Task 3: Build and launch the experiment
Now that we better understand the dataset let's develop a classification model capable of predicting the probability of a credit card client defaulting on their upcoming credit card payment.
In the H2O Driverless AI navigation menu, click DATASETS.
In the Datasets table, click UCI_Credit_card.csv.
Select PREDICT.
As soon as you select the Predict option, you are asked if you want to take a tour of the Driverless AI environment. Skip it for now by clicking Not Now.
Enter the following information into H2O Driverless AI:
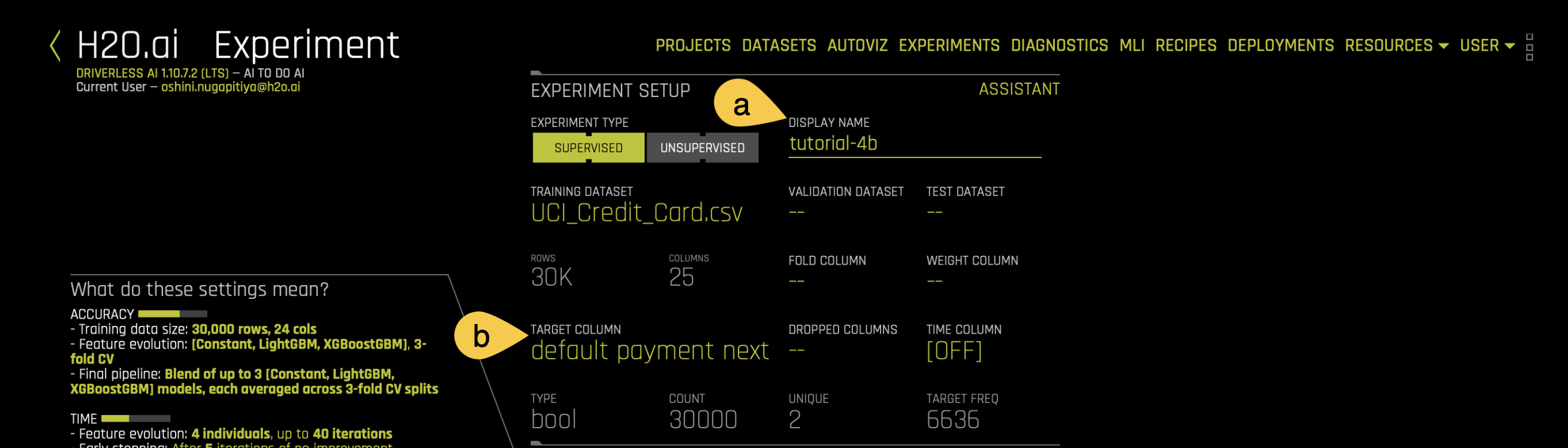
a. Display Name - Name the current experiment:
tutorial-4b.b. Target Column - Select default payment next month as the target variable for the classification task.
Adjust the following training settings accurately to run an effective classification model.
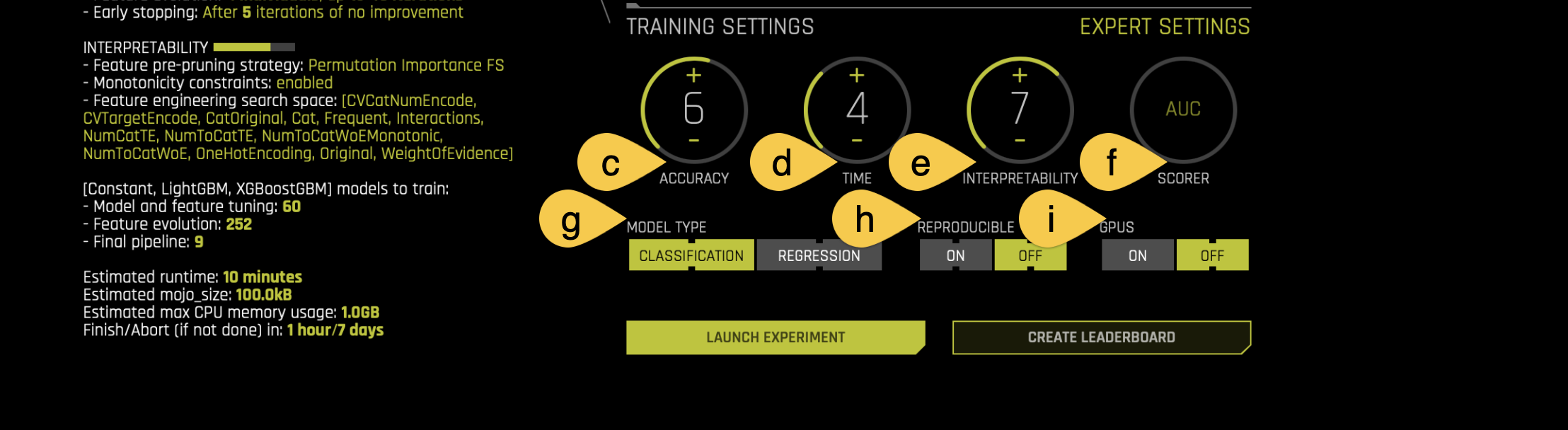
c. Accuracy - accuracy stands for relative accuracy, i.e., higher values should lead to higher confidence in model performance (accuracy). The accuracy setting impacts which algorithms are considered, level of assembling, and types of feature engineering.
- Therefore, set the Accuracy value to 6
d. Time - time is the relative time for completing the experiment. Higher values will lead to experiments taking longer.
- Keep the default Time value
e. Interpretability - interpretability is the degree to which a human can understand the cause of the decision.
- For this tutorial, let's try to generate a model that can be easily understood.
- Setting the interpretability to a minimum of >= 7 in an H2O Driverless AI experiment prompts the system to prioritize models that offer higher interpretability, even if they exhibit slightly lower accuracy.
- This preference stems from the fact that models with enhanced interpretability are easier to comprehend and explain, a crucial requirement in industries mandating model transparency.
- Increasing interpretability leads to the generation of simpler features by H2O Driverless AI.
- When interpretability reaches a certain threshold, the system produces a monotonically constrained model, enhancing transparency and interpretability further.
- This streamlined approach not only simplifies the understanding of metrics but also streamlines the elimination of potentially complex features that could pose challenges from an interpretability standpoint.
- It's essential to acknowledge the potential trade-off between interpretability and accuracy, underscoring the importance of carefully aligning the chosen interpretability level with the specific requirements of the use case.
- Therefore, set the Interpretability value to 7
f. Scorer - H2O Driverless AI automatically chooses the optimal scorer, considering the problem type and other factors. In binary classification tasks, the default scorer is AUC (Area Under the ROC Curve). Nevertheless, you can manually select an alternative scorer if necessary.
g. Model type: Driverless AI automatically determines the model type based on the response column. Though not recommended, you can override this setting by clicking this button. Our current problem is that of Classification.
- Make sure this setting is set to Classification
h. Reproducible: This button allows you to build an experiment with a random seed and get reproducible results. If this is disabled (default), the results will vary between runs.
- Don't enable this setting
i. GPUs: Specify whether to enable GPUs. (Note that this option is ignored on CPU-only systems).
- Make sure this setting is enable
Click LAUNCH EXPERIMENT.
Congratulations, you have successfully configured the training settings and launched your experiment. In Task 4, you will explore the experiment results.
- Submit and view feedback for this page
- Send feedback about H2O Driverless AI | Tutorials to cloud-feedback@h2o.ai