Metrics: Adversarial similarity
H2O Model Validation offers an array of metrics in the form of histograms, charts, and a table to understand an Adversarial Similarity validation test. Below, each metric is described in turn.
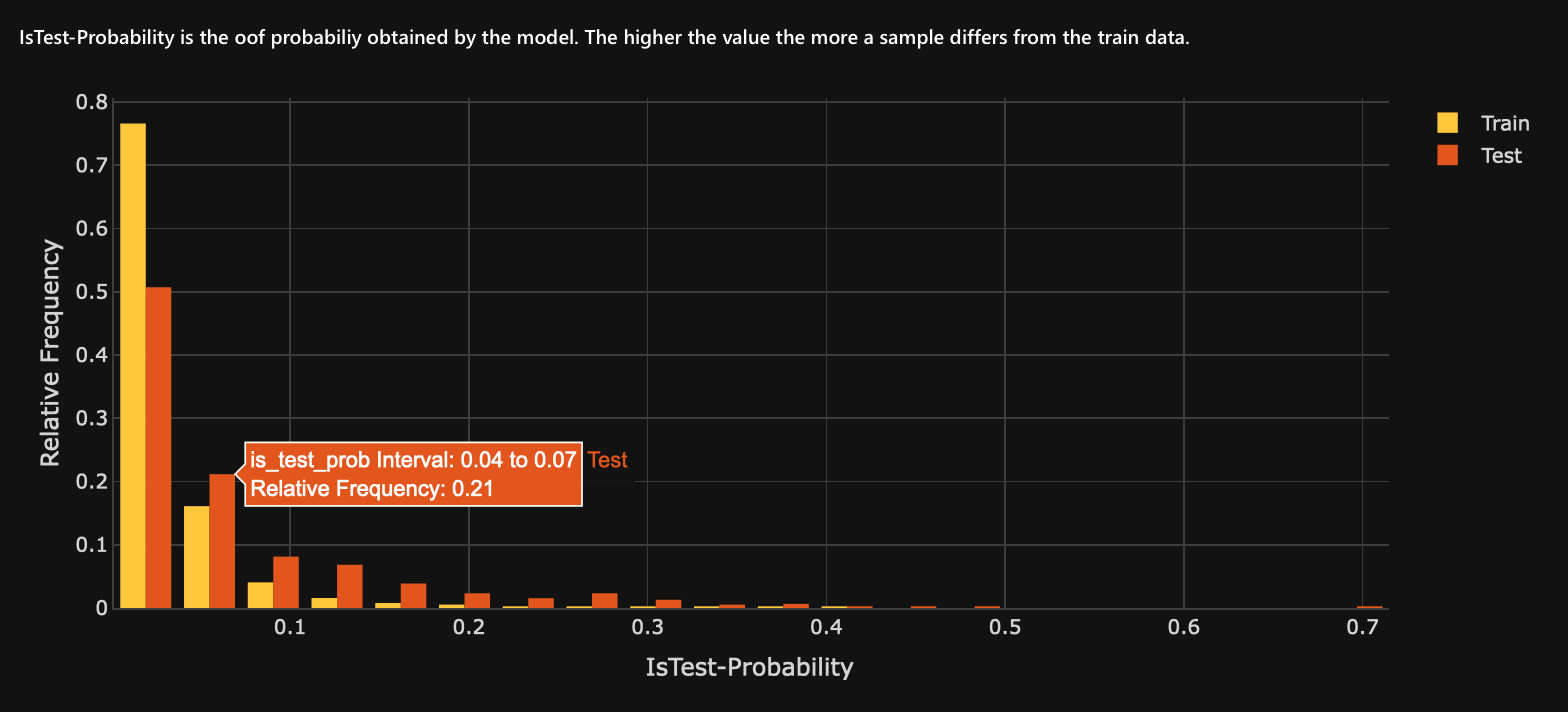
Histogram: IsReference-Probability
The IsReference-Probability histogram displays the AUC probability values obtained during the Adversarial Similarity test.
- In the Adversarial Similarity test, predictions (AUC probability values) are generated to determine how much a dataset’s row differs from those belonging to the training dataset.
