Chat session
Overview
A Chat session is a focused interaction between you and Enterprise h2oGPTe, consisting of a series of prompts and answers that are based on a specific Collection.
The default language used to chat with Enterprise h2oGPTe is set to English. However, you can also Chat using a different language by specifying the desired language within the following setting located in the Chat settings page: Personality (System Prompt). For more information about supported languages, see FAQs.
Components of a Chat session
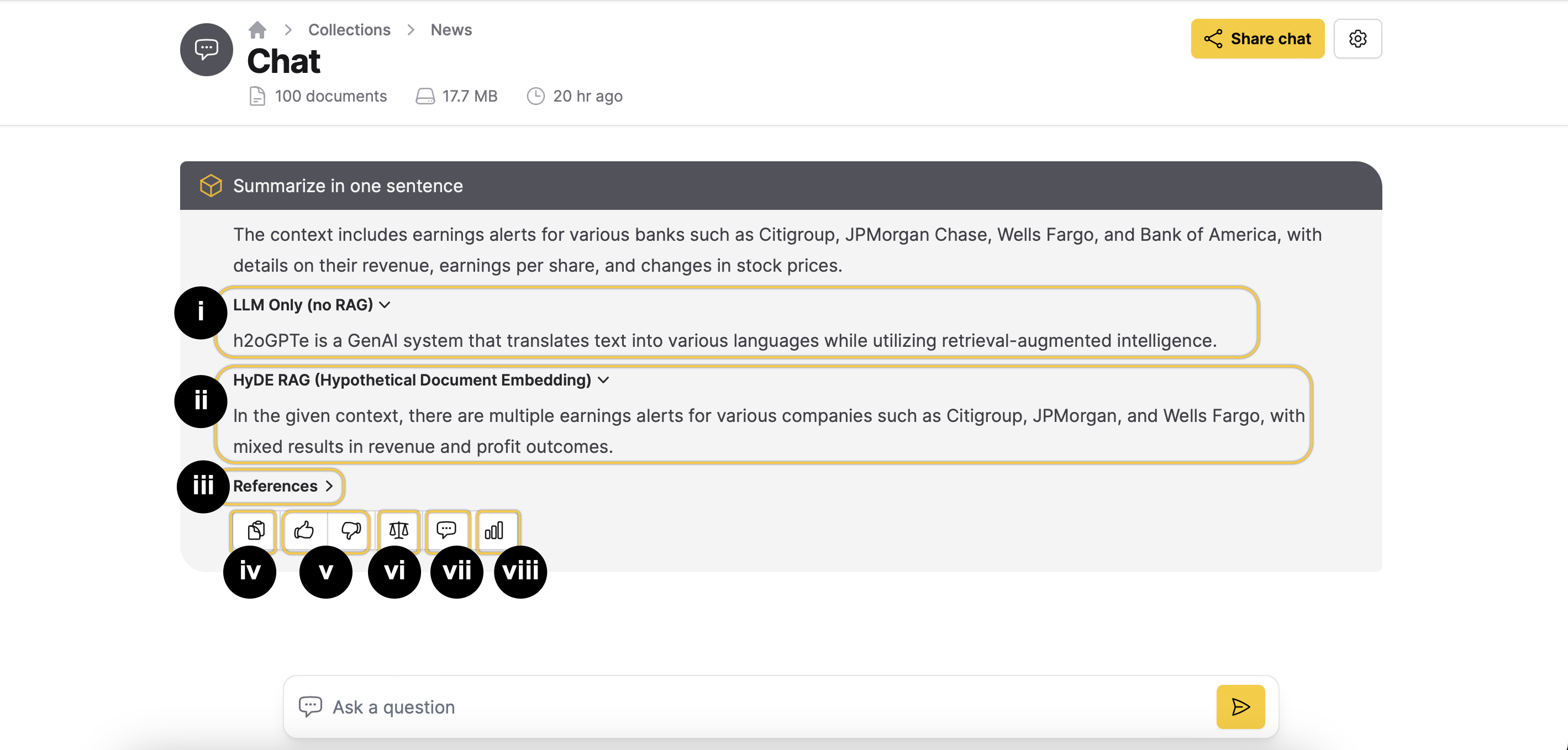
i: LLM Only (no RAG)
The LLM Only (no RAG) section only appears when you select LLM Only (no RAG) as the generation approach (RAG type to use). It shows the generated response to the user's query based on the Large Language Model (LLM) without considering supporting Document contexts from the collection.
