Driverless AI 中的宽数据集¶
带有众多特征的宽数据集给特征工程和模型构建带来了一些挑战。
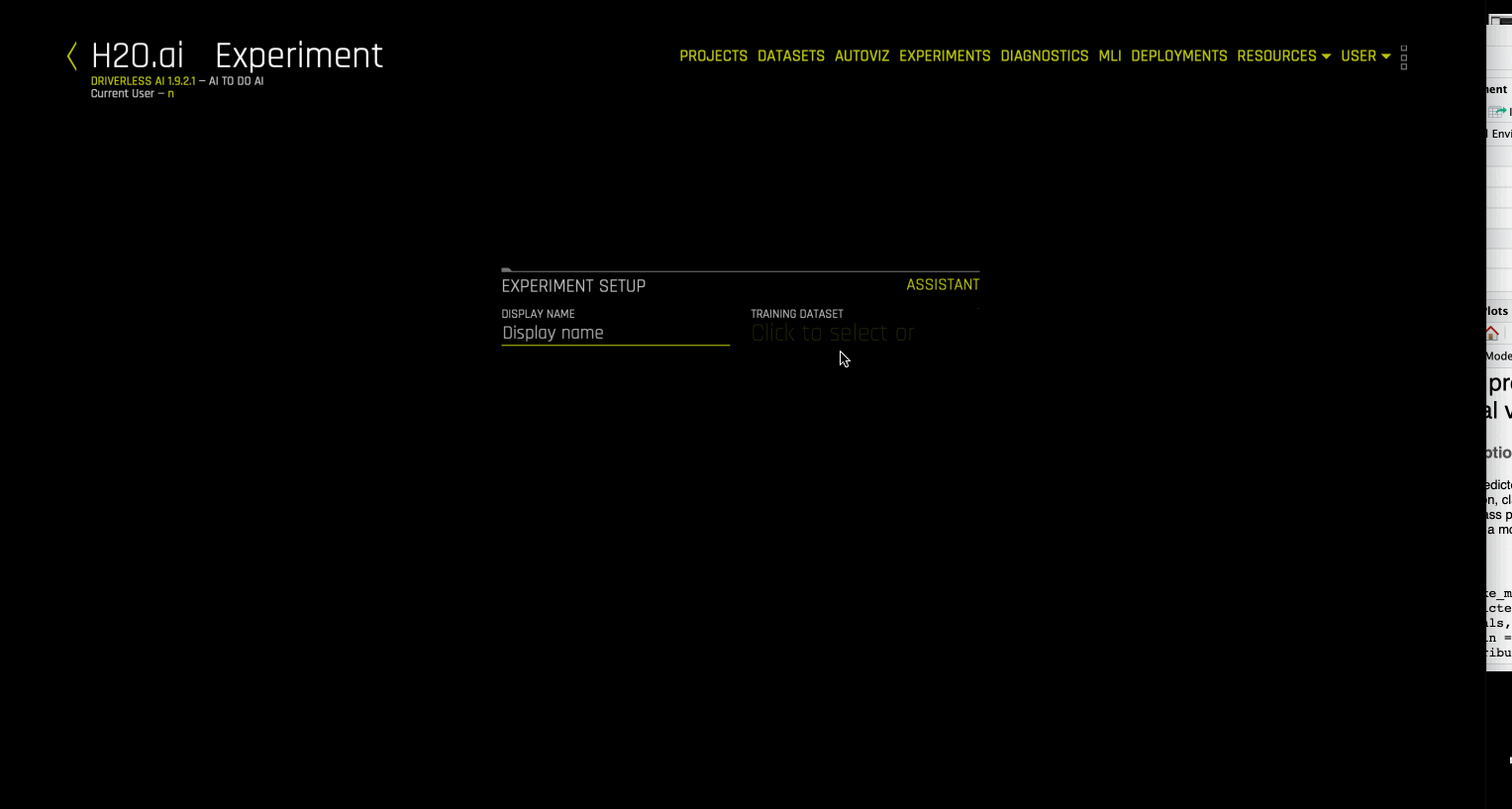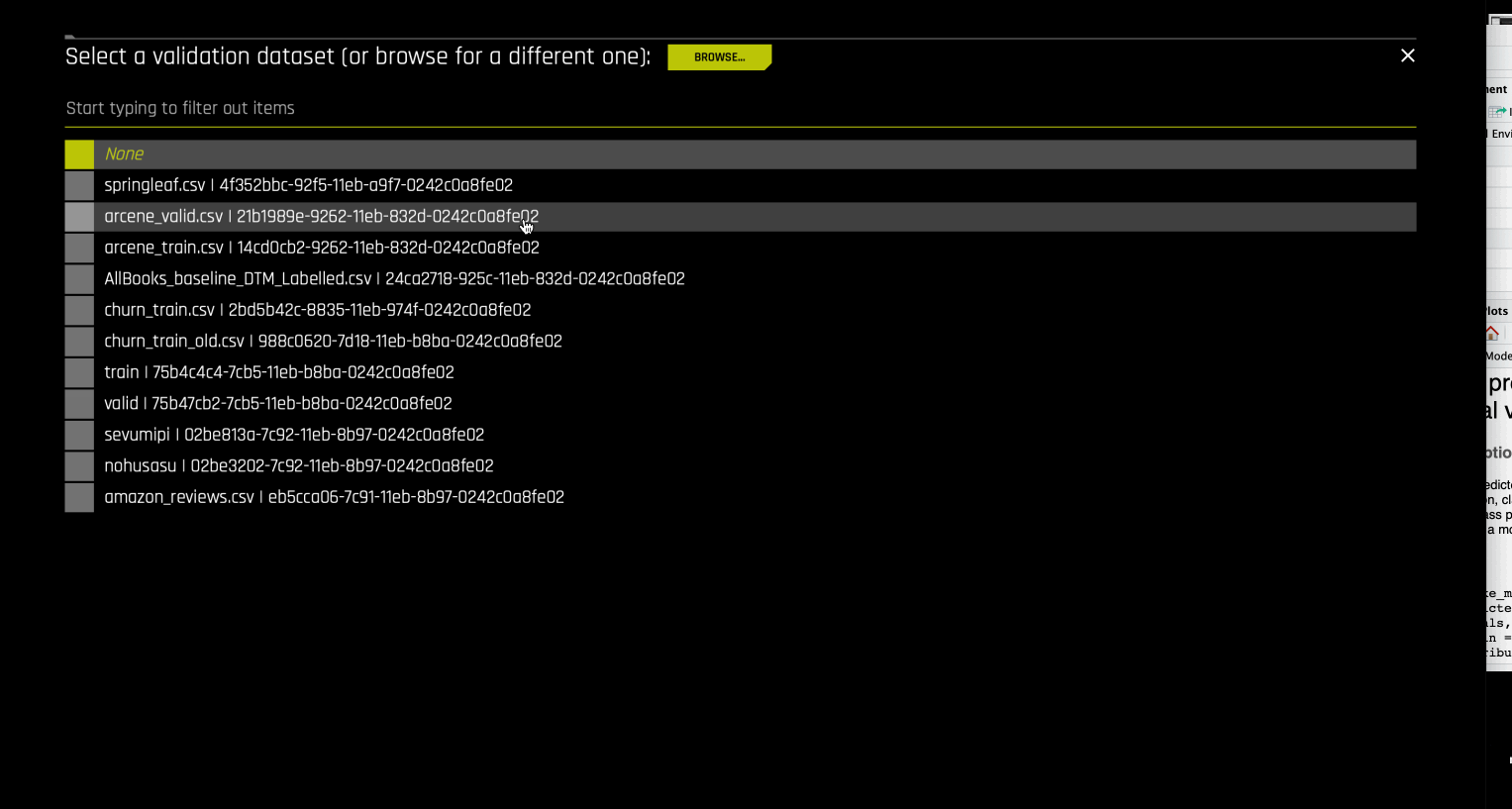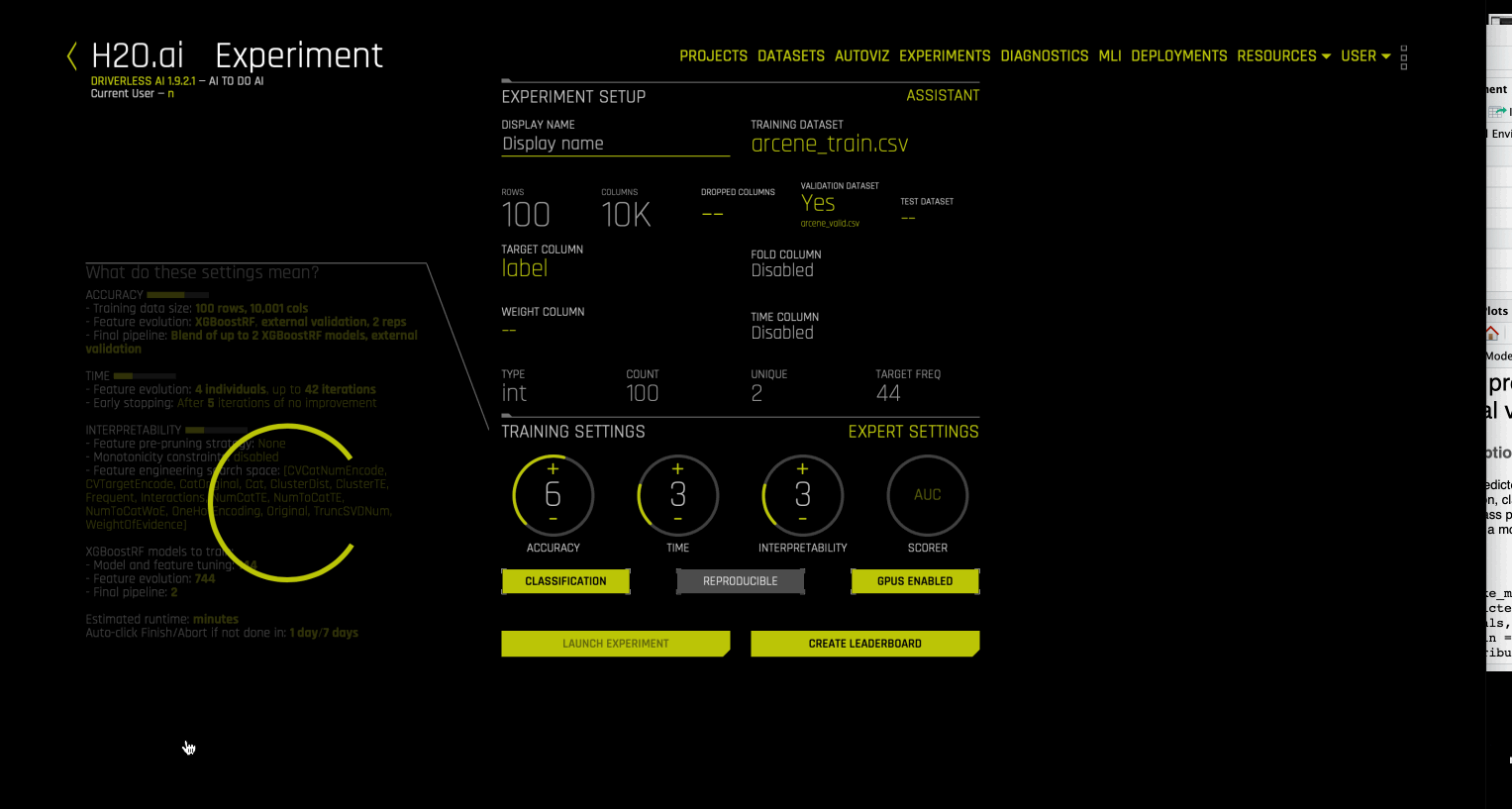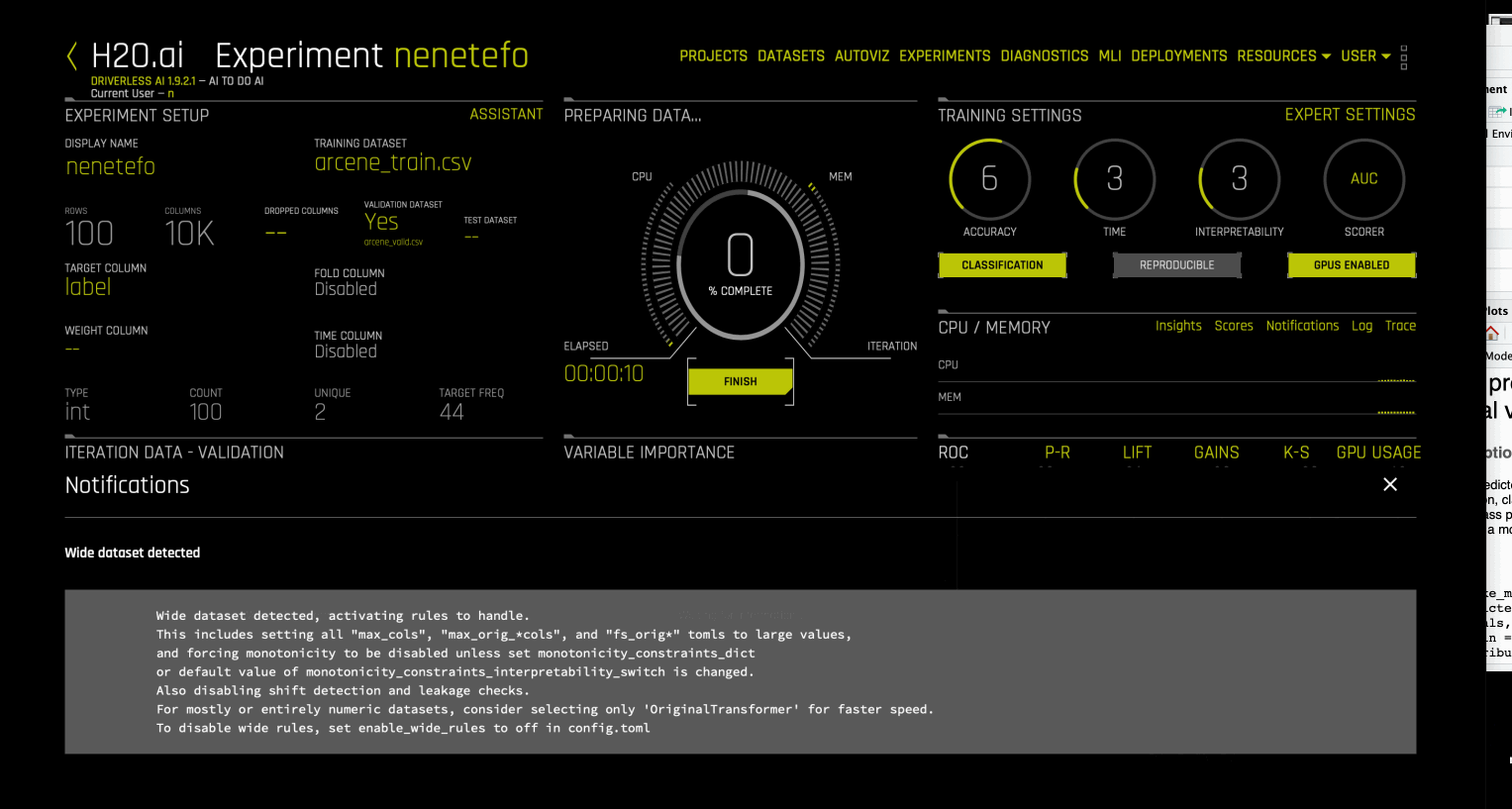
在 Driverless AI 中,列数 > 行数 的数据集被视为宽数据集。当对这些数据集运行实验时,Driverless AI 自动启用 enables wide rules 以提高允许的特征数量上限(可选择将这些特征用于特征演变和选择),以及禁用数据泄露和移位检测等检查、禁用单调性约束、AutoDoc 和管道可视化视图创建等。