Customize a Chat session
Overview
Using various settings, you can customize a Chat session. These settings, for example, let you adjust the system prompt and choose which Large Language Model (LLM) to use to generate responses.
Instructions
- In the Enterprise h2oGPTe navigation menu, click Chats.
- In the Recent chats table, select the Chat session you want to customize.
- If you do not see the Customize chat card, click Customize.

- You can customize the Chat session to suit your needs. For example, you can adjust the information source (Documents), configuration settings, and prompt template. For detailed information on each setting, see the following subsections: Documents, Configuration, and Prompts.
All customization edits made to the Chat session under Documents and Prompts are auto-saved, while the Configuration settings are not persisted.
Documents
The Documents tab includes the following settings:
Collection to use
This setting enables you to choose a collection to use as a source of information that provides context for the Chat session.
Description
This setting defines the description of the Collection.
Documents
This section displays the available Documents currently part of the selected Collection.
You can add more Documents to the Collection using the + Add documents button.
Configuration
The Configuration tab includes the following settings:
LLM
This setting lets you choose the Large Language Model (LLM) to generate responses.
Enable vision
In addition to sending document context to the normal Large Language Model (LLM), this setting allows you to pass document context as images to a vision-capable LLM.
- Off: This option does not use a vision-capable LLM to pass document context as images. Document context is sent only to the regular Large Language Model (LLM).
- Auto: This option allows the system to automatically determine whether to use a vision-capable LLM based on the document context and the LLM model being used. The system decides if a vision-capable LLM is needed and selects it accordingly.
- On: This option enables the use of a vision-capable LLM, ensuring that document context is passed as images to the vision-capable LLM.
Enabling vision mode can lead to higher latency and cost.
Vision LLM
This setting allows you to select the LLM for processing images. Selecting automatic mode will pick a vision LLM based on availability and configuration. It typically selects the same LLM for vision-capable models and the default LLM for non-vision models.
Generation approach
This setting lets you select the generation approach for responses. Enterprise h2oGPTe provides various methods to generate responses:
-
Automatic
This option is the automatic selection of the generation approach. LLM Only (no RAG) type is not considered for Chats with Collections.
-
LLM Only (no RAG)
This option generates a response to answer the user's query solely based on the Large Language Model (LLM) without considering supporting Document contexts from the Collection.
-
RAG (Retrieval Augmented Generation)
This option utilizes a neural/lexical hybrid search approach to find relevant contexts from the collection based on the user's query for generating a response. Applicable when the prompt is easily understood and the context contains enough information to come up with a correct answer.
RAG first performs a vector search for similar chunks limited by the number of chunks sorted by distance metric. By default, Enterprise h2oGPTe chooses the top 25 chunks using lexical distance and top 25 using neural distance. The distance metric is calculated by the cross entropy loss from the BAAI/bge-reranker-large model. These chunks are passed to the selected LLM to answer the user's query. Note that Enterprise h2oGPTe lets you view the exact prompt passed to the LLM.
-
LLM Only + RAG composite
This option extends RAG with neural/lexical hybrid search by utilizing the user's query and the LLM response to find relevant contexts from the collection to generate a response. It requires two LLM calls. Applicable when the prompt is somewhat ambiguous or the context does not contain enough information to come up with a correct answer.
HyDE (Hypothetical Document Embeddings) is essentially the same as RAG except that it does not simply search for the embeddings with the smallest distance to the query. Instead, it first asks an LLM to try to answer the question. It then uses the question and the hypothetical answer to search for the nearest chunks.
Example question: What are the implications of high interest rate?
-
RAG: Searches for chunks in the document with a small distance to the embedding of the question: "What are the implications of high interest rate?"
-
LLM Only + RAG composite:
- Asks an LLM: "What are the implications of high interest rate?"
- LLM answers: "High interest rates can have several implications, including: higher borrowing cost, slower economic growth, increased savings rate, higher returns on investment, exchange rate fluctuation, ..."
- RAG searches for chunks in the document with a small distance to the embedding of the question AND the answer from Step b. This effectively increases the potentially relevant chunks.
-
-
HyDE + RAG composite
This option utilizes RAG with neural/lexical hybrid search by using both the user's query and the HyDE RAG response to find relevant contexts from the collection to generate a response. It requires three LLM calls. Applicable when the prompt is very ambiguous or the context contains conflicting information and it's very difficult to come up with a correct answer.
