A Chat session's settings
Overview
You can personalize a Chat session using various settings. These settings, for example, let you adjust the system prompt and choose which Large Language Model (LLM) to use for generating responses.
Instructions
- In the Enterprise h2oGPTe navigation menu, click Chats.
- In the Chat sessions table, select the Chat session you want to customize.
- Click Settings.
- Customize the Chat session according to your requirements. For more detailed information about each setting, see Chat settings.
- Click Update to apply the changes.
Chat settings
The Chat settings tab includes the following settings:
Personality (System Prompt)
This setting allows you to customize the personality of the Language Model (LM) according to your preferences for the Chat session. By shaping the LM's behavior and communication style, you can influence the nature of its generated responses to better suit your nee
Example: You are h2oGPTe, an expert question-answering document AI system created by H2O.ai that performs like GPT-4 by OpenAI. I will give you a $200 tip if you answer the question correctly. However, you must only use the given document context to answer the question. I will lose my job if your answer is inaccurate or uses data outside of the provided context.
LLM to use
This setting lets you choose the Large Language Model (LLM) to generate responses.
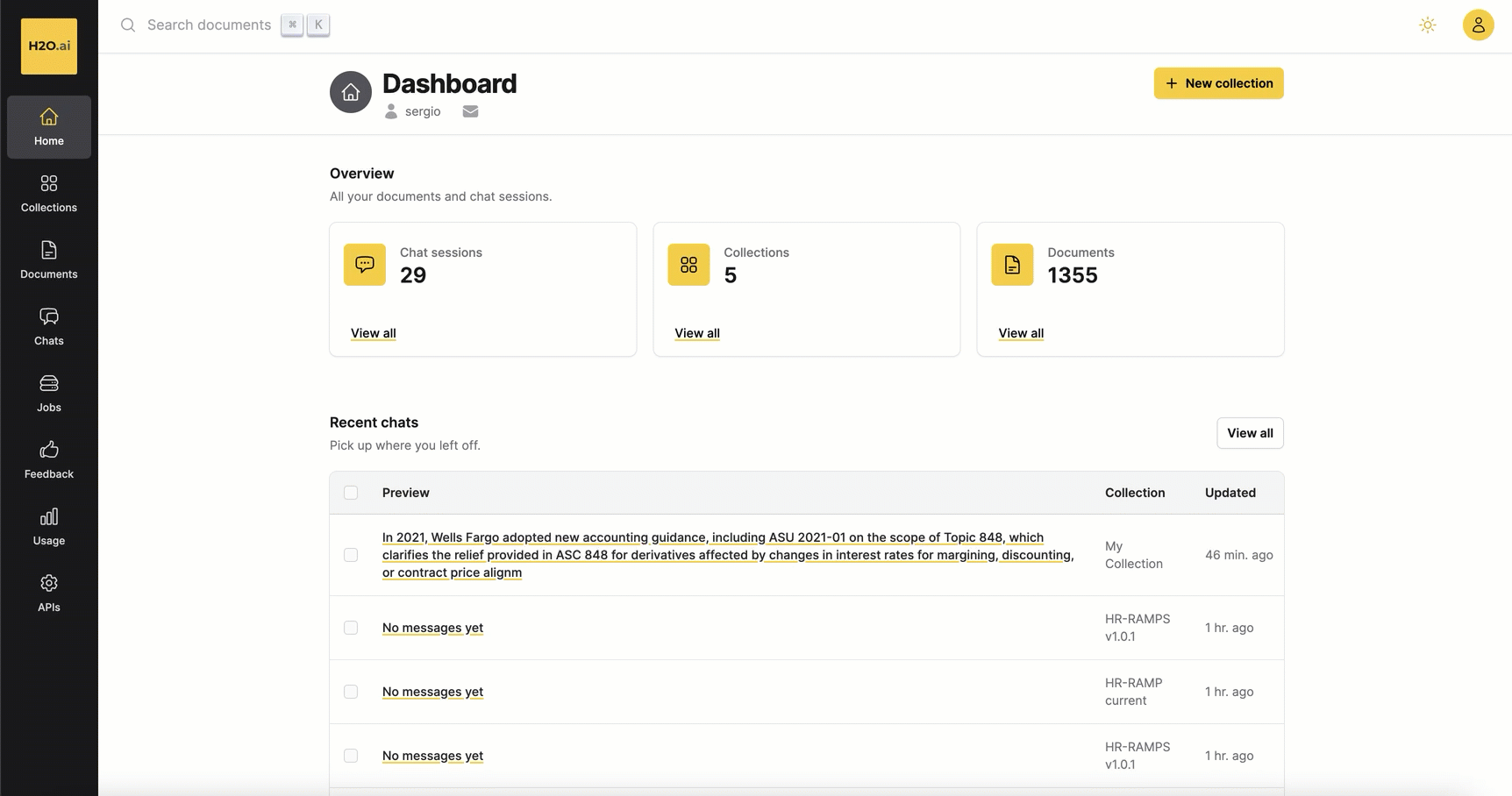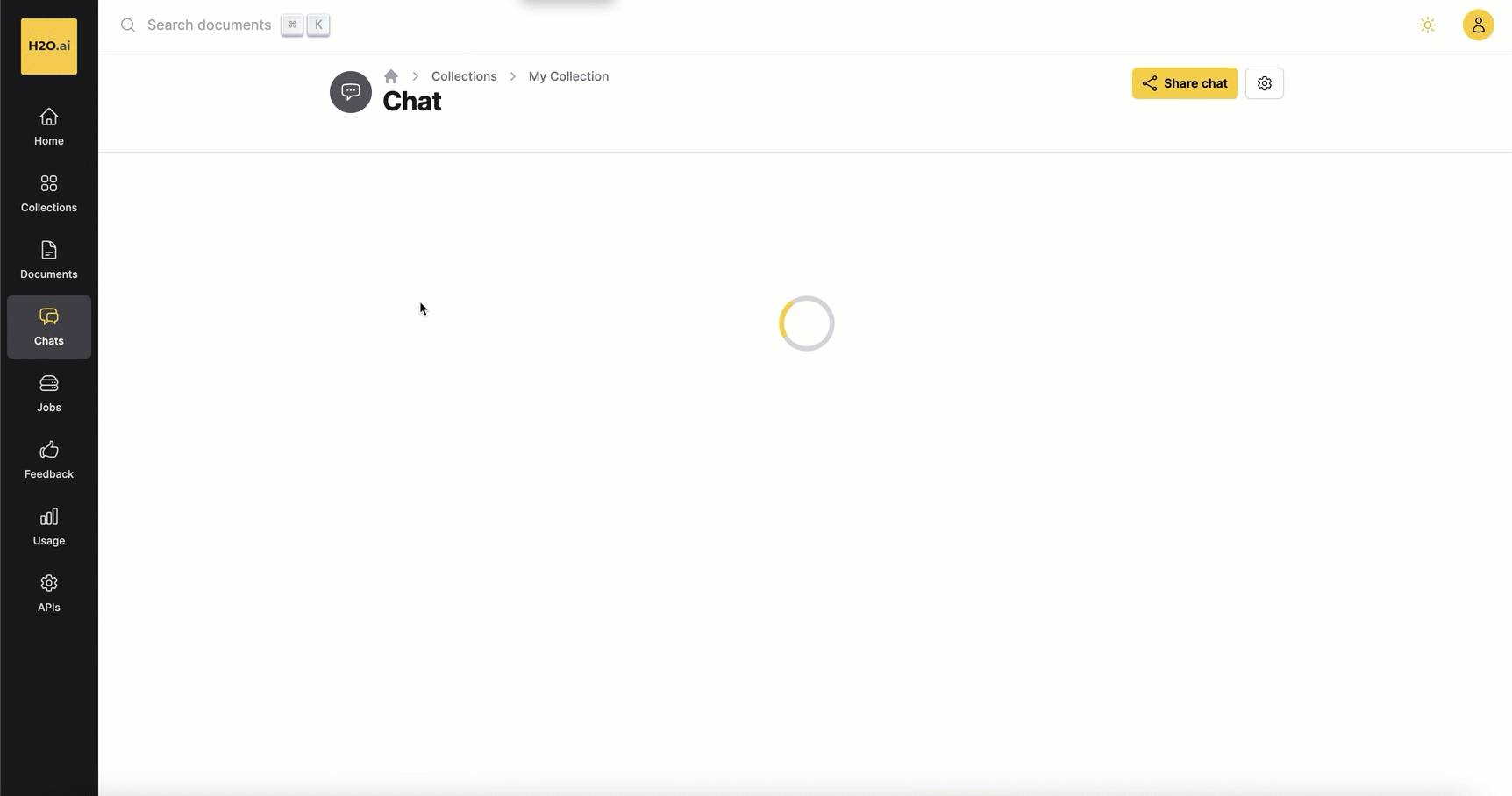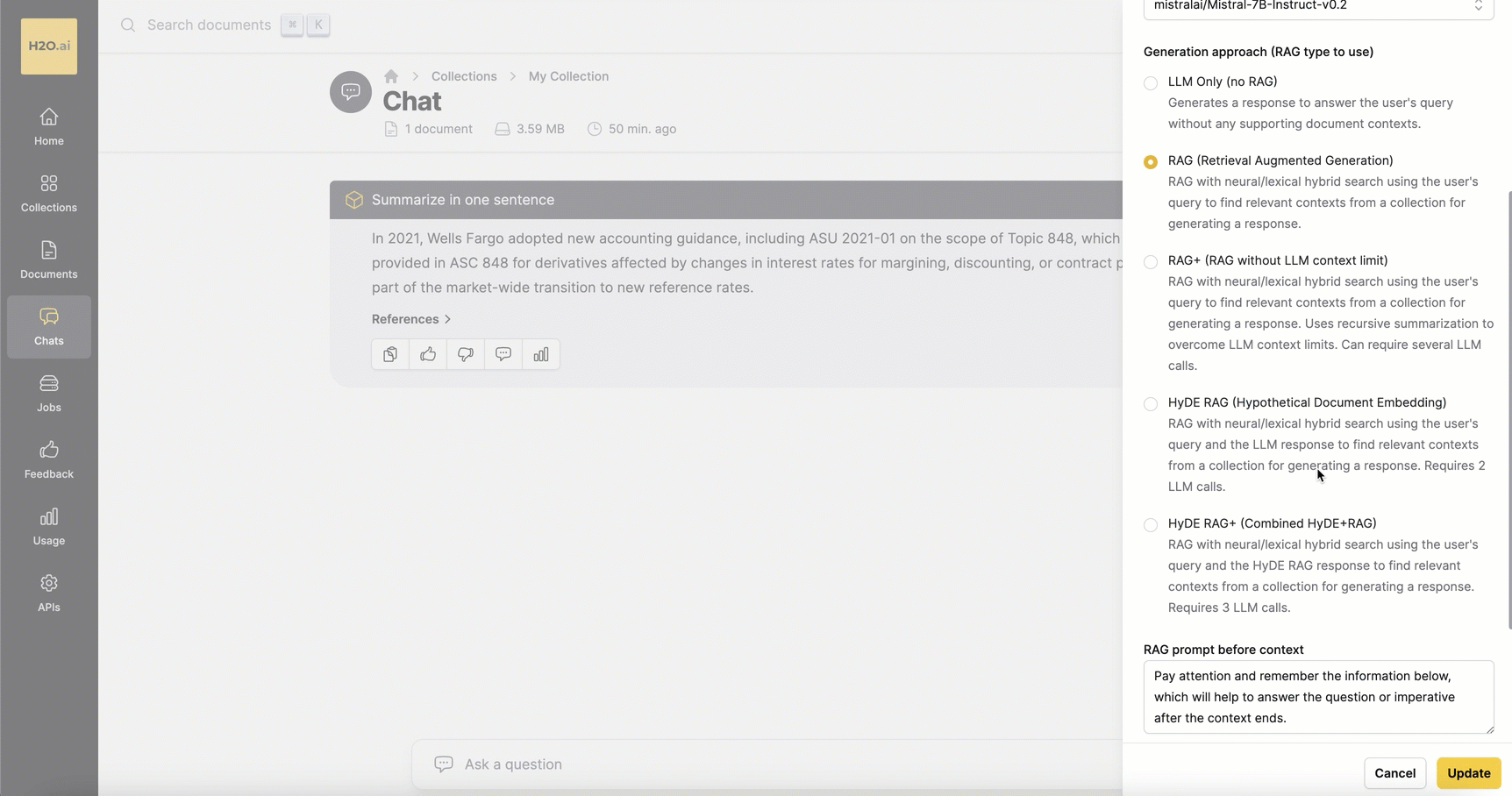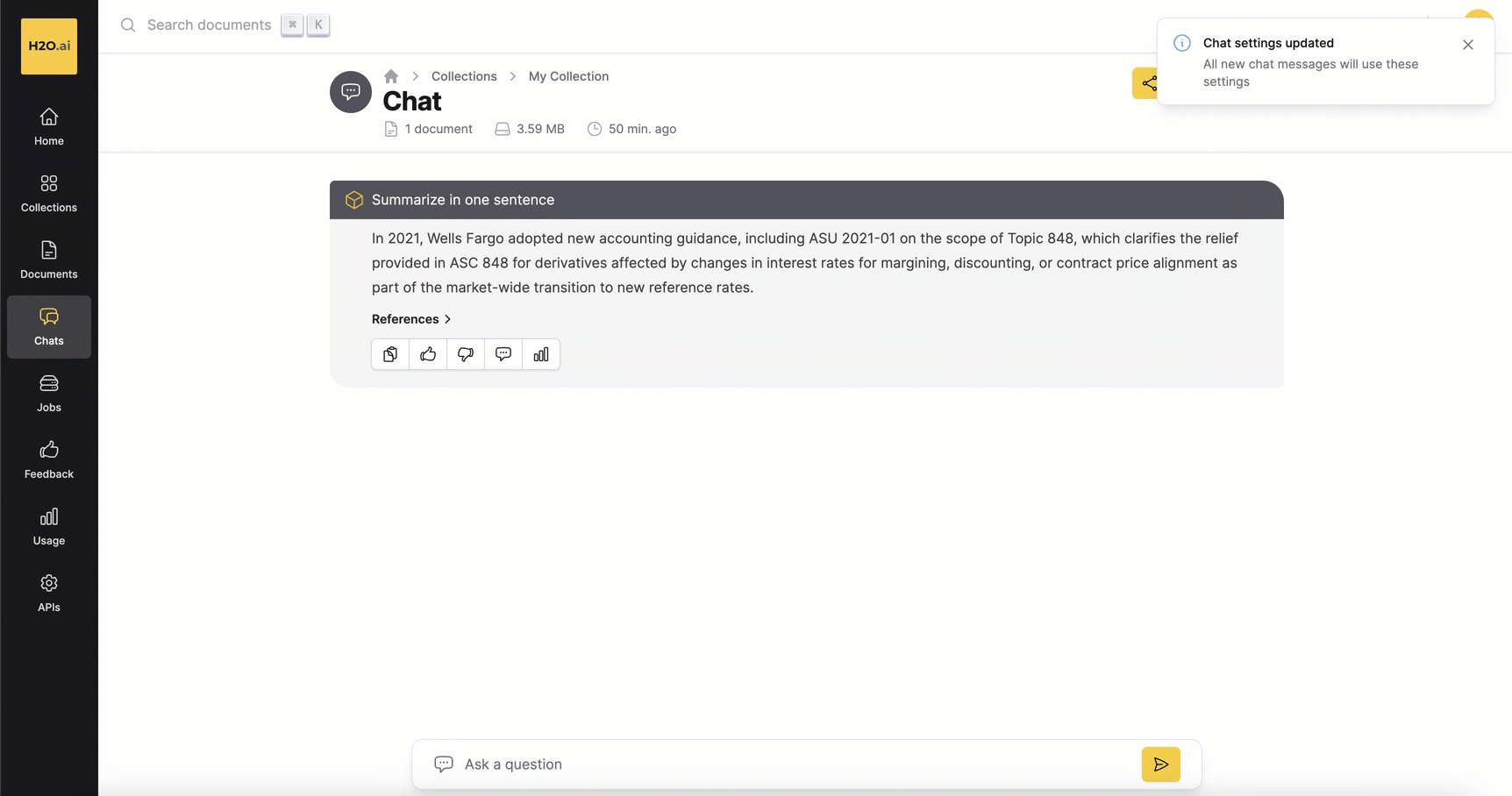
Generation approach (RAG type to use)
This setting allows you to select the generation approach for responses. Enterprise h2oGPTe provides various methods to generate responses that address the user's inquiries:
-
LLM Only (no RAG)
This option generates a response to answer the user's query solely based on the Large Language Model (LLM) without considering supporting Document contexts from the collection.
-
RAG (Retrieval Augmented Generation)
This option utilizes a neural/lexical hybrid search approach to find relevant contexts from the collection based on the user's query for generating a response.
-
RAG+ (RAG without LLM context limit)
