A Chat session
Overview
A Chat session is an interaction between you and Enterprise h2oGPTe that consists of a series of prompts and answers.
Components of a Chat session

-
Copy response
This button enables you to copy the LLM response.
-
Upvote/Downvote response
These two buttons allow you to provide feedback on the usefulness of a response. This feedback is valuable for developers in improving the model. Your feedback is stored on the Feedback page. To learn more, see Feedback.
-
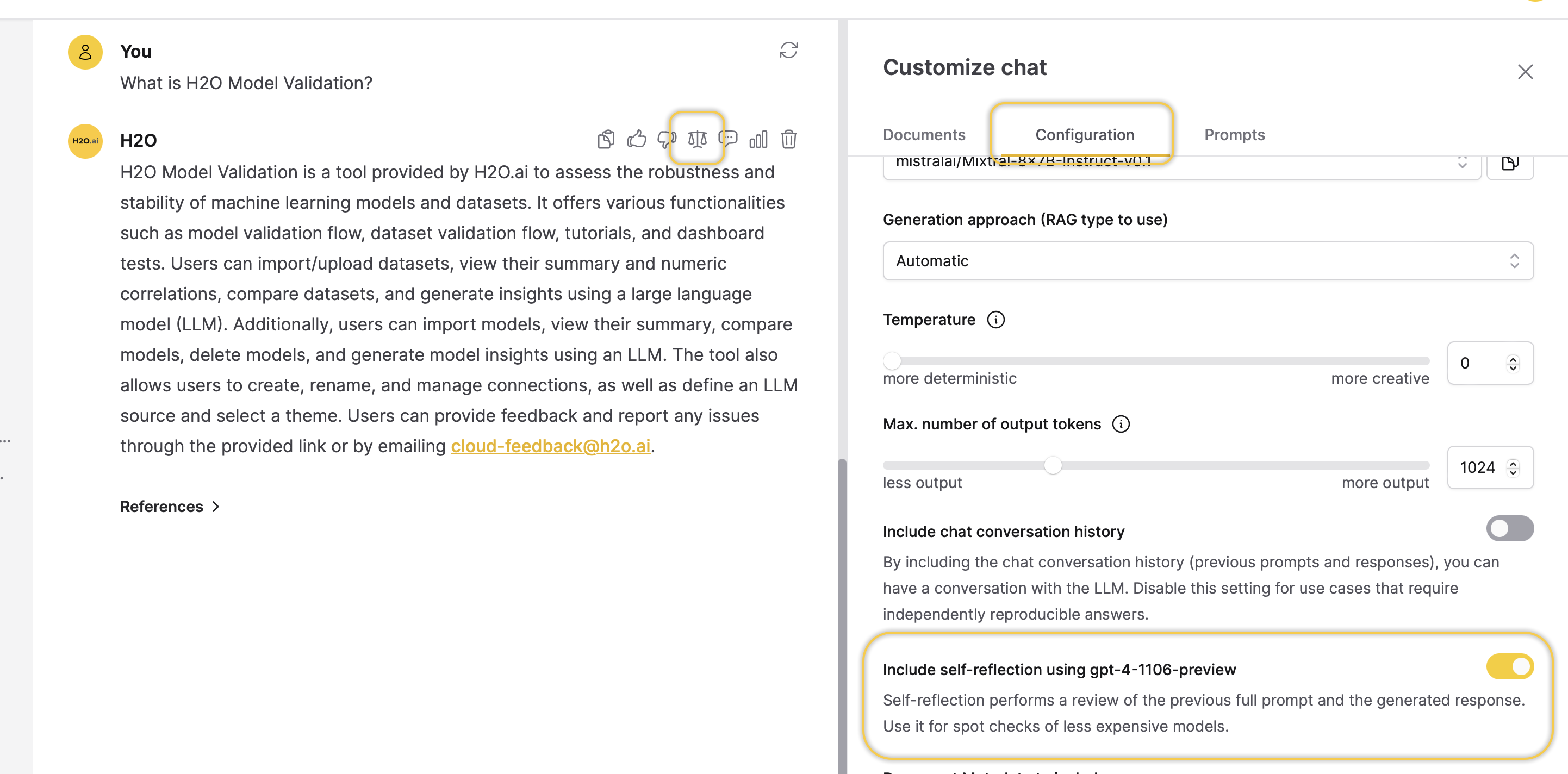
Self Reflection
This button grants you access to the self-reflection score of the LLM response.
noteThis button is only available if you turn on the following setting in the Configurations tab located in the Customize chat section: Include self-reflection using gpt-4-1106-preview.
-
LLM Prompt (excl. images)
This button allows you to view the full LLM prompt, constructed using the RAG prompt before context, the Document context, and the RAG prompt after context. The LLM prompt is the question sent to the LLM to generate a desired response.
-
Usage stats
This button showcases the Usage Stats card, which highlights detailed information about performance and resource utilization during a Chat session. These statistics encompass various metrics to track the efficiency and cost associated with the session.
- response_time: This metric indicates the duration required for the LLM (Large Language Model) to generate a response to the user's query.
- retrieval_time: This metric refers to the duration, measured in seconds, it takes to receive a response.
- cost: This represents the expenses linked with the Chat session. It denotes the expenditure involved in processing the user's query and producing the corresponding response, measured in US dollars.
- llm_args: This refers to the arguments or parameters provided to the Large Language Model (LLM).
- num_chunks: This indicates the number of chunks the data is divided into.
- num_images: This reflects the number of images involved in generating the LLM response.
- usage: This section provides additional insights about the resources used for the LLM response.
- llm: This denotes the Large Language Model (LLM) used to create the LLM response.
- input_tokens: This indicates the number of tokens in the user's input.
- output_tokens: This reflects the number of tokens in the generated output.
- tokens_per_second: This measures the rate at which tokens are processed per second.
- origin: This specifies the method or approach used to generate the LLM response.
- cost: This represents the expense associated with the LLM response.
-
Delete response
This button allows you to delete the LLM response.
-
References
This section lets you view the References section, which highlights the sections of the Document from which the context was derived to generate the response.
- Submit and view feedback for this page
- Send feedback about Enterprise h2oGPTe to cloud-feedback@h2o.ai