실험 설정¶
본 섹션은 실험 실행 시 사용 가능한 설정에 관해 설명합니다.
표시 이름¶
선택 사항: 새로운 실험의 표시 이름을 지정하십시오. 이름 지정에는 문자 또는 길이에 대한 제한이 없습니다. 해당 필드를 비워두면 Driverless AI가 자동으로 실험 이름을 생성합니다.
삭제된 열¶
삭제된 열은 실험에서 예측 변수로 사용되지 않는 열입니다. Driverless AI는 많은 수의 고유값을 포함하는 ID 열 및 열들을 자동으로 삭제합니다(config.toml 파일의 max_relative_cardinality 또는 상세 설정에서 *Max. allowed fraction of uniques for integer and categorical cols 이상).
검증 데이터 세트¶
유효성 검사 데이터 세트는 모델링 파이프라인을 튜닝에 사용됩니다. 제공되는 경우, 전체 학습 데이터가 학습에 사용되고 모델링 파이프라인의 검증 데이터 세트는 해당 유효성 검사 데이터 세트로만 수행됩니다. 유효성 검사 데이터 세트를 포함하지 않으면 Driverless AI가 I.I.D. 실험에 대해 K-폴드 교차 검증을 수행하고 시계열 실험에 대한 다중 롤링 윈도우 분할 검증을 수행합니다. 따라서 단일 데이터 세트에 대해서만 검증을 실시하므로 일반적으로 유효성 검사 데이터 세트를 포함하지 않는 것을 권장합니다. 시계열 실험은 유효성 검사 데이터 세트와 함께 사용하는 것이 불가합니다. 유효성 검사 데이터 세트를 포함하면 시간 열을 선택하는 기능이 비활성화되고 그 반대의 경우도 동일합니다.
이 데이터 세트는 학습 데이터 세트와 동일한 수의 열(및 열 유형)을 가지고 있어야 합니다. 또한 제공되는 경우, 검증 세트가 샘플링되지 않으므로 accuracy=1(학습 크기 감소)인 경우에도 메모리 사용량이 커질 수 있습니다.
테스트 데이터 세트¶
테스트 데이터 세트는 모델링 파이프라인을 테스트하고 테스트 예측을 만드는 데 사용합니다. 모델링 파이프라인 학습 도중에는 테스트 세트를 사용하지 않습니다.(테스트 세트의 제공 여부에 상관없이 결과는 같습니다.) 테스트 데이터 세트가 제공되면 실험 종료 시 테스트 세트 예측의 사용이 가능합니다.
가중치 열¶
선택 사항: 해당되는 경우 관찰 가중치 (일명 샘플 또는 행 가중치)를 나타내는 열입니다. 해당 열의 값은 0보다 커야 합니다. 가중치가 더 높은 행일수록 중요도가 높습니다. 가중치는 가중 손실 함수를 통해 모델 학습에 영향을 미치고 가중 메트릭을 통해 모델 점수에 영향을 미칩니다. 가중치 열은 테스트 세트의 예측 시 사용되지는 않지만 가중치 열(지정된 경우)은 테스트 점수의 계산 시 사용됩니다.
Note: 가중치 열은 모델링의 특성으로 사용되지 않습니다.
폴드 열¶
옵션: 폴드 열에 동일한 값이 있는 행은 학습, 검증 또는 교차 검증 데이터 세트에서 함께 유지되어야 하는 그룹을 나타냅니다. 이렇게 하면 데이터 누출을 방지하고 자연스럽게 그룹화되며 i.i.d. (동일하고 독립적으로 분포)가 아닌 데이터에 대한 일반화를 개선할 수 있습니다. 이 열은 정수 또는 범주형 변수여야 하며 검증 세트가 사용되거나 시간 열이 지정된 경우 지정할 수 없습니다.
Driverless AI는 기본적으로 데이터 세트를 i.i.d라고 가정하며, 회귀 분석 또는 분류를 위한 대상 변수의 활층을 위해 무작위로 검증 데이터 세트를 생성합니다.
폴드 열은 동일한 폴드 값을 가진 모든 행이 동일한 데이터 세트에 있을 수 있도록 학습 및 검증 데이터 세트를 만드는 데 사용됩니다. 이로써 데이터 유출의 방지 및 일반화의 개선이 가능합니다. 예를 들어, 폐렴 데이터 세트에 관한 데이터 확인 시, person_id 는 훌륭한 폴드 열입니다. 이는 데이터가 한 사람당 여러 개의 진단 스냅 샷을 포함할 수 있으며, 동일인의 특성이 학습 또는 검증 프레임에만 표시되고 데이터 유출의 방지를 위해 두 곳 모두에 표시되지 않도록 하기 위해서입니다.
