Architecture
This section describes the main components of the Feature Store.
High-level architecture
This subsection provides a basic overview of how the Feature Store runs.
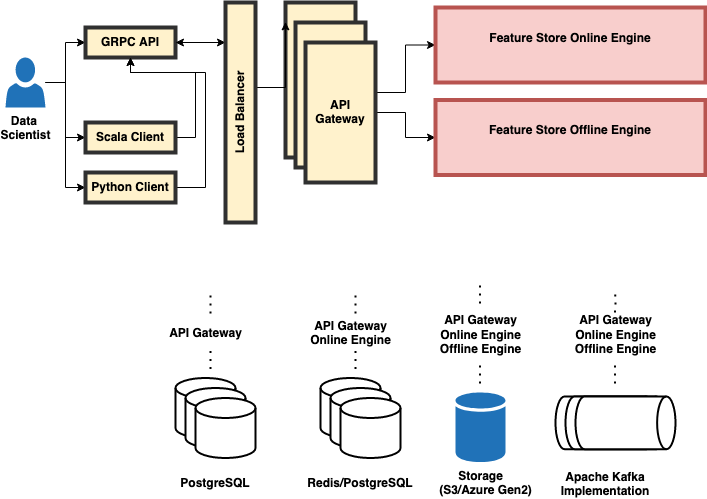
You can push data to Feature Store through one of the Clients. The load-balancer acts as an ingress router for the cloud and routes the traffic to the Feature Store service that exposes the API. This lets you connect to one of the engines.
There are two engines: offline and online. The offline engine is a core service that handles API requests. It stores the metadata (that is, feature sets) used to train the model in a PostgreSQL database. The online engine stores the users' data and metadata with better accessibility. It uses this information to inference the model. The online engine can store online records data in Redis or in PostgreSQL database. You can sync data between the offline and online engine depending on how you want to use it. The main difference between the two engines is the real data location.
Persistent storage can be located in either S3 or in Azure Gen2. Apache Kafka queues requests for the offline and online engines and passes them to the Feature Store.
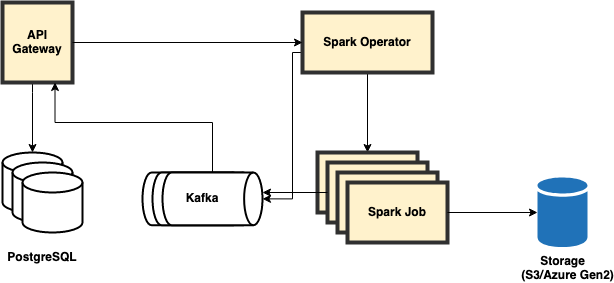
Feature Store offline engine
The core (pictured here as the offline engine) is a service that handles API requests.
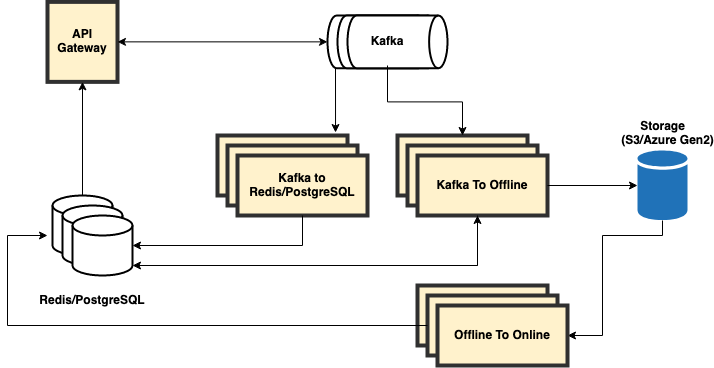
Feature Store online engine
The online engine is a scalable component that provides support for main three functionalities:
- storing data into the online storage - supported databases are Redis and PostgreSQL.
- saving data regularly from the online databases into the offline Feature Store storage (
online to offline). - updating Redis after each ingestion into the offline Feature Store storage with missing values (
offline to online).
Technical components
- Authorization - PostgreSQL for storing the authorization data
- Authentication - OpenIdConnect
- Database - PostgreSQL
- Execution framework - Apache Spark
- Deployment environment - Kubernetes
- API definition - ProtoBuf & GRPC
Running Feature Store in production
Feature Store itself requires four components to be up and running inside a Kubernetes cluster. These main services will be installed automatically when you use our Helm charts.
