Wide Datasets in Driverless AI
A wide dataset with many features comes with its own challenges for feature engineering and model building.
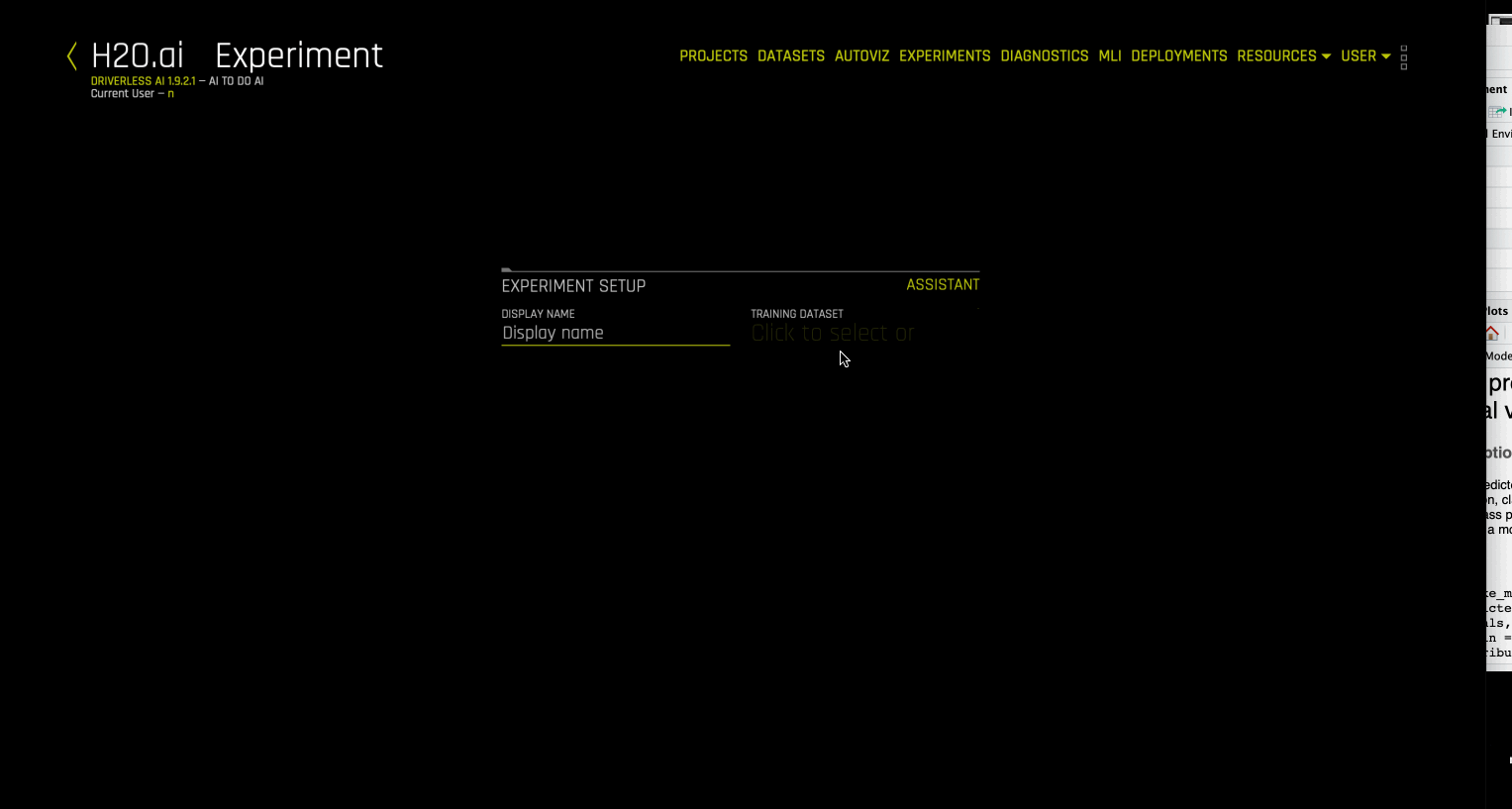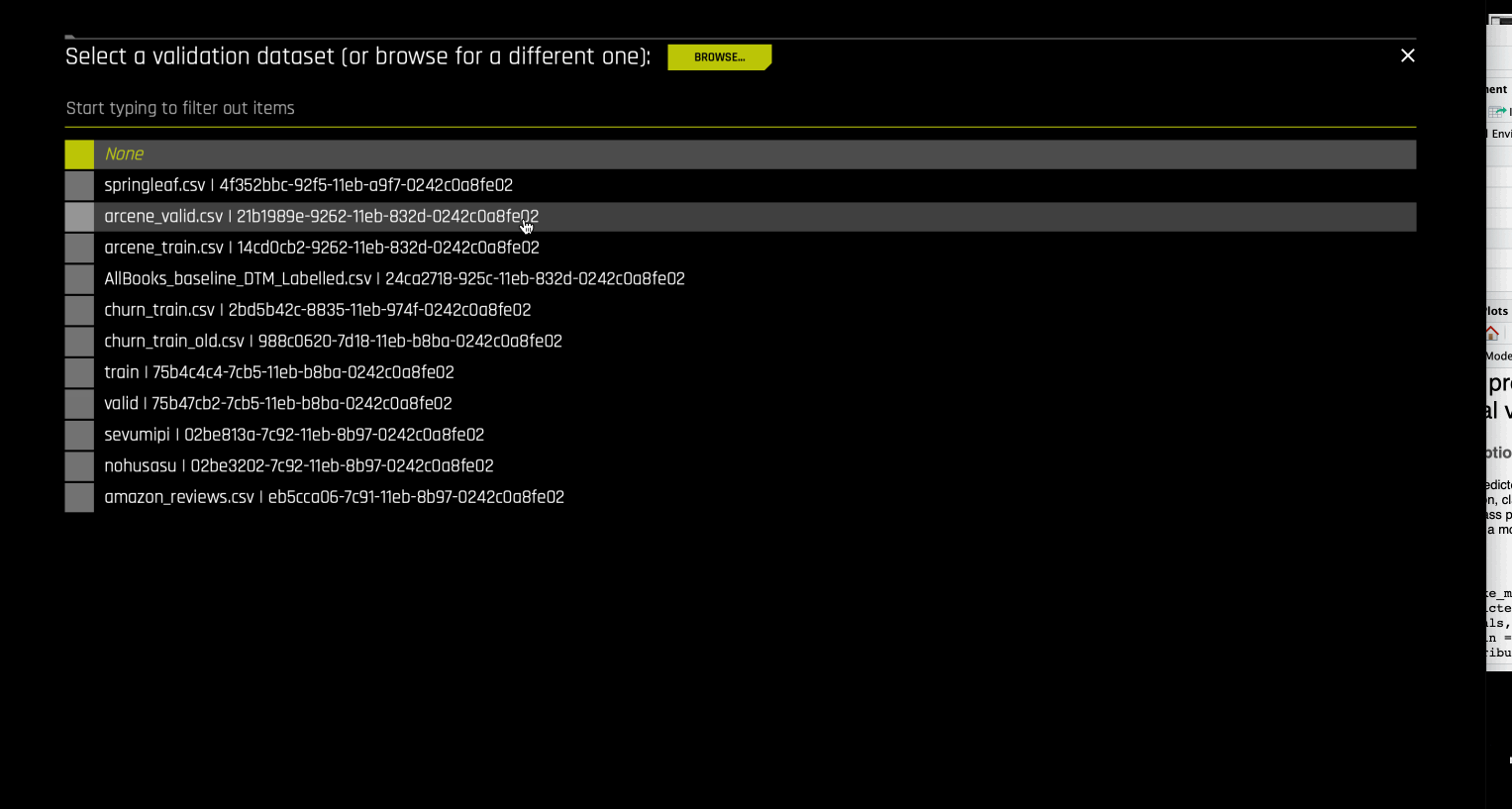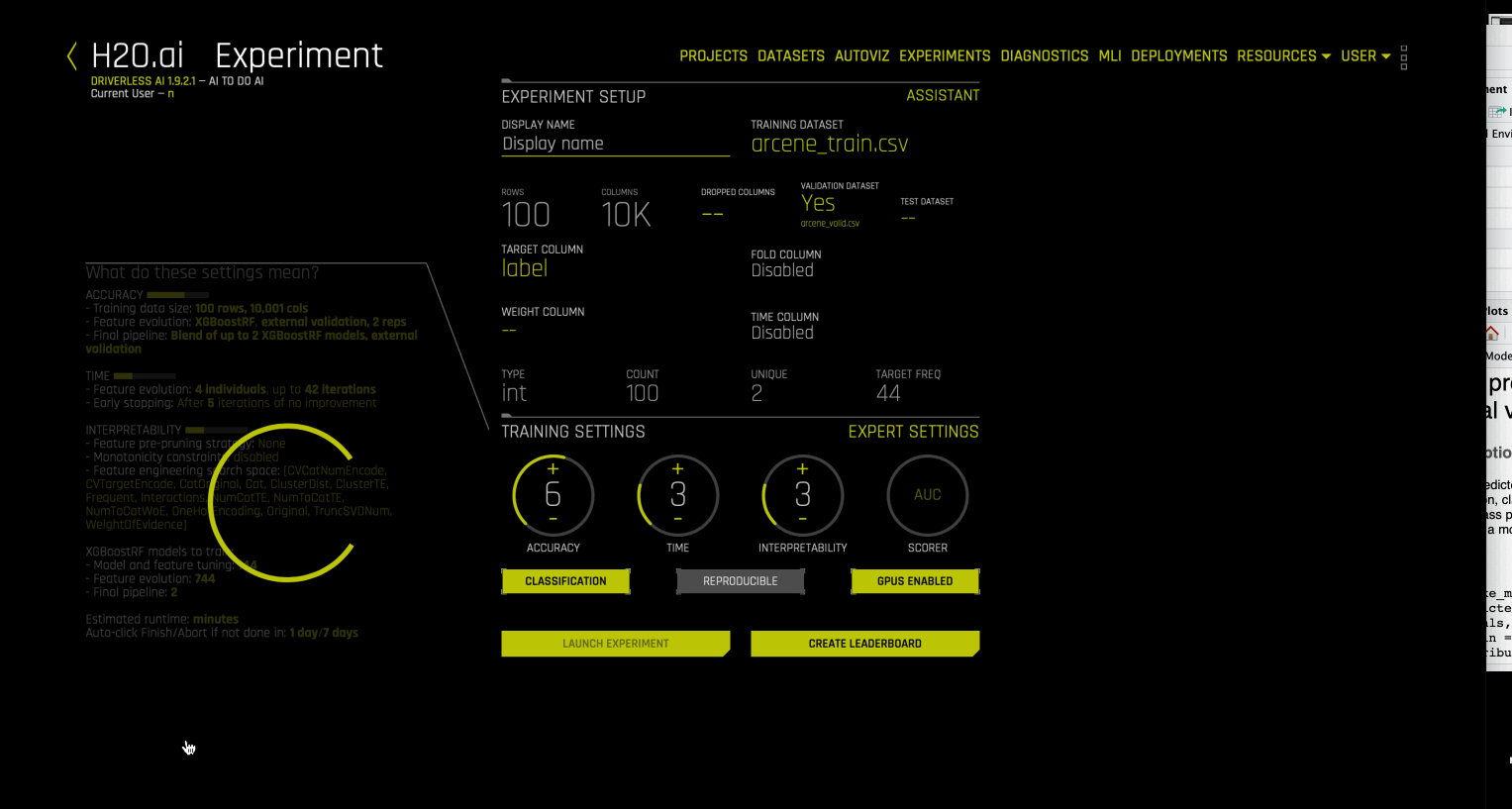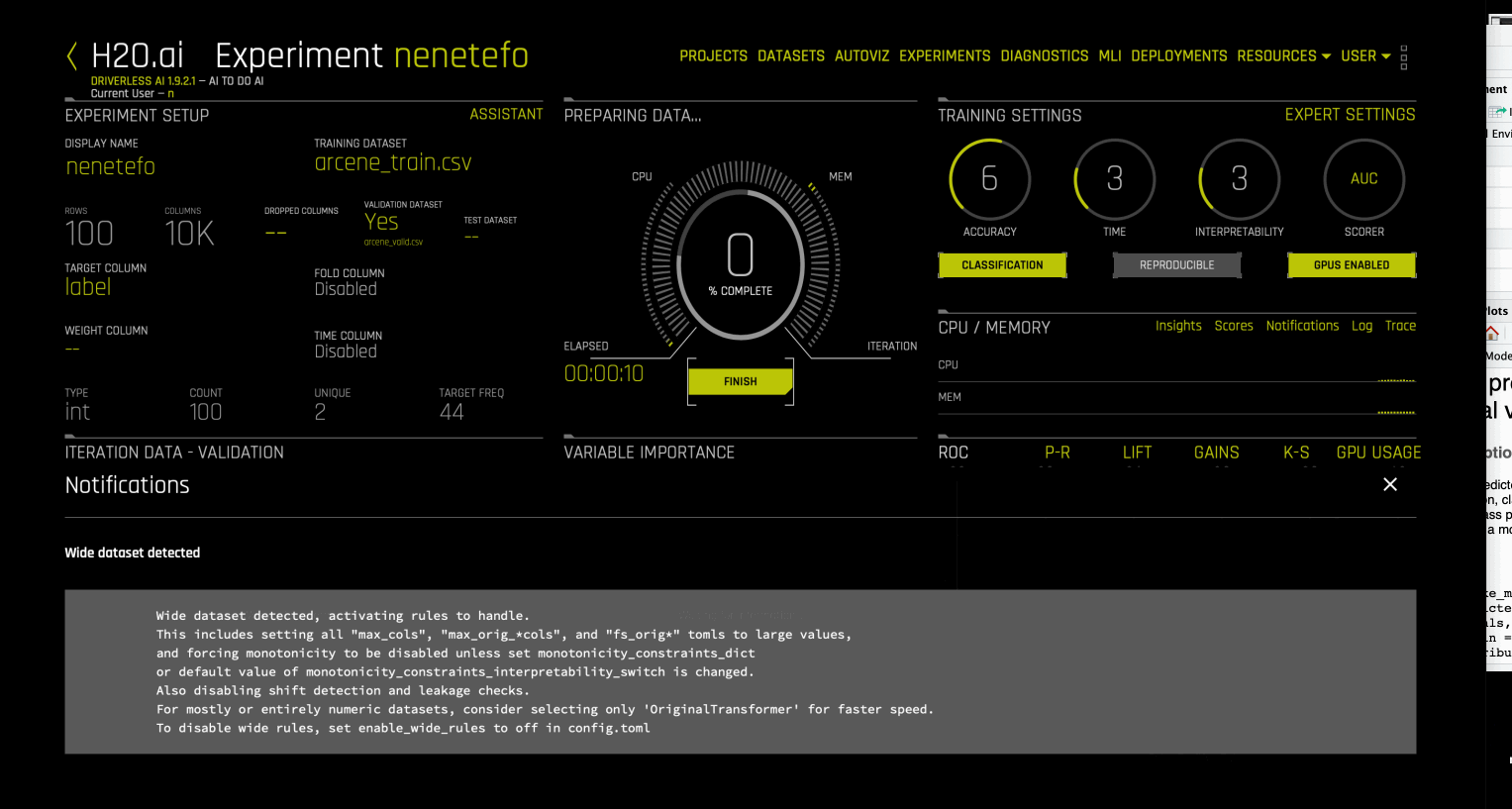
In Driverless AI, datasets where number of columns > number of rows are considered as wide. When running experiments on such datasets, Driverless AI automatically enables wide rules that extend the limits on the maximum number of allowed features (that can be selected for feature evolution and selection) to a large number, disables certain checks like data