- The target column is called is_test, and the predictions generated by the adversarial model are called IsReference-Probability.
- Higher IsReference-Probability values to the histogram's right will indicate a greater difference between the training dataset and the test dataset.
- A balance of IsReference-Probability values on both sides of the histogram will indicate a 1.0 AUC score (a perfect separation between the two datasets).
- The Y-axis refers to the relative frequency of an AUC probability (IsReference-Probability) value in one of the IsReference-Probability intervals.
- Futhermore, the relative frequency (Y-axis) refers to the percent-wise frequencies or number of occurrences of values in the datasets. H2O Model Validation performs this relative or percent-wise calculation to compare numbers between the training and reference datasets. Since H2O Model Validation expects each dataset to have a different size, making a fair comparison on direct frequencies will be harder. Therefore, H2O Model Validation divides the number of occurrences by the length of the dataset.
Dissimilarity score
The Dissimilarity score displays the Area Under the Curve (AUC) value for the dataset (test dataset) being compared to the training dataset. A higher AUC value indicates a higher dissimilarity.

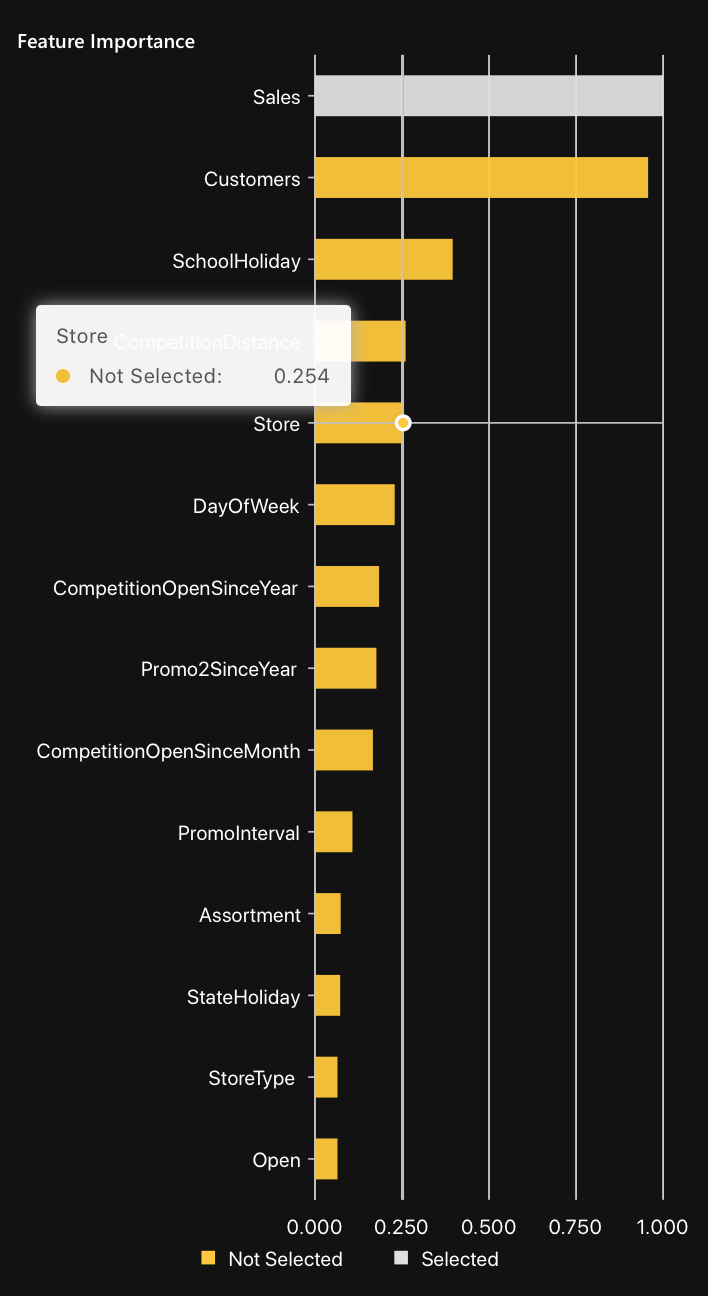
Chart: Feature importance
The Feature importance chart displays the top features generating a high AUC value for the Adversarial Similarity test. In other words, the chart displays the features from top to lowest, driving the separation between the two datasets being compared during the Adversarial Similarity test.
