Import an annotated dataset
Overview
After creating an annotation task, you can import to the annotation task already annotated samples (for example, annotated images) from the same dataset you used to create the annotation task.
Instructions
To import an annotated dataset to an annotation task, consider the following instructions:
- On the H2O Label Genie navigation menu, click Annotation tasks.
- In the annotation tasks table, double-click the row where the annotation task you want to use is located.
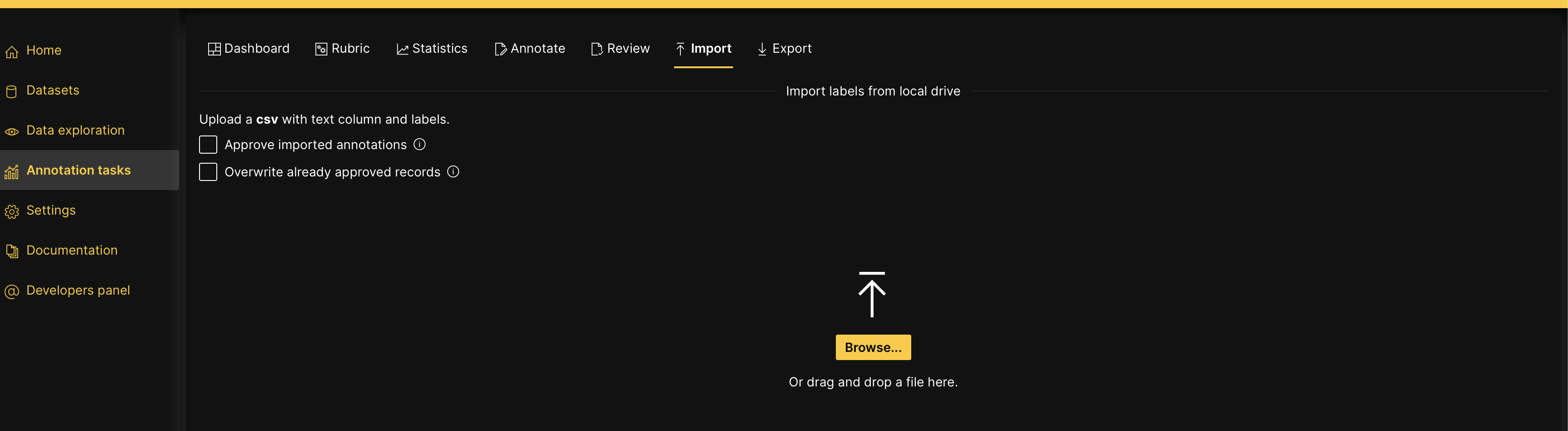
- Click Import tab.
- Upload your dataset with existing annotations.
- Click Import annotated samples.
- H2O Label Genie allows you to review and approve the imported annotations later. - To import them pre-approved: Click the Approve imported labels checkbox (so that you don’t have to approve them in the Annotate tab). - H2O Label Genie does not overwrite already approved records by default. - To enable overwrites: Click the Overwrite already approved records checkbox. - Before importing an annotated dataset to an existing annotation task, the annotated dataset needs to be formatted in a certain way depending on the problem type it aims to solve. To learn more, see Required annotated dataset format.
Required annotated dataset format
Before importing an annotated dataset to an existing annotation task, the annotated dataset needs to be formatted in a certain way depending on the problem type it aims to solve.
Text classification
The annotated dataset to import to a text classification annotation task needs to be formatted as follows:
A CSV file containing a text and label column. Columns:
- text: The text column needs to contain the original text input.
Note
The text column is used to merge the labels. Please make sure to use the original text column without any duplications. The original text column refers to the text column present in the dataset you used to create the annotation task.
- label: The label column needs to contain the labels attribute to the texts specified in the text column.
Text regression
The annotated dataset to import to a text regression annotation task needs to be formatted as follows:
A CSV file containing a text and label column. Columns:
- text: The text column needs to contain the original text input.
Note
The text column is used to merge the labels. Please make sure to use the original text column without any duplications. The original text column refers to the text column present in the dataset you used to create the annotation task.
- label: The label column needs to contain the labels attributed to the texts specified in the text column.
Text-entity recognition
The annotated dataset to import to a text-entity recognition annotation task needs to be formatted as follows:
A Parquet file containing a raw_text, text, and label column. Columns:
- raw_text: The text column needs to contain the original text input.
Note
The raw_text column is used to merge the labels. Please make sure to use the original text column without any duplications. The original text column refers to the text column present in the dataset you used to create the annotation task.
- text: The text column needs to contain the lists of entities.
- label: The label column needs to contain the lists of labels for the entities.
Text summarization
The annotated dataset to import to a text summarization annotation task needs to be formatted as follows:
A CSV file containing a text and label column. Columns:
- text: The text column needs to contain the original text input.
Note
The text column is used to merge the labels. Please make sure to use the original text column without any duplications. The original text column refers to the text column present in the dataset you used to create the annotation task.
- label: The label column needs to contain the summaries attributed to the texts specified in the text column.
Text-generative AI
The annotated dataset to import to a text-generative AI annotation task needs to be formatted as follows:
A CSV file containing the following columns:
- text: The text column needs to contain the original text input.
