Create a new project for data curation
Overview
H2O LLM DataStudio supports the conversion of documents to question-answer pairs, article summarization, and file summarization. To do this, start by creating a new project.
Before starting a new project, you must integrate h2ogpte by providing the required credentials. You cannot create a new project without configuring h2ogpte. For more information, see Settings.
Instructions
To create a new project for data curation, consider the following instructions:
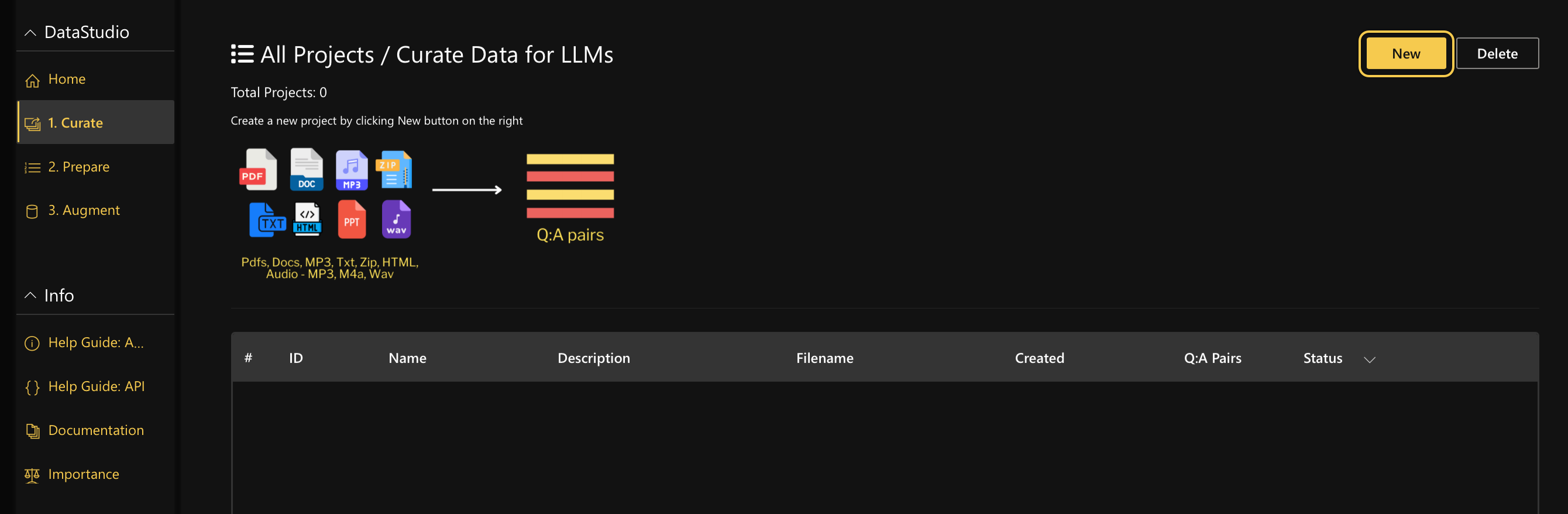
- On the H2O LLM DataStudio left navigation menu, click Curate.
- On the All Projects / Curate Data for LLMs page, click New.
- On the Project name text box, enter a name for the project (for example,
My new curate project). - On the Description text box, enter a description for the project.
- On the Document description text box, provide a brief description for your file's content. This label helps to quickly categorize and identify the document's purpose. Some examples of document types are,
Quarterly Financial Report,Purchase Order,User Guide,Product Brief,Research Paper, andMeeting Recording. - From the task type drop-down menu, select the appropriate task type for the experiment.