Clicking on the bar of a feature will trigger the display of the following plot: Plot: Feature PDP.
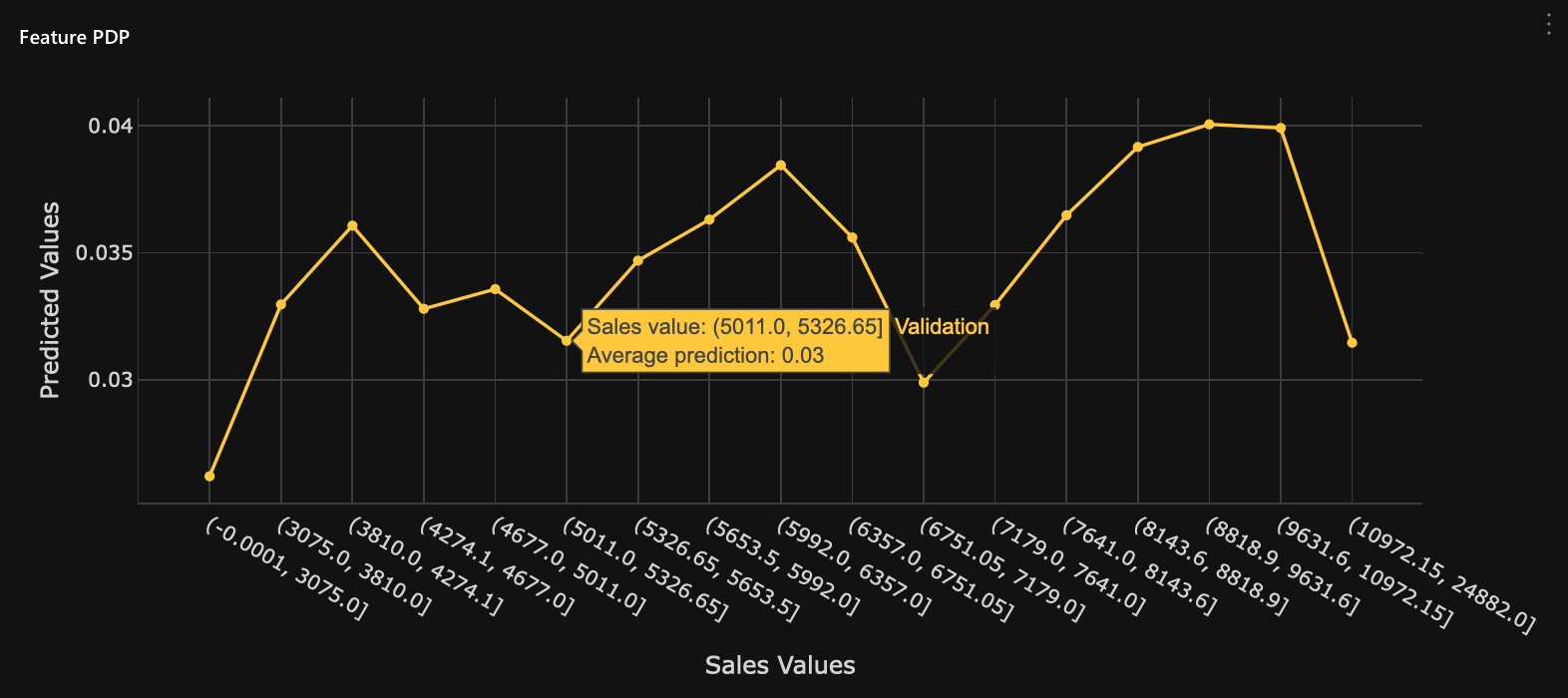
Plot: Feature PDP
The Feature Partial Dependence Plot (PDP) displays the impact the different values of the selected feature have on the predicted values. The selected feature refers to the feature (clicked) on the Feature importance chart.
