Hive Setup¶
Driverless AI allows you to explore Hive data sources from within the Driverless AI application. This section provides instructions for configuring Driverless AI to work with Hive in Docker installations.
Description of Configuration Attributes¶
enabled_file_systems: The file systems you want to enable. This must be configured in order for data connectors to function properly.hive_app_configs: Configuration for Hive Connector. Note that inputs are similar to configuring the HDFS connector. Important keys include:hive_conf_path: The path to Hive configuration. This can have multiple files. Typical files include hive-site.xml, hdfs-site.xml, etc.auth_type: Specify one ofnoauth,keytab, orkeytabimpersonationfor Kerberos authenticationkeytab_pathSpecify the path to the Kerberos keytab to use for authentication. This can be “” if usingauth_type='noauth'.principal_user: Specify the Kerberos app principal user. This is required when usingauth_type='keytab'orauth_type=`keytabimpersonation'.
The configuration should be JSON/Dictionary String with multiple keys. For example:
'{ "hive_connection_1": { "hive_conf_path": "/path/to/hive/conf", "auth_type": "one of ['noauth', 'keytab', 'keytabimpersonation']", "keytab_path": "/path/to/<filename>.keytab", "principal_user": "hive/LOCALHOST@H2O.AI", }, "hive_connection_2": { "hive_conf_path": "/path/to/hive/conf_2", "auth_type": "one of ['noauth', 'keytab', 'keytabimpersonation']", "keytab_path": "/path/to/<filename_2>.keytab", "principal_user": "my_user/LOCALHOST@H2O.AI", } }'Note: The expected input of
hive_app_configsis a JSON string. Double quotation marks ("...") must be used to denote keys and values within the JSON dictionary, and outer quotations must be formatted as either""",''', or'. Depending on how the configuration value is applied, different forms of outer quotations may be required. The following examples show two unique methods for applying outer quotations.Configuration value applied with the config.toml file:
hive_app_configs = """{"my_json_string": "value", "json_key_2": "value2"}"""Configuration value applied with an environment variable:
DRIVERLESS_AI_HIVE_APP_CONFIGS='{"my_json_string": "value", "json_key_2": "value2"}'hive_app_jvm_args: In cases where JAAS is required, specify additional Java Virtual Machine (JVM) args for the Hive connector. Each arg must be separated by a space. The following is an example of how this config.toml option can be specified:
hive_app_jvm_args = "-Xmx20g -Djavax.security.auth.useSubjectCredsOnly=false -Djava.security.auth.login.config=/etc/dai/jaas.conf"Notes:
The
-Djavax.security.auth.useSubjectCredsOnly=falsedefault arg is required for Kerberos authentication and impersonation.The
-Djava.security.auth.login.config=/etc/dai/jaas.confdefault arg is required to allow the underlying connector process to adopt the Kerberos login properties defined in /etc/dai/jaas.conf. You must create the jaas.conf file and place it in the specified directory. The following is an example of how the jaas.conf file can be specified:com.sun.security.jgss.initiate { com.sun.security.auth.module.Krb5LoginModule required useKeyTab=true useTicketCache=false principal="super-qa/mr-0xg9.0xdata.loc@H2OAI.LOC" [Replace this line] doNotPrompt=true keyTab="/etc/dai/super-qa.keytab" [Replace this line] debug=true; };
Start Driverless AI¶
This section describes how to enable Hive when starting Driverless AI in Docker. This can done by specifying each environment variable in the nvidia-docker run command or by editing the configuration options in the config.toml file and then specifying that file in the nvidia-docker run command.
Start DAI Using Environment Variables¶
This example enables the Hive connector and starts the Driverless AI Docker image.
nvidia-docker run \ --pid=host \ --init \ --rm \ --shm-size=256m \ --add-host name.node:172.16.2.186 \ -e DRIVERLESS_AI_ENABLED_FILE_SYSTEMS="file,hdfs,hive" \ -e DRIVERLESS_AI_HIVE_APP_CONFIGS='{"hive_connection_2: {"hive_conf_path":"/etc/hadoop/conf", "auth_type":"keytabimpersonation", "keytab_path":"/etc/dai/steam.keytab", "principal_user":"steam/mr-0xg9.0xdata.loc@H2OAI.LOC"}}' \ -p 12345:12345 \ -v /etc/passwd:/etc/passwd:ro \ -v /etc/group:/etc/group:ro \ -v /tmp/dtmp/:/tmp \ -v /tmp/dlog/:/log \ -v /tmp/dlicense/:/license \ -v /tmp/ddata/:/data \ -v /path/to/hive/conf:/path/to/hive/conf/in/docker \ -v /path/to/hive.keytab:/path/in/docker/hive.keytab \ -u $(id -u):$(id -g) \ h2oai/dai-centos7-x86_64:TAG
Start DAI by Updating the config.toml File¶
This example shows how to configure Hive options in the config.toml file, and then specify that file when starting Driverless AI in Docker.
