Hive Setup¶
Driverless AI allows you to explore Hive data sources from within the Driverless AI application. This section provides instructions for configuring Driverless AI to work with Hive in native installations.
Start Driverless AI¶
This example enables the Hive connector.
Export the Driverless AI config.toml file or add it to ~/.bashrc. For example:
# DEB and RPM export DRIVERLESS_AI_CONFIG_FILE="/etc/dai/config.toml" # TAR SH export DRIVERLESS_AI_CONFIG_FILE="/path/to/your/unpacked/dai/directory/config.toml"
Edit the following values in the config.toml file.
# File System Support # upload : standard upload feature # file : local file system/server file system # hdfs : Hadoop file system, remember to configure the HDFS config folder path and keytab below # dtap : Blue Data Tap file system, remember to configure the DTap section below # s3 : Amazon S3, optionally configure secret and access key below # gcs: Google Cloud Storage, remember to configure gcs_path_to_service_account_json below # gbq: Google Big Query, remember to configure gcs_path_to_service_account_json below # minio: Minio Cloud Storage, remember to configure secret and access key below # snow: Snowflake Data Warehouse, remember to configure Snowflake credentials below (account name, username, password) # kdb: KDB+ Time Series Database, remember to configure KDB credentials below (hostname and port, optionally: username, password, classpath, and jvm_args) # azrbs: Azure Blob Storage, remember to configure Azure credentials below (account name, account key) # jdbc: JDBC Connector, remember to configure JDBC below. (jdbc_app_configs) # hive: Hive Connector, remember to configure Hive below. (hive_app_configs) # recipe_url: load custom recipe from URL # recipe_file: load custom recipe from local file system enabled_file_systems = "upload, file, hdfs, hive" # Configuration for Hive Connector. # Note that inputs are similar to configuring HDFS connectivity. # important keys: # * hive_conf_path - path to hive configuration, may have multiple files. typically: hive-site.xml, hdfs-site.xml, etc # * auth_type - one of `noauth`, `keytab`, `keytabimpersonation` for kerberos authentication # * keytab_path - path to the kerberos keytab to use for authentication, can be "" if using `noauth` auth_type # * principal_user - Kerberos app principal user. Required when using auth_type `keytab` or `keytabimpersonation` # JSON/Dictionary String with multiple keys. Example: # '{ # "hive_connection_1": { # "hive_conf_path": "/path/to/hive/conf", # "auth_type": "one of ['noauth', 'keytab', 'keytabimpersonation']", # "keytab_path": "/path/to/<filename>.keytab", # "principal_user": "hive/LOCALHOST@H2O.AI", # }, # "hive_connection_2": { # "hive_conf_path": "/path/to/hive/conf_2", # "auth_type": "one of ['noauth', 'keytab', 'keytabimpersonation']", # "keytab_path": "/path/to/<filename_2>.keytab", # "principal_user": "my_user/LOCALHOST@H2O.AI", # } # }' # hive_app_configs = """{"hive_1": {"auth_type": "keytab", "key_tab_path": "/path/to/Downloads/hive.keytab", "hive_conf_path": "/path/to/Downloads/hive-resources", "principal_user": "hive/localhost@H2O.AI"}}"""Note: The expected input of
hive_app_configsis a JSON string. Double quotation marks ("...") must be used to denote keys and values within the JSON dictionary, and outer quotations must be formatted as either""",''', or'. Depending on how the configuration value is applied, different forms of outer quotations may be required. The following examples show two unique methods for applying outer quotations.
Configuration value applied with the config.toml file:
hive_app_configs = """{"my_json_string": "value", "json_key_2": "value2"}"""
Configuration value applied with an environment variable:
DRIVERLESS_AI_HIVE_APP_CONFIGS='{"my_json_string": "value", "json_key_2": "value2"}'
Save the changes when you are done, then stop/restart Driverless AI.
After the Hive connector is enabled, you can add datasets by selecting Hive from the Add Dataset (or Drag and Drop) drop-down menu.