Note
The text column is used to merge the labels. Please make sure to use the original text column without any duplications. The original text column refers to the text column present in the dataset you used to create the annotation task.
- label: The label column needs to contain the answers attributed to the texts specified in the text column.
Image classification
The annotated dataset to import to an image classification annotation task needs to be formatted as follows:
A CSV file containing an image_path and label column. Columns:
- image_path: The image_path column needs to specify the locations of the images.
Note
The image_path column is used to merge the labels. Please make sure to use the correct relative paths without any duplications.
- label: The label column needs to contain the labels attributed to the images specified in the image_path column.
Image regression
The annotated dataset to import to an image regression annotation task needs to be formatted as follows:
A CSV file containing an image_path and label column. Columns:
- image_path: The image_path column needs to specify the locations of the images.
Note
The image_path column is used to merge the labels. Please make sure to use the correct relative paths without any duplications.
- label: The label column needs to contain the labels attributed to the images specified in the image_path column.
Object detection
The annotated dataset to import to an object detection annotation task needs to be formatted as follows:
A Parquet file containing an image_path and class_id column; the file should also contain an x_min, x_max, y_min, and* y_max* column corresponding to the bounding box locations. Columns:
- image_path: The image_path column needs to specify the locations of the images.
Note
The image_path column is used to merge the labels. Please make sure to use the correct relative paths without any duplications.
- class_id: The class_id column needs to contain the class IDs of the bounding box(es).
- x_min,x_max,y_min, and y_max: The x_min, x_max, y_min, and y_max specify the spatial location of the bounding box(es).
Image instance segmentation
- Format
- Example
The annotated dataset to import to an image instance segmentation annotation task needs to be formatted as follows:
A JSON file in a COCO format containing the following keys:
- images: The image ID and file_name (location).
Note
The file_name is used to merge the labels. Please make sure to use the correct relative paths without any duplications.
- annotations: The annotations in a COCO polygon format.
- categories: The categories ID and name.
{
"images":[
{
"id":0,
"file_name":"car_or_coffee_sample/pexels-anna-tukhfatullina-food-photographerstylist-2648988.jpg",
"width":3423,
"height":4279
}
],
"annotations":[
{
"id":"1f138007-30e6-4fdc-b855-bad58ea5cce0",
"image_id":0,
"category_id":1,
"iscrowd":0,
"segmentation":[
[
1377.548780487805,
2156.21484375,
1385.8975609756098,
2198.001953125,
1444.3390243902438,
2256.50390625,
1594.6170731707318,
2306.6484375,
1711.5,
2323.36328125,
1895.1731707317074,
2315.005859375,
2045.451219512195,
2289.93359375,
2145.6365853658535,
2256.50390625,
2212.4268292682927,
2198.001953125,
2212.4268292682927,
2156.21484375,
2170.682926829268,
2114.427734375,
2053.7999999999997,
2055.92578125,
1861.778048780488,
2022.49609375,
1719.8487804878048,
2022.49609375,
1561.2219512195122,
2047.568359375,
1419.2926829268292,
2106.0703125
]
]
},
{
"id":"bbe67236-ced4-475a-b964-9c36d7511fd6",
"image_id":0,
"category_id":1,
"iscrowd":0,
"segmentation":[
[
1477.7341463414634,
2039.2109375,
1402.5951219512194,
2072.640625,
1327.4560975609756,
2181.287109375,
1327.4560975609756,
2415.294921875,
1360.8512195121953,
2565.728515625,
1452.6878048780488,
2766.306640625,
1502.780487804878,
2950.169921875,
1561.2219512195122,
3042.1015625,
1644.709756097561,
3092.24609375,
1853.429268292683,
3092.24609375,
1953.6146341463414,
3058.81640625,
2204.0780487804877,
2849.880859375,
2237.4731707317073,
2732.876953125,
2229.1243902439023,
2565.728515625,
2270.868292682927,
2390.22265625,
2270.868292682927,
2172.9296875,
2204.0780487804877,
2080.998046875,
2128.939024390244,
2047.568359375,
1920.2195121951222,
2005.78125,
1678.1048780487804,
2005.78125
]
]
}
],
"categories":[
{
"id":0,
"name":"Car"
},
{
"id":1,
"name":"Coffee"
}
]
}
Audio classification
The annotated dataset to import to an audio classification annotation task needs to be formatted as follows:
A CSV file containing an audio_path and label column. Columns:
- audio_path: The audio_path column needs to specify the locations of the audios.
Note
The audio_path column is used to merge the labels. Please make sure to use the correct relative paths without any duplications.
- label: The label column needs to contain the labels attributed to the audios specified in the audio_path column.
Audio regression
The annotated dataset to import to an audio regression annotation task needs to be formatted as follows:
A CSV file containing an audio_path and label column. Columns:
- audio_path: The audio_path column needs to specify the locations of the audios.
Note
The audio_path column is used to merge the labels. Please make sure to use the correct relative paths without any duplications.
- label: The label column needs to contain the labels attributed to the audios specified in the audio_path column.
- Submit and view feedback for this page
- Send feedback about H2O Label Genie to cloud-feedback@h2o.ai