내부 검증 기술¶
본 섹션은 Driverless AI의 내부 검증 기술에 관해 설명합니다.
실험을 위해 Driverless AI가 다음 중 하나를 수행합니다.
데이터를 학습 세트와 내부 검증 세트로 분할
또는
교차 검증을 사용하여 데이터를 \(n\) 폴드로 분할
Driverless AI는 데이터 크기 및 accuracy 설정에 따라 방법을 선택합니다. 방법 1의 경우 데이터의 일부가 제거되어 내부 유효성 검사에 이용됩니다( Note: 데이터가 작으면 학습에 더 많은 데이터를 사용하도록 학습 및 내부 검증 분할이 반복될 수 있습니다).
그러나 방법 2의 경우, 내부 검증에 데이터가 낭비되지 않습니다. 교차 검증을 사용하면 전체 데이터 세트가 활용되고 각 모델은 학습 데이터의 다른 서브세트에서 학습됩니다. 아래의 시각화에서는 5-폴드가 있는 교차 검증의 사례를 볼 수 있습니다..
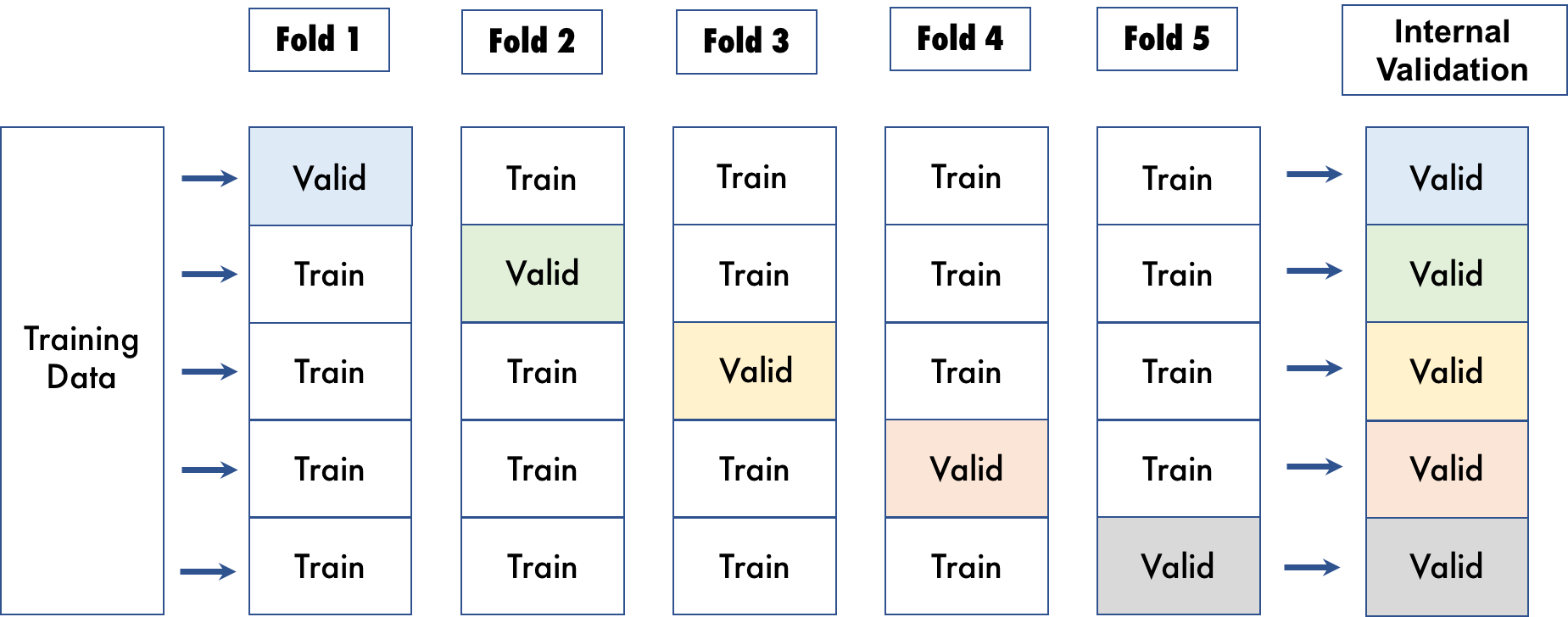
Driverless AI는 교차 검증을 위해 데이터를 지정된 폴드 수로 무작위 분할합니다. 교차 검증을 사용하면 전체 데이터 세트가 활용되고, 각 모델은 학습 데이터의 다른 서브세트에서 학습됩니다.
Driverless AI는 사용자가 폴드 열 또는 검증 데이터 세트를 제공하는 경우, 무작위로 내부 검증 데이터를 자동 생성하지 않습니다. 폴드 열 또는 데이터 세트가 제공되면, Driverless AI는 해당 데이터를 사용하여 Driverless AI 모델 성능을 계산하고 모든 성능 그래프 및 통계를 계산합니다.( Note: 폴드 및 가중치 열은 모델링에서 특성으로 사용되지 않습니다.)
만약 실험이 Time Series 유스케이스이고, 시간 열이 선택되면 Driverless AI가 내부 검증 데이터가 생성되는 방식을 변경합니다. 시간 데이터에서는 과거 데이터를 학습하고 최신 데이터를 검증하는 것이 중요합니다. Driverless AI는 무작위 분할을 수행하지 않고, 데이터 유출 방지를 위해 데이터의 시간적 특성을 중요시합니다. 또한, 학습/검증 분할은 학습과 테스트 사이의 시간 gap과 forecast horizon(예측 기간)의 함수입니다. 테스트 데이터가 제공되는 경우, Driverless AI는 해당 매개변수에 대한 값을 제안하여 가능한 한 테스트 세트와 유사한 검증 세트를 만듭니다. 하지만, 사용자가 실제 응용 프로그램에 맞도록 검증 분할 생성을 제어할 수 있습니다.