Deploying a model with Kubernetes resource and replica requests
This example demonstrates how you can upload a model to MLOps and deploy it within a Kubernetes cluster by defining the resources allocated to that model and the number of replicas you need to deploy.
-
Resources: Resource requests can be used to specify the amount of memory or CPU a model is expected to use and define the limit where memory or CPU usage is considered beyond the expected amount. This is useful for the underlying Kubernetes scheduler when deciding whether a model should be evicted due to overconsumption of resources.
-
Replicas: The number of concurrent pods that will be associated with the model. This specifies the number of concurrent instances of the same model you need to deploy. Concurrent models can decrease scoring times by balancing simultaneous scoring requests across multiple model replicas.
For more information about Kubernetes resources and replicas, see Resource Management for Pods and Containers and Deployments in Kubernetes.
- You will need a model zip file to upload and deploy in MLOps. This can be any type of model supported by MLOps. For this example, you can use this MLFLow_sklearn-sentiment.zip model.
- You will need the values for the following constants in order to successfully carry out the task. Contact your administrator to obtain deployment specific values.
| Constant | Value | Description |
|---|---|---|
MLOPS_API_URL | Usually: https://api.mlops.my.domain | Defines the URL for the MLOps Gateway component. You can verify the correct URL by navigating to the API URL in your browser. It should provide a page with a list of available routes. |
TOKEN_ENDPOINT_URL | https://mlops.keycloak.domain/auth/realms/[fill-in-realm-name]/protocol/openid-connect/token | Defines the token endpoint URL of the Identity Provider. This uses Keycloak as the Identity Provider. Keycloak Realm should be provided. |
REFRESH_TOKEN | <your-refresh-token> | Defines the user's refresh token |
CLIENT_ID | <your-client-id> | Sets the client id for authentication. This is the client you will be using to connect to MLOps. |
MODEL_FILE_PATH | <path-to-your-model-zip-file> | Defines a model zip file that will be uploaded and deployed. This can be any type of model supported by MLOps. |
MODEL_DISPLAY_NAME | DeployWithKubernetesResourcesAndReplicas | Defines the model's display name. |
PROJECT_NAME | UploadAndDeployWithResources | Defines a project that the script will create for the model. |
DEPLOYMENT_ENVIRONMENT | DEV | Defines the target deployment environment. |
REFRESH_STATUS_INTERVAL | 1.0 | Defines a refresh interval for the deployment health check. |
MAX_WAIT_TIME | 300 | Defines maximum waiting time for the deployment to become healthy. |
The following steps demonstrate how you can use the MLOps Python client to upload a model to MLOps and deploy it within a Kubernetes cluster by defining resources and replicas associated with it.
