时间序列设置¶
time_series_recipe¶
Time-Series Lag-Based Recipe
此插件指定在使用所提供的(或自动检测的)时间列训练模型时是否包括时间序列滞后特征。默认会启用此插件。所生成的主要时间序列特征是滞后特征,即为变量的过去值。在具有时间戳 \(t\) 的给定样本中,考虑了在过去某一时差 \(T\) (滞后)的特征。例如,如果今天的销量为 300,昨天的销量为 250,则销量方面一天的滞后就为 250。可对任何特征和目标创建滞后项。滞后变量在时间序列中非常重要,因为知道在过去的不同时间段内发生了什么情况会极大地方便对未来的预测。请注意:在启用带有时间列的基于滞后的插件时,会禁用集成,因为此插件仅支持单个最终模型。如果选择时间列或如果在实验设置屏幕中将时间列设置为 [Auto],也会禁用集成。
时间序列用例:销量预测 一节提供了关于时间序列滞后的更多信息。
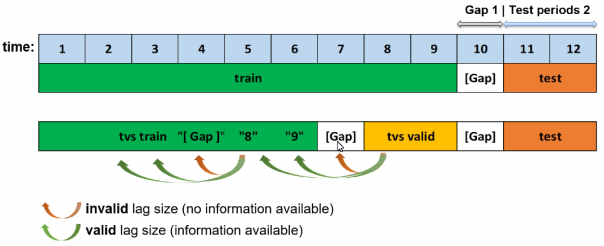
time_series_leaderboard_mode¶
Control the automatic time-series leaderboard mode
从以下选项中选择:
‘diverse’:探索使用各种专家设置构建的各种模型集。注意,您可以在表现最好的模型之上重新运行另一个不同的排行榜,这将有效地帮助您构建这些专家设置。
‘sliding_window’:如果预测期为 N 时段,以时段为单位为 “每个 (间隔, 预测期) 对 (0,n), (n,n), (2*n,n), …, (2*N-1, n) 创建一个独立模型。每个模型的预测时段数 n 由专家设置
time_series_leaderboard_periods_per_model控制,默认值为 1。它有助于提高短期预测质量。
time_series_leaderboard_periods_per_model¶
Number of periods per model if time_series_leaderboard_mode is ‘sliding_window’
如果 time_series_leaderboard_mode 设置为 sliding_window ,指定每个模型的时段数。值越大,会导致模型越少。
time_series_merge_splits¶
Larger Validation Splits for Lag-Based Recipe
指定是否创建不与预测期长度绑定的更大验证拆分段。这有助于防止对小数据或短预测期进行过度拟合。默认会启用此选项。
merge_splits_max_valid_ratio¶
Maximum Ratio of Training Data Samples Used for Validation
指定在创建更大验证拆分段时用于在各拆分中进行验证的训练数据样本的最大比例(请参阅 time_series_merge_splits 设置)。根据验证拆分段的总数, 默认值 (-1) 会自动设置此比例值。
fixed_size_splits¶
Fixed-Size Train Timespan Across Splits
指定是否在内部验证过程中为基于时间的各个拆分段保持固定的训练时间跨度,这会导致每个拆分段中存在相同数量的训练样本。默认会禁用此选项。
time_series_validation_fold_split_datetime_boundaries¶
Custom Validation Splits for Time-Series Experiments
指定将用于自定义训练和验证拆分的日期或日期时间戳(与时间列的格式相同)。
timeseries_split_suggestion_timeout¶
Timeout in Seconds for Time-Series Properties Detection in UI
在 Driverless AI 用户界面上指定时间序列属性检测的超时时间,单位为秒。默认值为 30。
holiday_features¶
Generate Holiday Features
对于时间序列实验,指定是否为实验生成假日特征。默认会启用此选项。
holiday_countries¶
Country code(s) for holiday features
以列表形式指定国家/地区代码,此列表用来查询节假日。
请注意:此设置仅用于迁移。
override_lag_sizes¶
Time-Series Lags Override
指定将使用的替代滞后项。这些滞后项可用于为应用了替代后仍然被考虑的滞后项赋予更高的重要性。以下示例显示了可用来指定替代滞后项的各种方法:
“[0]” 禁用滞后项
“[7, 14, 21]” 指定此确切列表
“21” 指定每个值的范围为 1 至 21
“21:3” 指定每个值的范围为 1 至 21,步长为 3
“5-21” 指定每个值的范围为 5 至 21
“5-21:3” 指定每个值的范围为 5 至 21,步长为 3
