时间序列最佳实践¶
本文档介绍关于在 Driverless AI 中运行时间序列实验的最佳实践。
准备数据¶
时间序列用例的目标是使用历史数据进行预测。用于预测的数据将依据预测的目的格式化。若要格式化用于预测的数据,需聚合相应时间段内各个分组的数据。
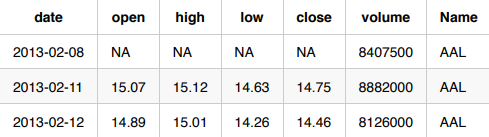
在以下三个用例中,预测了依据标准普尔 500 指数股票的交易量。每个用例均提供了决定数据格式化方式的唯一场景。我们的原始数据如下所示:
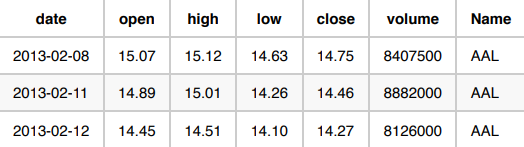
用例 1:预测明天的股票总交易量。
在此用例中,您可以保持原始数据,因为已经按
Name和日对其进行了聚合。
用例 2:预测下月的股票总交易量。
在此用例中,将按
Name和月计算总交易量。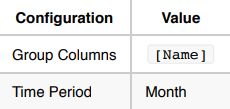
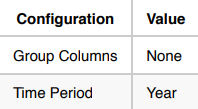
用例 3:预测所有标普 500 股票明年的总交易量。
在此用例中,将计算所有标普 500 股票的全年总交易量。
实验设置¶
将数据格式化以匹配您的用例之后,可以立即开始设置您的实验。

时间序列设置¶
在提供时间列之后,您还需完成时间序列特定的配置。

时间分组列:将数据分割为各个时间序列的列。在本实例中,每支股票有一个时间序列(列:Name),因此,将 Name 选为时间分组列。
预测时不可用的列:在预测时未知的列。在标普 500 数据示例中,独立的变量为
open、high、low和close. 非提前已知的任何变量必须被标记为在“预测时不可用的列”。Driverless AI 只将历史值用于被标记的独立变量。预测期:您想预测未来多长的时间。
间隔:指定训练数据与要开始预测的时刻之间是否有任何间隔。例如,如果您想在星期一预测星期三和星期四的股票交易量,则您必须提供以下配置:
预测期 = 2 日
间隔 = 1 日
对于第一个用例(预测明天的股票交易量),时间序列特定的配置设置如下:

验证和测试¶
对于时间序列用例,始终依据更新的数据验证和测试模型。在 Driverless AI 中,默认会自动创建验证数据,这些数据用来评估每个模型的性能。
测试数据是用户提供的可选数据集。只有在选择最终模型以防止意外将测试数据过度拟合之后, Driverless AI 才使用此数据集。
验证数据
Driverless AI 使用滚动窗口方法自动生成验证数据。验证数据中包含的时间单位的数量与预测期和间隔配置相匹配。如果您想预测明天的数据,则验证数据必须包括一天的数据。如果您想预测未来五天的数据,验证数据必须包括五天的数据。在第一个用例中,Driverless AI 将在内部创建拆分段,在这些拆分段中,验证数据总是包括一天的数据。
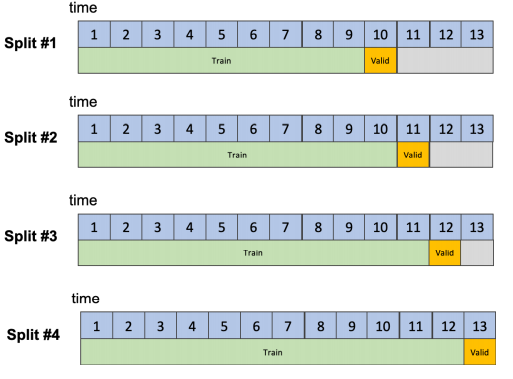
用于验证模型的数据点总数为:
在用例中,时间分组列的数量较小,并且您只想预测某一支股票的交易量,验证数据可能会变得非常小。对于这些用例,必须确保验证数据足够大,以防止过度拟合。为此,一般可以使用两种方法:增加 Driverless AI 完成的验证拆分段的数量,或增加数据集中时间分组列的数量。您可以通过进入“时间序列”选项卡中的“专家设置”增加 Driverless AI 执行验证拆分数量。

