Using models in production: REST Endpoint
Execute the server
Using the properties file to define specific runtime settings is the easiest way to run the server.
Add license
An H2O Driverless AI (DAI) license is required to score. Specify the license on the command line using one of the following methods:
- Environment variable
DRIVERLESS_AI_LICENSE_FILE: A location of the file with a license. - Environment variable
DRIVERLESS_AI_LICENSE_KEY: The license key. - JVM system property (
-Doption)ai.h2o.mojos.runtime.license.file: The location of license file. - JVM system property (
-Doption)ai.h2o.mojos.runtime.license.key: The license key. - Classpath: The license is loaded from resource called
/license.sig. The default resource name can be changed via system propertyai.h2o.mojos.runtime.license.filename.
Use a properties file
The server reads its settings from a properties file specified in the
propertiesfilename command-line argument. If this parameter is not provided, the server uses the default file name H2OaiRestServer.properties.
If the properties file is unavailable, the server uses the built-in defaults, as documented in the parameters section.
Example override:
The following example causes the server to use the settings in the production.properties file:
-Dpropertiesfilename =production.properties
Server parameters as arguments
If needed, the parameters in the properties file can be specified on the command line using -D arguments. This approach allows you to bypass the properties file, with all parameters provided via the command line.
Example override:
To set the ModelDirectory to a different location, use the following command-line argument:
-DModelDirectory=/mnt/prod/models/
Override ordering
Parameters are prioritized in the following order:
- Properties file
- Command line (
-D) - Server defaults
Use case example
If you want a common properties file for all instances but need different model directories for business isolation:
- Create a properties file, but comment out the
ModelDirectorysetting. - Add
-DModelDirectory=to the command line, specifying the location for each instance.
At runtime, the server will use the parameters from the properties file for common settings and the -D command-line argument for ModelDirectory.
Command line
The server requires only a few command line settings:
java -Xms4g -Xmx4g -jar ai.h2o.mojos.jar
Memory settings
It's recommended to set the -Xms (minimum) and -Xmx (maximum) memory for the process. The -Xmx should not exceed 75% of the available physical memory.
Server overrides
The server application accepts most Spring settings after the .jar parameter on the command line.
A few examples that are common to set:
| Server Parameter | Definition |
|---|---|
--spring.servlet.multipart.max-file-size=50MB | Maximum file size for upload scoring |
--spring.servlet.multipart.max-request-size=50MB | Maximum request size for upload scoring |
--server.tomcat.max-threads=10 | Number of threads for scoring |
--server.tomcat.accesslog.enabled=true | Additional logging |
--server.port=9080 | Change the server listen port |
Service daemon
The following is an example of how to set up the server to start when the system boots and use Linux system commands to control its execution.
Start script
-
Create a script that the
rootuser can execute, for example,StartRestServer.sh:#!/bin/bash
echo starting H2O.ai Rest Server > /var/tmp/StartRestServer.out
java -jar /root/ai.h2o.mojos.jar >> /var/tmp/StartRestServer.out -
Correct the paths in the script to use absolute paths.
-
Ensure that the script is executable:
chmod a+x StartRestServer.sh
Service definition
Create a service definition for the REST server at /etc/systemd/system/H2OaiRestServer.service:
[Unit]
Description=H2O.ai REST Server for model serving
After=network.target
[Service]
Type=simple
ExecStart=/root/StartRestServer.sh
TimeoutStartSec=0
[Install]
WantedBy=default.target
Service commands
As root or with sudo, the following commands are available:
| Command | Usage |
|---|---|
systemctl daemon-reload | Load the service definition after it is created or edited. |
systemctl enable H2OaiRestServer | Enable the service to auto-start on the next reboot. |
systemctl start H2OaiRestServer | Manually start the server. |
systemctl stop H2OaiRestServer | Manually stop the server. |
Monitoring
Monitoring runtime and model performance is critical in production environments. Several server functions facilitate this task.
Management beans
Java Management Beans (JMX) can be enabled so that monitoring tools within the environment can collect runtime metrics. Tools such as JConsole, VisualVM, and commercial tools like New Relic and Splunk can use JMX to gather metrics.