override_ufapt_lag_sizes¶
Lags Override for Features That are not Known Ahead of Time
为没有提前已知的非目标特征指定滞后项替代。
“[0]” 禁用滞后项
“[7, 14, 21]” 指定此确切列表
“21” 指定每个值的范围为 1 至 21
“21:3” 指定每个值的范围为 1 至 21,步长为 3
“5-21” 指定每个值的范围为 5 至 21
“5-21:3” 指定每个值的范围为 5 至 21,步长为 3
override_non_ufapt_lag_sizes¶
Lags Override for Features That are Known Ahead of Time
为提前已知的非目标特征指定滞后项替代。
“[0]” 禁用滞后项
“[7, 14, 21]” 指定此确切列表
“21” 指定每个值的范围为 1 至 21
“21:3” 指定每个值的范围为 1 至 21,步长为 3
“5-21” 指定每个值的范围为 5 至 21
“5-21:3” 指定每个值的范围为 5 至 21,步长为 3
min_lag_size¶
Smallest Considered Lag Size
指定所考虑的最小滞后阶数。默认值为 -1。
allow_time_column_as_feature¶
Enable Feature Engineering from Time Column
指定是否根据所选时间列(如 Date~weekday)启用特征工程。默认会启用此选项。
allow_time_column_as_numeric_feature¶
Allow Integer Time Column as Numeric Feature
指定是否通过整数时间列启用特征工程。请注意,如果您使用时间序列插件,将时间列(数字时间戳)用作输入特征会导致模型存储实际时间戳而非在未来可泛化的特征。默认会禁用此选项。
datetime_funcs¶
Allowed Date and Date-Time Transformations
指定允许 Driverless AI 使用的日期或日期时间转换方式。从以下转换器中选择:
年
季度
月
周
星期
日
日期
数值(表示时间浮点值的直接数值,默认会禁用)
时
分
秒
Driverless AI 中的特征采用 get_ 的形式,其后带有转换器名称。注意如果对 IID 问题使用 get_num,会导致过度拟合。默认会禁用 get_num.
filter_datetime_funcs¶
Auto Filtering of Date and Date-Time Transformations
指定是否自动过滤掉会在未来产生不可见值的日期和日期时间转换。默认会启用此选项。
allow_tgc_as_features¶
Consider Time Groups Columns as Standalone Features
指定是否将时间分组列视为独立特征。默认会禁用此选项。
allowed_coltypes_for_tgc_as_features¶
Which TGC Feature Types to Consider as Standalone Features
指定是否将时间分组列 (TGC) 视为独立特征。如果启用了 ”将时间分组列视为独立特征” ,则指定将哪些类型的 TGC 特征视为独立特征。可用类型为 numeric、categorical、ohe_categorical、datetime、date 和 text 。默认会选择所有类型。请注意,”time_column” 将通过 “从时间列启用特征工程” 选项单独处理 。另请注意,如果禁用 “时间序列滞后插件” ,则所有时间分组都将是允许的特征。
enable_time_unaware_transformers¶
Enable Time Unaware Transformers
指定是否启用各种转换器(聚类、截断 SVD);对于时间序列实验,由于在每个折叠的拟合范围内可能随时间泄露而发生过度拟合,因此会禁用此选项。此选项默认设置为 Auto 。
tgc_only_use_all_groups¶
Always Group by All Time Groups Columns for Creating Lag Features
指定是否对用于创建滞后特征而进行采样的所有时间分组列进行分组。默认会启用此选项。
tgc_allow_target_encoding¶
Allow Target Encoding of Time Groups Columns
指定是否允许对时间分组列进行目标编码。默认禁用此项设置。
请注意:
此设置不受
allow_tgc_as_features的影响。可通过禁用
tgc_only_use_all_groups对子组进行编码。
time_series_holdout_preds¶
Generate Time-Series Holdout Predictions