ii: HyDE RAG (Hypothetical Document Embedding)
The HyDE RAG (Hypothetical Document Embedding) section provides the response generated from RAG with neural/lexical hybrid search by utilizing the user's query and the LLM response.
iii: References
The References section highlights the sections of the Document from which the context was derived in order to generate the response.

iv: Copy response
You can copy the LLM response to the clipboard by clicking the icon.
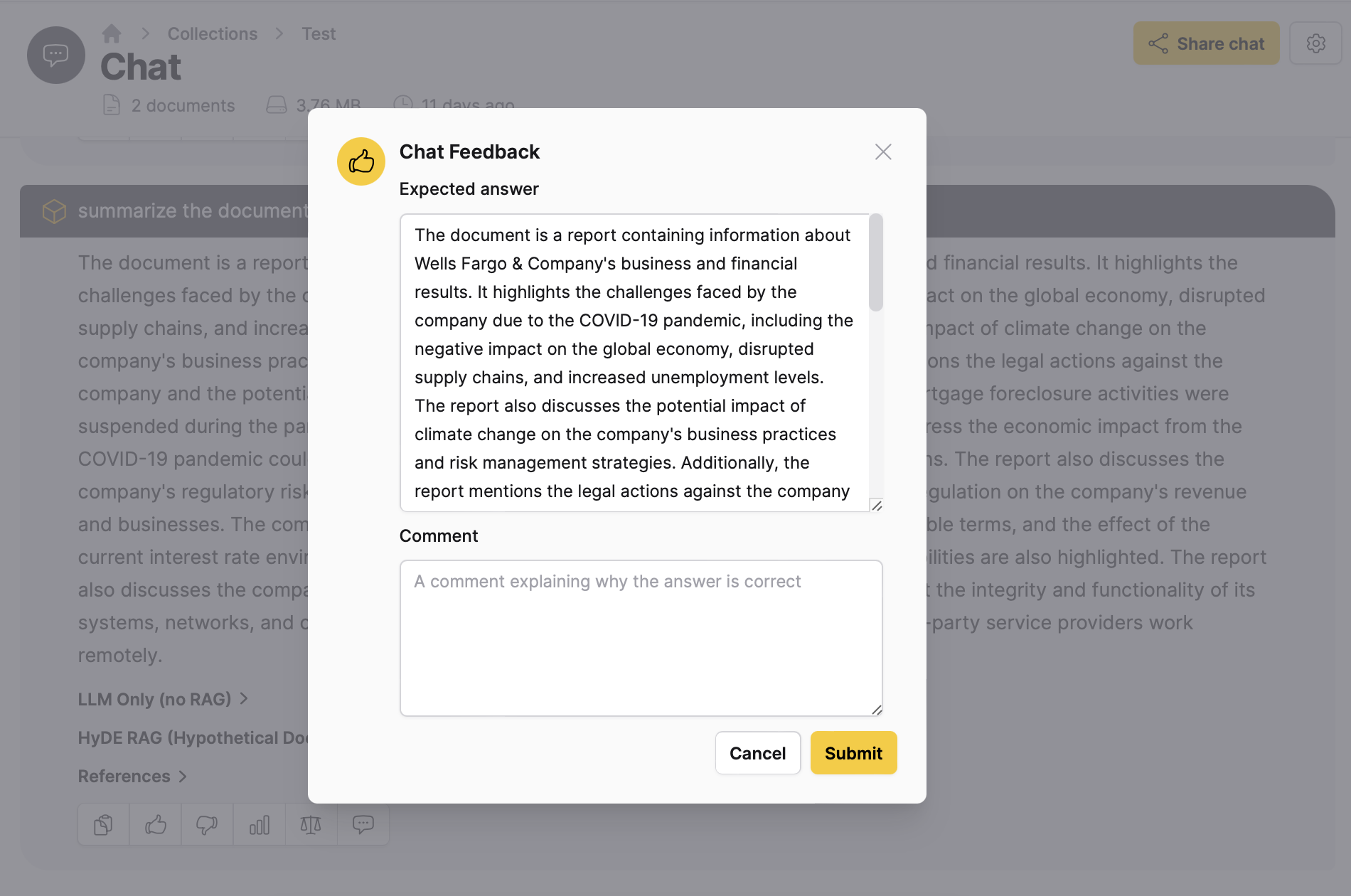
v: User feedback
The and icons let you provide feedback on the usefulness of a response. This helps developers improve the model. Add your comment on the response generated by a Large Language Model (LLM) and click Submit.