leakage and shift detection, monotonicity constraints, AutoDoc and pipeline visualization creation. It also enables XGBoost random forest model for modeling, which helps to avoid overfitting on wide datasets with few rows. See enable_wide_rules.
A big-wide dataset can result in large models that can run out of memory on GPUs. To avoid such model failures for XGBoost models (GBM, GLM, RF, DART), Driverless AI provides protection against GPU OOM by performing automatic feature selection by building sub-models (with repeats) to select features. A final model is then built on the important features that fit on the GPU. See allow_reduce_features_when_failure for details.
Here is an example of config.toml settings for a quick model run on a wide dataset.
This disables genetic algorithm/tuning/evolution to get a quick final model. It also uses (XGBoost) random forest that is best to avoid overfit on wide data with few rows. The following config settings can be copy/pasted in the expert settings GUI TOML to run this model.
num_as_cat=false
target_transformer="identity_noclip"
included_models=["XGBoostRFModel"]
included_transformers=["OriginalTransformer"]
fixed_ensemble_level=1
make_mojo_scoring_pipeline="off"
make_pipeline_visualization="off"
n_estimators_list_no_early_stopping=[200]
fixed_num_folds=2
enable_genetic_algorithm="off"
max_max_bin=128
reduce_repeats_when_failure=1
The reduce_repeats_when_failure controls the repeats, 1 is default. A value of 3 or more can take longer but can give more accuracy by finding the best features to build a final model on. One should also tune n_estimators_list_no_early_stopping. i.e. can start with 200, but try more to see if makes model more accurate. Also might be good to change fixed_num_folds to the number of GPUs, to most efficiently use the GPUs when have more GPUs, which will then help to improve the generalizability of the model.
By default, leakage and shift detection are disabled if set to auto.