이 열은 정수 또는 범주형의 변수이어야 하고, 검증 세트가 사용되거나 시간 열이 지정된 경우에는 지정이 불가합니다.
Note: 폴드 열은 모델링의 특성으로 사용되지 않습니다.
시간 열¶
선택 사항: 가능한 경우, 시간 순서 (관측에 대한 타임 스탬프)를 제공하는 열을 지정하십시오. 이를 통해 대상 값이 순서 (time series 그룹당)와 관련하여 자동으로 연관되는 문제에 대한 모델 성능 및 모델 검증 accuracy를 향상할 수 있습니다.
해당 열의 값은 《2017-11-29 00:30:35》, 《2017/11/29》 또는 정수 값과 같이 pandas.to_datetime()에서 인식할 수 있는 날짜 및 시간의 형식이어야합니다. [AUTO]를 선택하면, 모든 문자열이 잠재적인 날짜/날짜 및 시간의 내용에 대해 테스트 되고 잠재적인 시간 열로 간주됩니다. 시간 열이 발견되면, 변수 가공 및 모델 검증은 시간의 인과 관계를 존중합니다. [OFF] 선택 시, 모델링에 시간 순서가 사용되지 않으며 데이터가 무작위로 뒤섞일 수 있습니다(잠재적인 일시적인 인과 관계는 무시됨).
데이터가 날짜 열을 포함하고 있는 경우, 대부분의 시간 열에 [AUTO]를 지정하는 것만으로도 충분합니다. 그러나 특정 날짜 열을 선택하면 Driverless AI가 추가적인 사이드 메뉴를 제공합니다. 해당 사이드 메뉴로부터 시간 그룹 열을 지정 또는 [Auto]를 지정하여 Driverless AI가 최적의 시간 그룹 열을 결정하도록 하는 것이 가능합니다. 또한 예측 시간에 사용이 불가능한 열(자세한 내용은 예측 시 사용할 수 없는 열에 대한 추가 정보 참조), Forecast Horizon(Driverless AI에 의해 확인된 시간 단위) 및 학습과 테스트 기간 사이의 Gap 지정도 가능합니다.
Driverless AI의 time series 실험에 대한 자세한 내용 및 time series 예제를 확인하려면 Driverless AI의 Time Series 를 참조하십시오.

Notes:
time series 실험 빌드 시, MLI에 가공된 특성이 사용됩니다. 이는 병합된 time series 기능이 원시 time series 기능과 비교해서 MLI에 더 유용한 기능이기 때문입니다.
폴드 열이 지정된 경우 시간 열의 지정이 불가합니다. 이것은 폴드 열 및 시간 열이 모두 학습 데이터 세트를 학습 및 검증으로 분할하는 데만 사용되기 때문입니다. 따라서 시간별로 분할한 후에는 폴드 열로 분할하는 것이 불가합니다. 시간 열이 지정된 경우 시간 그룹 열은 time series의 폴드 열 역할을 합니다.
검증 데이터 세트의 사용 시, 시간 열의 지정이 불가합니다.
예측 시간에 사용 불가한 것으로 지정된 열에는 이것에 대해(또는 함께) 생성된 지연 관련 특성만 가지고 있습니다.
예측 시간에 사용할 수 없는 열에는 지연 관련 특성만 생성(또는 포함)되기 때문에, 해당 옵션은 time_series_recipe 가 활성화된 경우에만 사용됩니다.
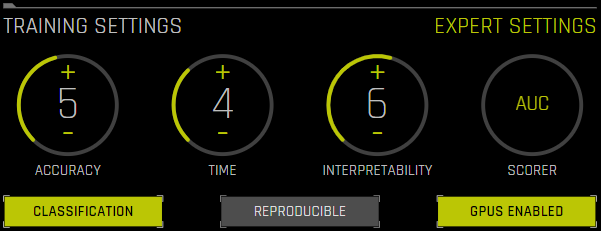
accuracy, 시간 및 해석 가능성 노브¶
실험 미리보기는 특정 실험에 대한 정확도, 시간 및 해석 가능성 설정의 의미에 관해 설명합니다. 이 미리보기는 실험의 설정이 변경되면 자동으로 업데이트됩니다(노브 포함).