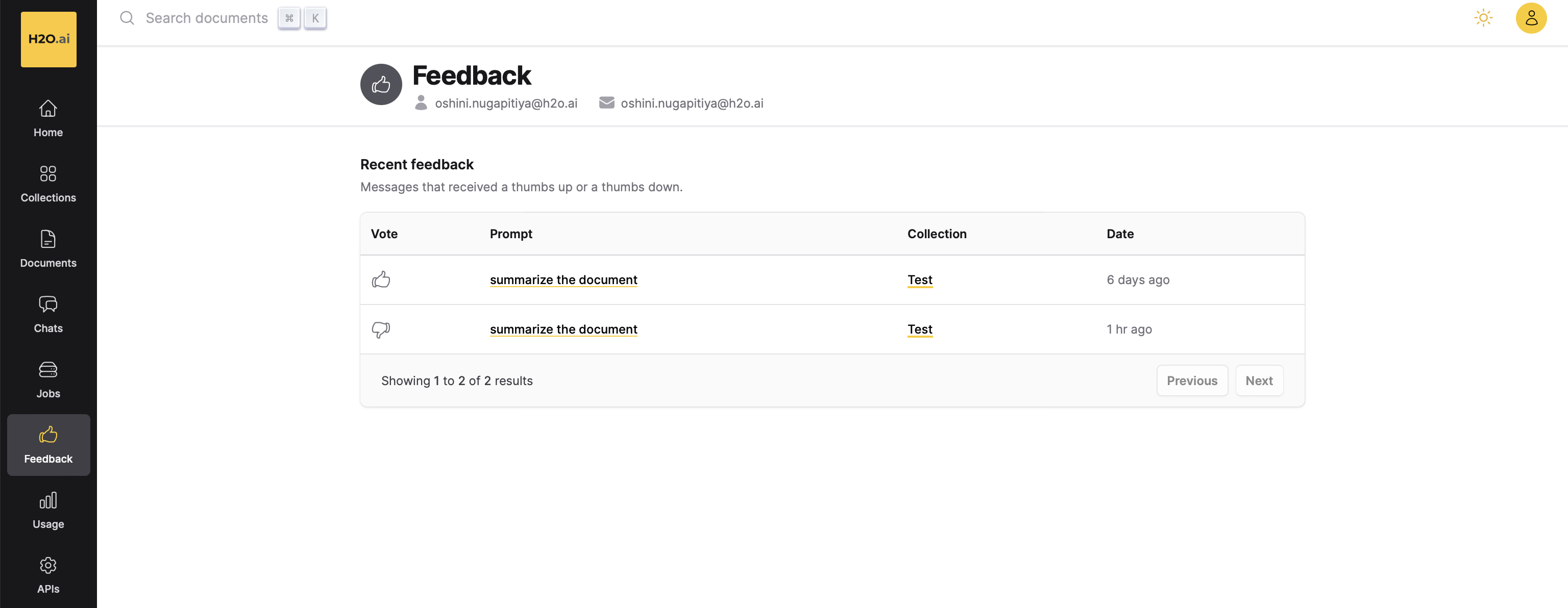
Your feedback will be stored in the Feedback section. To view all the recent feedback, click Feedback on the h2oGPTe navigation menu.
vi: Self-reflection
The Self-reflection section appears when you toggle the Include self-reflection for every response option in Chat settings. It asks another LLM for a reflection of the answer given to the question and the context provided in the Collection. It can be used to evaluate the LLM’s performance.
vii: LLM prompt
You can view the full LLM prompt that is constructed using the RAG prompt before context, the Document context, and the RAG prompt after context. The LLM prompt is the question that is sent to the LLM to generate a desired response.
