Tutorial 8: With an Extractor, transform unstructured document content into structured JSON data
Overview
This tutorial demonstrates how to utilize Extractors in Enterprise h2oGPTe to convert unstructured document content into structured JSON data. While documents can contain valuable information, their unstructured nature often makes it challenging to analyze efficiently. Extractors address this challenge by transforming the content of these documents into structured formats that can be readily utilized by individuals and applications requiring organized data.
In this tutorial, we will illustrate how Extractors function by extracting specific pieces of information from Alphabet's Form 10-K.
Objective
- Learn how to create and configure an Extractor in Enterprise h2oGPTe to transform unstructured document content into a structured JSON format.
Prerequisites
- Complete the following tutorial: Tutorial 1: A quick introduction to Enterprise h2oGPTe.
- Download the following Form 10-K from Alphabet: Form 10-K (goog-10-k-2023.pdf).
Step 1: Discuss Extractors
Extractors, defined by JSON schemas, play an important role in document AI by converting unstructured document content into structured, actionable JSON data. They allow users to retrieve information from various document types—such as CVs, invoices, Form 10-Ks, or scanned images—without requiring complex setups or extensive annotations.
To use an Extractor, first identify the specific information you want to extract from a document. This information is specified in a JSON schema, which is part of an Extractor and acts as a blueprint for the data, detailing the fields and data types you wish to capture. Once you define this schema, you can apply the Extractor to the document, retrieving the desired information in a structured JSON format. This structured data is useful for individuals and applications that require organized information.
Step 2: Create a Collection
To apply an Extractor to a document, you must first add the document to a Collection. The document we will use for this tutorial will be Alphabet's Form 10-K. A Form 10-K is a comprehensive annual report that publicly traded companies in the United States must file with the Securities and Exchange Commission (SEC). It provides a detailed overview of their financial performance, operations, and risks. This document includes audited financial statements, management's discussion and analysis, and information about the company's business activities, helping investors make informed decisions.
Let's create a Collection with Alphabet's Form 10-K.
- In the Enterprise h2oGPTe navigation menu, click Collections.
- Click + New collection.
- In the Collection name box, enter the following:
Tutorial 8
- Click Browse Files.
- Upload Alphabet's Form 10-K (downloaded as goog-10-k-2023.pdf).
- Click + Create.
Enterprise h2oGPTe creates a Job to upload the document. After a successful upload, the uploaded document can be located in the Documents table.
Step 3: Create an Extractor
Let's create an Extractor that will be in charge of extracting the following metrics from Alphabet's Form 10-K:
- Revenue growth rate
- Net profit margin
- Current ratio
- Return on equity
- Debt-to-equity ratio
- In the Documents table, click goog-10-k-2023.
- Click Document AI to open the Documet AI section.
- Click Summarize, Extract, Process.
- In the LLM list, select an LLM.
note
We will select the following LLM for this tutorial: deepseek-ai/DeepSeek-R1-shadeform.
- In the Output mode list, select JSON schema.
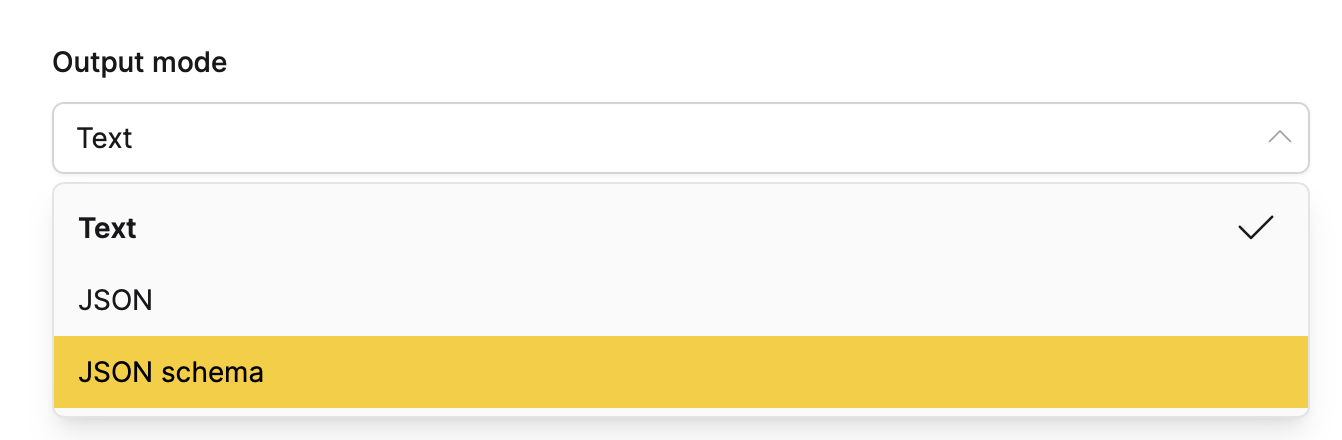
- In the JSON Schema box, enter:
{"type":"object","properties":{"revenueGrowthRate":{"type":"number","description":"The growth rate of revenue."},"netProfitMargin":{"type":"number","description":"The company's profit margin."},"currentRatio":{"type":"number","description":"The company's liquidity position."},"returnOnEquity":{"type":"number","description":"The efficiency in generating profit from equity."},"debtToEquityRatio":{"type":"number","description":"The proportion of debt to shareholders' equity."}},"required":["revenueGrowthRate","netProfitMargin","currentRatio","returnOnEquity","debtToEquityRatio"]}note
The JSON schema does not require exact label names to align perfectly with document fields, as the collection's large language model (LLM) can interpret and infer label purposes based on context. This allows the model to understand and map various label names, even if there are minor differences in terminology, to their intended data points. Just as a human might deduce what a field intends to capture, the LLM uses its interpretive capability to accurately match schema labels with relevant content, even when exact terms differ.
