Task 6: Feature engineering
In this task, we will explore Feature Engineering.
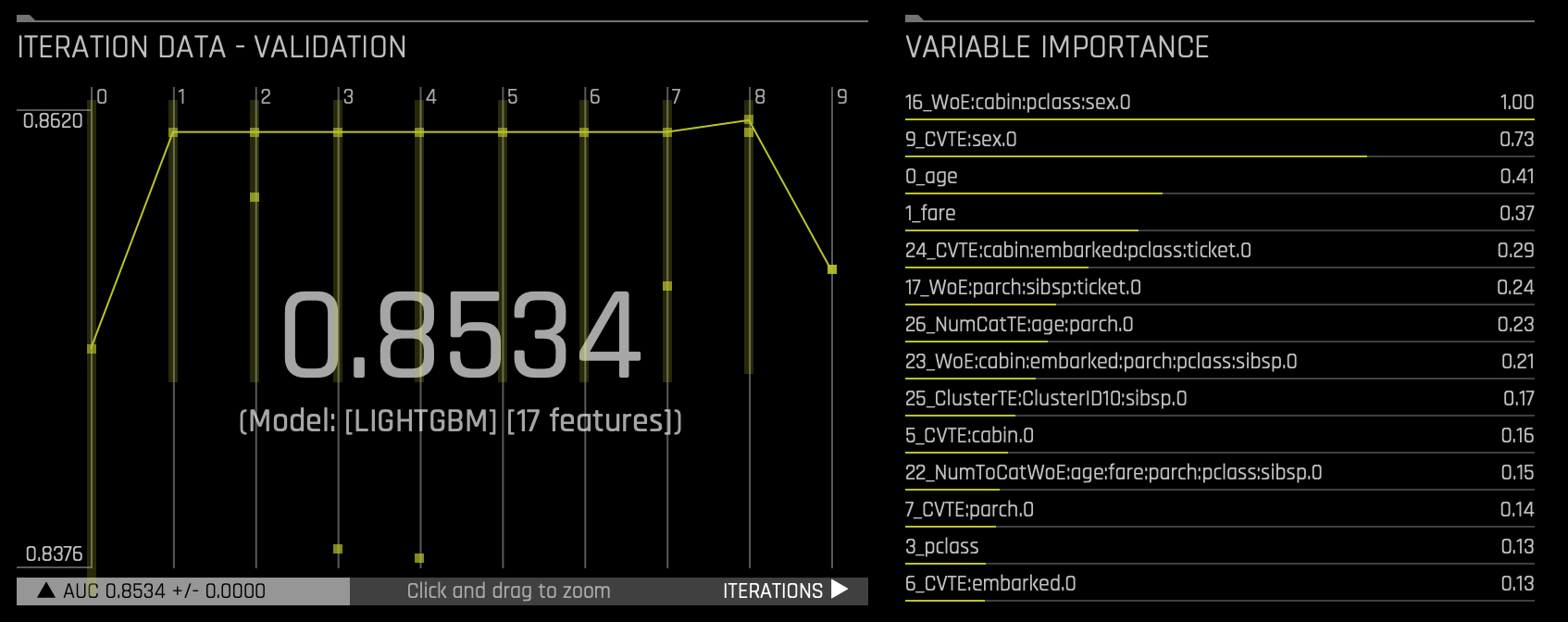
Driverless AI performs feature engineering on the dataset to determine the optimal representation of the data. Various stages of the features appear throughout the iteration of the data. These can be viewed by hovering over points on the "ITERATION DATA - VALIDATION" Graph and seeing the updates on the Variable Importance section.
This task is optional. Its objective is to find and note the transformed features that affect the DAI model you created and understand how they have been transformed to optimize the model. However, if you feel that exploring this is not neccessary for you right now, you can skip this task and move directly to Task 7 to explore the experiment results instead.