-
Change the values of the following constants in your
KubernetesResourcesReplicas.pyfile as given in the preceding data table.- Format
- Sample
KubernetesResourcesReplicas.py### Constants
MLOPS_API_URL = <MLOPS_API_URL>
TOKEN_ENDPOINT_URL = <TOKEN_ENDPOINT_URL>
REFRESH_TOKEN = <REFRESH_TOKEN>
CLIENT_ID = <CLIENT_ID>
MODEL_FILE_PATH = <MODEL_FILE_PATH>
MODEL_DISPLAY_NAME = <MODEL_DISPLAY_NAME>
PROJECT_NAME = <PROJECT_NAME>
DEPLOYMENT_ENVIRONMENT = <DEPLOYMENT_ENVIRONMENT>
REFRESH_STATUS_INTERVAL = <REFRESH_STATUS_INTERVAL>
MAX_WAIT_TIME = <MAX_WAIT_TIME>KubernetesResourcesReplicas.py### Constants
MLOPS_API_URL = "https://api.mlops.my.domain"
TOKEN_ENDPOINT_URL="https://mlops.keycloak.domain/auth/realms/[fill-in-realm-name]/protocol/openid-connect/token"
REFRESH_TOKEN="<your-refresh-token>"
CLIENT_ID="<your-mlops-client>"
MODEL_FILE_PATH = "<local-path-to-your-model-zip-file>"
MODEL_DISPLAY_NAME = "DeployWithKubernetesResourcesAndReplicas"
PROJECT_NAME = "UploadAndDeployWithResources"
DEPLOYMENT_ENVIRONMENT = "DEV"
REFRESH_STATUS_INTERVAL = 1.0
MAX_WAIT_TIME = 300 -
Run the
KubernetesResourcesReplicas.pyfile.- Execution
- Sample response
python3 KubernetesResourcesReplicas.pyDeployment has become healthy -
Finally, navigate to MLOps and click the project name
UploadAndDeployWithResourcesunder Projects to view the deployed model.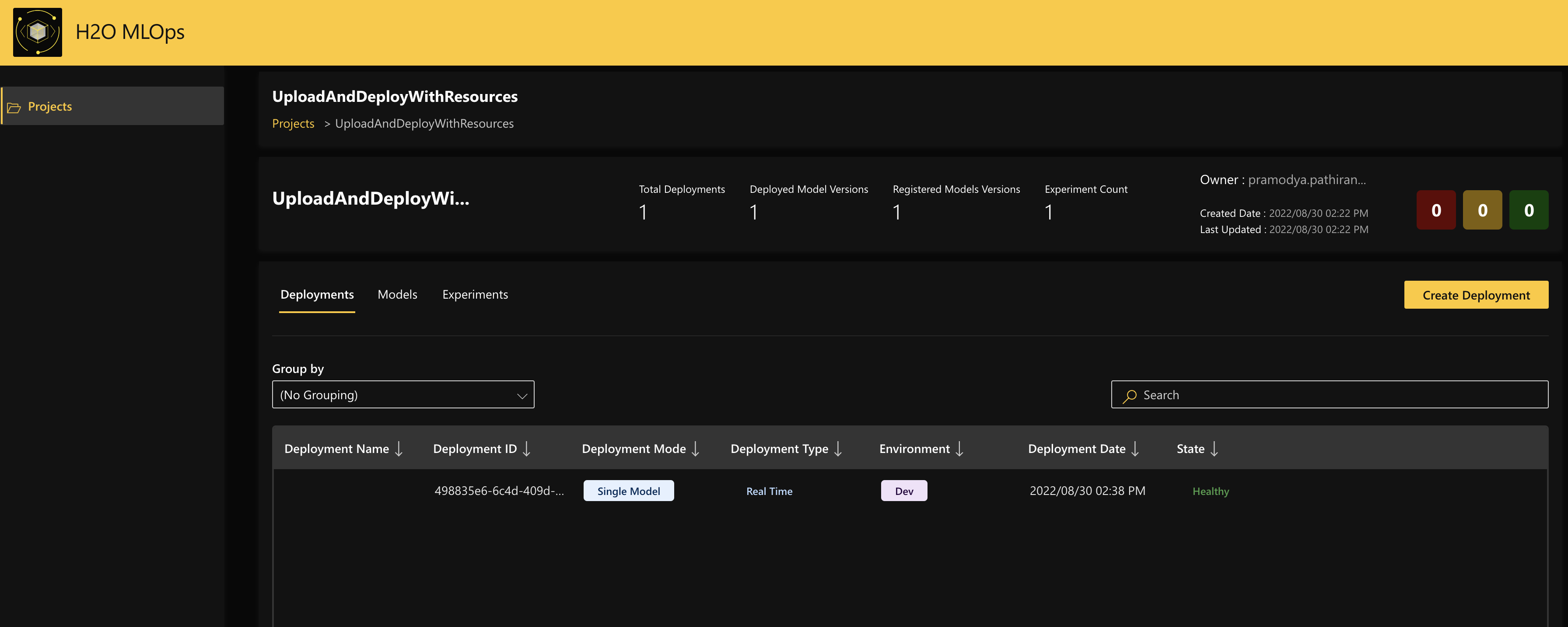 Note
NoteFor more information about model deployments in MLOps, see Understand deployments in MLOps.
Scaling deployment Kubernetes resources post-deployment
The following steps describe how to use the H2O MLOps Python client to update the Kubernetes resources and replicas of a deployment after creating it (that is, to scale the resources up for performance or scale it down for cost). To achieve this, you can use the update_model_deployment function.
-
Determine the new deployment resource allocation (
DeployKubernetesResourceSpec). In this example, the number of replicas is set to 5. Note that if you want to set the number of replicas to zero (that is, have no Kubernetes resources allocated to the deployment), setreplicas=-1.new_resource_spec = mlops.DeployKubernetesResourceSpec(
replicas=5, # -1 means none, 0 means default
) -
Update the deployment using the new resource spec you defined in the preceding step. In this example, the deployment that the update is applied to is
to_deploy.to_deploy.single_deployment.kubernetes_resource_spec = new_resource_spec
mlops.deployer.deployment.update_model_deployment(
h2o_mlops_client.DeployUpdateModelDeploymentRequest(
deployment=to_deploy
)
) -
Check the new deployment resource spec:
to_deploy.single_deployment.kubernetes_resource_spec
Example walkthrough
This section provides a walkthrough of each of the sections in the KubernetesResourcesReplicas.py file.