- Question-answer task: Used to generate question-answer pairs from documents for LLM fine-tuning
- Summarization task: Used to generate chunk summaries for LLM fine-tuning
- File Summary task: Used to generate complete file summary (Note: This task type cannot be used for fine-tuning due to context limitations)
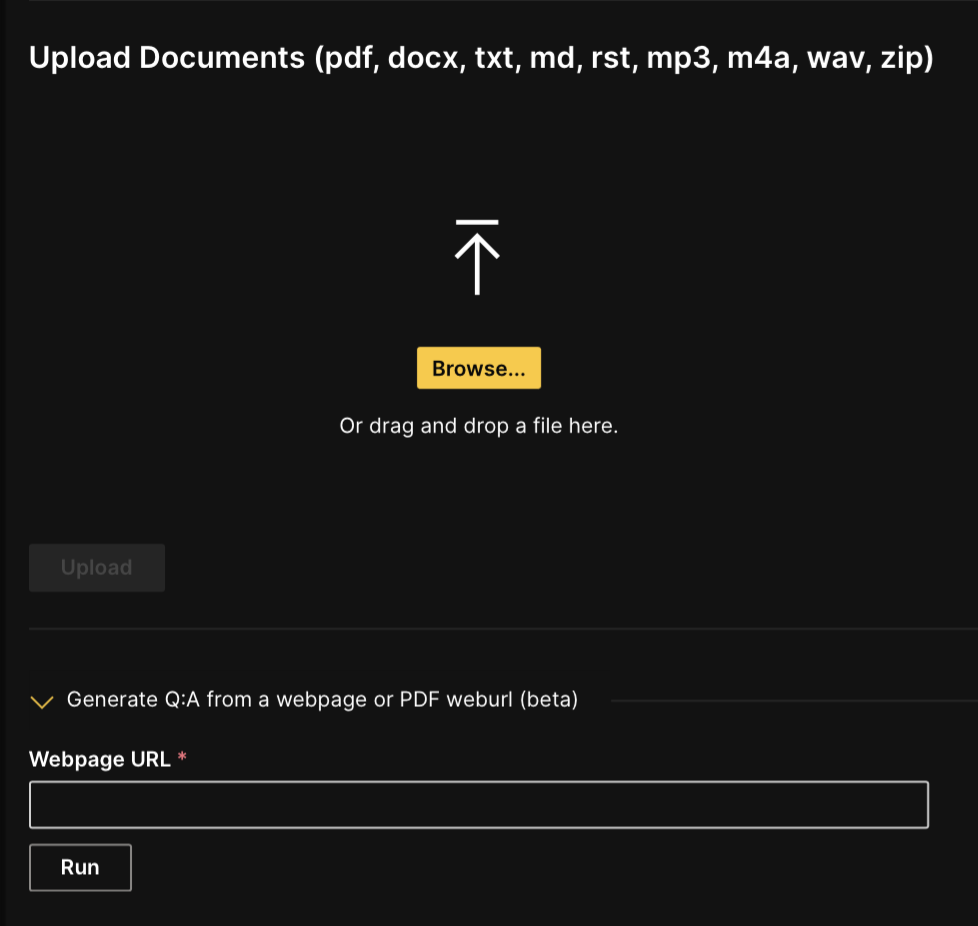
- Click Browse and choose the file you want to upload or add the webpage URL and click Run.
note
- H2O LLM DataStudio supports
PDF,DOCX,TXT,MD,RSTand audio files (MP3,M4A,WAV). - If you have multiple documents you can upload them in a
ZIPfile.
- H2O LLM DataStudio supports
- Click Upload to upload the document.
- Once you upload the documents, select your preferred H2OGPTE LLM from the available LLMs on the LLM selection section.
- In the Relevance score selection dropdown menu, choose between the Bert approach (context-aware deep learning model), Regex approach (pattern-based matching), or FinBert approach (financial text relevance) to set your preferred method for calculating relevance scores.
- Use the slider labeled Number of tokens per chunk to adjust the tokenization settings. This controls the maximum number of tokens per chunk of text processed by the model. The default is set to 1000 tokens.
More customization options are available only for the English language. For optimal results, we recommend using the Bring your own prompt in the Expert option. Please be aware that if you select options from multiple levels (basic, advanced, or expert options), the system will automatically apply the most advanced setting by default.
Basic options
- In the Select personas type section, use the dropdown menu labeled Personas types to choose a predefined persona type for the model to emulate during the processing. For detailed descriptions on the different options, click the info icon next to the setting. If you want to create a custom persona, click the Design own persona button, which will guide you through the process of defining your own persona settings.
Advanced options
- Select knowledge prompts: Select the knowledge prompts you want the system to focus on in the provided text box. For detailed descriptions of the different knowledge prompts, click the info icon next to the setting.
