Download an annotated dataset
Overview
At any point in an annotation task, you can download the already approved annotated samples. You do not need to fully annotate an imported dataset to download already annotated samples (approved samples).
An array of datasets labeled in H2O Label Genie are supported in H2O Hydrogen Torch and H2O LLM Studio.
Instructions
To download an annotated dataset (approves samples), consider the following instructions:
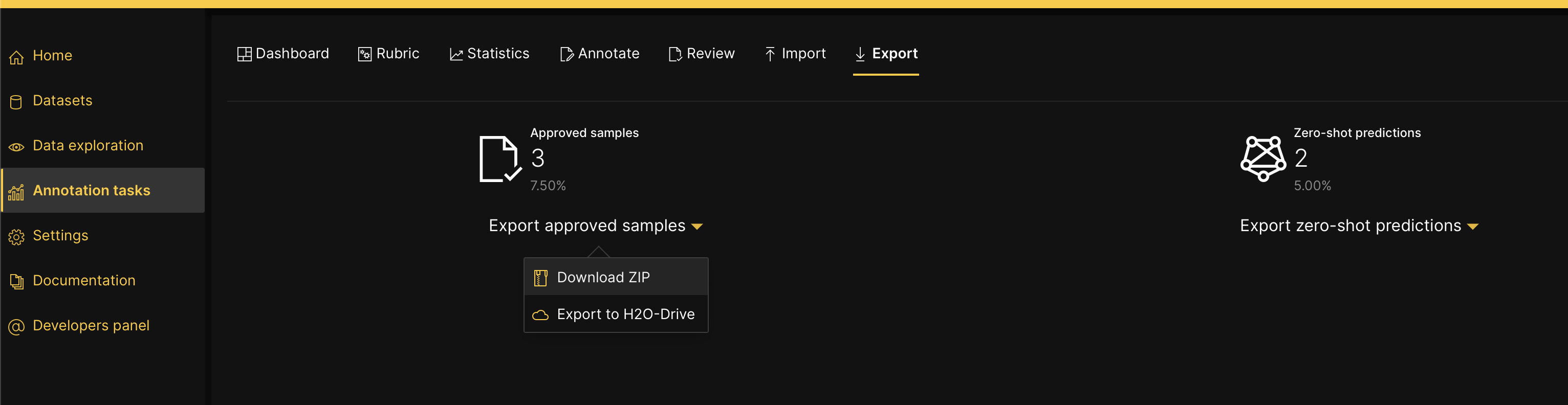
- On the H2O Label Genie navigation menu, click Annotation tasks.
- In the annotation tasks table, double-click the row where the annotation task you want to download is located.
- Click the Export tab.
- In the Export approved samples list, select Download ZIP.
Note
H2O Label Genie downloads a zip file containing the annotated dataset in a particular format depending on the dataset's annotation task. To learn more, see Downloaded dataset formats.
- Zero-shot learning models: H2O Label Genie generates zero-shot predictions for specific annotation tasks that can be downloaded or exported to H2O Drive.
- To learn how to download a dataset's zero-shot predictions, see Download a dataset's zero-shot predictions
- To learn how to export a dataset's zero-shot predictions to H2O Drive, see Export a dataset's zero-shot predictions to H2O Drive
- Export an annotated dataset to H2O Drive: You can export an annotated dataset (approved samples) to H2O Drive. To learn more, see Export an annotated dataset to H2O Drive.
Downloaded dataset formats
Text classification
A downloaded text classification dataset (with approved samples) follows the following dataset format: A zip file (1) containing a CSV file (2):
folder_name.zip (1)
│ └───csv_name.csv (2)
- A zip file.
- A CSV file containing a text and label column:
- text: The text column contains the text input
- label: The label column contains the labels attributed to the texts specified in the text column
H2O Hydrogen Torch supports the downloaded dataset of a text classification annotation task. In particular, H2O Hydrogen Torch supports the downloaded dataset for a text classification experiment.
Text regression
A downloaded text regression dataset (with approved samples) follows the following dataset format: A zip file (1) containing a CSV file (2):
folder_name.zip (1)
│ └───csv_name.csv (2)
- A zip file.
- A CSV file containing a text and label column:
- text: The text column contains the text input
- label: The label column contains the labels attributed to the texts specified in the text column
H2O Hydrogen Torch supports the downloaded dataset of a text regression annotation task. In particular, H2O Hydrogen Torch supports the downloaded dataset for a text regression experiment.
Text-entity recognition
A downloaded text entity recognition dataset (with approved samples) follows the following dataset format: A zip file (1) containing a .pq file (2):
folder_name.zip (1)
│ └───pq_name.pq (2)
- A zip file.
- A
.pqfile containing a text and label column:- text: The text column contains the text input
- label: The label column contains the labels attributed to the text-entities specified in the text column
Text summarization
A downloaded text summarization dataset (with approved samples) follows the following dataset format: A zip file (1) containing a CSV file (2):
folder_name.zip (1)
│ └───csv_name.csv (2)
- A zip file.
- A CSV file containing a text and label column:
- text: The text column contains the text input
- label: The label column contains the summaries attributed to the texts specified in the text column
Text-generative AI
A downloaded text-generative AI dataset (with approved samples) follows the following dataset format: A ZIP file (1) containing a CSV file (2):
folder_name.zip (1)
│ └───csv_name.csv (2)
- A zip file.
