Time Series 모범 사례¶
이 문서에서는 Driverless AI에서 time series 실험을 실행하는 모범 사례를 설명합니다.
데이터 준비¶
time series 사용 사례의 목표는 과거 데이터를 사용한 예측입니다. 예측에 사용되는 데이터의 형식을 지정하는 방식은 이 예측 결과의 용도에 따라 다릅니다. 예측용 데이터의 형식을 지정하려면 특정 기간 동안 관심 있는 각 그룹의 데이터를 집계합니다.
다음은 S&P 500에서 거래되는 주식의 양을 예측하는 세 가지 사용 사례입니다. 각 사용 사례는 데이터 형식을 결정하는 고유한 시나리오를 제공합니다. 원시 데이터는 다음과 같습니다.
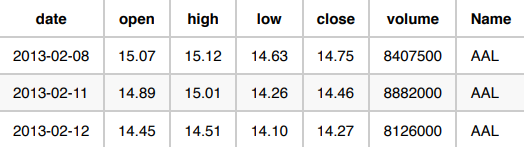
사용 사례 1: 내일 주식의 총 거래량을 예측합니다.
이 사용 사례에서는 데이터가 이미
Name및 날짜별로 집계되어 있으므로 그대로 둡니다.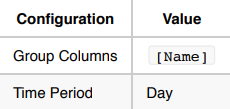
사용 사례 2: 다음 달 주식의 총 거래량을 예측합니다.
이 사용 사례에서는
Name별과 월별로 총 거래량을 계산합니다.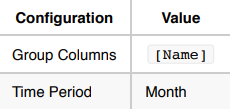
사용 사례 3: 내년도 전체 S&P 500 주식의 총 거래량을 예측합니다.
이 사용 사례에서는 1년 동안의 모든 S&P 500 주식의 총 거래량을 계산합니다.

실험 설정¶
사용 사례에 맞게 데이터 형식을 지정하면 실험 설정을 시작할 수 있습니다.

Time Series 설정¶
시간 열을 제공하면 time series별 구성을 입력하라는 메시지가 표시됩니다.

시간 그룹 열: 데이터를 개별 time series로 분리하는 열. 이 예에서는 주식당 하나의 time series가 있으므로(열: Name) Name이 시간 그룹 열로 선택됩니다.
Unavailable Columns at Prediction Time(예측 시 사용할 수 없는 열): 예측 시 알려지지 않은 열. S&P 500 데이터 예시에서 독립 변수는
open,high,low,close입니다. 사전에 알려지지 않은 모든 변수는 예측 시 사용할 수 없는 열로 표시되어야 합니다. Driverless AI는 표시된 독립 변수에 대해서만 과거 값을 사용합니다.Forecast Horizon: 얼마나 먼 미래를 예측하려는지 나타내는 구성.
Gap: 학습 데이터와 예측을 시작할 시점 사이에 gap이 있는지 여부를 지정합니다. 예를 들어 월요일에 수요일과 목요일의 주식 거래량을 예측하려면 다음 구성을 제공해야 합니다.
Forecast Horizon = 2일
Gap = 1일
첫 번째 사용 사례(내일 주식 거래량 예측)의 경우 time series별 구성은 다음과 같이 설정됩니다.

검증 및 테스팅¶
time series 사용 사례의 경우, 항상 최신 데이터에서 모델을 검증하고 테스트합니다. Driverless AI에서는 기본적으로 검증 데이터가 자동으로 생성되며 이 데이터를 사용해 각 모델의 성능을 평가합니다.
테스트 데이터는 사용자가 제공하는 선택적 데이터 세트입니다. 테스트 데이터에 우발적인 과적합이 발생하는 것을 방지하기 위해, 최종 모델이 선택되기 전에는 Driverless AI가 테스트 데이터를 사용하지 않습니다.
Validation Data(검증 데이터)
검증 데이터는 Driverless AI가 롤링 윈도우 방식을 사용하여 자동으로 생성합니다. 검증 데이터에 포함된 시간 단위의 수는 forecast horizon 및 gap 구성과 일치합니다. 다음 날을 예측하려면 검증 데이터를 하루 동안의 데이터로 구성해야 합니다. 향후 5일을 예측하려면 검증 데이터를 5일 동안의 데이터로 구성해야 합니다. 첫 번째 사용 사례에서, Driverless AI는 검증 데이터가 항상 하루 동안의 데이터로 구성되는 분할을 내부적으로 생성합니다.