Enable JMX
Add the following command-line parameters to the server and restart it:
-Dcom.sun.management.jmxremote.ssl=false-Dcom.sun.management.jmxremote.authenticate=false-Dcom.sun.management.jmxremote.port=8889
Reported metrics
| Name | Description |
|---|---|
| Algo | Algorithm used for H2O-3 models |
| Baseline | Population stability of the results |
| Category | Model category for H2O-3 models |
| Error_count | Number of scoring errors |
| Errror_msg | Last error message text ` |
| H2OVersion | Product version string |
| Invocation_count | Number of scoring requests |
| Latency | Last scoring latency in nanoseconds |
| Latency_ave | Average scoring latency |
| ModelVersion | Model UUID (if available) |
| PSI | Population stability of the results |
VisualVM example
When using VisualVM, the H2O.ai management bean will appear as follows: 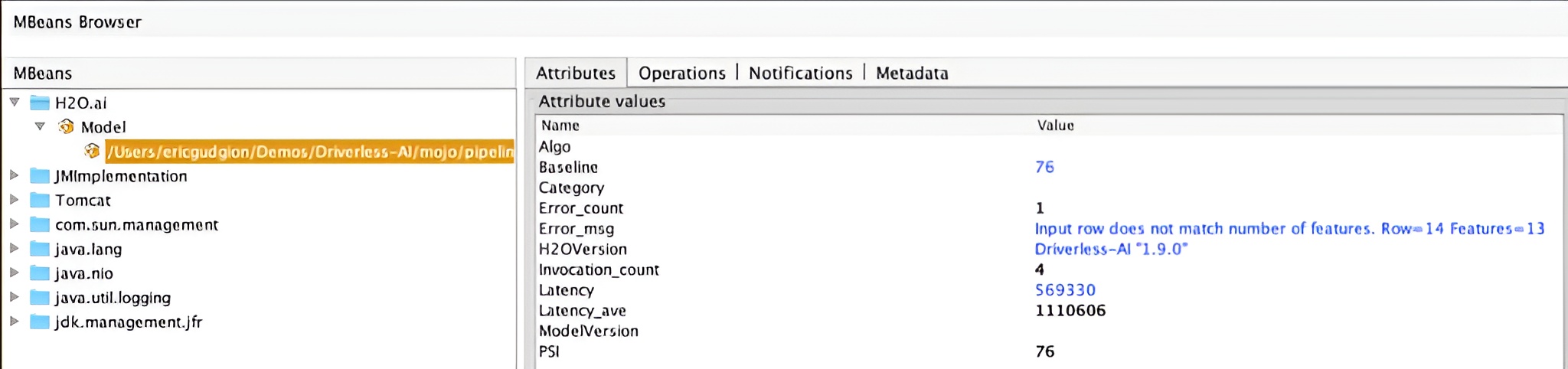
Notifications
Applications that register for notifications can receive alerts when errors occur during scoring.

Model Monitoring
If the H2O.ai Model Monitoring component is available, set the ModelMonitor = True option to create log records for that tool.
Monitoring URIs
The server provides specific URIs for monitoring details, all requiring Admin-level authentication:
| URI | Description |
|---|---|
/modeljmx | Java Management metrics via HTTP request |
/modelstats | Similar metrics to /modeljmx, but at the thread level |
/monitor | System, process, and thread status details |
Security
Securing the server is critical. The server and models should not be directly exposed to the internet but placed behind a firewall and IP routers for protection. Additional configuration can further secure the server.
User authentication
The server has two users with matching roles, Admin and Restuser, to control what functions each can perform.
Set passwords
Add the parameter -DsetPassword=true and start the server. You will be prompted to set passwords for the Default (restuser) and Admin users.
Please enter password to use for Default user aaaa
set the parameters in properties file as follows:
RestUser = h2o
RestPass = YWFhYWFhYQ==
Please enter password to use for Admin user eeee
AdminUser = h2oadmin
AdminPass = ZWVlZWVlZWU=
Authenticated URIs
The SecureEndPoint parameter defines the entry point where authentication is required. The default is /modelsecure**. If the parameter is changed to /**, then any request will require authentication.
If authentication is required:
- Web browser: A login panel will prompt you.
