실험의 체크포인팅, 재실행, 재학습¶
Driverless AI UI의 오른쪽 상단에 Experiments 링크가 있습니다.

링크를 클릭하면 Experiments 페이지가 열립니다. 이 페이지에서 실험의 이름을 변경하거나, 이전 실험을 보거나, 새 실험을 시작하거나, 실험을 재실행하거나 삭제할 수 있습니다.
체크포인팅, 재실행, 재학습¶
Driverless AI에서는 마지막 체크포인트에서 실험을 다시 실행하거나, 기존 실험의 설정으로 새 실험을 실행하거나, 실험의 최종 파이프라인을 재학습할 수 있습니다.
실험 체크포인팅¶
현실 시나리오에서 데이터를 변경할 수 있습니다. 예를 들어, 현재 생산 중인 모델은 백만 개의 레코드를 사용하여 빌드되었습니다. 이후에는 수십만 개의 레코드를 더 받을 수 있습니다. Driverless AI는 새로운 모델을 처음부터 빌드하기보다는, 내장된 H2O.ai Brain을 사용해 이전 모델을 캐싱하고 스마트하게 재사용하여 새 모델의 특성을 생성할 수 있습니다.
실험의 상세 설정 에서 다음 Brain 레벨 중 하나를 구성할 수 있습니다.
-1: 브레인 캐시를 사용하지 않음
0: 브레인 캐시를 사용하지 않지만, 캐시에 쓰기는 수행함
1: 이전 experiment_id가 전달된 경우(예: GUI의 “resume one like this》 실행을 통해) 스마트 체크포인팅
2: 실험이 모든 열 이름, 열 유형, 클래스, 클래스 레이블 및 time series 옵션과 동일하게 일치할 때의 스마트 체크 포인트.(기본값)
3: 레벨 #1과 비슷한 스마트 체크포인팅. 단, 전체 모집단에 해당함. 브레인 모집단의 크기가 충분하지 않은 경우에만 튜닝.
4: 레벨 #2와 비슷한 스마트 체크포인팅. 단, 전체 모집단에 해당함. 브레인 모집단의 크기가 충분하지 않은 경우에만 튜닝.
5: 레벨 #4와 비슷한 스마트 체크포인팅, 단, 최고 점수의 개별 항목을 얻기 위해 전체 모집단의 브레인 캐시(선택된 경우 재개된 실험에서 시작)를 스캔함.
레벨 2(기본 구성)를 선택하면 적절한 경우 레벨 1도 수행됩니다.
스마트 체크포인팅을 활용하려면 새로운 데이터가 다음 조건을 충족해야 합니다.
이전 실험과 데이터 열 이름이 동일해야 합니다.
이전 실험과 각 열의 데이터 유형이 동일해야 합니다(예를 들어 열이 모두 int이고 문자열 행이 하나인 경우, 일치하지 않음).
이전 실험과 대상이 동일해야 합니다.
이전 실험과 대상 클래스(분류인 경우)가 동일해야 합니다.
time series인 경우, 간격 및 gap에 대한 모든 선택 사항이 동일해야 합니다.
위의 조건이 충족하면 다음 작업을 수행할 수 있습니다.
동일 유형의 실험을 시작하고 더 오래 재실행할 수 있습니다.
더 작거나 더 큰 데이터 세트를 사용할 수 있습니다(행의 수가 더 작거나 더 큰 데이터).
데이터 행을 변경하고 새로운 accuracy, 시간 = 1 및 해석력으로 실험을 시작하여 최종 앙상블 리핏(re-fit)을 효과적으로 수행할 수 있습니다. 앙상블에 대한 실험 미리보기를 확인할 수 있습니다.
취소, 중단 또는 완료된 실험을 다시 시작/재개할 수 있습니다.
