Snowflake Setup¶
Driverless AI allows you to explore Snowflake data sources from within the Driverless AI application. This section provides instructions for configuring Driverless AI to work with Snowflake. This setup requires you to enable authentication. If you enable Snowflake connectors, those file systems will be available in the UI, but you will not be able to use those connectors without authentication.
Start Driverless AI¶
The following sections describes how to enable the Snowflake data connector when starting Driverless AI in Docker. This can done by specifying each environment variable in the nvidia-docker run command or by editing the configuration options in the config.toml file and then specifying that file in the nvidia-docker run command.
Enable Snowflake with Authentication¶
This example enables the Snowflake data connector with authentication by passing the account, user, and password variables. Replace TAG below with the image tag.
nvidia-docker run \
--rm \
--shm-size=256m \
-e DRIVERLESS_AI_ENABLED_FILE_SYSTEMS="file,snow" \
-e DRIVERLESS_AI_SNOWFLAKE_ACCOUNT = "<account_id>" \
-e DRIVERLESS_AI_SNOWFLAKE_USER = "<username>" \
-e DRIVERLESS_AI_SNOWFLAKE_PASSWORD = "<password>"\
-u `id -u`:`id -g` \
-p 12345:12345 \
-v `pwd`/data:/data \
-v `pwd`/log:/log \
-v `pwd`/license:/license \
-v `pwd`/tmp:/tmp \
-v `pwd`/service_account_json.json:/service_account_json.json \
h2oai/dai-centos7-x86_64:TAG
After the Snowflake connector is enabled, you can add datasets by selecting Snowflake from the Add Dataset (or Drag and Drop) drop-down menu.
Start DAI by Updating the config.toml File¶
This example shows how to configure Snowflake options in the config.toml file, and then specify that file when starting Driverless AI in Docker.
Configure the Driverless AI config.toml file. Set the following configuration options.
enabled_file_systems = "file, snow"
snowflake_account = "<account_id>"
snowflake_user = "<username>"
snowflake_password = "<password>"
Mount the config.toml file into the Docker container.
nvidia-docker run \ --pid=host \ --init \ --rm \ --shm-size=256m \ --add-host name.node:172.16.2.186 \ -e DRIVERLESS_AI_CONFIG_FILE=/path/in/docker/config.toml \ -p 12345:12345 \ -v /local/path/to/config.toml:/path/in/docker/config.toml \ -v /etc/passwd:/etc/passwd:ro \ -v /etc/group:/etc/group:ro \ -v /tmp/dtmp/:/tmp \ -v /tmp/dlog/:/log \ -v /tmp/dlicense/:/license \ -v /tmp/ddata/:/data \ -u $(id -u):$(id -g) \ h2oai/dai-centos7-x86_64:TAG
Adding Datasets from Snowflake¶
After the Snowflake connector is enabled, you can add datasets by selecting Snowflake from the Add Dataset (or Drag and Drop) drop-down menu.

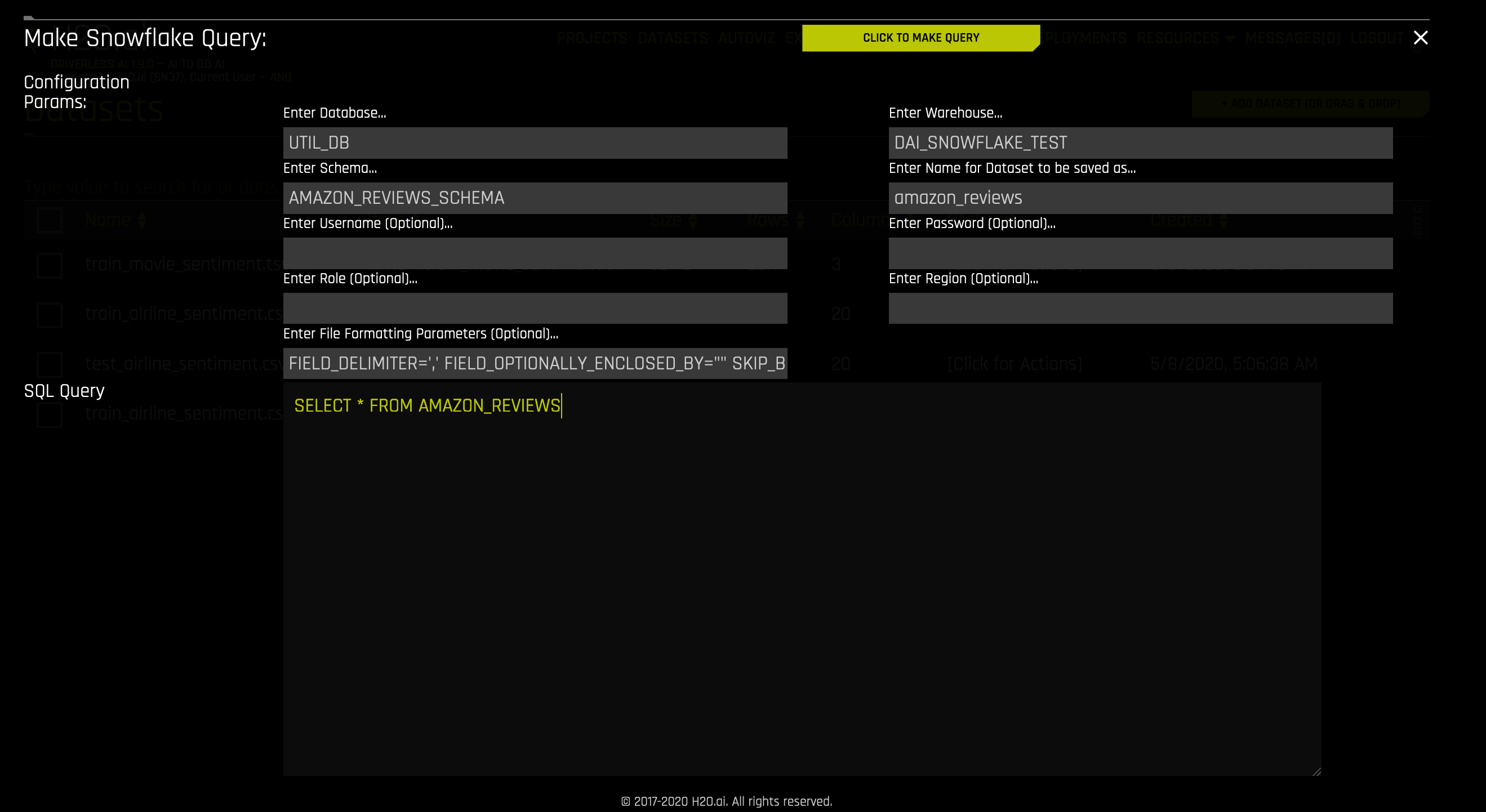
Specify the following information to add your dataset.
Enter Database: Specify the name of the Snowflake database that you are querying.
