Driverless AI의 대량 데이터 세트¶
다양한 특성이 포함된 대량 데이터 세트에는 변수 가공 및 모델 빌드에 대한 고유한 문제가 있습니다.
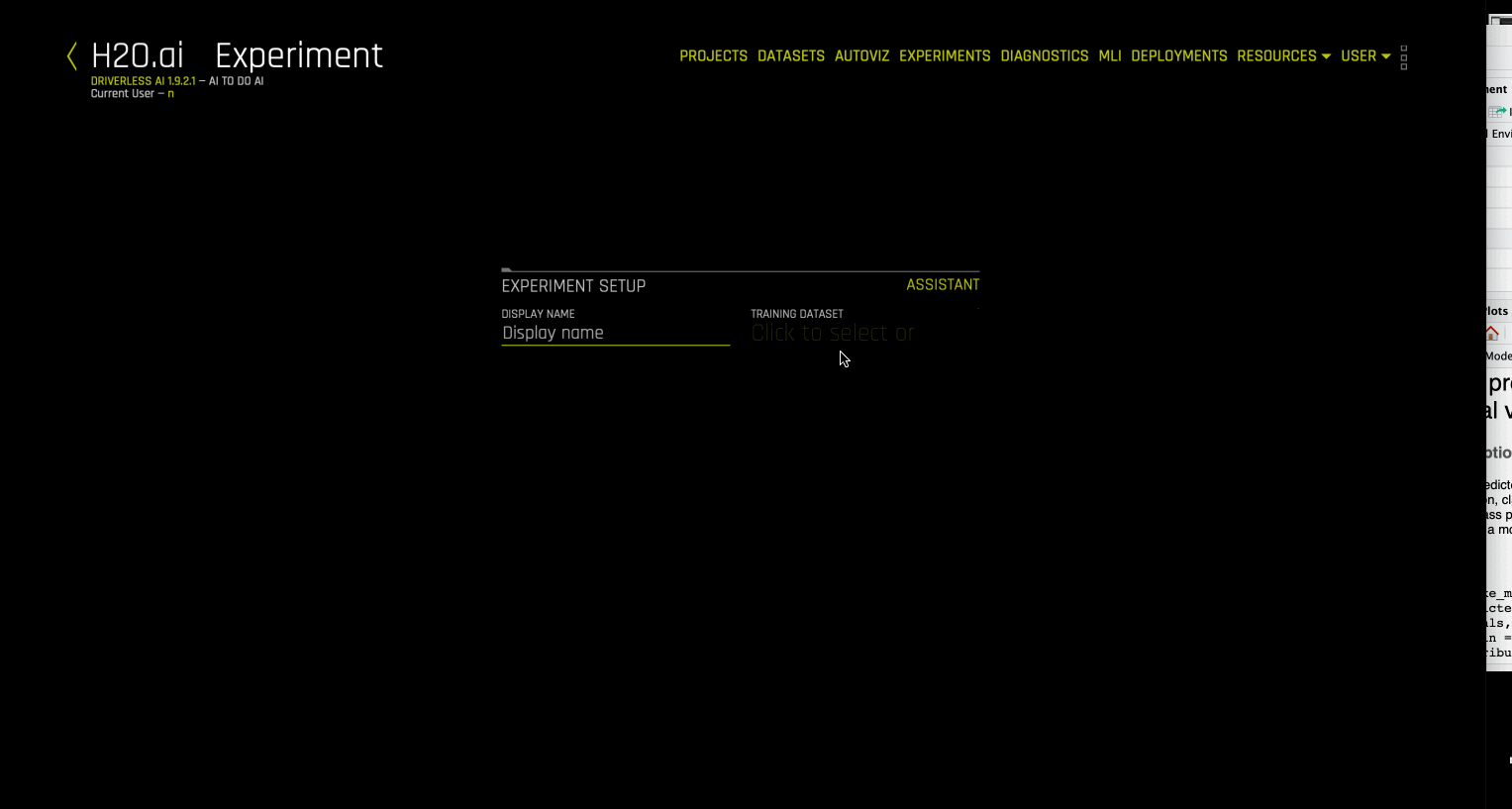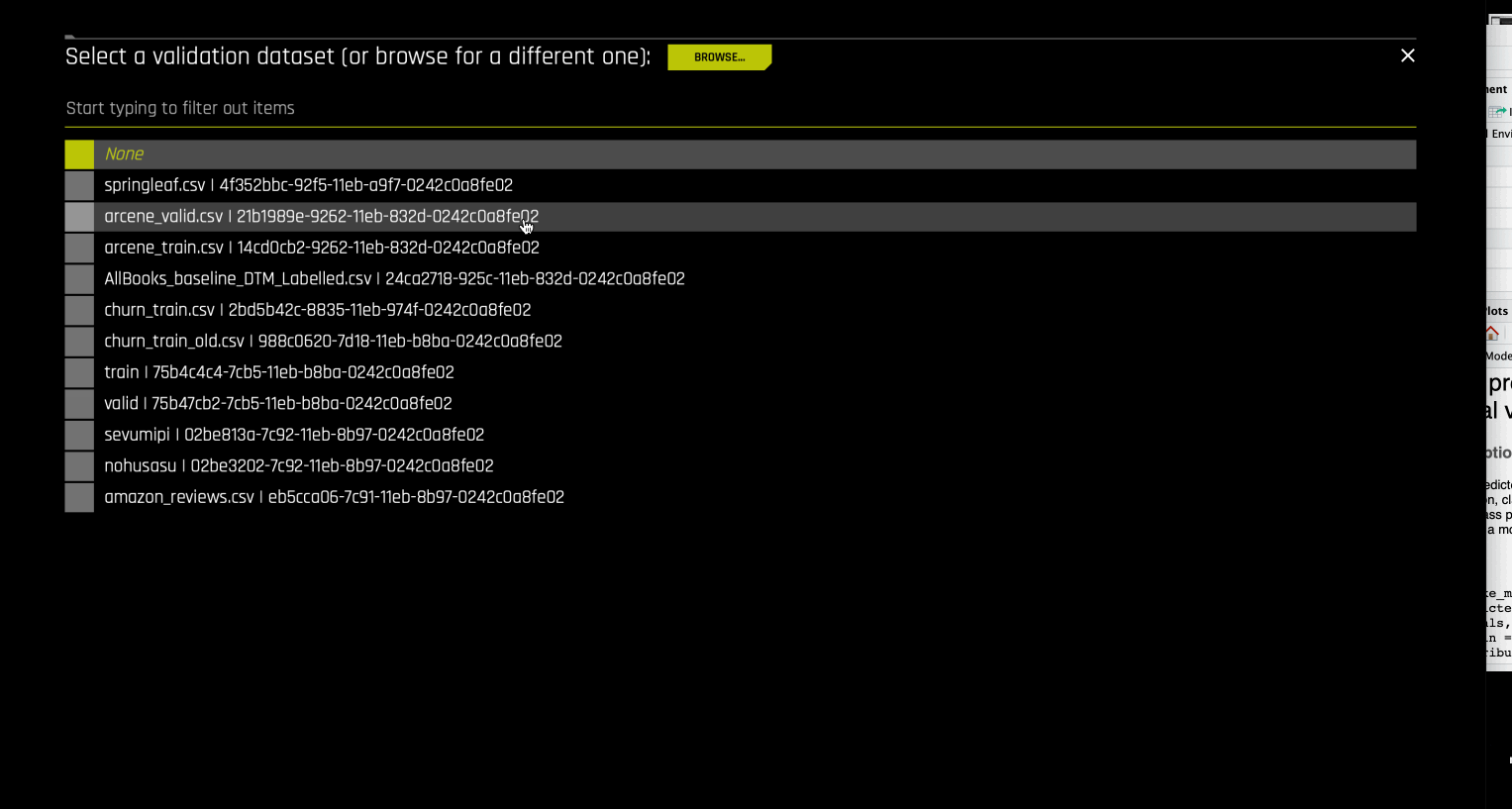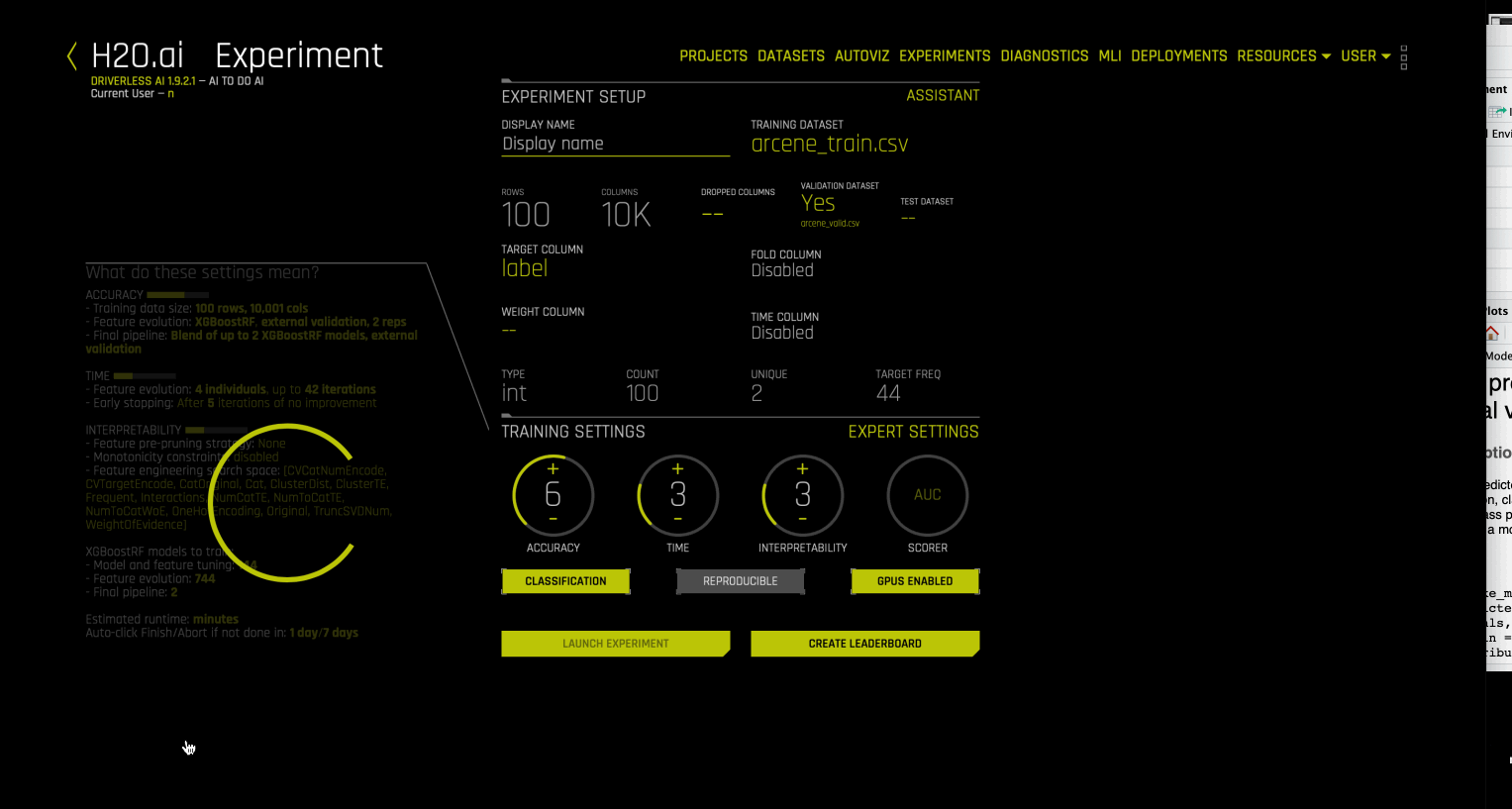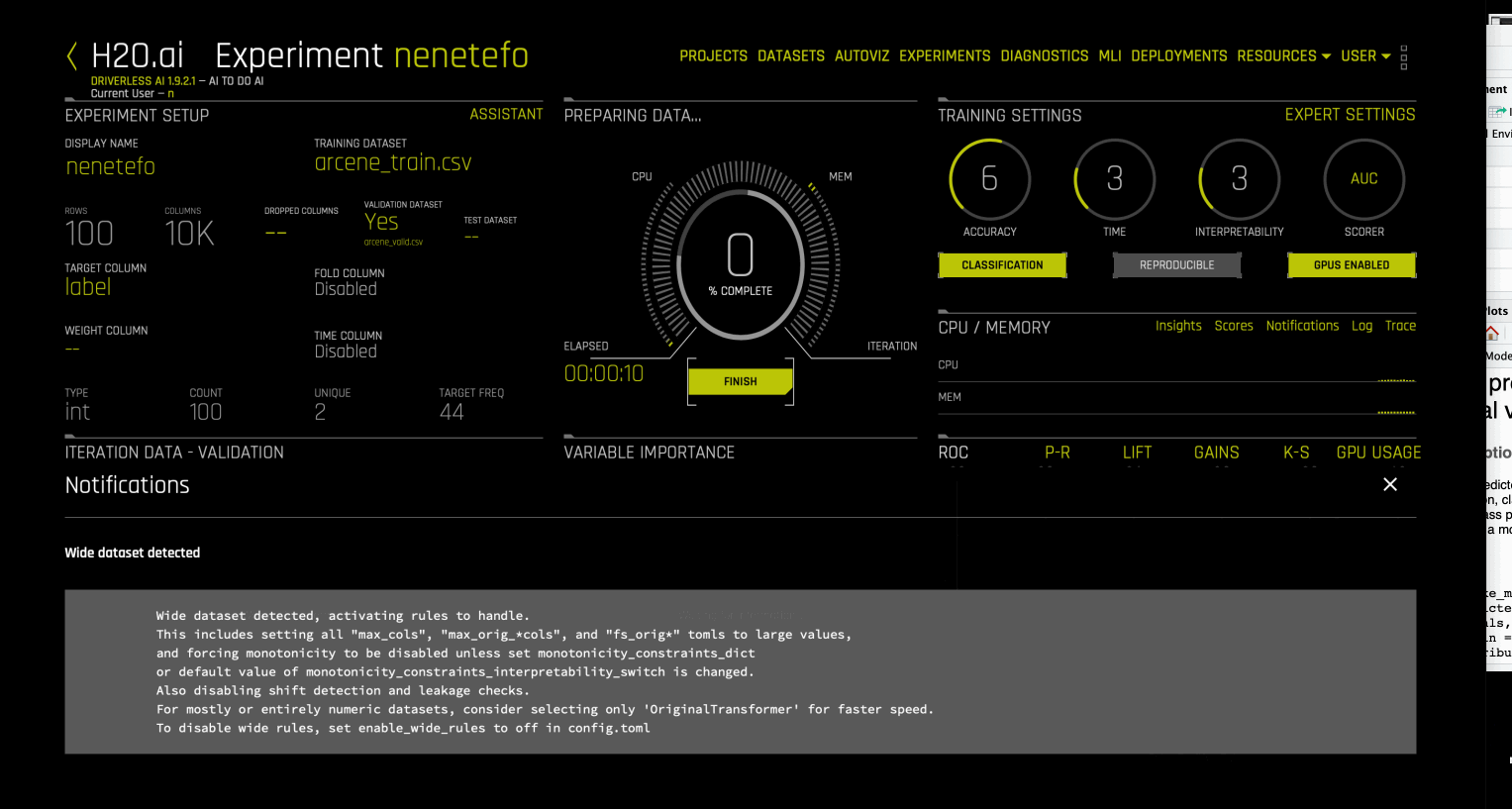
Driverless AI에서는 칼럼 수 > 행 수 이면 대량 데이터 세트로 간주됩니다. 이러한 데이터 세트에 대한 실험을 실행할 때, Driverless AI는 최대 허용 특성 수(특성 진화 및 선택을 위해 선택할 수 있는)에 대한 제한을 크게 확장하는 enables wide rules(광범위한 규칙을 자동으로 활성화) 하고, 데이터 누출 및 시프트 감지, monotonicity constraints 조건, AutoDoc, 파이프라인 시각화 생성과 같은 특정 검사를 비활성화합니다. 