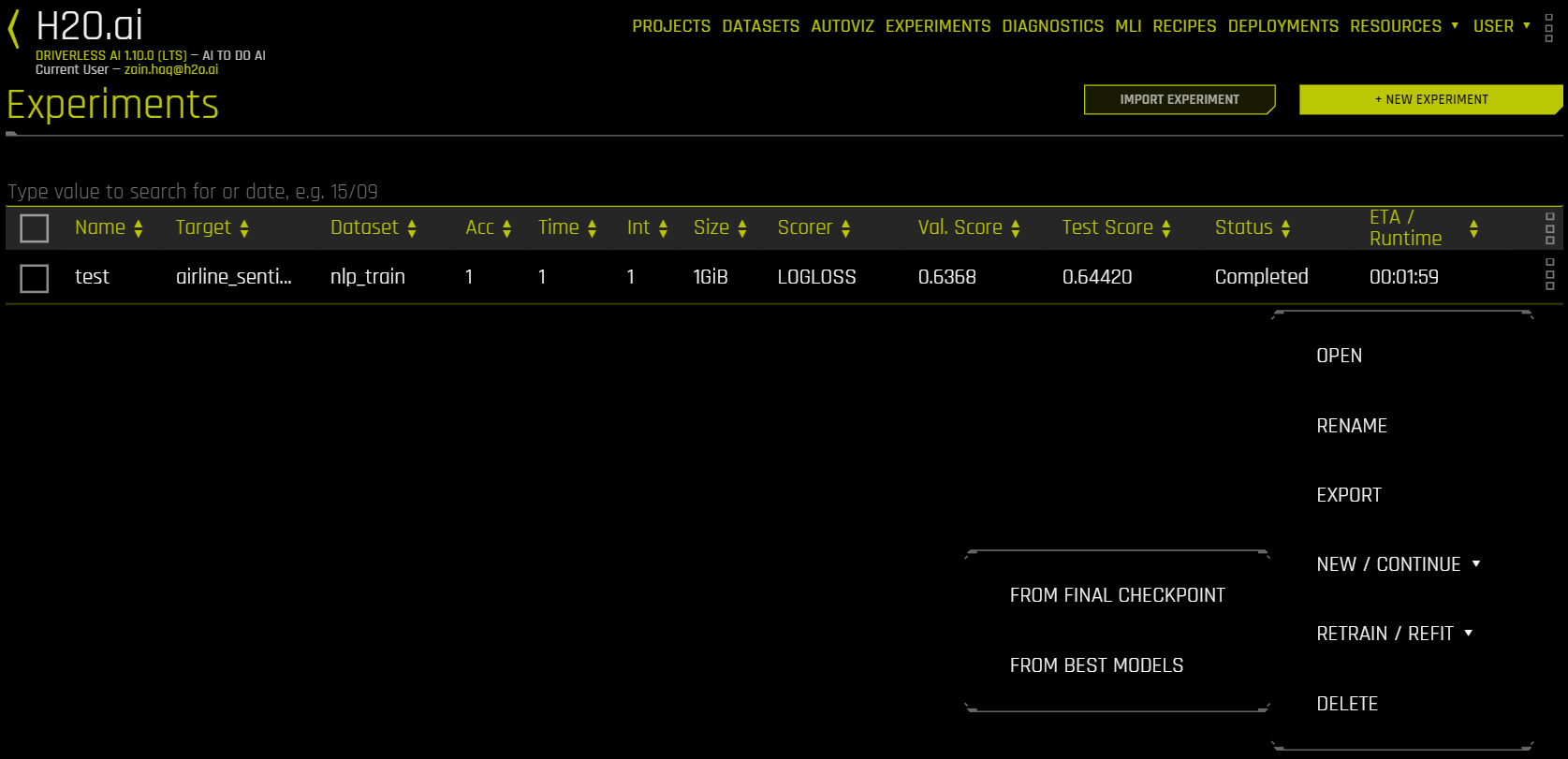
기존 실험에 스마트 체크포인팅을 실행하려면, 다시 실행하려는 실험을 오른쪽 클릭한 다음 Restart from Last Checkpoint(마지막 체크포인트에서 다시 시작) 를 선택합니다. 실험 설정 페이지가 열립니다. 새로운 데이터 세트를 지정합니다. 필요하면 실험 설정을 변경할 수도 있으나, 대상 열이 반드시 동일해야 합니다. Launch Experiment(실험 시작) 를 클릭하여 마지막 체크포인트에서 실험을 재개하고 새 실험을 빌드합니다.