指定是否使用移动窗口针对训练数据创建用于诊断的保持预测。默认会启用此选项。此选项可用于 MLI,但启用后会降低实验的速度。请注意,在此设置启用后,模型本身仍然保持不变。
time_series_validation_splits¶
Number of Time-Based Splits for Internal Model Validation
指定用于内部模型验证、基于时间的拆分数量(固定值)。请注意,允许的拆分段实际数量可小于指定值,并且在实验运行时会确定允许的拆分段数量。默认值为 -1(自动)。
time_series_splits_max_overlap¶
Maximum Overlap Between Two Time-Based Splits
指定两个基于时间的拆分段之间的最大重叠。此值越大,可能的拆分段就越多。默认值为 0.5。
time_series_max_holdout_splits¶
Maximum Number of Splits Used for Creating Final Time-Series Model’s Holdout Predictions
指定用于创建最终时间序列模型的保持预测的最大拆分段数量。如果默认值为 (-1),则会使用在模型验证过程中使用的相同拆分段数量。使用 time_series_validation_splits 控制用于模型验证的基于时间的拆分段数量。
mli_ts_fast_approx¶
Whether to Speed up Calculation of Time-Series Holdout Predictions
指定是否要针对训练数据的回溯测试加快时间序列保持预测。此设置用于 MLI 和计算指标。请注意,此设置启用后,预测的准确度可能稍有降低。默认会禁用此设置。
mli_ts_fast_approx_contribs¶
Whether to Speed up Calculation of Shapley Values for Time-Series Holdout Predictions
指定是否要针对训练数据的回溯测试,为时间序列保持预测加快生成 Shapley 值。此设置用于 MLI。请注意,此设置启用后,预测的准确度可能稍有降低。默认会启用此设置。
mli_ts_holdout_contribs¶
Generate Shapley Values for Time-Series Holdout Predictions at the Time of Experiment
指定是否针对在实验时使用移动窗口进行的训练数据保持预测,允许创建 Shapley 值。此设置可用于 MLI,但在启用后,会降低实验的速度。如果禁用此设置,MLI 会按需生成 Shapley 值。默认会启用此设置。
time_series_min_interpretability¶
Lower Limit on Interpretability Setting for Time-Series Experiments (Implicitly Enforced)
指定时间序列实验的可解释性设置下限。如果值大于等于 5 (默认值),将会更主动地丢弃最不重要的特征,以提高泛化性能。若要禁用此设置,可将值设置为 1。
lags_dropout¶
Dropout Mode for Lag Features
指定滞后特征的丢弃模式,以达到训练与验证/测试之间相等的 NA 比。独立 模式将执行简单的特征丢弃。依赖 模式将对每个样本/行考虑滞后阶数的依赖性。默认会启用 依赖 模式。
prob_lag_non_targets¶
Probability to Create Non-Target Lag Features
可对任何特征和目标创建滞后项。指定创建非目标滞后特征的概率值。默认值为 0.1。
rolling_test_method¶
Method to Create Rolling Test Set Predictions
指定用于创建滚动测试集预测的方法。可选择测试时增强 (TTA) 或最终管道连续调整(调整)。默认会启用 TTA。
请注意:
此设置仅适用于用户在实验过程中提供的测试集。
只有提供测试集的时间跨度超出预测期且测试集的目标值已知,此设置才起作用。
fast_tta_internal¶
Fast TTA for Internal Validation
指定遗传算法是否应用一次测试时增强 (TTA) ,而不是将滚动窗口用于时长超过预测期的验证拆分。默认会启用此设置。
prob_default_lags¶
Probability for New Time-Series Transformers to Use Default Lags
指定与新滞后项或 EWMA 基因使用默认滞后值的概率。此设置取决于频率、间隔和预测期,与数据无关。默认值为 0.2。
prob_lagsinteraction¶
Probability of Exploring Interaction-Based Lag Transformers
指定根据交互情况选择其他滞后时间序列转换器的非规范化概率。默认值为 0.2。
prob_lagsaggregates¶
