内部验证方法¶
本节介绍 Driverless AI 的内部验证方法。
对于实验,Driverless AI 将:
把数据拆分为训练集和内部验证集
或
使用交叉验证将数据拆分为 \(n\) 个折叠
Driverless AI 将根据数据大小和准确度设置选择方法。对于方法 1,部分数据将被移除以用于内部验证。(请注意:如果数据较小,则可能重复此训练和内部验证拆分,以将更多数据用于训练。)
但是,对于方法 2,不会由于内部验证而浪费任何数据。通过交叉验证,可利用整个数据集,并且可使用训练数据的不同子集训练每个模型。以下可视化视图表展示了一个 5 折交叉验证的示例。
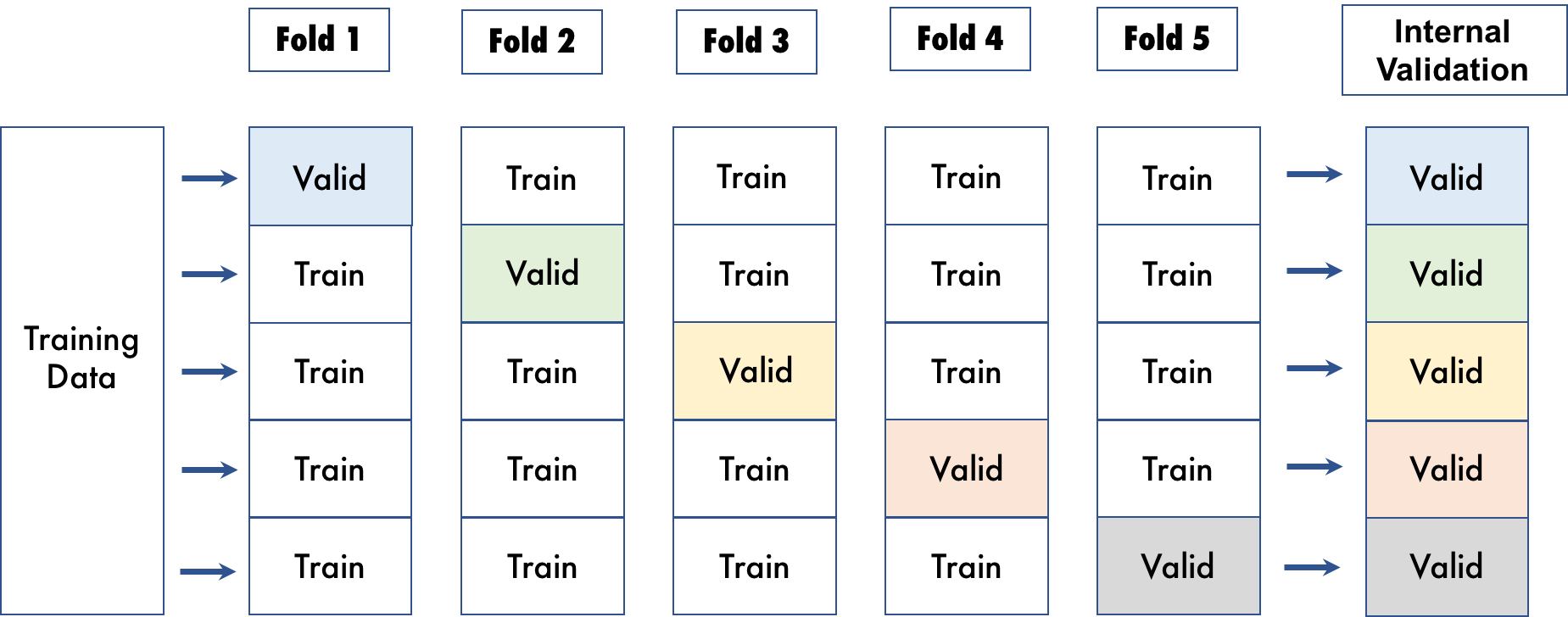
Driverless AI 将数据随机拆分成指定数量的交叉验证折叠。通过交叉验证,可利用整个数据集,并且可使用训练数据的不同子集训练每个模型。
如果用户提供了折叠列或验证数据集,则 Driverless AI 将不会自动随机创建内部验证数据。如果提供了折叠列或验证数据集,则 Driverless AI 将使用所提供的数据来计算 Driverless AI 模型的性能以及计算所有性能图表和统计数据。(请注意:折叠列和权重列在建模过程中不会被用作特征。)
如果实验属于时间序列用例,并选择了时间列,则 Driverless AI 将更改内部验证数据的创建方式。对于时间数据,则会使用历史数据进行训练并使用较新的数据进行验证,这一点尤为重要。Driverless AI 不执行随机拆分,而是会遵循数据的时间特性以防止任何数据泄露。此外,训练/验证拆分是训练和测试之间的时间间隔以及预测期(要预测的时间周期数量)的函数。如果提供了测试数据,则 Driverless AI 将针对这些参数的值提出建议,这些值会导致得到与测试集尽可能相似的验证集。但是用户可以控制验证拆分的创建,以对其进行调整,使其适用于实际的应用。