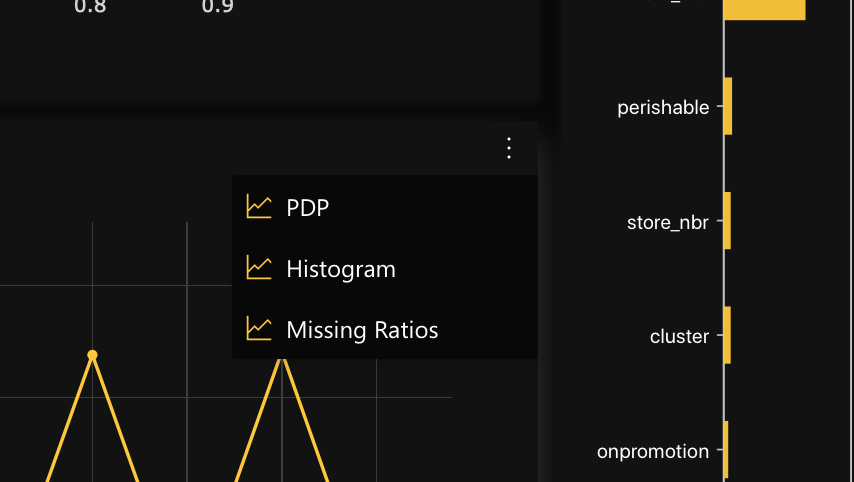
The following histogram and graph are available for the selected feature in the Feature Partial Dependence Plot (PDP):
To access either the histogram or graph above, consider the following instructions when viewing the Feature Partial Dependence Plot (PDP):
- Click Kebab menu.
- To view the Feature histogram per data, click Histogram.
- To view the Feature missing ratios graph, click Missing Ratios.
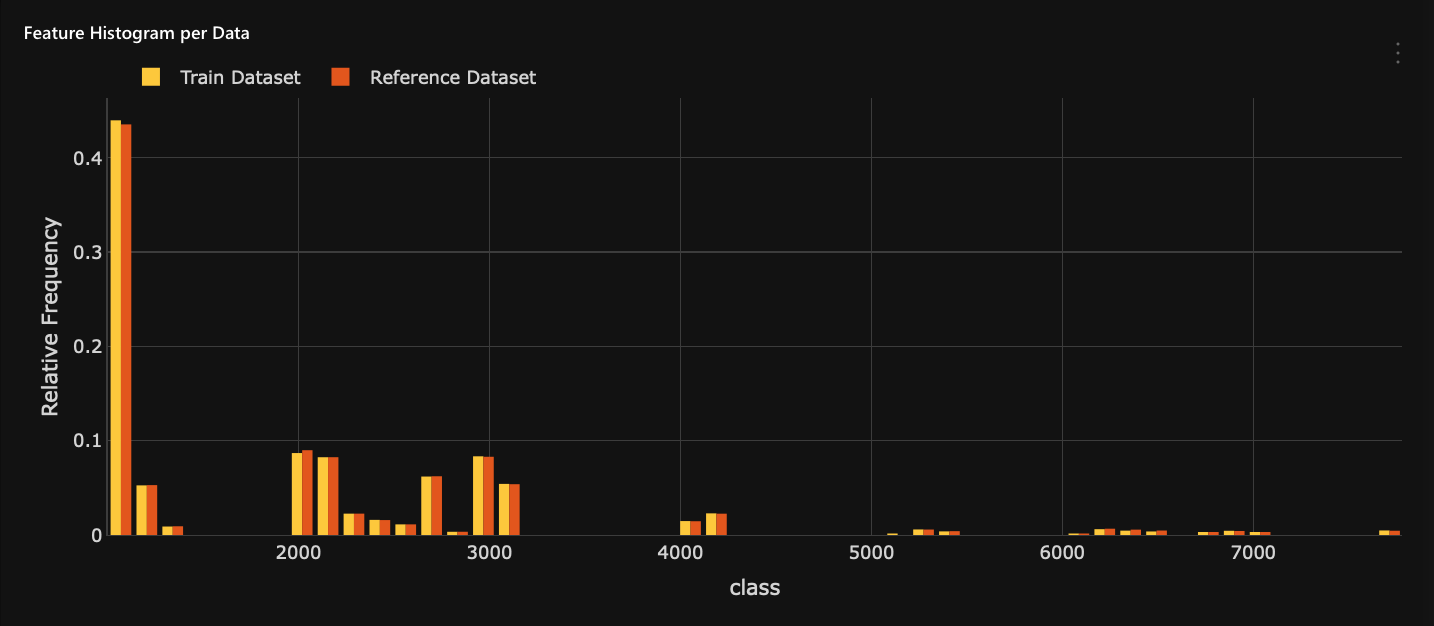
Histogram: Feature histogram per data
The Feature histogram per data displays the selected feature on the Feature importance chart.