Accuracy 노브는 상대 정확도를 나타냅니다. 값이 높으면 모델 성능의 신뢰도가 높아집니다. 이는 일반적으로 더 큰 데이터(더 적은 샘플링), 더 많은 모델링 작업(더 많은 튜닝, 더 높은 정확도 설정), 더 통계적인 계산(교차 검증, 부트스트랩)을 통해 달성됩니다. 최종 모델이 항상 낫다는 의미는 아니지만 일반적으로 최종 추정치가 더 정확함을 의미합니다. 확실하지 않은 경우 더 높은 정확도 설정으로 실험 결과의 신뢰도를 향상시키십시오.
시간 노브는 상대 시간 허용 오차를 나타냅니다. 값이 높으면 일반적으로 실행 시간이 길어집니다. 실험 점수의 수렴에 대한 기다림을 나타냅니다. 값이 크면 더 나은 모델을 얻을 확률이 높아집니다. 시간이 너무 오래 걸리는 경우 〈Finish〉 버튼만 클릭하면 수렴을 달성한 것과 마찬가지로 실험을 종료합니다.
해석 가능성 노브는 상대 해석 가능성을 나타냅니다. 값이 높으면 복잡하지 않은 변수 가공(적은 기능, 단순한 기능)으로 더 해석 가능한 모델(예: 선형 모델, 의사 결정 트리, 단일 모델)을 선호합니다. 값이 낮으면 더 복잡한 모델(예: 신경망, gbms, 앙상블)과 더 복잡한 기능 파이프라인(더 많은 기능, 높은 수준의 상호 작용 기능)을 생성합니다.
참고
Features to Force In 상세 설정을 사용하여 정확도, 시간 및 해석 가능성 수준과 관계없이 실험에 적용할 개별 기능을 수동으로 선택할 수 있습니다.
기능이 삭제되기 전에 허용되는 가장 낮은 변수의 중요성을 조정하려면 Lowest Allowed Variable Importance at Interpretability 10 을 사용하십시오.
Accuracy, Time, and Interpretability Knobs¶

Experiment Preview¶
Accuracy¶
accuracy가 높아질수록 Driverless AI는 진화 및 앙상블의 수행 방법을 점진적으로 조정합니다. 낮은 accuracy에서 Driverless AI는 특성 및 모델이 다양하지만 모두 서로 균등하게 경쟁합니다. accuracy가 높을수록 각각의 독립 메인 모델은 독립적으로 진화하고, 다른 메인 모델에 대한 앙상블로서 최종 앙상블의 일부로 포함됩니다. 더 높은 accuracy에서 Driverless AI는 독립적으로 진화하는 대상 인코딩 on 및 off와 같은 앙상블 특성 유형을 진화시킵니다. 마지막으로, 제일 높은 accuracy에서 Driverless AI는 모델과 특성 추적을 모두 수행하고 이러한 모든 변형을 통합합니다.
이 값을 변경하면 특성 진화 및 최종 파이프라인에 영향을 줍니다.
Note: accuracy 5 이상에 대한 학습과 테스트 사이의 분포 변화 확인.
Training data size: 훈련 데이터의 행과 열 수를 표시합니다.
Feature evolution: 이것은 실험 생성에 사용된 알고리즘을 나타냅니다. 검증 세트 없이 테스트 세트가 제공되면 Driverless AI는 실험 중에 1/3 검증 분할을 수행합니다. 검증 세트가 제공되면 실험은 외부 검증을 수행합니다.
Final pipeline: 이것은 최종 파이프라인에서 사용되는 모델 수 및 검증 방법을 나타냅니다. 앙상블 모델링의 경우, 모델 결합 방법에 대한 정보도 여기에 표시됩니다.
시간¶
이것은 실험 완료에 대한 상대 시간을 지정합니다(즉, 높은 설정일수록 더 오래 걸립니다).
Feature Brain Level: 실험에 대한 특성 브레인 수준을 표시합니다. 더 자세한 내용은 feature_brain_level 을 참조하십시오.
Feature evolution: 해당 실험에서 실행될 개체 수 및 최대 반복 횟수를 표시합니다.
Early stopping: 해당 실험이 정해진 반복 횟수 동안 점수를 높이지 못하면 조기 중지가 실행됩니다.
해석 가능성¶
본 실험에 대한 상대적 해석 가능성을 지정하십시오. 값이 클수록 해석 가능성이 높은 모델이 선호됩니다. 해석 가능성 수준을 변경하면 특성 사전가지치기 전략, monotonicity constraints 및 변수 가공 검색 영역에 영향을 줍니다.