모델 검증에 사용되는 총 데이터 포인트의 수는 다음과 같습니다.
Time Group Column의 수가 적고 특정 주식의 거래량만 예측하려는 사용 사례에서는 검증 데이터가 매우 작아질 수 있습니다. 이러한 경우에는 검증 데이터가 과적합을 방지할 수 있을 정도로 커야 합니다. 일반적으로 두 가지 방법으로 수행할 수 있습니다. 즉, Driverless AI가 수행하는 검증 분할의 수를 늘리거나 데이터 세트에서 Time Group Column의 수를 늘리는 것입니다. Time Series 탭의 상세 설정에서 Driverless AI가 수행하는 검증 분할 수를 증가시킬 수 있습니다.
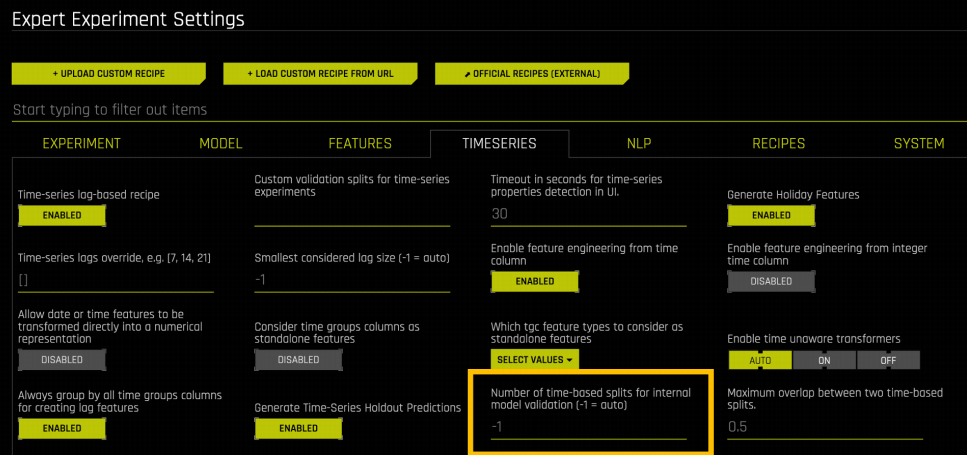
기본적으로 Driverless AI는 accuracy 설정에 따라 검증 분할 수를 자동으로 결정합니다(accuracy가 높을수록 검증 분할 수가 늘어남). 각 검증 분할의 행 수가 적다는 것을 알고 있는 경우(즉, 적은 수의 Time Group Column 및/또는 작은 Forecast Horizon) 이 값을 더 큰 수로 재정의할 수 있습니다.
이를 재정의하면 실험 미리보기에 변경 사항이 반영되어 있습니다. 다음 실험에서는 상세 설정 패널에서 검증 분할 수가 20개로 증가했습니다. 이 변경 사항은 실험 미리보기에 반영됩니다.