Preferred architecture used in production:
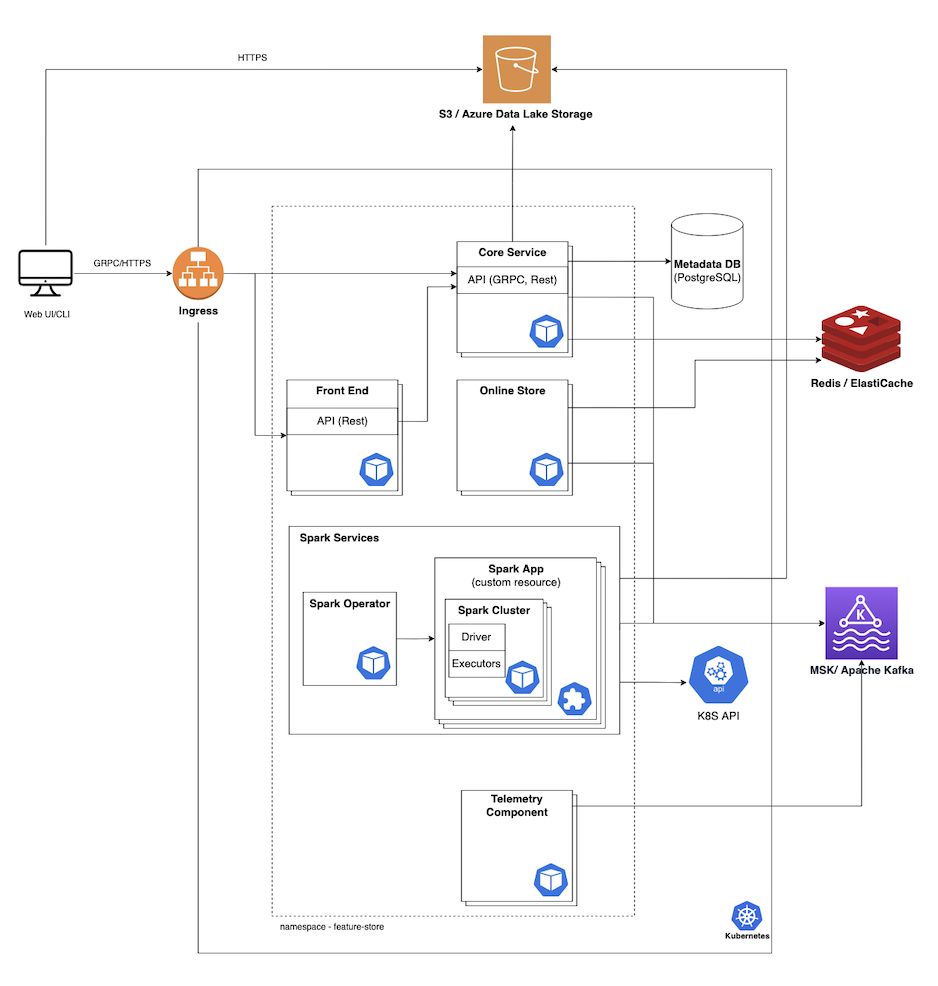
This graph does not present OAuth integration. To authenticate a user in the system, it has to be integrated with SSO (which supports OpenID protocol).
Feature Store services
Core API
The Feature Store Core is a Feature Store component that is always deployed within the container of the Kubernetes cluster. It uses GRPC to define the API, allowing it to be easily consumed by the clients. It performs several important functions:
- registers the features in the database.
- triggers the start of data manipulation tasks on the Spark cluster.
- performs authentication and queries for authorization permissions.
This service provides a customer-facing API. It can be exposed via Kubernetes Ingress or any other Load Balancer. The Ingress must be able to route traffic to a GRPC service. We recommend to start at least two pods of this component to ensure high availability. We also suggest to assign at least 2 CPUs and 2GB of RAM for each pod, but the values depend on the client needs.
Online store
This service is responsible for ingesting data into Redis and managing online-to-offline processes. We recommend starting at least two pods of this component to ensure high availability. We also suggest assigning at least 2 CPUs and 2GB of RAM for each pod, but the values depend on the client needs.
Spark operator
The Kubernetes operator which manages the Spark jobs. The Feature Store Core submits a Spark job specification to the Spark operator. The Spark operator fully manages the life cycle of the Spark job. It also pushes job status change events to a messaging queue.
Only one pod can be present in the cluster. We suggest assigning at least 2 CPUs and 2GB of RAM to the pod.
Spark job
The Spark cluster started dynamically by the operator to process your data. The Spark cluster is used for data manipulation tasks (such as registering new features or creating output data from selected features). The Feature Store Core takes care of starting and stopping separate Spark clusters for each new job. The communication between the Core and Spark is also implemented via GRPC.
We recommend using dedicated Kubernetes nodes with auto-scaling to host Spark clusters. The number of resources in the production environment depends on the feature set sizes, but we recommend assigning no less than 2 CPUs and 8GB of RAM. By default, the Spark Cluster will use 1 driver pod + 3 executors.
Third-party software
Feature Store also requires third-party software to be present and accessible. This third-party software is seen lining the outside of the preceding production image.
PostgreSQL
Feature Store uses PostgreSQL as the database. The database stores information about features, feature sets, projects, and users (also known as the metadata).
Postgres can also be used as a backend for online Feature Store (Redis is the default).
Redis
By default, the Feature Store online engine uses Redis as a backend to store online data. It is recommended to use the Redis cluster setup, but any other configuration should work. Memory allocated to the cluster depends on the client needs and features stored in it.
Main storage
The system supports 2 types of storage:
- S3 (and S3 compatible, e.g., Minio)
- Azure Data Lake Storage Gen2
Event platform
We recommend you use Kafka.
- Submit and view feedback for this page
- Send feedback about H2O Feature Store to cloud-feedback@h2o.ai