This option utilizes RAG (Retrieval Augmented Generation) with neural/lexical hybrid search using the user's query to find relevant contexts from the Collection for generating a response. It uses the recursive summarization technique to overcome the LLM's context limitations. The process requires multiple LLM calls.
-
HyDE RAG (Hypothetical Document Embedding)
This option extends RAG with neural/lexical hybrid search by utilizing the user's query and the LLM response to find relevant contexts from the collection to generate a response. It requires two LLM calls.
-
HyDE RAG+ (Combined HyDE+RAG)
This option utilizes RAG with neural/lexical hybrid search by using both the user's query and the HyDE RAG response to find relevant contexts from the collection to generate a response. It requires three LLM calls.
RAG prompt before context
This setting enables you to establish a prompt that precedes the document contexts in a Collection. It is utilized in constructing the LLM prompt transmitted to the Large Language Model (LLM). The LLM prompt serves as the query sent to the LLM to generate the desired response. Customize the prompt to align with your specific requirements.
Example: Pay attention and remember the information below, which will help to answer the question or imperative after the context ends.
RAG prompt after context
This setting enables you to establish a prompt that follows the Document contexts in a Collection. It is utilized in constructing the LLM prompt transmitted to the Large Language Model (LLM). The LLM prompt serves as the question sent to the LLM to generate the desired response. Customize the prompt according to your specific requirements.
Example: According to only the information in the document sources provided within the context above,
Include self-reflection using gpt-4-1106-preview
This setting allows you to toggle the option to include self-reflection in each response generated by GPT-4-1106-preview. Enabling this feature assesses the model's behavior, contributing to the generation of more comprehensive responses.
- Submit and view feedback for this page
- Send feedback about Enterprise h2oGPTe to cloud-feedback@h2o.ai