默认情况下,Driverless AI 依据“准确度”设置自动确定验证拆分数量(准确度越高,验证拆分数量就越大)。如果您知道每个验证拆分段的行数较少(这意味着时间分组列的数量较少和/或预测期较短),则您可以使用更大的数量覆盖这一数量。
如果覆盖此数量,您可以通过实验预览查看所带来的变化。在以下实验中,已通过专家设置面板将验证拆分数量增加到 20。实验预览也反映了这一变化。

防止验证数据较小的另一种方法是考虑包含更多的时间分组列。您可以整合所有股票的数据并运行单个实验,而非针对每支股票分别预测交易量。
测试数据
测试数据是用户提供的可选数据集。Driverless AI 依据此数据集自动计算最终模型的性能,但不会使用此数据集来选择模型。测试数据集可能会比预测期大。第一个用例涉及到预测明天的股票交易量。但是,您可以为 Driverless AI 提供一个月的测试数据。在此场景中,Driverless AI 将评估模型在以下方面的性能:在一个月的时间段内预测明天的股票交易量。
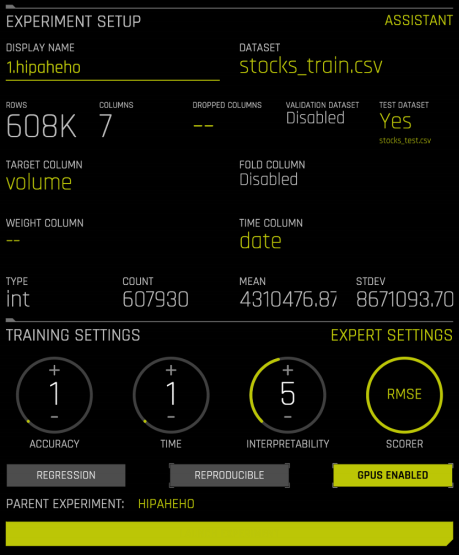

通过 MLI 解释模型¶
在完成实验后点击“解释此模型”,即可收集关于最终模型使用验证和测试数据进行预测的性能信息。
“模型可解释性”模块中的第一个图表显示了验证和测试数据中每个日期的误差:

