Task 2: Explore dataset
Let's explore the dataset to understand each column.
- In the DATASETS page, observe the two datasets we will use for this tutorial.
- Click the
loan_prediction_train.csvdataset and select the DETAILS option. - Let’s take a quick overview of the columns of the training dataset:
- The dataset consists of 13 columns which are as follows:
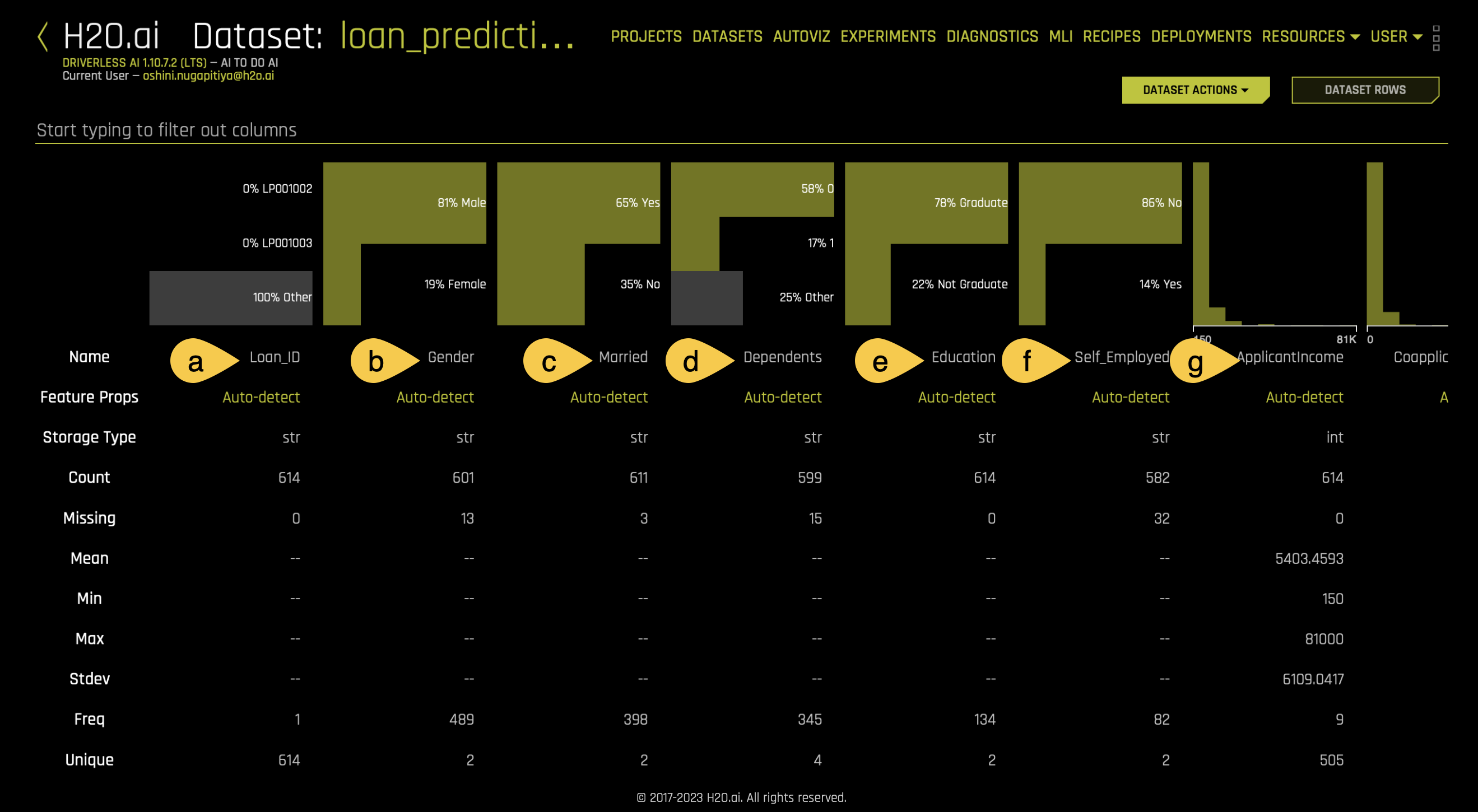 a. Loan_ID - A unique identifier for each loan application
a. Loan_ID - A unique identifier for each loan application
b. Gender - The gender of the applicant (Male/Female)
c. Married - The marital status of the applicant (Yes/No)
d. Dependents - The number of dependents the applicant has
e. Education - The education level of the applicant (Graduate/Not Graduate)
f. Self_Employed - Whether the applicant is self-employed (Yes/No)