Graph: Feature missing ratios
The Feature missing ratios graph displays any missing ratio values of the selected feature in the train and test dataset (the dataset being compared to the training dataset). The selected feature refers to the feature (clicked) on the Feature importance chart.
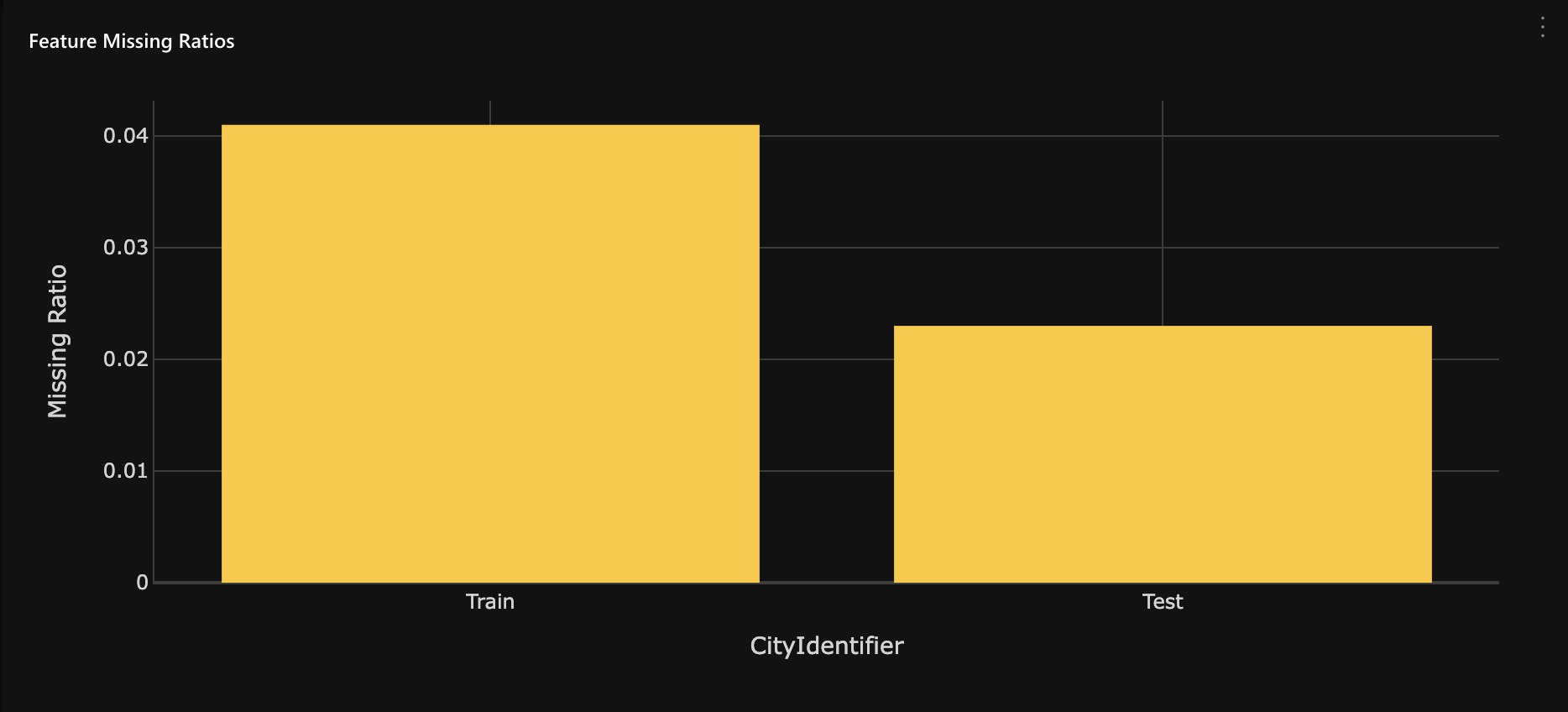
Table: Shapley
The Shapley table contains adversarial model results from a Shapley perspective. Each row in the table represents a row of the test dataset (being compared to the training dataset). Rows are ordered from the highest to lowest predictive value (is_test.1). In other words, rows higher in the table represent the rows of the test dataset most dissimilar to the training dataset.