其还启用了用于建模的 XGBoost 随机森林模型,这样就能帮助避免过度拟合行数较少的宽数据集。请参见 enable_wide_rules.
大型宽数据集能产生可能会耗尽 GPU 内存的大型模型。对于 XGBoost 模型 (GBM、GLM、RF、DART),为了避免此类模型故障,Driverless AI 会(重复)构建子模型以选择特征,进而执行自动特征选择,以 防止发生 GPU OOM 。然后再依据适合 GPU 的重要特征构建最终模型。相关详细信息,请参见 allow_reduce_features_when_failure.
以下示例展示了 在宽数据集上快速运行的模型 的 config.toml 设置。
这会 禁用遗传算法/调优/演化 ,以获得 快速的最终模型。其还使用 (XGBoost) 随机森林,这种算法最适用于避免过度拟合行数较少的宽数据集。在 GUI TOML 专家设置中可以复制/粘贴以下配置设置,以运行此模型。
num_as_cat=false
target_transformer="identity_noclip"
included_models=["XGBoostRFModel"]
included_transformers=["OriginalTransformer"]
fixed_ensemble_level=1
make_mojo_scoring_pipeline="off"
make_pipeline_visualization="off"
n_estimators_list_no_early_stopping=[200]
fixed_num_folds=2
enable_genetic_algorithm="off"
max_max_bin=128
reduce_repeats_when_failure=1
Reduce_repeats_when_failure 能控制重复次数,其默认值为 1。如果其值为 3 或以上,则会花费更长的时间,但能通过找到用于构建最终模型的最佳特征来实现更高的准确度。您也应该对 n_estimators_list_no_early_stopping 进行调优,也就是说,可以从 200 开始,以便在有更多 GPU 时最高效地使用 GPU,这样就能帮助提高模型的普遍适用性。
默认情况下,如果设置为“自动”,会禁用泄露和移位检测。