- A CSV file containing the following columns:
- llm_input: The final prompts sent to the large language model (LLM) as an input query
- llm_output: The answers provided to the query (llm_input)
- original columns: All the original columns
H2O LLM Studio supports the downloaded dataset of a text-generative AI annotation task.
Image classification
A downloaded image classification dataset (with approved samples) follows the following dataset format: A zip file (1) containing a CSV file (2) and an image folder (3).
folder_name.zip (1)
│ └───csv_name.csv (2)
│ │
│ └───image_folder_name (3)
│ └───name_of_image.image_extension
│ └───name_of_image.image_extension
│ └───name_of_image.image_extension
│ ...
- A zip file.
- A CSV file containing an image_path and label column:
- image_path: The image_path column specifies the location of the image
- label: The label column contains the labels attributed to the images specified in the image_path column
- Image folder that contains all the images specified in the image_path column.
H2O Hydrogen Torch supports the downloaded dataset of an image classification annotation task. In particular, H2O Hydrogen Torch supports the downloaded dataset for an image classification experiment.
Image regression
A downloaded image regression dataset (with approved samples) follows the following dataset format: A zip file (1) containing a CSV file (2) and an image folder (3).
folder_name.zip (1)
│ └───csv_name.csv (2)
│ │
│ └───image_folder_name (3)
│ └───name_of_image.image_extension
│ └───name_of_image.image_extension
│ └───name_of_image.image_extension
│ ...
- A zip file.
- A CSV file containing an image_path and label column:
- image_path: The image_path column specifies the location of the image
- label: The label column contains the labels attributed to the images specified in the image_path column
- Image folder that contains all the images specified in the image_path column
H2O Hydrogen Torch supports the downloaded dataset of an image regression annotation task. In particular, H2O Hydrogen Torch supports the downloaded dataset for an image regression experiment.
Object detection
A downloaded object detection dataset (with approved samples) follows the following dataset format: A zip file (1) containing a .pq file (2) and an image folder (3).
folder_name.zip (1)
│ └───pq_name.pq (2)
│ │
│ └───image_folder_name (3)
│ └───name_of_image.image_extension
│ └───name_of_image.image_extension
│ └───name_of_image.image_extension
│ ...
- A zip file.
- A
.pqfile containing an image_path and class_id column; the file also contains an x_min, x_max, y_min, and y_max column corresponding to the bounding box locations- image_path: The image_path column specifies the location of the image
- class_id: The class_id column contains the class IDs of the bounding box(es)
- x_min,x_max,y_min, and y_max: The x_min, x_max, y_min, and y_max specify the spatial location of the bounding box(es)
- Image folder that contains all the images specified in the image_path column.
H2O Hydrogen Torch supports the downloaded dataset of an object detection task. In particular, H2O Hydrogen Torch supports the downloaded dataset for an image object detection experiment.
Image instance segmentation
A downloaded image instance segmentation dataset (with approved samples) follows the following dataset format: A zip file (1) containing a JSON file (2) and an image folder (3).
folder_name.zip (1)
│ └───json_name.json (2)
│ │
│ └───image_folder_name (3)
│ └───name_of_image.image_extension
│ └───name_of_image.image_extension
│ └───name_of_image.image_extension
│ ...
- A zip file.
- A JSON file containing the labels in a COCO format (+ the annotated dataset's original columns)
- Image folder that contains all the images specified in the JSON file.
H2O Hydrogen Torch supports the downloaded dataset of an image instance segmentation annotation task. In particular, H2O Hydrogen Torch supports the downloaded dataset for an image instance segmentation experiment.
Audio classification
A downloaded audio classification dataset (with approved samples) follows the following dataset format: A zip file (1) containing a CSV file (2) and an audio folder (3).
folder_name.zip (1)
│ └───csv_name.csv (2)
│ │
│ └───audio_folder_name (3)
│ └───name_of_audio.audio_extension
│ └───name_of_audio.audio_extension
│ └───name_of_audio.audio_extension
│ ...
- A zip file.
- A CSV file containing an audio_path and label column:
- audio_path: The audio_path column specifies the location of the audio
- label: The label column contains the labels attributed to the audios specified in the audio_path column
- Audio folder that contains all the audios specified in the audio_path column.
H2O Hydrogen Torch supports the downloaded dataset of an audio classification annotation task. In particular, H2O Hydrogen Torch supports the downloaded dataset for an audio classification experiment.
Audio regression
A downloaded audio regression dataset (with approved samples) follows the following dataset format: A zip file (1) containing a CSV file (2) and an audio folder (3).
folder_name.zip (1)
│ └───csv_name.csv (2)
│ │
│ └───audio_folder_name (3)
│ └───name_of_audio.audio_extension
│ └───name_of_audio.audio_extension
│ └───name_of_audio.audio_extension
│ ...
- A zip file.
- A CSV file containing an audio_path and label column:
- audio_path: The audio_path column specifies the location of the audio
- label: The label column contains the labels attributed to the audios specified in the audio_path column
- Audio folder that contains all the audios specified in the audio_path column.
H2O Hydrogen Torch supports the downloaded dataset of an audio regression annotation task. In particular, H2O Hydrogen Torch supports the downloaded dataset for an audio regression experiment.
- Submit and view feedback for this page
- Send feedback about H2O Label Genie to cloud-feedback@h2o.ai