또한 XGBoost Random Forest 모델의 모델링을 활성화하므로, 행 수가 적고 광범위한 데이터 세트에서 과적합을 방지할 수 있습니다. enable_wide_rules 를 참조하십시오.
대량의 광범위한 데이터 세트로 인해 대형 모델은 GPU에 메모리가 부족할 수 있습니다. XGBoost models (GBM, GLM, RF, DART)에 대한 이러한 모델 장애를 방지하기 위해, Driverless AI는 특성을 선택하는 하위 모델을 구축함으로써(반복 포함) 자동 특성 선택을 수행하여 protection against GPU OOM 을 제공합니다. 그러면 최종 모델은 GPU에 적합하게 중요한 특성에 기반하여 구축됩니다. 자세한 내용은 allow_reduce_features_when_failure 를 참조하십시오.
다음은 quick model run on a wide dataset(대량 데이터 세트에서 빠른 모델 실행) 에 대한 config.toml 설정의 예입니다.
이는 빠른 최종 모델 을 얻기 위해 유전 알고리즘/튜닝/진화를 비활성화 합니다. 또한 행이 적고 광범위한 데이터에서 과적합을 방지하는 데 가장 좋은(XGBoost) Random Forest를 사용합니다. 다음 구성 설정을 상세 설정 GUI TOML에 복사/붙여넣기하여 이 모델을 실행할 수 있습니다.
num_as_cat=false
target_transformer="identity_noclip"
included_models=["XGBoostRFModel"]
included_transformers=["OriginalTransformer"]
fixed_ensemble_level=1
make_mojo_scoring_pipeline="off"
make_pipeline_visualization="off"
n_estimators_list_no_early_stopping=[200]
fixed_num_folds=2
enable_genetic_algorithm="off"
max_max_bin=128
reduce_repeats_when_failure=1
Reduce_repeats_when_failure 는 반복을 제어하며 기본값은 1입니다. 값이 3 이상이면 시간이 더 오래 걸릴 수 있지만, 최종 모델을 구축하는 데 가장 적합한 특성을 찾아 accuracy를 높일 수 있습니다. N_estimators_list_no_early_stopping 도 조정해야 합니다. 200으로 시작하면 되지만, 더 높게 시도하여 모델의 accuracy가 향상되는지 확인합니다. 또한, GPU를 늘린 경우 GPU의 효율성을 높이기 위해 fixed_num_folds 를 GPU의 수만큼으로 변경하는 것도 좋습니다. 그러면 모델의 일반화 기능을 개선하는 데 도움이 됩니다.
기본적으로 자동으로 설정되어 있으면 누출 및 이동 감지는 비활성화됩니다.