Enter Warehouse: Specify the name of the Snowflake warehouse that you are querying.
Enter Schema: Specify the schema of the dataset that you are querying.
Enter Name for the Dataset to be saved as: Specify an the name for this dataset as it will appear in Driverless AI.
Enter Username (Optional): Specify the username associated with this Snowflake account. This can be left blank if
snowflake_userwas specified in the config.toml when starting Driverless AI; otherwise, this field is required.Enter Password (Optional): Specify the password associated with this Snowflake account. This can be left blank if
snowflake_passwordwas specified in the config.toml when starting Driverless AI; otherwise, this field is required.Enter Region: (Optional) Specify the region of the warehouse that you are querying. This can be found in the Snowflake-provided URL to access your database (as in <optional-deployment-name>.<region>.<cloud-provider>.snowflakecomputing.com). This is optional and can also be left blank if
snowflake_urlwas specified with a<region>in the config.toml when starting Driverless AI.Enter Role: (Optional) Specify your role as designated within Snowflake. See https://docs.snowflake.net/manuals/user-guide/security-access-control-overview.html for more information.
Enter File Formatting Params: (Optional) Specify any additional parameters for formatting your datasets. Available parameters are listed in https://docs.snowflake.com/en/sql-reference/sql/create-file-format.html#type-csv. (Note: Use only parameters for
TYPE = CSV.) For example, if your dataset includes a text column that contains commas, you can specify a different delimiter usingFIELD_DELIMITER='character'. Separate multiple parameters with spaces only. For example:
FIELD_DELIMITER=',' FIELD_OPTIONALLY_ENCLOSED_BY="" SKIP_BLANK_LINES=TRUENote: Be sure that the specified delimiter is not also used as a character within a cell; otherwise an error will occur. For example, you might specify the following to load the “AMAZON_REVIEWS” dataset:
Database: UTIL_DB
Warehouse: DAI_SNOWFLAKE_TEST
Schema: AMAZON_REVIEWS_SCHEMA
Query: SELECT * FROM AMAZON_REVIEWS
Enter File Formatting Parameters (Optional): FIELD_OPTIONALLY_ENCLOSED_BY = ‘”’
In the above example, if the
FIELD_OPTIONALLY_ENCLOSED_BYoption is not set, the following row will result in a failure to import the dataset (as the dataset’s delimiter is,by default):positive, 2012-05-03,Wonderful\, tasty taffy,0,0,3,5,2012,Thu,0Note: Numeric columns from Snowflake that have NULL values are sometimes converted to strings (for example, \ \N). To prevent this from occuring, add
NULL_IF=()to the input of FILE FORMATTING PARAMETERS.
Enter Snowflake Query: Specify the Snowflake query that you want to execute.
When you are finished, select the Click to Make Query button to add the dataset.