H2O Model Validation in the Shapley table displays the top N highest (dissimilar) or lowest (similar) results (is_test.1 prediction values), where N=40.
- To display the top N highest (dissimilar) results, see Show dissimilar.
- To display the top N lowest (similar) results, see Show similar.
- To download the Shapley results of the test dataset, see Download Shapley values.

The first three columns of the Shapley table refer to the row's ID, the target column, and the predictive value given to the row, while the rest of the columns refer to the train columns of the model.
| Name | Description |
|---|---|
Adv-ID | Row ID |
Adv-IsReference | Target column |
Adv-IsReference-Probability | Predictive value given to the row |
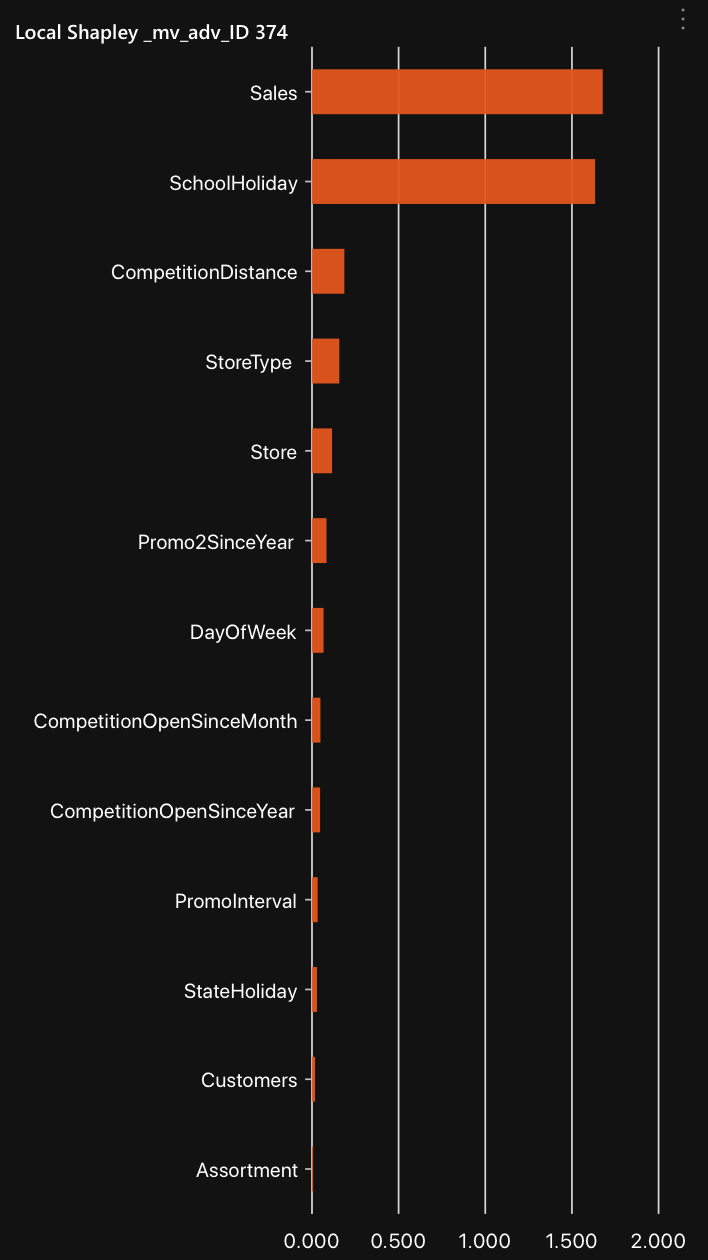
Clicking on one row ID (374) will display a local Shapley chart highlighting the highest and lowest contributing features for the row's prediction value (is_test.1).