Transformations in Driverless AI are applied to columns in the data. The transformers create the engineered features in experiments. Driverless AI provides a number of transformers. The following transformers are available for regression and classification (multiclass and binary) experiments:
- Numeric Transformers
- Categorical Transformers
- Time and Date Transformers
- Time Series Transformers
- NLP (text) Transformers
- Image Transformers
Below are just some of the transformers found in our experiment:
Look at some of the variables in the following section: Variable Importance. Note that some of the variables start with
_CVTE(_CVTargetEncode) followed by the dataset's column name. Other variables might also begin with_NumToCatTEor_WoEdepending on the experiment you run. These are the new, high-value features for our training dataset.These transformations are created with the following transformers:
- Cross Validation Target Encoding Transformer:
_CVTE- The Cross Validation Target Encoding Transformer calculates the mean of the response column for each value in a categorical column and uses this as a new feature. Cross Validation is used to calculate mean response to prevent overfitting.
- Weight of Evidence :
_WoE- The Weight of Evidence Transformer calculates Weight of Evidence for each value in categorical column(s). The Weight of Evidence is used as a new feature. Weight of Evidence measures the "strength" of a grouping for separating good and bad risk and is calculated by taking the log of the ratio of distributions for a binary response column. This only works with a binary target variable. The likelihood needs to be created within a stratified kfold if a fit_transform method is used.
- Numeric to Categorical Target Encoding Transformer:
_NumToCatTE- The Numeric to Categorical Target Encoding Transformer converts numeric columns to categoricals by binning and then calculates the mean of the response column for each group. The mean of the response for the bin is used as a new feature. Cross Validation is used to calculate mean response to prevent overfitting.
- Cross Validation Target Encoding Transformer:
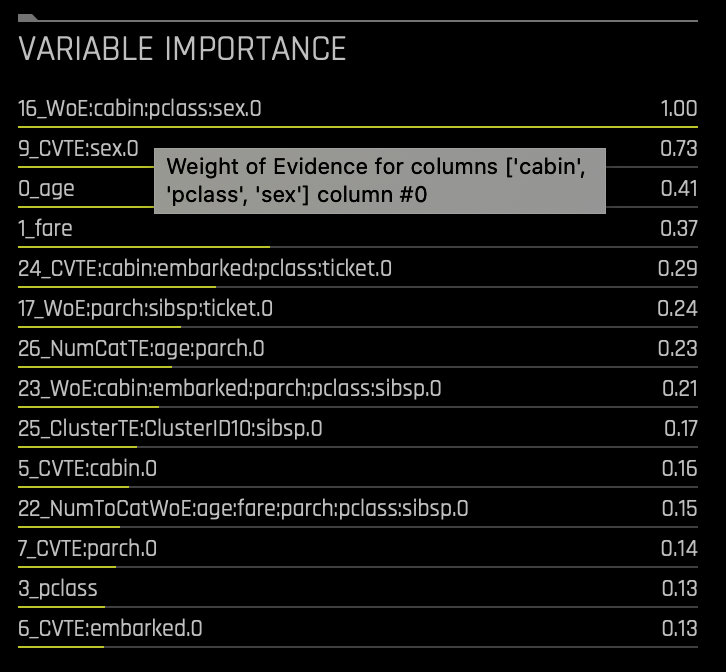
- Hover over any of the variables under Variable Importance to get a simple explanation of the transformer used, as seen in the image below:
The complete list of features used in the final model is available in the Experiment Summary and Logs. The experiment summary also provides a list of the original features and their estimated feature importance. In other words, the experiment summary and logs include the transformations that Driverless AI applied to our titanic experiment.
To access this summary and logs, don't forget that you can click on the following option located in the Status Complete section: DOWNLOAD SUMMARY & LOGS
For more information about Driverless AI Transformations, see the H2O Driverless AI documentation.
- Submit and view feedback for this page
- Send feedback about H2O Driverless AI | Tutorials to cloud-feedback@h2o.ai