Probability of Exploring Aggregation-Based Lag Transformers
指定根据聚合情况选择其他滞后时间序列转换器的非规范化概率。默认值为 0.2。
ts_target_trafo¶
Time Series Centering or Detrending Transformation
指定是否将居中或趋势分离转换用于时间序列实验。从以下选项中选择:
无(默认)
居中(快速)
居中(稳健)
线性(快速)
线性(稳健)
逻辑
传染病(使用 SEIRD 模型)
在拟合所选模型的自由参数后,立即将拟合信号从每个时间序列的目标信号中移除。线性 或 逻辑 选项将移除拟合的线性和逻辑趋势,居中 选项只能移除目标信号的平均值,传染病 选项将移除通过 易感-暴露-感染-康复-死亡 (SEIRD) 传染病模型指定的信号。在针对残差对管道进行拟合后,可立即通过添加之前移除的信号实施预测。
请注意:
目前当此设置被启用时,会禁用 MOJO 支持。
快速 居中和线性趋势分离选项使用最小二乘方拟合。
稳健 居中和线性趋势分离选项使用 随机样本一致性 (RANSAC) 达到更高的异常值容限。
关于如何自定义自由 SEIRD 参数边界的更多详细信息,请参阅 ( Custom Bounds for SEIRD Epidemic Model Parameters) 。
ts_target_trafo_epidemic_params_dict¶
Custom Bounds for SEIRD Epidemic Model Parameters
针对每个时间序列分组,指定用于控制 易感-暴露-感染-康复-死亡 (SEIRD) 传染病模型参数的自定义边界,以便对目标进行趋势分离。目标列必须与 I(t) (将感染病例数表示为时间的函数)对应。
对于每个训练拆分段和时间序列分组,针对每个时间序列分组优化一系列自由参数,从而将 SEIRD 模型拟合为目标信号。之后将模型的值从训练响应中减除,将残差传递给特征工程和建模管道。对于预测,将 SEIRD 模型的值加入每个时间序列分组的管道得出的残差预测结果中。
以下是自由参数的列表:
N:总人数,N = S+E+I+R+D
beta:暴露率 (S -> E)
Gamma:康复率 (I -> R)
delta:潜伏期
alpha:致死率
rho:个体死亡率
lockdown:封锁天数 (-1 => 不封锁)
beta_decay:因封锁产生的 Beta 衰减
beta_decay_rate:beta 衰减的速度
提供您想控制的每个参数的上限或下限。以下是有效参数的列表:
N_minN_maxbeta_minbeta_maxgamma_mingamma_maxdelta_mindelta_maxalpha_minalpha_maxrho_minrho_maxlockdown_minlockdown_maxbeta_decay_minbeta_decay_maxbeta_decay_rate_minbeta_decay_rate_max
您可以更改参数的任何子集。例如:
ts_target_trafo_epidemic_params_dict="{'N_min': 1000, 'beta_max': 0.2}"
更多关于 SEIRD 模型的信息,请参考 https://en.wikipedia.org/wiki/Compartmental_models_in_epidemiology 和 https://arxiv.org/abs/1411.3435。
请注意:如果死亡率非常低,SEIR 模型可显著提高计算速度。要获取 SEIR 模型,需设置 alpha_min=alpha_max=rho_min=rho_max=beta_decay_rate_min=beta_decay_rate_max=0 和 lockdown_min=lockdown_max=-1.
ts_target_trafo_epidemic_target¶
Which SEIRD Model Component the Target Column Corresponds To
为要对应的目标列指定 SEIRD 模型组件。从以下选项中选择:
I (默认值):已感染
R:已康复
D:已死亡
ts_lag_target_trafo¶
Time Series Lag-Based Target Transformation
指定是使用当前目标与滞后目标之间的差值还是比值。选项包括 无 (默认值)、差值 和 比值 。
请注意:
目前当此设置被启用时,会禁用 MOJO 支持。
通过
ts_target_trafo_lag_size专家设置指定对应的滞后阶数。
ts_target_trafo_lag_size¶
Lag Size Used for Time Series Target Transformation
指定用于时间序列目标转换的滞后阶数。当使用 ts_lag_target_trafo 设置时,需指定此设置。默认值为 -1。
请注意 :滞后阶数不应小于预测期和间隔之和。