-
Summary RAG
This option utilizes RAG (Retrieval Augmented Generation) with neural/lexical hybrid search using the user's query to find relevant contexts from the Collection for generating a response. It uses the recursive summarization technique to overcome the LLM's context limitations. The process requires multiple LLM calls. Applicable when the prompt is asking for a summary of the context or a lengthy answer such as a procedure that might require multiple large pieces of information to process.
The vector search is repeated as in RAG but this time k neighboring chunks are added to the retrieved chunks. These returned chunks are then sorted in the order they appear in the document so that neighboring chunks stay together. The expanded set of chunks is essentially a filtered sub-document of the original document, but more pertinent to the user's question. Enterprise h2oGPTe then summarizes this sub-document while trying to answer the user's question. This step uses the summary API, which applies the prompt to each context-filling chunk of the sub-document. It then takes the answers and joins 2+ answers and subsequently applies the same prompt, recursively reducing until only one answer remains.
The benefit of this additional complexity is that if the answer is throughout the document, this mode is able to include more information from the original document as well as neighboring chunks for additional context.
-
All Data RAG
This option is similar to summary RAG, but includes all the chunks. It uses the recursive summarization technique to overcome the LLM's context limitations. The process requires multiple LLM calls.
Show Automatic LLM Routing Cost Controls
This toggle setting routes the chat request to the optimal LLM based on cost/performance considerations when "Automatic" is selected in the LLM setting.
Upper Limit on Cost per LLM call
This setting defines the maximum allowable cost in U.S. dollars (USD) per LLM call during Automatic model routing (when "Automatic" selected in the LLM setting). If the estimated cost, based on input and output token counts, exceeds this limit, the request will fail as early as possible.
Willingness to Pay for Accuracy
This setting specifies the amount you're willing to pay, in U.S. dollars (USD), for each additional 10% or more increase in model accuracy when performing automatic routing for every LLM call. Automatic routing refers to "Automatic" selected in the LLM setting.
Enterprise h2pGPTe starts with the least accurate model. For each more accurate model, it is accepted if the increase in estimated cost divided by the increase in estimated accuracy is no more than this value divided by 10%, up to the upper limit on cost per LLM call.
Setting a lower value for this setting will try to keep the cost as low as possible; higher values will approach the cost limit to increase accuracy.
Willingness to Wait for Accuracy
This setting determines how long you're willing to wait for a more accurate model during automatic routing, measured in seconds per 10% or more increase in accuracy. Automatic routing refers to "Automatic" selected in the LLM setting. The process starts with the least accurate model and progresses to more accurate ones. A model is accepted if the increase in estimated time divided by the increase in estimated accuracy does not exceed this value divided by 10%. Lower values prioritize faster processing, while higher values allow more time to improve accuracy.
Show Expert Settings
This toggle setting determines whether to display expert settings for retrieval, chat, and generation. Turning this toggle displays the following settings:
- Temperature
- Output Token Limit
- Include chat conversation history
- Include self-reflection
- Document Metadata to include
Temperature
This setting lets you adjust the temperature parameter, which affects the model's text generation variability. By softening the probability distribution over the vocabulary, you encourage the model to produce more diverse and creative responses.
A higher temperature value makes the model more willing to take risks and explore less likely word choices. This can result in more unpredictable but more imaginative outputs. Conversely, lower temperatures produce more conservative and predictable responses, favoring high-probability words.
Adjusting the temperature parameter is particularly useful when injecting more variability into the generated text. For example, a higher temperature can inspire a broader range of ideas in creative writing or brainstorming scenarios. However, a lower temperature might be preferable to ensure accuracy in tasks requiring precise or factual information.
Output Token Limit
This setting lets you control the maximum number of tokens the model can generate as output. There's a constraint on the number of tokens (words or subwords) the model can process simultaneously. This includes both the input text you provide and the generated output.
This setting is crucial because it determines the length of the responses the model can provide. By default, the model limits the number of tokens in its output to ensure it can handle the input text and generate a coherent response. However, for detailed answers or to avoid incomplete responses, you may need to allow for longer responses.
Increasing the number of output tokens expands the model's capacity to generate longer responses. However, this expansion comes with a trade-off: it may require sacrificing some input context. In other words, allocating more tokens to the output might mean reducing the number of tokens available for processing the input text. This trade-off is important to consider because it can affect the quality and relevance of the model's responses.
Include chat conversation history
This setting lets you include the chat history as context for future responses provided within the conversation with the LLM. Including chat conversation history can help the model give more specific responses catered to your context, and based on what you have already asked for before.