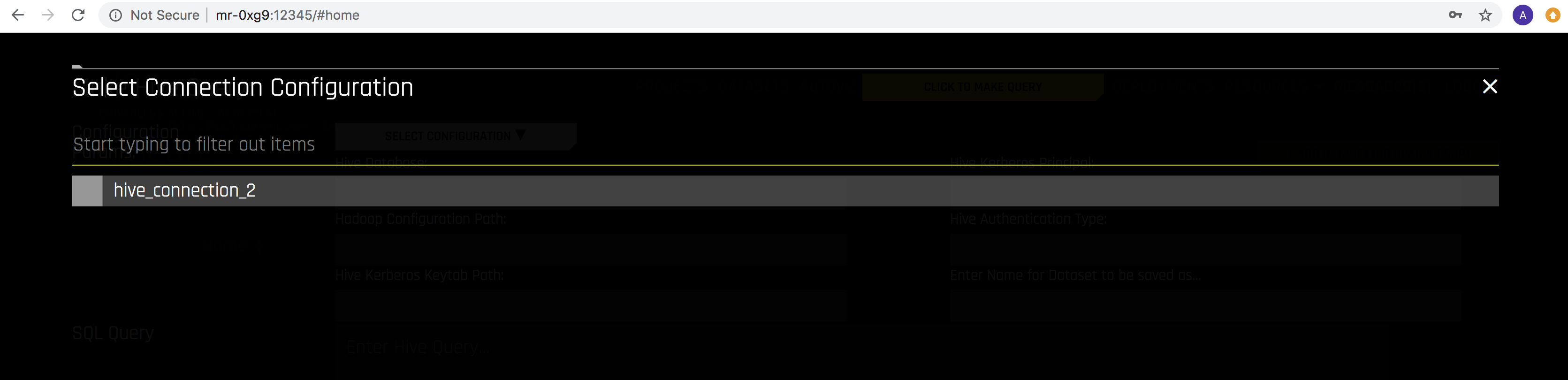
Select the Hive configuraton that you want to use.
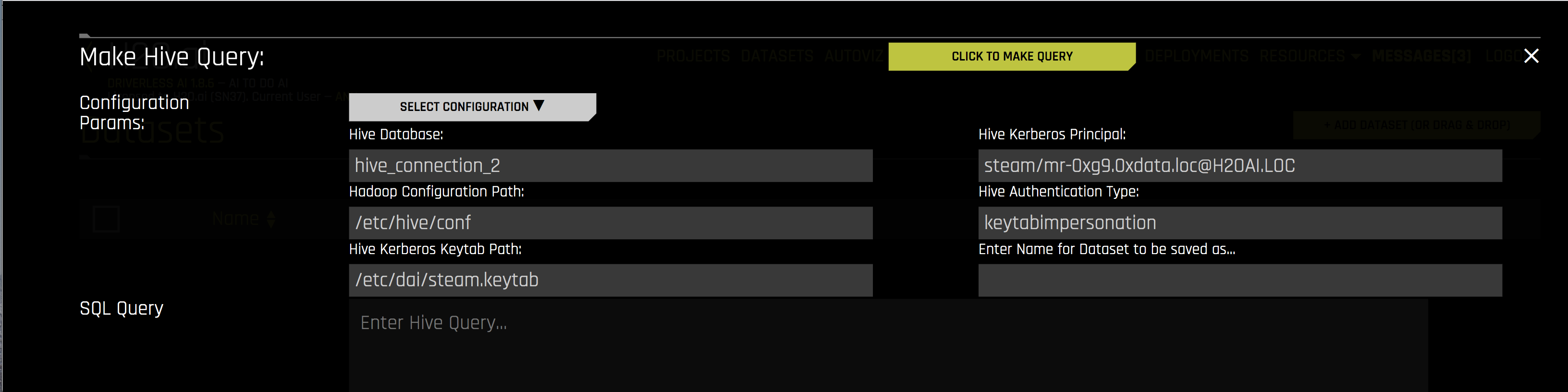
Specify the following information to add your dataset.
Hive Database: Specify the name of the Hive database that you are querying.
Hadoop Configuration Path: Specify the path to your Hive configuration file.
Hive Kerberos Keytab Path: Specify the path for the Hive Kerberos keytab.
Hive Kerberos Principal: Specify the Hive Kerberos principal. This is required if the Hive Authentication Type is keytabimpersonation.
Hive Authentication Type: Specify the authentication type. This can be noauth, keytab, or keytabimpersonation.
Enter Name for Dataset to be saved as: Optionally specify a new name for the dataset that you are uploading.
SQL Query: Specify the Hive query that you want to execute.