- REST API call: Pass a base64 encoded username and password.
| URI | Authenticated Role | Details |
|---|---|---|
/snowflakeconfig | Admin | Used to configure external functions |
/modelupload | Admin | Uploads a model to the server |
/modeljmx | Admin | Returns JMX metrics |
/modelstats | Admin | Returns thread-level metrics |
/monitor | Admin | Displays system-level metrics |
/modeldefence | Admin | Returns details about the model defense function |
/modeldelete | Admin | Deletes a model from the running server's memory |
/modelreload | Admin | Flushes all loaded models from memory |
/version | Admin | Displays version information about the runtime |
/modelsecure** | User | Full authenticated access is required |
Enabling HTTPS
- To enable HTTPS, follow these steps to create a JKS keystore:
keytool -genkeypair -alias H2OaiRestServer -keyalg RSA -keysize 2048 -keystore keystore.jks -
validity 3650 -storepass h2oh2o
keytool -importkeystore -srckeystore keystore.jks -destkeystore keystore.p12 -deststoretype
pkcs12 - Add the following settings to the command-line arguments of the startup command after the .jar file:
--server.port=8443 --server.ssl.key-store-type=pkcs12 --server.ssl.key-store=keystore.p12 --
server.ssl.key-store-password=h2oh2o --server.ssl.key-alias= H2OaiRestServer --
security.require-ssl=true
IP-Based Checking
The server can limit access from a specific IP prefix, allowing ranges or a specific IP to be accepted as follows:
| SecureEndPointsAllowedIP | Details |
|---|---|
| 0.0.0.0/0 | All hosts. This is the default |
| 127.0.0.0/1 | Only local hosts |
| 192.168.1.0/24 | Only requests from this subnet |
| 10.19.200.194 | Only this specific host |
Additional Settings
The server has additional settings described in the Parameters section of this document. Review the following parameters:
| Parameter | Description |
|---|---|
| SecureEndPoints | The URI root that requires authentication |
| SecureEndPointsAllowedIP | IP prefix-based access restriction |
| SecureModel | Tracks requests based on source IP |
| SecureModelAllowedAgent | Specific HTTP agent checking |
| Autogen | Consider disabling so that callers cannot retrieve templates and API details |
| SnowflakeAllowedFunctions | Rejects requests not using these functions |
Audit Logging
The server has the following logs that can be used for audit functions:
-
Server Access log
Add this parameter to the command line:
--server.tomcat.accesslog.enabled=true -
ScoreLog
Writes a line for each prediction. See ScoreLog in the parameters section for more information. -
ModelMonitoring A log record for each prediction. See ModelMonitor in the parameters section for more information.
Kubernetes
Executing the server in a Kubernetes environment is straightforward. Models can either be saved to local storage for the container or a shared location. Additionally, using the /modelupload API call, models can be dynamically deployed as needed. Using the /ping URI from a load balancer is also useful to verify availability.
Docker container
-
Here is a simple Dockerfile configuration with the minimum settings. Review the section on override ordering, which allows for a common configuration if multiple servers are required but each server has local container setting overrides.
FROM openjdk:8-jre
EXPOSE 8080
COPY target/ai.h2o.mojos.jar .
CMD java -Xms5g -Xmx5g -Dai.h2o.mojos.runtime.license.filename=/License/license.sig -DModelDirectory=/Models/ -jar ai.h2o.mojos.jar -
The following command builds the Docker container image:
docker build -t h2orestserver . -
The following commands execute it. Change the IP and ports as needed for the environment.
kubectl run h2orestserver --replicas=2 --labels="run=load-balancer- h2orestserver " --image=h2orestserver:v1 --port=8080
kubectl expose rs daimojorestserver --type="LoadBalancer" --name=" h2orestserver -service" --external-ip=192.168.1.40
kubectl get pods --selector="run=load-balancer-daimojorestserver" --output=wide
kubectl get service daimojorestserver-service --output=wide
AWS SageMaker
The REST server can be hosted as a SageMaker inference. This allows both H2O-3 and Driverless AI models to be used for scoring with an AWS environment that calls SageMaker.
The REST server can automatically generate the required artifacts for SageMaker:
- SageMaker Docker container
- Commands to deploy the container into AWS ECR
- Test command to verify the integration is working
Integration details
The integration allows models to be deployed using SageMaker by embedding the model, license, REST server, and properties file in the container. All AWS deployment and management options are inherited from the SageMaker platform.
Create a model repository
The deployment requires an AWS repository (ECR). You may need to create this repository using the AWS Console (web UI) if one does not exist or if you want to separate other repositories:
Create AWS ECR repository
Create artifacts
Follow these steps to create the artifacts for deployment:
-
Create the container using auto-generation.
-
Create the commands and example test data for SageMaker.
-
Optionally, generate a Jupyter notebook with an example of calling SageMaker to invoke the model.
-
Optionally, generate a RedShift SQL function to invoke the model from AWS databases such as RedShift, Athena, or Aurora.
Call a model
A Jupyter notebook can be generated for a specific model (see AutoGen settings). This notebook will provide an example of how to call the model hosted in SageMaker with a sample payload.
