实验图表¶
本节介绍为运行中和已完成实验显示的仪表板图表。这些图表为交互式图表,将鼠标悬停在图表上的某个点,即可获取关于此点的更多详细信息。
二元分类实验¶
对于二元分类实验,Driverless AI 会显示 ROC 曲线、P-R 图、提升图、K-S 曲线和增益图。
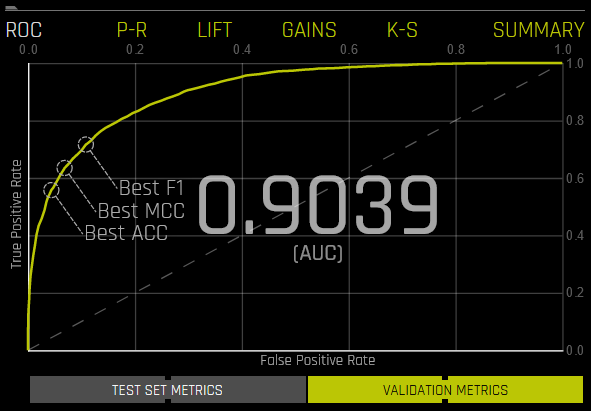
ROC 曲线:此曲线展示了验证数据的受试者工作特征曲线统计信息以及最佳准确度、MCC 值和 F1 值。ROC 曲线是十分有用的工具,因为此曲线仅关注模型区分类别的能力如何。但是,请注意,对于其中一个类别很少出现的模型,较高的 AUC 值可能会让您产生模型正在正确预测结果的错觉。这正是精确率和召回率的概念变得重要的原因。
此曲线下的面积称为 AUC。真正例率 (TPR) 是正确正例预测结果的相对分数,而假正例率 (FPR) 则是不正确正例预测结果的相对分数。每个点对应一个分类阈值(例如,如果概率 >= 0.3,则为 YES,否则为 NO)。对于每个阈值,均有表示 TPR 和 FPR 之间平衡关系的唯一混淆矩阵。通常,最有用的工作点位于左上角。
将鼠标悬停在 ROC 曲线中的某个点上,以混淆矩阵的形式查看此点的真负例、假正例、假负例、真正例、阈值、FPR、TPR、准确度、F1 值和 MCC 值。