- Select question type: From the dropdown menu, choose the type of questions you wish to generate. The options include factual, open-ended, inferential, analytical, predictive, and comparative. For detailed descriptions of each question type, click the info icon next to the setting.
- Select difficulty level of questions: Use the dropdown to specify the desired difficulty level (easy, medium, or hard) for the questions generated.
- Select desired answer length: Choose the preferred length of answers (short, medium, or long) from the dropdown options.
Expert options
- Bring your own Prompt: Input a custom prompt to generate specific question-answer pairs. For example, you can provide detailed instructions on the type of questions and answers you need, targeting a specific audience or focusing on particular aspects of a document.
-
Enable the Perform Smart Chunking (Fast) option to optimize the processing of large documents, typically hundreds or thousands of pages. This feature speeds up the chunking process but may limit the generation of sufficient records for fine-tuning.
-
Adjust the Sampling ratio for smart chunking. By default, the sampling ratio is set to 0, and when the ratio is 0, LLM DataStudio will automatically select the sampling ratio based on the length of the document. It is recommended to set the sampling ratio to a value greater than or equal to 0.5.
-
Toggle the Use h2oGPTe's ingestion pipeline option to choose between using the h2oGPTe's ingestion pipeline or the default LLM DataStudio pipeline. If this is turned on, it will initiate the following process:
- A new collection is created in h2oGPTe.
- The document is uploaded directly to this collection.
- h2oGPTe generates and returns content chunks from the uploaded document.
If this is turned off, the ingestion pipeline of LLM DataStudio is used automatically.
-
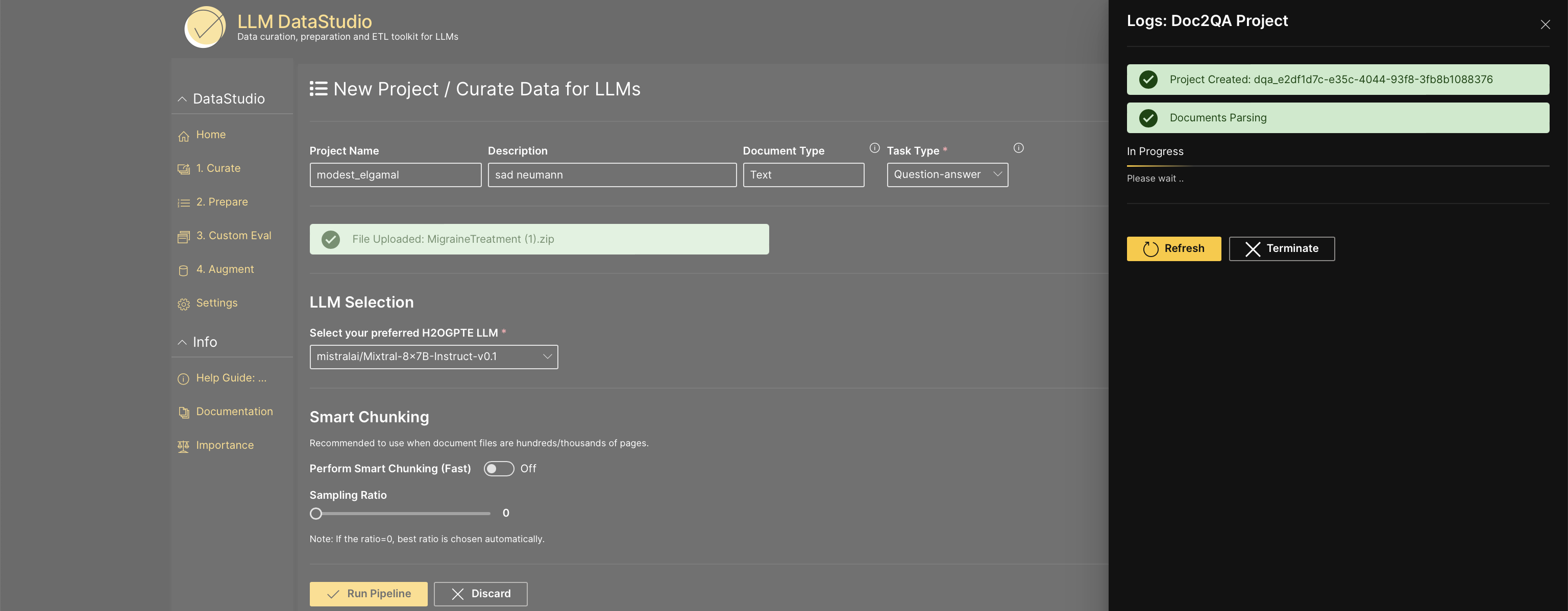
Click Run pipeline to trigger the pipeline.