Notebook
The following command generates an example notebook for the model:
curl "http://127.0.0.1:8080/autogen?name=pipeline.mojo¬ebook=sagemaker-jupyter" -o sagemaker-jupyter.ipynb
Command line
- The AWS CLI can also be used to call the model hosted in SageMaker. This command can be generated using:
curl "http://127.0.0.1:8080/autogen?name=pipeline.mojo¬ebook=sagemaker-commands" - Then, use the AWS CLI to invoke the endpoint:
aws sagemaker-runtime invoke-endpoint --endpoint-name <Inference-Endpoint-Name> --body
fileb://sagemaker-example.json --content-type=application/json SageMaker.out - Example data for testing using the file sagemaker-example.json:
Example data for testing using file sagemaker-example.json
{"name":"pipeline.mojo","verbose":"true","data":"0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0"}
SageMaker endpoint
The model can be deployed as an endpoint that is managed by the SageMaker Inference Runtime. This enables H2O-3 or Driverless AI models to be used for inferencing by passing either a JSON body or a CSV-formatted row of data.
API Gateway / HTTP endpoint
The SageMaker instance can also have an externally reachable connection if the API Gateway is configured. The setup steps for setting up an HTTP endpoint can be found on the AWS website.
Overview of configuration steps
Use the AWS instructions linked in the Reference section for detailed steps. At a high level, the process consists of the following steps:
-
Create an execution role for the REST API: Before building the REST API, you need to create an execution role that gives your API the necessary permission to invoke your Amazon SageMaker endpoint.
-
Build an API Gateway endpoint: Select the REST API option.
-
Only a POST method is required: No mapping is required.
-
Generate the example JSON payload for testing: The AutoGen sagemaker-commands output will generate an example JSON payload for testing.
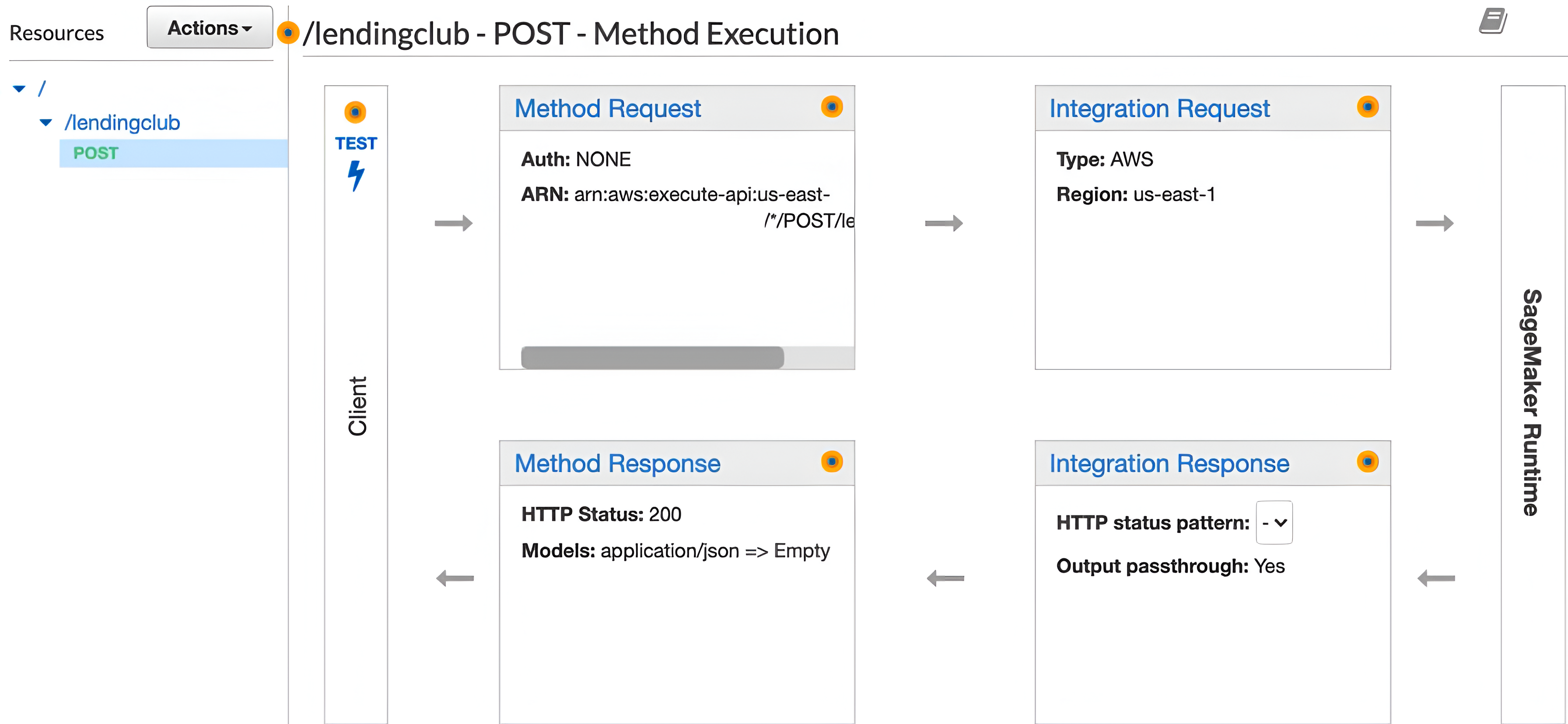
Reference
For detailed instructions on creating the correct setup, IAM roles, and SageMaker invocation privileges, review the following guide: Creating a Machine Learning Powered REST API with Amazon API Gateway and SageMaker
Security roles
Each integration point requires specific access to the AWS services in use. For example, if only using the SageMaker Runtime Inference endpoint, RedShift access is not required.