However, for use cases that do not require prior context and only need independently reproducible answers, you can disable this setting.
- Off: Disables the inclusion of chat history. Each response is generated independently of the context of the prior conversation.
- Auto: Automatically includes chat history when it improves response accuracy but omits it when the context isn’t necessary.
- On: Ensures chat history is always included in the conversation, allowing the model to reference past interactions for context continuously.
Include self-reflection
This setting lets you engage in self-reflection with the model's responses. With self-reflection, the model reviews both the prompt you've given and the response it generates. It's particularly useful for spot checks, especially when working with less computationally expensive models.
Self-reflection lets you assess the quality and relevance of the model's output in the context of the input prompt. Reviewing both the prompt and the generated response, you can quickly identify any inconsistencies, errors, or areas for improvement.
Self-reflection uses the most powerful model for spot checks of less expensive models.
The h2oGPTe API allows complete control over the model and parameters.
Document Metadata to include
This setting lets you to include metadata for the uploaded documents as part of the document context. Including metadata is useful for creating custom prompt templates. The additional metadata helps LLMs better understand the documents.
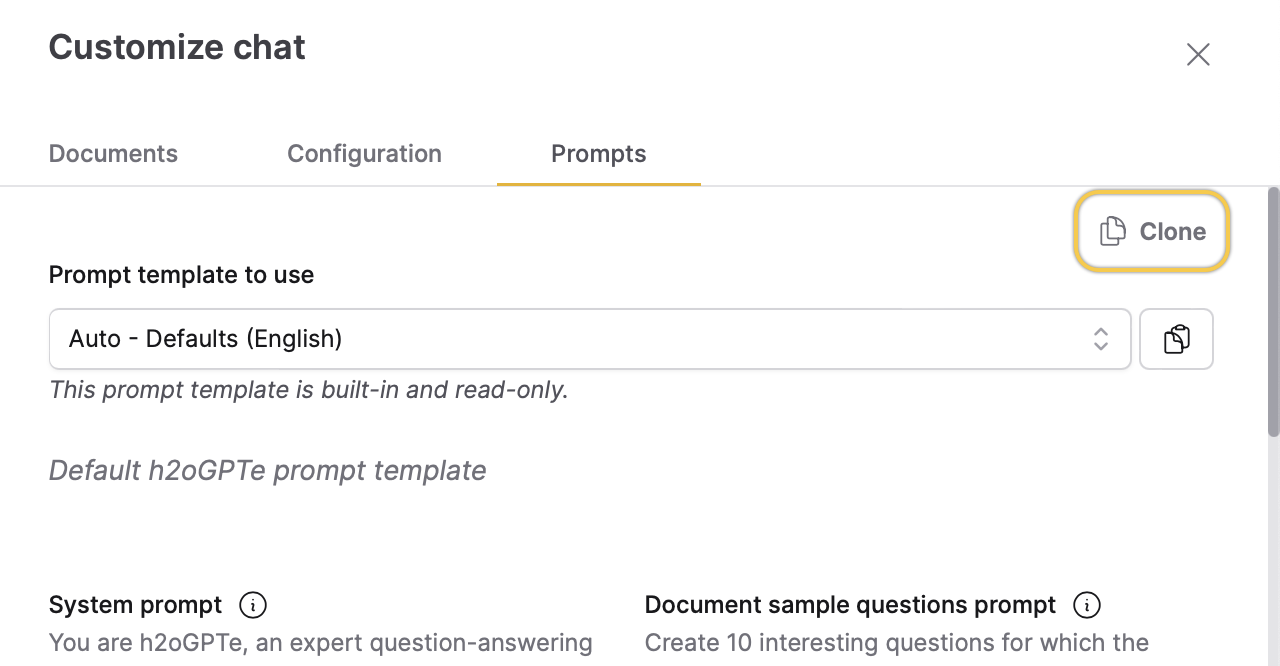
Prompts
The Prompts tab includes the following settings:
Prompt template to use
This setting lets you choose a prompt template to use within the Chat session. You can create your prompt template on the Prompts page and apply it to your Collection.
Click Clone to duplicate the selected prompt template and create an additional template with identical or similar configurations. This feature lets you create a prompt template tailored to your specific requirements. For more information, see Clone a prompt template.
- Submit and view feedback for this page
- Send feedback about Enterprise h2oGPTe to cloud-feedback@h2o.ai