You can check the logs of the curation process from Logs: Doc2QA Project.
 Click Refresh to review the progress and the percentage of completion.
Click Refresh to review the progress and the percentage of completion.
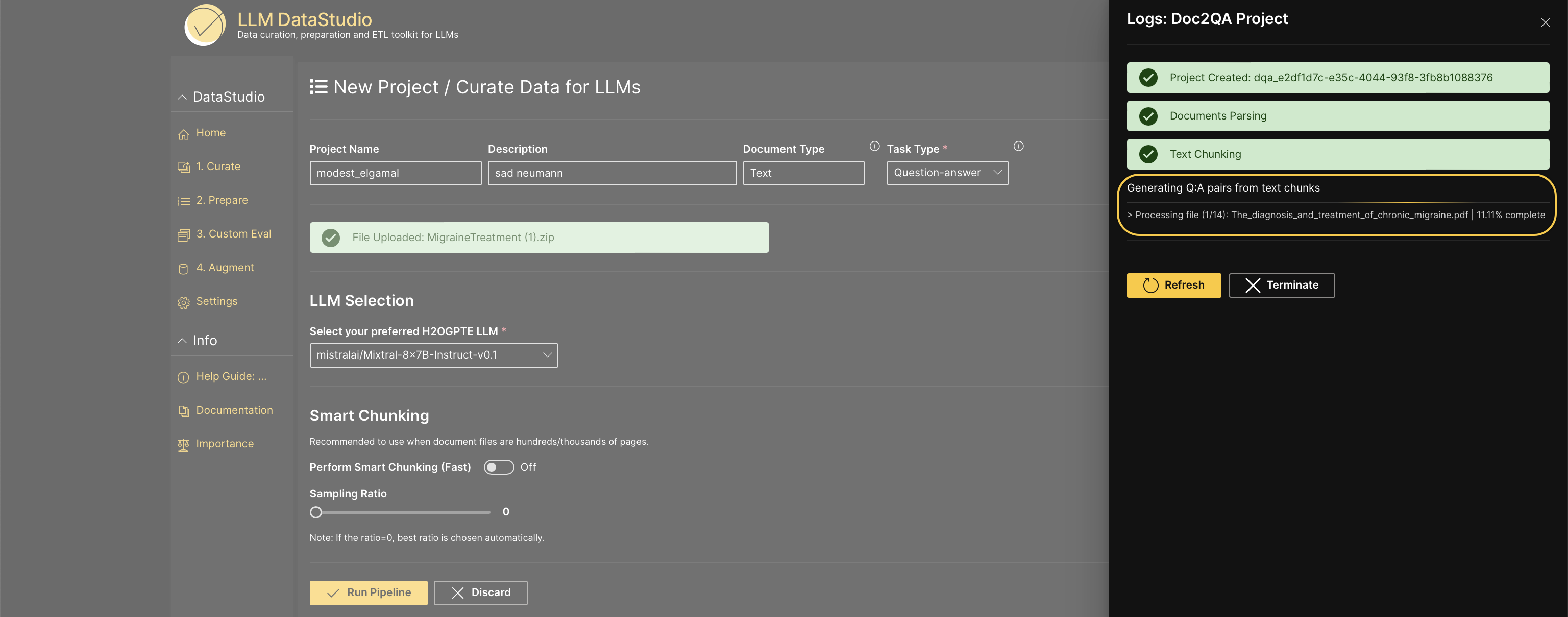 Click Terminate to stop the data curation process midway. It terminates the running process, and the question-answer pairs generated so far will be available to view and download.
Click Terminate to stop the data curation process midway. It terminates the running process, and the question-answer pairs generated so far will be available to view and download.
- Submit and view feedback for this page
- Send feedback about H2O LLM DataStudio | Docs to cloud-feedback@h2o.ai