The following example uses full access settings, which should not be used in a production environment. Set the privileges to the minimum required.
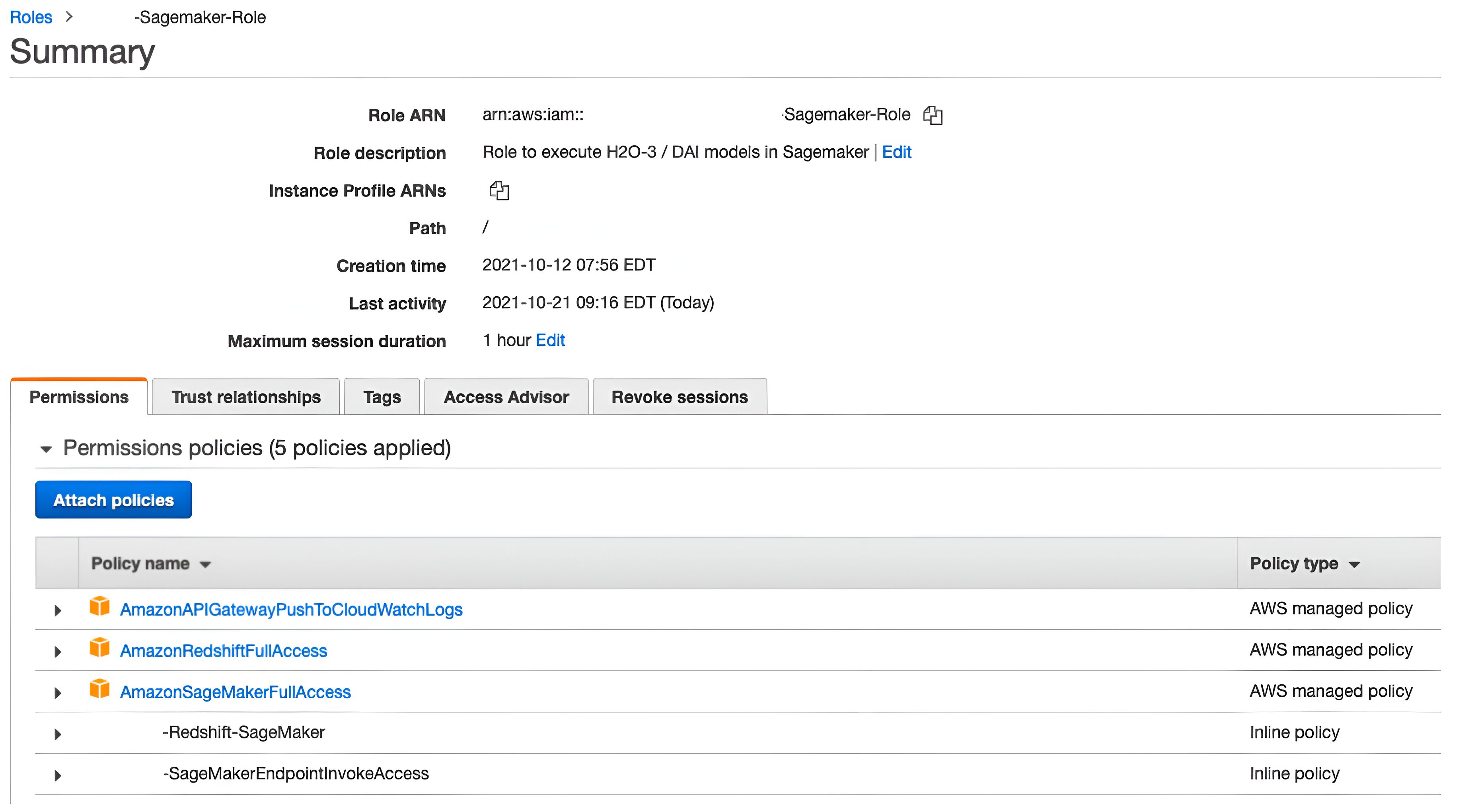
Inline policy
You may need to grant SageMaker access to resources, depending on your security settings.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "sagemaker:*",
"Resource": "*"
}
]
}
Trust relationship
The Create Model step may require access to services if invoked from other AWS services.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": [
"firehose.amazonaws.com",