-
Include the Helper function, which waits for the deployment to be healthy.
-
Convert the extracted metadata into storage compatible value objects.
-
Create a project in MLOps and create an artifact in MLOps storage.
-
Upload the zip file and analyze it.
KubernetesResourcesReplicas.py# Uploading the zip file.
with open(MODEL_FILE_PATH, "rb") as mojo_file:
mlops_client.storage.artifact.upload_artifact(
file=mojo_file, artifact_id=artifact.id
)
# Analyzing the zip file.
ingestion: mlops.IngestMetadata = mlops_client.ingest.model.create_model_ingestion(
mlops.IngestModelIngestion(artifact_id=artifact.id)
).ingestion
model_metadata = convert_metadata(ingestion.model_metadata)
model_params = mlops.StorageExperimentParameters(
target_column=ingestion.model_parameters.target_column
) -
Create an experiment from the zip file and link the artifact to the experiment.
KubernetesResourcesReplicas.py# Creating an experiment from the zip file.
experiment: mlops.StorageExperiment = (
mlops_client.storage.experiment.create_experiment(
mlops.StorageCreateExperimentRequest(
project_id=prj.id,
experiment=mlops.StorageExperiment(
display_name=MODEL_DISPLAY_NAME,
metadata=model_metadata,
parameters=model_params,
),
)
).experiment
)
# Linking the artifact to the experiment.
artifact.entity_id = experiment.id
artifact.type = ingestion.artifact_type
mlops_client.storage.artifact.update_artifact(
mlops.StorageUpdateArtifactRequest(
artifact=artifact, update_mask="type,entityId"
)
) -
Customize the composition of the deployment.
KubernetesResourcesReplicas.pycomposition = mlops.DeployDeploymentComposition(
experiment_id=experiment.id,
artifact_id=artifact.id,
deployable_artifact_type_name="python/mlflow.zip",
artifact_processor_name="unzip_processor",
runtime_name="python-scorer_mlflow_38",
)NoteEnsure the parameters here are correct, depending on the type of model you want to deploy.
deployable_artifact_type_name- This can bedai/scoring_pipeline,dai/mojo_pipeline,python/mlflow.zip, etc.artifact_processor_name- This depends on thedeployable_artifact_type_name.unzip_processoris the standard for this, but for example,dai/scoring_pipelinehas a unique processor.runtime_name- Runtimes are dependent on the type of artifact being deployed. Dependencies vary for different models.
For more information, see Artifact type and runtime section in Deploy a model.
-
Define the Kubernetes resource requirements and the number of replicas you need to deploy.
KubernetesResourcesReplicas.pyto_deploy = mlops.DeployDeployment(
project_id=prj.id,
deployment_environment_id=deployment_env_id,
single_deployment=mlops.DeploySingleDeployment(
deployment_composition=composition,
kubernetes_resource_spec=mlops.DeployKubernetesResourceSpec(
kubernetes_resource_requirement=mlops.DeployKubernetesResourceRequirement(
requests={"cpu": "200m", "memory": "256Mi", "nvidia.com/gpu": "1"},
limits={"cpu": "300m", "memory": "512Mi", "nvidia.com/gpu": "1"}
),
replicas=2,
)
),
)Notekubernetes_resource_specand its nested objects define the resource requests and their limits, and replicas.This deployment is requesting a deployment with 2 pods, each with a minimum resource allocation of 200m CPU, 256Mi, and 1 NVIDIA GPU Memory. If pod resource consumption exceeds 300m CPU or 512Mi Memory or 1 NVIDIA GPU, the pod will risk being restarted.
For more information, see Resource Management for Pods and Containers
nvidia.com/gpuis a good example of an arbitrary resource request. MLOps only expectscpuandmemoryto be defined, but will accept any other string if provided. If the Kubernetes scheduler is unaware of the resource requested, the model deployment will fail. -
Finally, create the deployment and wait for the deployment to become healthy. This analyzes and sets the metadata and parameters of the model, and then deploys it to the
DEVenvironment.
- Submit and view feedback for this page
- Send feedback about H2O MLOps to cloud-feedback@h2o.ai