Configure the Driverless AI config.toml file. Set the following configuration options:
enabled_file_systems = "file, upload, hive" hive_app_configs = """{"hive_1": {"auth_type": "keytab", "keytab_path": "/path/in/docker/hive.keytab", "hive_conf_path": "/path/to/Downloads/hive-resources", "principal_user": "hive/localhost@H2O.AI"}}"""
Mount the config.toml file and requisite JAR files into the Docker container. Replace TAG below with your image tag.
nvidia-docker run \ --pid=host \ --init \ --rm \ --shm-size=256m \ --add-host name.node:172.16.2.186 \ -e DRIVERLESS_AI_CONFIG_FILE=/path/in/docker/config.toml \ -p 12345:12345 \ -v /local/path/to/config.toml:/path/in/docker/config.toml \ -v /etc/passwd:/etc/passwd:ro \ -v /etc/group:/etc/group:ro \ -v /tmp/dtmp/:/tmp \ -v /tmp/dlog/:/log \ -v /tmp/dlicense/:/license \ -v /tmp/ddata/:/data \ -v /path/to/hive/conf:/path/to/hive/conf/in/docker \ -v /path/to/hive.keytab:/path/in/docker/hive.keytab \ -u $(id -u):$(id -g) \ h2oai/dai-centos7-x86_64:TAG
After the Hive connector is enabled, you can add datasets by selecting Hive from the Add Dataset (or Drag and Drop) drop-down menu.
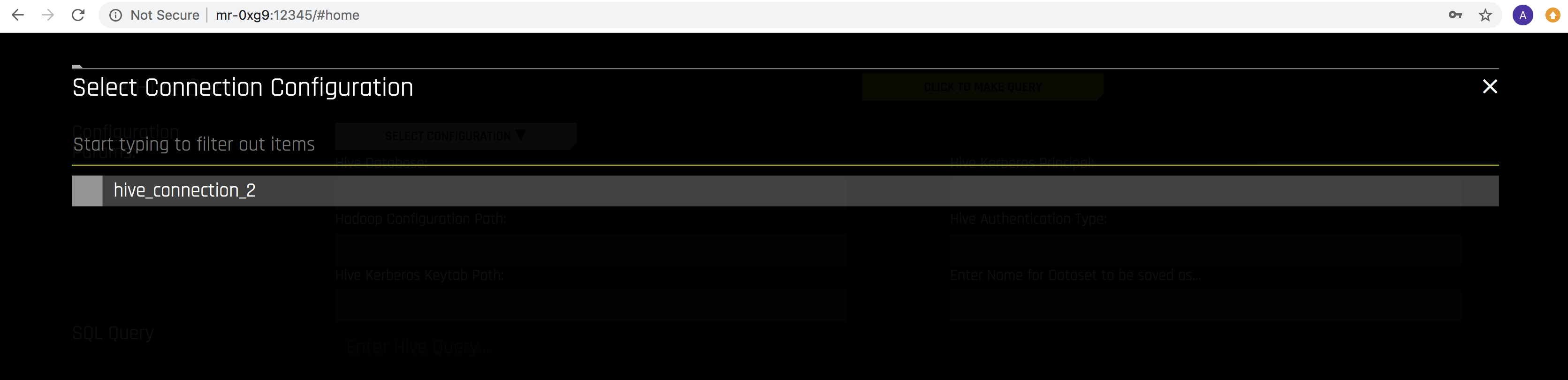
Select the Hive configuraton that you want to use.
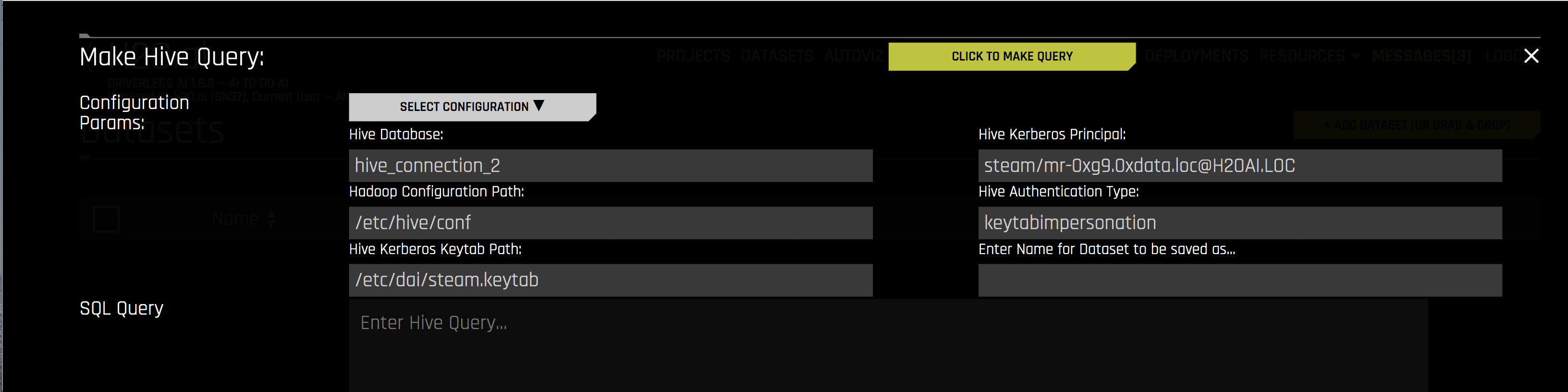
Specify the following information to add your dataset.
Hive Database: Specify the name of the Hive database that you are querying.
Hadoop Configuration Path: Specify the path to your Hive configuration file.
Hive Kerberos Keytab Path: Specify the path for the Hive Kerberos keytab.
Hive Kerberos Principal: Specify the Hive Kerberos principal. This is required if the Hive Authentication Type is keytabimpersonation.
Hive Authentication Type: Specify the authentication type. This can be noauth, keytab, or keytabimpersonation.
Enter Name for Dataset to be saved as: Optionally specify a new name for the dataset that you are uploading.
SQL Query: Specify the Hive query that you want to execute.