"cloudformation.amazonaws.com",
"apigateway.amazonaws.com",
"sagemaker.amazonaws.com",
"glue.amazonaws.com",
"states.amazonaws.com",
"events.amazonaws.com",
"lambda.amazonaws.com",
"codebuild.amazonaws.com",
"codepipeline.amazonaws.com"
]
},
"Action": "sts:AssumeRole"
}
]
}
Define the model
In the AWS Console, define the model to be deployed. This points to the Docker image uploaded to ECR. Define AWS SageMaker Model
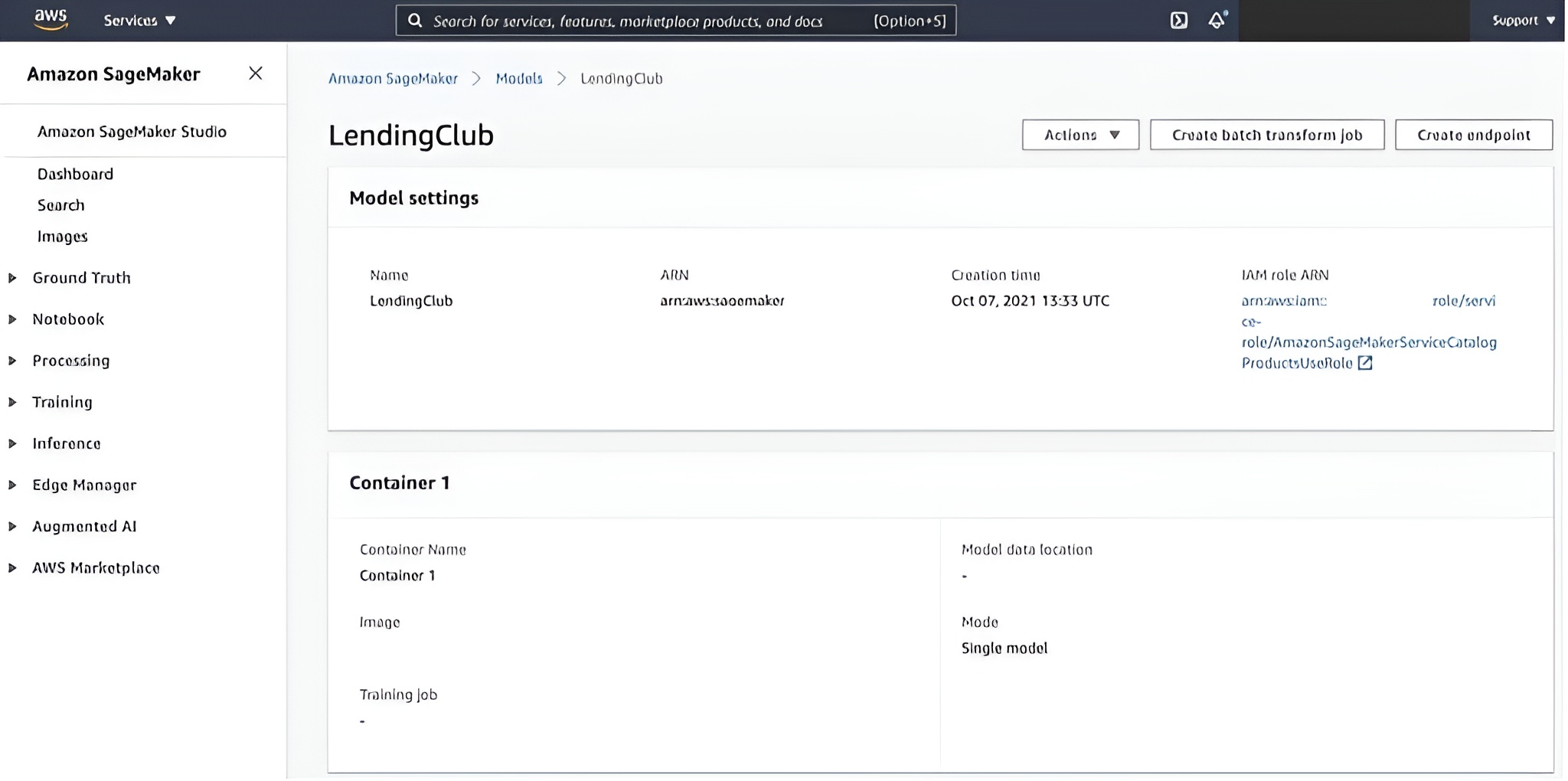
Configure the endpoint
Define how the endpoint will scale and specify whether data logging is required.
