Imbalanced modeling in Driverless AI
This page describes Driverless AI’s imbalanced modeling capabilities.
Overview
Driverless AI offers imbalanced algorithms for use cases where there is a binary, imbalanced target. These algorithms are enabled by default if the target column is considered imbalanced. While they are enabled, Driverless AI may decide to not use them in the final model to avoid poor performance.
Note
While Driverless AI does try imbalanced algorithms by default, they have not generally been found to improve model performance. Note that using imbalanced algorithms also results in a significantly larger final model, because multiple models are combined with different balancing ratios.
Imbalanced algorithms
Driverless AI provides two types of imbalanced algorithms: ImbalancedXGBoost and ImbalancedLightGBM. These imbalanced algorithms train an XGBoost or LightGBM model multiple times on different samples of data and then combine the predictions of these models together. These models use different samples of data and may use different sampling ratios. (By trying multiple ratios, DAI is more likely to come up with a robust model.)
Note
When your experiment is complete, you can find more details about what bagging was performed in the experiment AutoDoc. For a sample AutoDoc, view the blog post on this topic.
For more information on imbalanced modeling sampling methods, see Imbalanced Model Sampling Methods.
Relevant configuration options
Note: The following options can be accessed from the Expert Settings window. For more information, see Understanding Expert Settings.
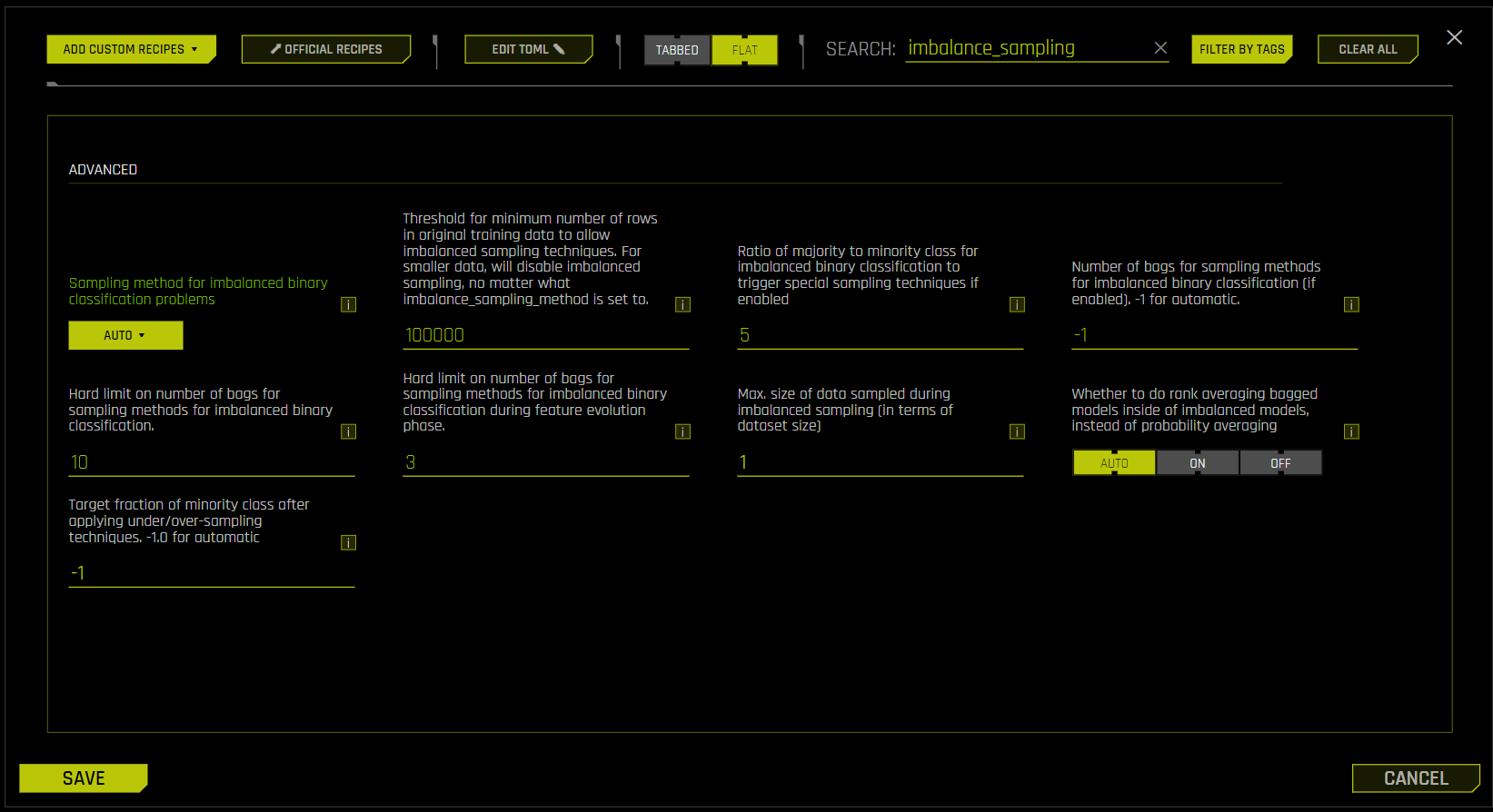
imbalance_sampling_method: Sampling method for imbalanced binary classification problems. Select one of the following options.auto: Sample both classes as needed, depending on the data.over_under_sampling: Over-sample the minority class and under-sample the majority class, depending on the data.under_sampling: Under-sample the majority class to reach class balance.off: Do not perform any sampling.
imbalance_ratio_sampling_threshold: Set this ratio below what is needed to classify the problem as imbalanced. By default, this is set to 5.
Enabling imbalanced algorithms
The following steps describe how to enable only imbalanced algorithms:
On the Experiment Setup page, click Expert Settings.
In the Expert Settings window, enter imbalance_sampling in the search field to filter the displayed settings.
Set Sampling method for imbalanced binary classification problems to
auto.Set Ratio of majority to minority class for imbalanced binary classification to trigger special sampling techniques if enabled to the ratio below what is needed to classify the problem as imbalanced. By default, this is set to 5.
Clear the search field. Go to the Training > Models tab.
For the Include specific models setting, click Select values. The Select Included Models page is displayed. Note that ImbalancedXGBoostGBM and ImbalancedLightGBM are selected by default.
To select only the unbalanced algorithms, click Uncheck All, and then select only the imbalanced algorithms: ImbalancedXGBoostGBM and ImbalancedLightGBM. Click Done to confirm your selection.
In the Expert Settings window, click the Save button.
Additional tips
This section describes additional tips you can make use of when enabling imbalanced algorithms.
Scorer selection
Ensure that you select a scorer that is not biased by imbalanced data. We recommend using the following scorers:
MCC: A proportion of true negatives is used instead of an absolute number. (In imbalanced use cases, you have a high count of true negatives.)
AUCPR: In this calculation, true negatives are not used at all.
Weight column
A weight column can be used to internally upsample the rare events. If you create a weight column that has a value of 10 when the target is positive and otherwise is 1, it tells the algorithms internally to consider getting the positive class correct as being ten times more important.