Feature pre-pruning strategy: 이것은 특성 선택 전략을 나타냅니다(모델 점수를 명확하게 개선하지 않는 특성을 제거하기 위함). 만약 전략 = “Permutation Importance FS》, 해석 가능성 >=6인 경우; 여기에 해당하지 않으면 전략은 없습니다.
Monotonicity constraints: Monotonicity Constraints 이 활성화 된 경우, 해당 모델은 예측 변수 및 대상 변수 간의 데이터의 단조성 및 단조관계에 관한 지식을 충족합니다. 예를 들어, 주택 가격 예측에서 주택 가격은 부지의 크기 및 방의 수에 따라 상승해야하며, 지역의 범죄율에 따라 하락해야 합니다. 활성화되면 Driverless AI가 자동으로 단조성의 존재 유뮤를 확인하고, 이를 모델링 파이프라인에서 적용합니다. 상관관계에 따라 Driverless AI는 양수 또는 음수를 지정하거나 또는 monotonicity constraints를 할당하지 않습니다. 절대 상관관계가 0.1보다 클 경우에는 단조성이 적용됩니다. 기타 모든 예측 변수에는 단 조성이 적용되지 않습니다. 더 자세한 내용은 Monotonicity Constraints 를 참조하십시오.
Note: monotonicity constraints는 XGBoost GBM, XGBoost Dart, LightGBM 및 Decision Tree 모델에서 사용됩니다.
Feature engineering search space: 이것은 실험 중에 사용될 transformer를 나타냅니다.
[…] 학습 모델¶
나열된 모델의 경우:
Model and feature tuning: 튜닝 모집단 크기를 곱한 검증 분할의 수를 나타냅니다.
Feature evolution: 가공된 특성 평가를 위해 학습된 모델의 수를 나타냅니다.
Final pipeline: 최종 모델의 수를 나타냅니다.
Per-model hyperparameter optimization trials:
evolution - 튜닝 모델의 하이퍼파라미터 최적화를 위해 수행된 트라이얼의 수를 나타냅니다.
final - 튜닝 모델의 하이퍼파라미터 최적화를 위해 수행된 최종 수를 나타냅니다.
분류/회귀 분석 버튼¶
Driverless AI는 반응 열을 기반으로 문제 유형을 자동으로 결정합니다. 권장 사항은 아니지만, 해당 버튼을 클릭하여 이 설정을 재정의가 가능합니다.
재현¶
Reproducible 버튼을 사용하면 무작위 시드를 사용하여 실험을 구축하고 재현 가능한 결과를 얻을 수 있습니다. 해당 옵션을 사용하지 않으면(기본값) 실행들 사이의 결과가 달라지기 때문에 실험 결과 사이의 분산을 알 수 있습니다.
해당 옵션 활성화 시 다음 사항에 유의하십시오.
실험은 동일한 하드웨어(동일한 수 및 유형의 GPU / CPU, 동일한 아키텍처(예: Linux 또는 PPC 등)에서 실행될 때에만 재현이 가능합니다. 예를 들어 어떤 GPU 시스템에서 실험을 실시한 후, CPU 전용 시스템 또는 GPU 유형이 다른 시스템에서 결과를 재현하려고 시도하면 결과가 달라집니다.
해당 옵션은 OS 및 환경 아키텍처에 따라 여러 수준의 재현성을 보장하는 reproducibility_level 상세 설정 옵션과 함께 사용되어야 합니다. Reproducibility 활성 시, 기본적으로
reproducibility_level=1이 된다는 점을 기억하시기 바랍니다.여러 개의 코어를 가진 TensorFlow를 사용하여 실행된 실험은 재현할 수 없습니다.
LightGBM은 64 비트 플로트로 더 재현이 가능하고, Driverless AI는 LightGBM에 대해서 64 비트 플로트로 전환합니다(자세한 내용은 https://lightgbm.readthedocs.io/en/latest/Parameters.html#gpu_use_dp 를 참조하십시오).
해당 옵션을 활성화하면 모든 특성 브레인 상세 설정 옵션이 자동으로 비활성화됩니다. 여기에는 특히 다음이 해당됩니다.
GPU 활성화¶
GPUs Enabled 버튼을 클릭하여 GPU를 활성화/비활성화합니다. 해당 옵션은 CPU 전용 시스템에서 무시됩니다.