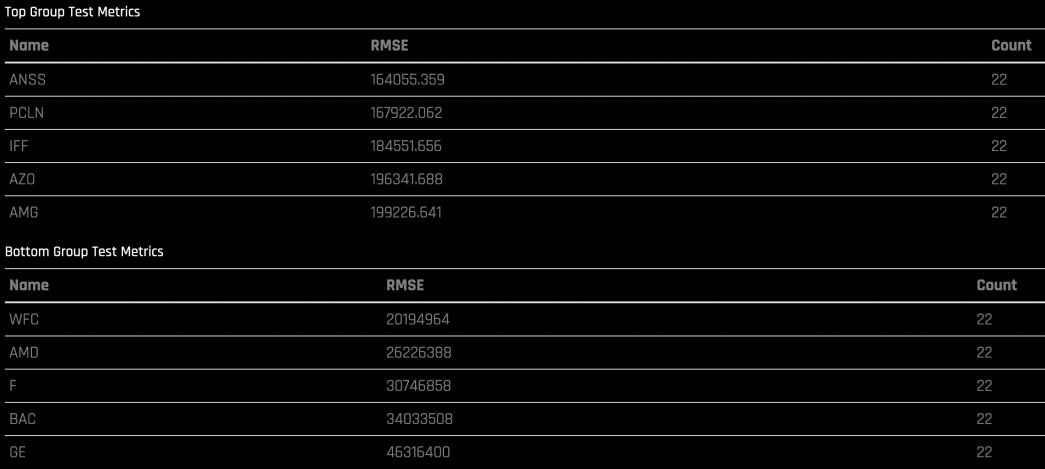
您还可以查看误差非常高和误差非常低的分组:
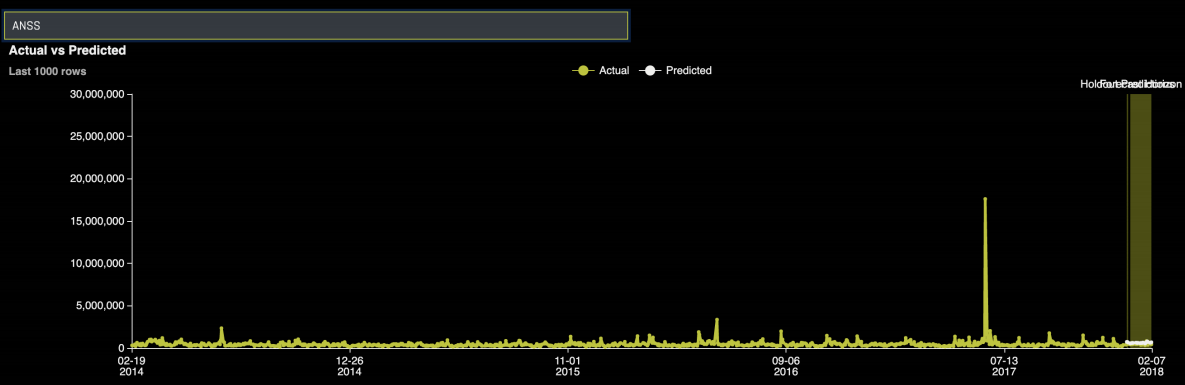
您可以搜索某一分组,以查看实际时间序列和预测时间序列:
点击某一预测点,即可查看该预测点的 Shapley 贡献值,这样就可以知道每个预测因子对该点预测的影响。
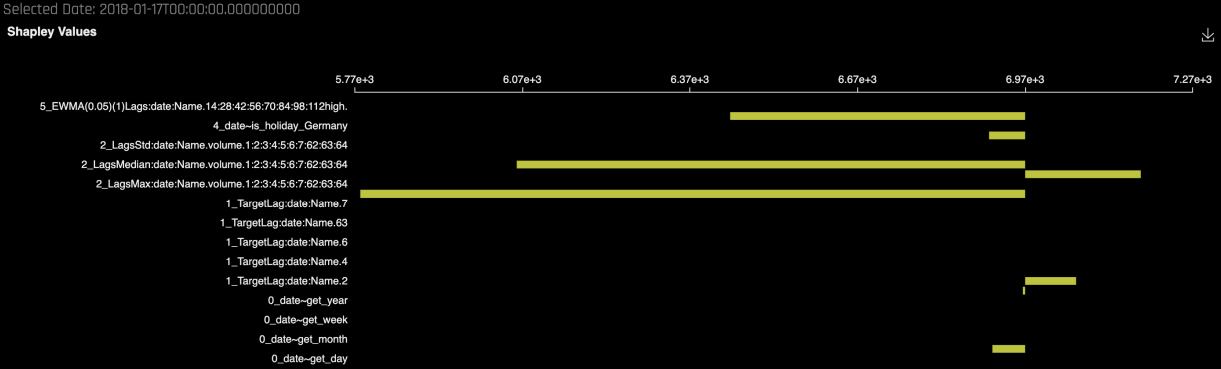
Shapley 贡献值也表示与所选日期相关的每个预测因子的强度和方向。
评分¶
由于 Driverless AI 构建了传统的机器学习模型(如 GLM、GBM、随机森林),其要求提供用于评分的记录,以生成预测值。如果您想使用模型进行预测,将有三种不同的评分选项:
使用 Driverless AI
Python 评分管道
不依赖 Driverless AI
内部附带评分函数的 Python whl
MOJO 评分管道
不依赖 Driverless AI
Java 运行时或 C++ 运行时
如果您要使用模型对预测期以后的时间段进行评分,则只能使用 Driverless AI 或 Python 评分管道进行评分。这意味着如果您为 Driverless AI 提供 2018 年 2 月 7 日之前的训练数据并请求 Driverless AI 构建模型以预测明天的交易量,则只能使用 MOJO 得出 2018 年 2 月 8 日的评分。
MOJO 是无状态的,取一个记录,提供一个预测值。由于其无状态,只能使用训练数据中保存的信息(如过去的行为)。如果 Driverless AI 模型显示前一天的股票交易量非常重要,则在使用 MOJO 开始对 2018 年 2 月 8 日以后的时间段进行评分后,其将不再拥有与前一日股票交易量相关的信息。
在预测期内预测
如果想在预测期内预测,您可以为 Driverless AI、Python 评分管道或 MOJO 评分管道提供您想用于预测的记录。例如:
训练数据结束于 2018 年 1 月 5 日(星期五),并且您想预测下一交易日的股票交易量。因此,2018 年 1 月 8 日(星期一)在预测期内。为了预测 AAL 股票在 2018 年 1 月 8 日的交易量,需提供具有以下数据的任何评分方法:

输出为交易量预测值。
请注意:由于在预测时开盘价 (Open)、最高价 (High)、最低价 (Low) 和收盘价 (Close) 等变量未知,因此将以 NA 填充。
在预测期外预测
如果您想使用模型预测 2018 年 1 月 8 日以后的数据,则您只能使用 Driverless AI 或 Python 评分管道进行评分,因为 MOJO 是无状态的,不能在预测期以外使用。
为了在预测期以外预测,您需要为模型提供在训练数据结束以后产生的、在您想预测的那一日之前的任何信息。如果您想预测 2018 年 1 月 9 日的数据,则必须为模型提供 2018 年 1 月 8 日(训练数据中没有此日期,因此 Driverless AI 并不知道在该日发生了什么)的相关信息。
为了对 2018 年 1 月 9 日进行评分,需为 Driverless AI 提供以下数据:
模型会返回两个预测值:2018 年 1 月 8 日的预测值和 2018 年 1 月 9 日的预测值(相关预测值)。
其他方法¶
使用 IID 插件¶
尝试在不使用时间序列插件的情况下构建实验有时也非常有用的,即使已有预测用例。时间序列插件很大程度上依赖于数据的滞后,这意味着如果过去行为具有非常大的预测作用,则此插件是最有用。如果时间趋势不强,则在不开启时间序列插件的情况下使用 Driverless AI 就会非常有用。为此,您可以在设置实验时不提供时间列。
请注意:
如果您决定在不开启时间序列的情况下尝试使用模型,请务必提供过时的测试数据集。
Driverless AI 默认执行随机交叉验证,在您有预测用例时,这可能会导致过度拟合。
如果您不提供时间列,将无法告诉 Driverless AI 哪些列在预测时不可用。这意味着您必须提前对数据进行滞后处理。
提前对数据进行滞后处理
在此用例中,您并没有提前知道开盘价、最高价、最低价和收盘价这几个预测因子。如果您想在不开启时间序列插件的情况下使用 Driverless AI,则必须手动对这些变量进行滞后处理,以便它们包含前一日的信息。
原始数据:

针对 Driverless AI IID 进行滞后处理后
您可以通过在 Driverless AI 中使用“数据插件”选项来达到这一目的。为此,您需点击“数据集详细信息”,然后选择“通过插件修改”:
您可以上传修改插件或使用活动代码。如果您选择使用活动代码,您可以查看代码预览并了解代码如何修改数据集:

以下是用于此示例的代码:
X # X is your input dt.Frame
X = X.to_pandas() # convert to pandas
# Calculate lags
lag_cols = ["open", "close", "low", "high"] # columns to lag
time_col = "date"
time_group_cols = ["Name"]
X = X.set_index([time_col] + time_group_cols)
lagged_data = X.loc[:, lag_cols].groupby(level=time_group_cols).shift(1)
# Join lags to original data
X = X.join(lagged_data.rename(columns=lambda x: x +"_lag"))
return X