,
score_validation_samples=score_validation_samples,
stopping_rounds=stopping_rounds)
dl.train(x=list(range(3)),
y="Claims",
training_frame=insurance)
# Download the model as a MOJO.
artifact_location = dl.download_mojo('/dbfs/FileStore/H2O3/')
print(artifact_location)
# Add signatures. ModelSignature specifies the schema of a model's inputs and outputs.
target='Claims'
schema = []
for column in insurance.columns:
colspec = mlflow.types.ColSpec(name=column, type=mlflow.types.DataType.long)
schema.append(colspec)
input_schema = mlflow.types.Schema(inputs=schema)
output_schema = mlflow.types.Schema(
inputs=[
mlflow.types.ColSpec(name=target, type=mlflow.types.DataType.long)
]
)
model_signature = mlflow.models.ModelSignature(
inputs=input_schema, outputs=output_schema
)
# Register the model in the MLflow Model Registry.
log_model(h2o3_artifact_location=artifact_location, artifact_path ="h2o3_mojo", registered_model_name="<Name for the registered model>")
mlflow.end_run()
The preceding example is also available as a Jupyter notebook:
H2O-3 Register H2O-3 models in the MLflow Model Registry
- Submit and view feedback for this page
- Send feedback about H2O MLOps to cloud-feedback@h2o.ai