작은 검증 데이터를 방지하는 또 다른 방법은 더 많은 Time Group Columns를 포함시키는 것입니다. 각 주식의 거래량을 개별적으로 예측하는 대신 모든 주식에 대한 데이터를 결합하여 단일 실험을 실행할 수 있습니다.
Test Data(테스트 데이터)
테스트 데이터는 사용자가 제공하는 선택적 데이터 세트입니다. Driverless AI는 이 데이터 세트에서 최종 모델의 성능을 자동으로 계산하지만, 모델 선택에는 사용하지 않습니다. 테스트 데이터 세트는 Forecast Horizon보다 클 수 있습니다. 첫 번째 사용 사례는 다음 날의 주식 거래량을 예측하는 것입니다. 그러나 Driverless AI에 한 달의 테스트 데이터를 제공할 수 있습니다. 이 시나리오에서 Driverless AI는 모델이 한 달 동안 다음 날의 주식 거래량을 예측하는 방식을 평가합니다.
scorer¶
scorer는 Driverless AI가 각 모델의 성공을 평가하는 방법을 결정합니다.
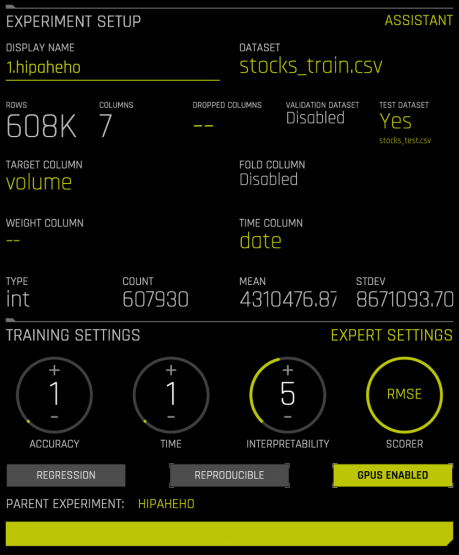
다음은 많이 사용되는 scorer와 각 scorer의 탁월한 사용 사례에 대한 정보입니다.
MLI를 사용한 모델 해석¶
실험이 완료된 후 Interpret this Model을 클릭하면 검증 및 테스트 데이터에서 수행된 최종 모델의 성능에 관한 자세한 정보를 수집할 수 있습니다.
Model Interpretability 모듈의 첫 번째 그래프는 검증 및 테스트 데이터의 각 날짜에 대한 오류를 보여줍니다.
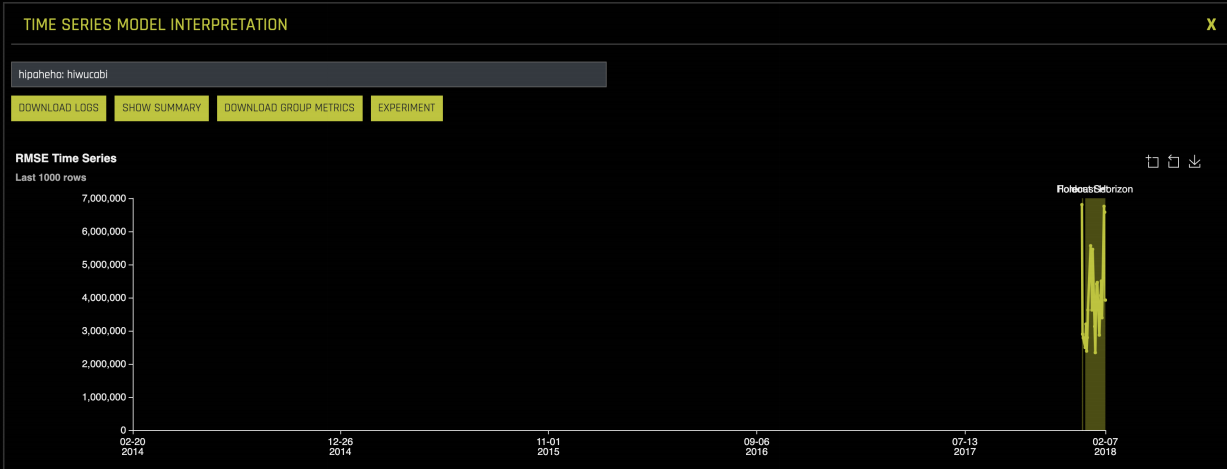
오류가 매우 높은 그룹과 오류가 매우 낮은 그룹도 볼 수 있습니다.
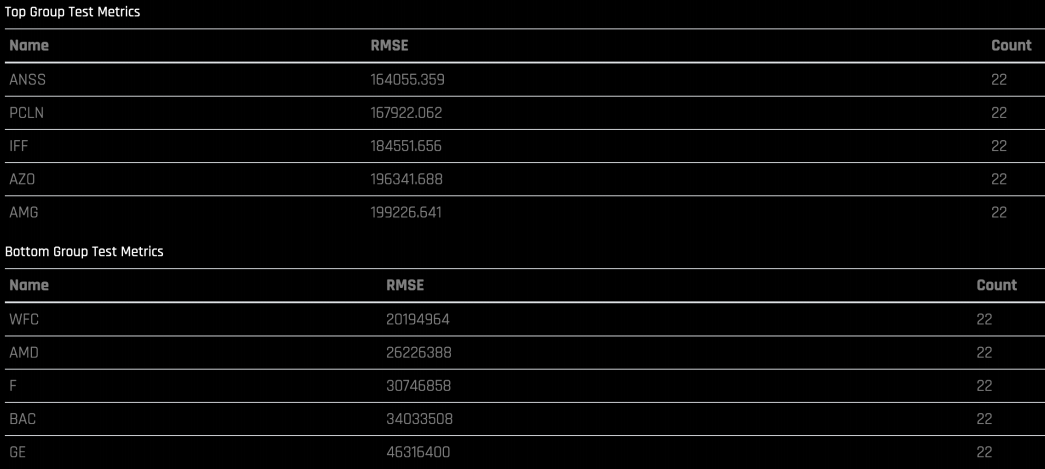
특정 그룹을 검색하면 실제 time series와 예측된 내용을 비교하여 볼 수 있습니다.
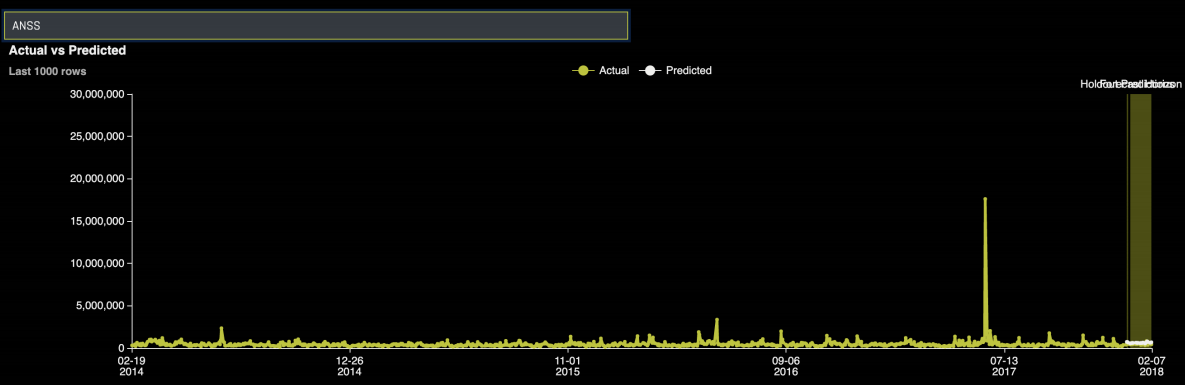
특정 예측 포인트를 클릭하면 해당 포인트에 대한 Shapley 기여도를 확인할 수 있습니다. Shapley 기여도는 각 예측 변수가 해당 포인트에 대한 예측에 미치는 영향을 나타냅니다.

