Task 3: Set up experiment
Now that we have a better understanding of the dataset, let's build the experiment from scratch.
In the DATASETS page, click on the
consumer_complaint_resolution_train.csvdataset, and select the PREDICT option.As soon as you select the Predict option, you are asked if you want to take a tour of the Driverless AI environment. Skip it for now by clicking Not Now.
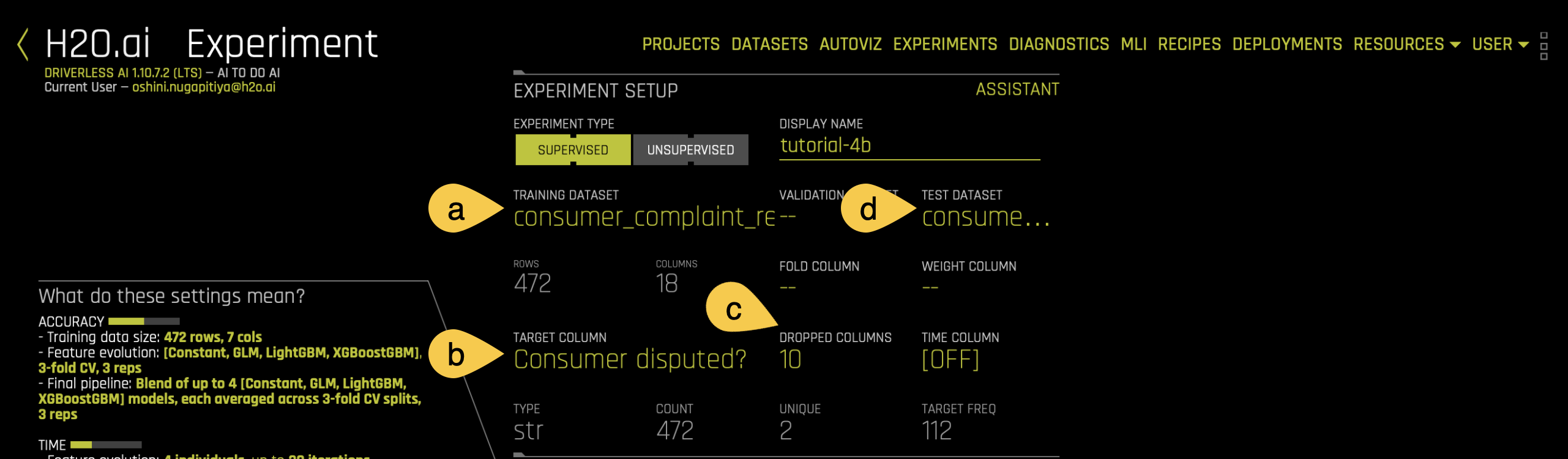
Feed the following information into Driverless AI:
 note
notea. Display Name - Name the current experiment:
tutorial-4c.b. Target Column - Select Consumer disputed? as the target column. The aim of the experiment is to predict whether a customer will dispute the resolution of their complaint. The column has only two values, yes and no.
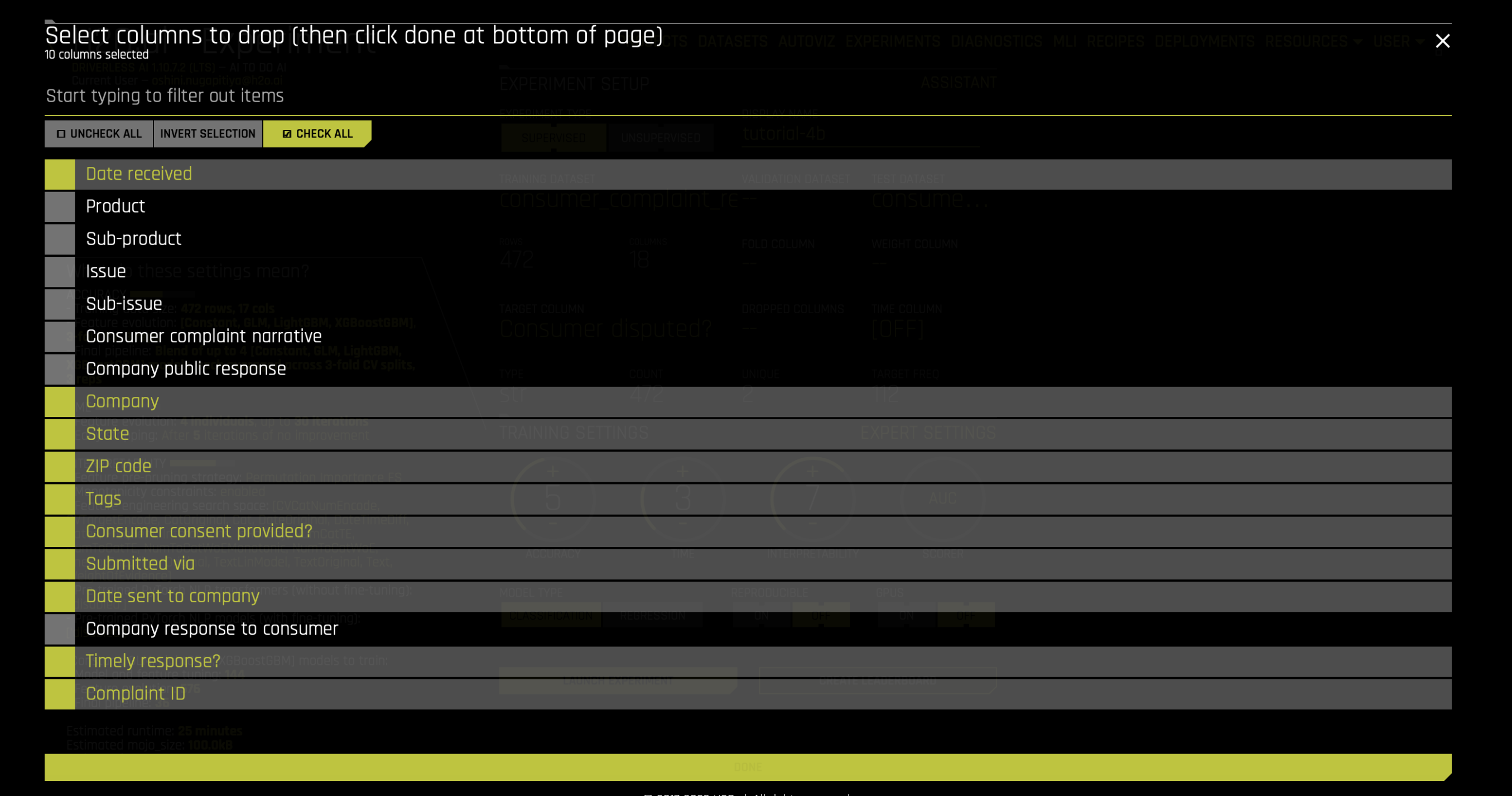
c. Dropped Columns - For this experiment, the primary focus is on text columns. Therefore, drop all columns that are not relevant for text analysis, such as IDs, date or other non-informative columns. Please note that if you decide to keep the non-text columns, the NLP algorithms will still work on the non-text columns.
d. Test Dataset - The Test dataset is a dataset used to provide an unbiased evaluation of a
finalmodel fit on the training dataset. It is not used during training of the model. Select theconsumer_complaint_resolution_test.csvdataset for the test dataset option.
In Task 4: Configure training settings, let's continue editing the experiment settings.
- Submit and view feedback for this page
- Send feedback about H2O Driverless AI | Tutorials to cloud-feedback@h2o.ai