g. ApplicantIncome - The income of the loan applicant in numerical form - Continue scrolling to the right of the page to view the rest of the columns of the dataset:
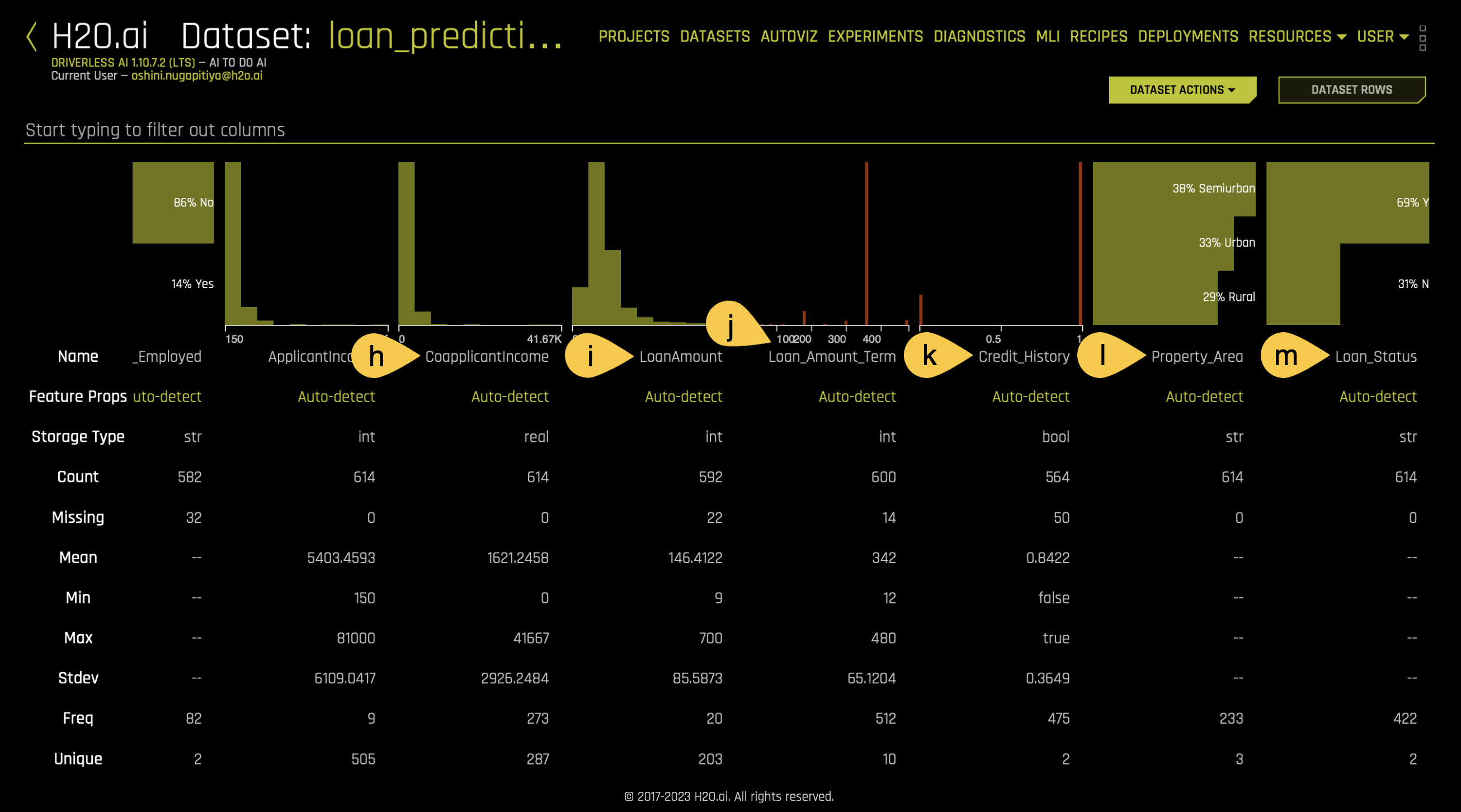 h. CoapplicantIncome - The income of the co-applicant, if any
h. CoapplicantIncome - The income of the co-applicant, if any
i. LoanAmount - The loan amount requested
j. Loan_Amount_Term - The term of the loan in months
k. Credit_History - A numerical representation of the applicant's credit history (1 for good credit, 0 for bad credit)
l. Property_Area - The type of property area (Urban, Semi-Urban, or Rural)
m. Loan_Status - Whether the loan was approved (Y) or not (N)
- Return to the Datasets page.
Now that you understand each column of the dataset, in Task 3, we will learn how to set up the experiment from scratch.
Feedback
- Submit and view feedback for this page
- Send feedback about H2O Driverless AI | Tutorials to cloud-feedback@h2o.ai