스마트 체크포인팅은 이전 모델을 튜닝 중에 사용되는 다른 모델로 추가하면 계속됩니다. 이전 모델이 더 나은 경우(더 많이 반복하여 실행한 경우 더 나을 가능성이 높음), 특성 진화 반복 및 최종 앙상블 중에 스마트 체크포인트 모델이 사용됩니다.
Notes:
Driverless AI는 정확한 지속성을 보장하지 않으며, 마지막 포인트부터의 스마트 지속성만 보장합니다.
H2O.ai Brain 메타 모델 파일이 저장되는 디렉터리는 tmp/H2O.ai_brain 입니다. 또한, 기본 최대 브레인 크기는 20GB입니다. 디렉터리와 최대 크기 모두 config.toml 파일에서 변경할 수 있습니다.
실험 재실행¶
기존 실험의 설정을 사용하여 새 실험을 실행하려면, 새 실험의 기초로 사용할 실험을 오른쪽 클릭한 다음 New Experiment with Same Settings(동일 설정의 새 실험) 을 선택합니다. 실험 설정 페이지가 열립니다. 이 페이지에서 원래 설정을 사용하여 실험을 다시 실행하거나 새 데이터를 사용하도록 지정하거나 다른 실험 설정을 지정할 수 있습니다. Launch Experiment(실험 시작) 을 클릭하여 동일한 옵션으로 새 실험을 만듭니다.
재학습/리핏¶
실험의 최종 파이프라인을 다시 학습하려면 새 실험의 기초로 사용할 실험 옆의 사각 아이콘 그룹을 클릭하고 Retrain / Refit 을 클릭한 다음 From Final Checkpoint 을 선택합니다. Time이 0으로 설정된 것을 제외하고는 원래 실험과 동일하게 설정된 실험 설정 페이지가 열립니다.
Note: 실험의 최종 파이프라인을 다시 학습할 때 Driverless AI는 실험의 최종 모델도 리핏합니다. 여기에는 새로운 특성 추가, 이전에 사용된 특성 제외, 하이퍼파라미터 검색 공간의 변경 또는 기존 모델 아키텍처에 대한 새 매개변수 찾기 등이 포함될 수 있습니다.
새로운 기능을 추가하지 않고 최종 파이프라인을 다시 학습하려면 From Best Models 옵션을 선택하십시오. 이 옵션은 다음 config.toml 옵션을 재정의합니다.
refit_same_best_individual=True
brain_add_features_for_new_columns=False
feature_brain_reset_score="off"
force_model_restart_to_defaults=False
자세한 내용은 config.toml 파일의 feature_brain_level 설정을 참조하십시오.
참고
이에 상응하는 재학습/리핏 옵션에 대한 Python 클라이언트 호출 정보는 다음 목록을 참조하십시오.
동일한 설정으로 새로 시작/계속:
retrain(...)
마지막 체크포인트에서 새로 시작/계속:
retrain(..., use_smart_checkpoint=True)
최종 체크포인트에서 재학습/리핏
retrain(..., final_pipeline_only=True)
최적의 모델에서 재학습/리핏
retrain( ..., final_pipeline_only=True, brain_add_features_for_new_columns = False, refit_same_best_individual = True, feature_brain_reset_score = 'off', force_model_restart_to_defaults = False )
《Pausing》 실험¶
실험을 《pausing》하는 요령은 다음과 같습니다.
실험을 중단합니다.
실험 페이지에서 중단된 실험에 대해 Restart from Last Checkpoint 을 선택합니다.
상세 설정 페이지에서 ensemble level for the final pipeline 옵션에 0을 지정합니다.
실험 삭제¶
실험을 삭제하려면 삭제할 실험을 오른쪽 클릭한 다음 Delete 를 선택합니다. 삭제하려는지 질문하는 확인 메시지가 표시됩니다. OK 를 클릭하여 실험을 삭제하거나 Cancel 을 클릭하여 삭제하지 않고 실험 페이지로 돌아갑니다.