Configure AWS SageMaker Endpoint
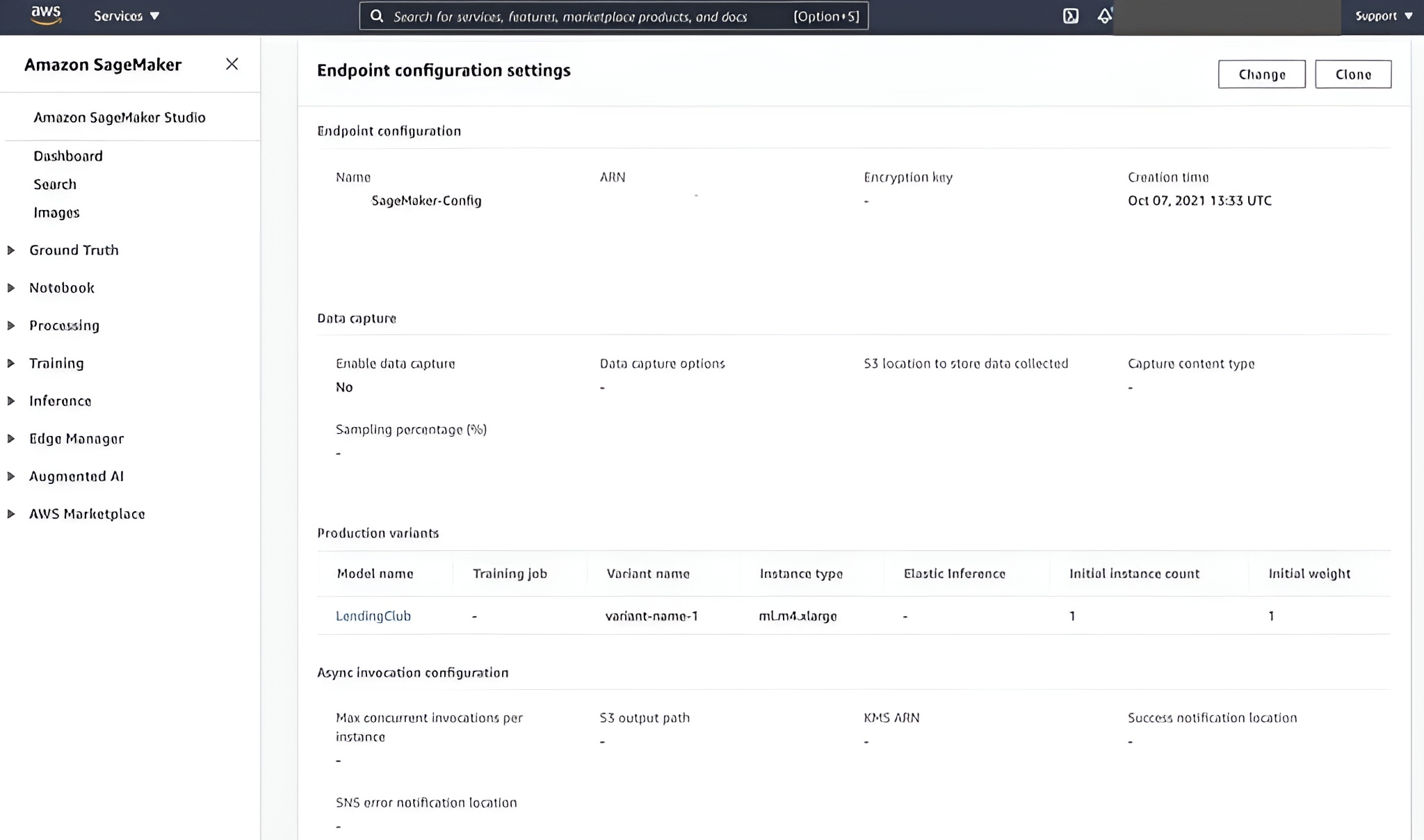
Deploy endpoint
Deploy the endpoint. The deployment may take around 10 minutes to start. Health checks and logs will be available in CloudWatch.