The RAG prompt before and after context can be configured in three places:
- In Collection settings: Once you customize the prompts, they will be persisted as the new default for any use of that collection.
- In Chat settings: Once you customize the prompts, they will be persisted as the new default for other Chat sessions of that particular collection.
- Via h2oGPTe Python Client: You can customize the prompts per query through the Python client.

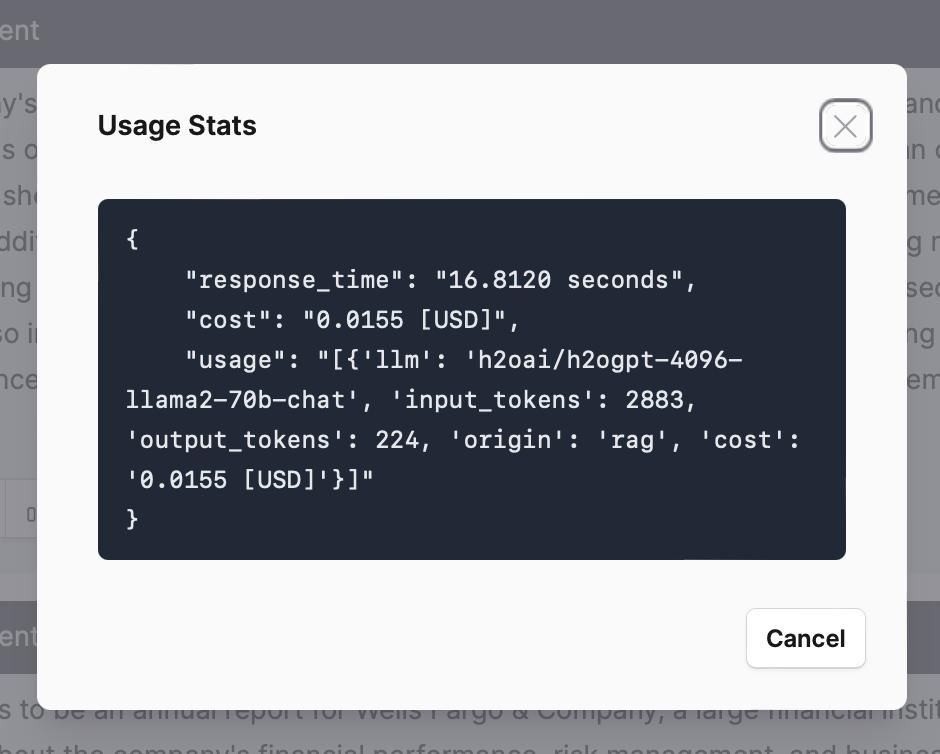
viii: Usage stats
The Usage stats provides detailed information about the performance and resource utilization during a Chat session.
The Usage stats include the following metrics to help track the efficiency and cost associated with a Chat session.
- Response time: indicates the duration it takes for the LLM (Large Language Model) to generate a response to the user's query.
- Cost: represents the cost associated with the Chat session. It indicates the cost incurred to process the user's query and generate the corresponding response. The cost is given in US dollars.
- Usage: provides more details about the usage of resources during the Chat session.
- llm: the Large Language Model (LLM) to use for generating responses.
- input_tokens: the number of tokens in the user's query.
- output_tokens: the number of tokens in the generated response.
- origin: the generation approach (RAG type) used for generating responses to answer the user's queries.
- cost: the cost associated with the Chat session.
For more information, see Chat settings, Share a Chat session, and Delete a Chat session.
- Submit and view feedback for this page
- Send feedback about Enterprise h2oGPTe to cloud-feedback@h2o.ai