A global Shapley chart is available for the Shapley table, which highlights the features that, on average, increase the prediction value. For more information, see Chart: Global Shapley.
Show similar
By default, rows in the Shapley table are ordered from highest to lowest predictive value (is_test.1). To switch the default order and view rows from lowest to highest predictive values, consider the following instructions:
- When viewing the Shapley table, click Show similar.
Show dissimilar
To revert to the default order of the rows in the Shapley table, where test rows are ordered from highest to lowest predictive value (is_test.1), consider the following instructions:
- When viewing the Shapley table, click Show dissimilar.
Download Shapley values
To download the Shapley values of the test dataset, consider the following instructions when viewing the Shapley table:
- Click Download Shapley Values.
The .csv file contains adversarial model results from a Shapley perspective for the test dataset (reference dataset).
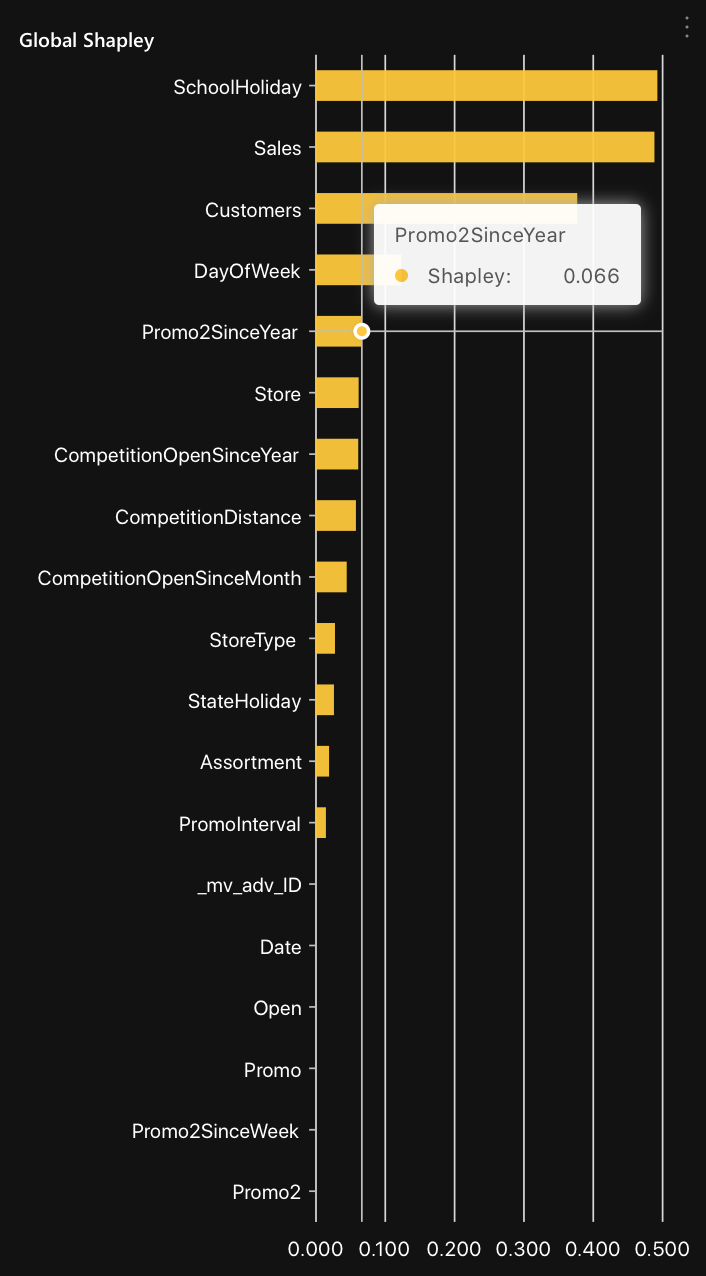
Chart: Global Shapley
The global Shapley chart displays the top features increasing the average model predictions the most, driving the most dissimilarity between the datasets.
- Submit and view feedback for this page
- Send feedback about H2O Model Validation to cloud-feedback@h2o.ai