- Click Summarize, Extract, Process.
note
Enterprise h2oGPTe creates a Job to extract the appropriate information.
Step 4: View extracted information
Once the Extractor has finished, you can access the extracted information by following the following steps (the Extractor is considered completed when its Job is finished):
- In the Document AI section, under Recent results, click the card titled deepseek-ai/DeepSeek-R1-shadeform.
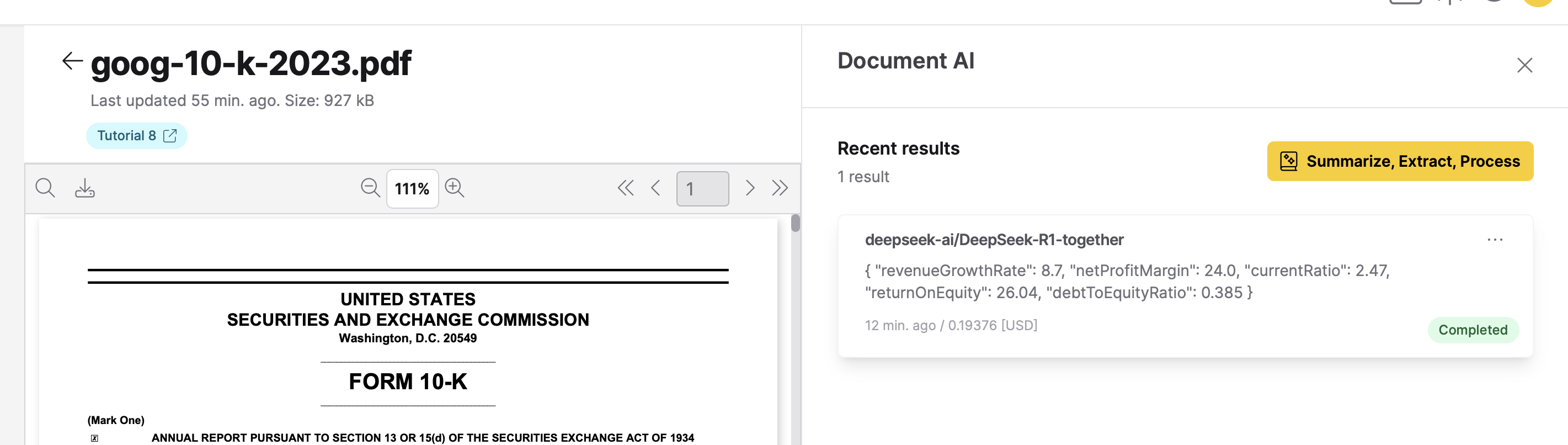
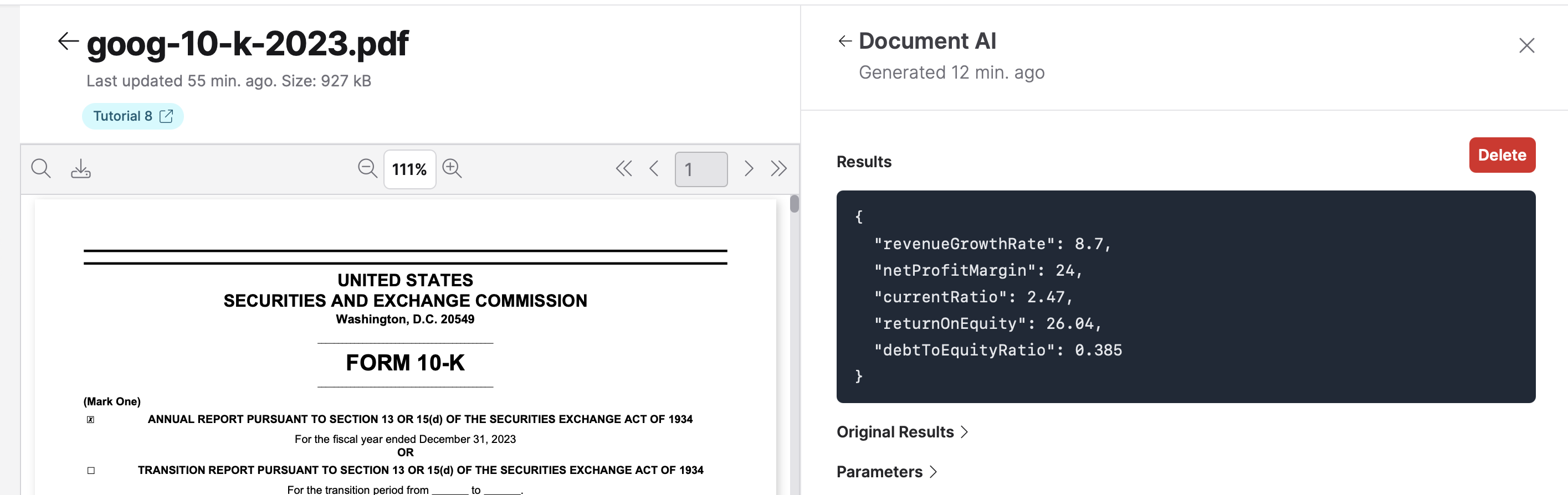
Summary
This tutorial illustrated how Extractors can efficiently organize and extract information from a document, simplifying the process for individuals and applications to interact with a document's data in a structured manner.
- Submit and view feedback for this page
- Send feedback about Enterprise h2oGPTe to cloud-feedback@h2o.ai