Shapley 기여도는 선택한 날짜에 대한 각 예측 변수의 강도와 방향을 보여줍니다.
스코어링¶
Driverless AI는 전통적인 기계학습 모델(GLM, GBM, Random Forest 등)을 구축하기 때문에 예측을 생성하려면 채점할 레코드가 필요합니다. 모델을 사용하여 예측하려는 경우 세 가지 스코어링 옵션이 있습니다.
Driverless AI 사용
Python Scoring Pipeline
Driverless AI로부터 독립적
스코어링 기능이 내장된 Python whl
MOJO Scoring Pipeline
Driverless AI로부터 독립적
Java 런타임 또는 C++ 런타임
모델을 사용하여 Forecast Horizon 이외의 채점을 하려면, Driverless AI 또는 Python Scoring Pipeline만 스코어링에 사용할 수 있습니다. 즉, 2018-02-07까지의 학습 데이터를 Driverless AI에 제공하고 익일 거래량을 예측하는 모델을 빌드하도록 요청하면 MOJO는 2018-02-08에 대한 채점에만 사용할 수 있습니다.
MOJO는 상태를 저장하지 않습니다(stateless). 단일 레코드를 사용하여 예측을 제공합니다. 상태 비저장성이기 때문에 학습 데이터에서 저장된 정보(과거 행동 등)만 사용할 수 있습니다. Driverless AI 모델이 전날의 주식 거래량이 매우 중요하다는 것을 보여 주고, MOJO를 사용하여 2018-02-08 이후의 스코어링을 시작하면 전날 주식 거래량에 대한 정보가 더 이상 없습니다.
Predicting Within Forecast Horizon
Forecast Horizon 내에서 예측하려는 경우, Driverless AI, Python Scoring Pipeline 또는 MOJO Scoring Pipeline에 예측하려는 레코드를 제공할 수 있습니다. 예를 들면 다음과 같습니다.
학습 데이터는 2018-01-05 금요일에 종료되며 다음 영업일의 주식 거래량을 예측하려고 합니다. 따라서 Forecast Horizon에 2018-01-08 월요일이 있습니다. 2018-01-08의 Stock: AAL에 대한 주식 거래량을 예측하려면 스코어링 방법과 함께 다음 데이터를 제공합니다.