如果为实验提供了测试集,则点击图表下方的 验证指标 按钮即可查看测试数据的统计信息。
P-R 曲线:此图展示验证数据的 P-R 曲线以及最佳准确度、MCC 值和 F1 值。此曲线下的面积称为 AUCPR。P-R 曲线是 ROC 曲线的一种补充工具,特别是当数据集显著偏斜时,尤为有用。P-R 曲线针对每个可能的分类阈值,绘制出了精确率或正例预测值(y 轴)相对灵敏度或真正例率(x 轴)的关系。在较高层次上,您可以将精确率视为对模型所获得结果的准确性或质量的度量,而召回率则是对模型所获得结果的完整性或数量的度量。P-R 曲线可度量模型所获得结果的相关性。
精确率:正确正例预测结果数 (TP)/正例总数 (TP + FP)。
召回率:正确正例预测结果数 (TP)/正例预测结果数 (TP + FN)。
每个点对应一个分类阈值(例如,如果概率 >= 0.3,则为 YES,否则为 NO)。对于每个阈值,均有表示召回率和精确率之间平衡关系的唯一混淆矩阵。对于高度不平衡的数据集,此 P-R 曲线可能比 ROC 曲线更直观。
将鼠标悬停在此图表中的某个点上,即可查看此点的真正例、真负例、假正例、假负例、阈值、召回率、精确率、准确度、F1 值和 MCC 值。
如果为实验提供了测试集,则点击图表下方的 验证指标 按钮即可查看测试数据的统计信息。
提升图:此图展示验证数据的提升统计信息。例如,”与随机选择观测值相比,正例目标类别的观测值在预测结果前 1%、2%、10% 等(累积)中的占比会多出多少倍?”根据定义,100% 的提升即为 1.0。提升图可以帮助解答以下问题:与随机模型(或无模型)相比,您期望使用预测模型得到多好的结果。提升图可度量预测模型的有效性,此有效性根据模型所获得的结果与随机模型(或无模型)所获得的结果之间的比率计算得出。也就是说,增益 % 与给定分位数的随机期望值 % 的比率。第 x 位分位数的随机期望值为 x%。
将鼠标悬停在提升图中的某个点上,即可查看此点的分位数百分比和累积提升值。
如果为实验提供了测试集,则点击图表下方的 验证指标 按钮即可查看测试数据的统计信息。
K-S 曲线:此图用于度量用于验证或测试数据的正例和负例之间的分隔程度。
将鼠标悬停在此图中的某个点上,即可查看此点的分位数百分比和 K-S 值。
如果为实验提供了测试集,则点击图表下方的 验证指标 按钮即可查看测试数据的统计信息。
增益图:此图展示验证数据的增益统计信息。例如,”正例目标类别的所有观测值占预测结果前 1%、2%、10% 等(累积)的比例为多少?”根据定义,100% 的增益即为 1.0。
将鼠标悬停在增益图中的某个点上,即可查看此点的分位数百分比和累积增益值。
如果为实验提供了测试集,则点击图表下方的 验证指标 按钮即可查看测试数据的统计信息。
多类别分类实验¶
对于多类别分类实验,除了 ROC 曲线、P-R 图、提升图、K-S 图和增益图外,还可使用混淆矩阵。Driverless AI 将多类别问题视为多个一对多的问题,从而生成这些图表。这些图表(混淆矩阵除外)均基于一种被称为微平均的方式进行绘制。(请参阅:http://scikit-learn.org/stable/auto_examples/model_selection/plot_roc.html#multiclass-settings)。
例如,您可能想预测鸢尾属植物数据集中的种类。预测结果可能会像如下所示:
class.Iris-setosa |
class.Iris-versicolor |
class.Iris-virginica |
0.9628 |
0.021 |
0.0158 |
0.0182 |
0.3172 |
0.6646 |
0.0191 |
0.9534 |
0.0276 |
若需创建这些图表,Drvierless AI 会将结果转化为 3 个一对多的问题:
prob-setosa |
actual-setosa |
prob-versicolor |
actual-versicolor |
prob-virginica |
actual-virginica |
||
0.9628 |
1 |
0.021 |
0 |
0.0158 |
0 |
||
0.0182 |
0 |
0.3172 |
1 |
0.6646 |
0 |
||
0.0191 |
0 |
0.9534 |
1 |
0.0276 |
0 |
结果是二元分类问题的预测值和实际值的 3 个向量。Driverless AI 会连接这 3 个向量以计算图表。
predicted = [0.9628, 0.0182, 0.0191, 0.021, 0.3172, 0.9534, 0.0158, 0.6646, 0.0276]
actual = [1, 0, 0, 0, 1, 1, 0, 0, 0]
多类别混淆矩阵¶
混淆矩阵从假正例、假负例、真正例和真负例方面展示了实验性能。对于每个阈值,混淆矩阵用于表示 TPR 和 FPR (ROC) 之间或精确率和召回率 (P-R) 之间的平衡关系。通常,最有用的工作点位于左上角。
在此图中,实际结果显示在列中,预测结果则显示在行中;正确的预测结果会被突出显示。在以下示例中, Iris-setosa 有 30 次正确预测, Iris-virginica 有 32 次正确预测,而 Iris-versicolor 有 2 次被预测为 Iris-virginica (针对验证集而言)。
如果为实验提供了测试集,则点击图表下方的 验证指标 按钮即可查看测试数据的统计信息。

回归实验¶
残差:残差 是观测到的响应与模型预测的响应之间的差值。任何残差模式均证明模型不充分或数据不合规(例如异常值),并表明可如何改进模型。此图展示验证数据或测试数据的残差(实际值 – 预测值)值与预测值。请注意,此图会保留所有异常值。对完美的模型,其残差应为零。
将鼠标悬停在此图的某个点上,以查看此点的预测值与残差值。
如果为实验提供了测试集,则点击图表下方的 验证指标 按钮即可查看测试数据的统计信息。

实际值与预测值对比图:此图展示验证数据的实际值与预测值。其中将显示值的一小部分样本。完美的模型会有一条对角线。
将鼠标悬停在此图中的某个点上,即可查看此点的实际值与预测值。
如果为实验提供了测试集,则点击图表下方的 验证指标 按钮即可查看测试数据的统计信息。