출력은 거래량 예측입니다.
Note: 예측 시점에 open, high, low, close를 알지 못하므로 NA로 표시됩니다.
Predicting Outside Forecast Horizon
이제 모델을 사용하여 2018-01-08 이후를 예측하려는 경우, 상태 비저장성 MOJO는 Forecast Horizon 외에서는 사용할 수 없으므로 Driverless AI 또는 Python Scoring Pipeline만 채점에 사용할 수 있습니다.
Forecast Horizon 이외에서 예측하려면 학습 데이터가 종료된 후 예측하려는 날짜까지 발생한 모든 정보를 모델에 제공해야 합니다. 2018-01-09를 예측하려는 경우 2018-01-08에 발생한 일을 모델에 알려야 합니다(이 날짜는 학습 데이터에 없었기 때문에 Driverless AI는 이 날짜에 대한 정보를 알지 못합니다).
2018-01-09에 대한 채점을 하려면 Driverless AI에 다음 데이터를 제공합니다.
그러면 모델이 다음 두 가지 예측값을 반환합니다. 2018-01-08에 대한 예측과 2018-01-09에 대한 예측(관심 있는 예측).
기타 방법¶
IID 레시피 사용¶
예측 사용 사례가 있더라도 Time Series 레시피 없이 실험을 빌드하는 것이 유용한 경우도 있습니다. Time Series 레시피는 데이터 지연에 크게 의존하므로 과거 행동이 예측 가능한 경우에 가장 효과적입니다. 강력한 일시적 추세가 없는 사용 사례인 경우, Time Series 레시피 없이 Driverless AI를 사용하는 것이 효과적일 수 있습니다. 이러한 방식으로 수행하려면 실험을 설정할 때 Time Column을 제공하지 않으면 됩니다.
Notes:
Time Series를 사용하지 않고 모델을 사용하려면, 시간이 지난 테스트 데이터 세트를 제공해야 합니다.
기본적으로 Driverless AI는 예측 사용 사례가 있는 경우 과적합이 발생할 수 있는 무작위 교차 검증을 수행합니다.
Time Column을 제공하지 않으면 예측 시점에 사용할 수 없는 열을 Driverless AI에게 알릴 수 없습니다. 즉, 사전에 데이터를 사전에 지연시켜야 합니다.
Lagging Data in Advance(데이터의 사전 지연)
이 사용 사례의 경우 open, close, low, high 예측 변수를 미리 알 수 없습니다. Time Series 레시피를 설정하지 않고 Driverless AI를 사용하려는 경우, 이러한 변수를 수동으로 지연시켜야 전날의 정보로 구성됩니다.
원본 데이터
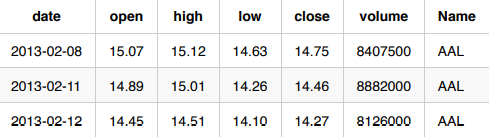
Driverless AI IID에 대해 지연됨

Driverless AI의 Data Recipe 옵션을 사용하면 이 작업을 수행할 수 있습니다. 이를 위해서는 Details of the Dataset를 클릭하여 Modify by Recipe를 선택합니다.

수정 레시피를 업로드하거나 Live Code를 사용할 수 있습니다. Live Code를 선택하면 코드 미리보기와 데이터 세트 수정 방법을 볼 수 있습니다.

다음은 이 예시에 사용된 코드입니다.
X # X is your input dt.Frame
X = X.to_pandas() # convert to pandas
# Calculate lags
lag_cols = ["open", "close", "low", "high"] # columns to lag
time_col = "date"
time_group_cols = ["Name"]
X = X.set_index([time_col] + time_group_cols)
lagged_data = X.loc[:, lag_cols].groupby(level=time_group_cols).shift(1)
# Join lags to original data
X = X.join(lagged_data.rename(columns=lambda x: x +"_lag"))
return X