Deploy SageMaker Endpoint
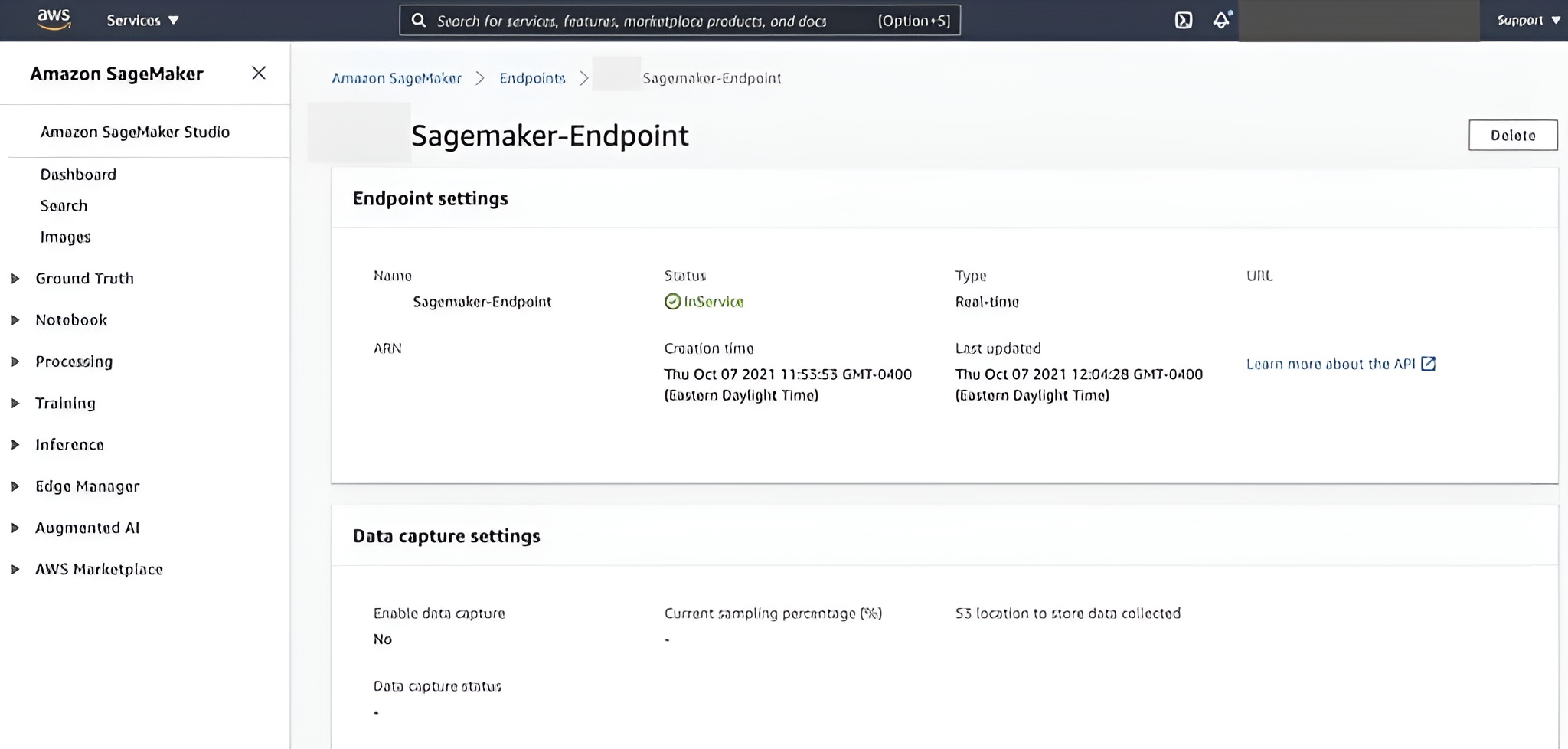
CloudWatch
The integration supports SageMaker calls to /ping and /invocations and logs output to CloudWatch.
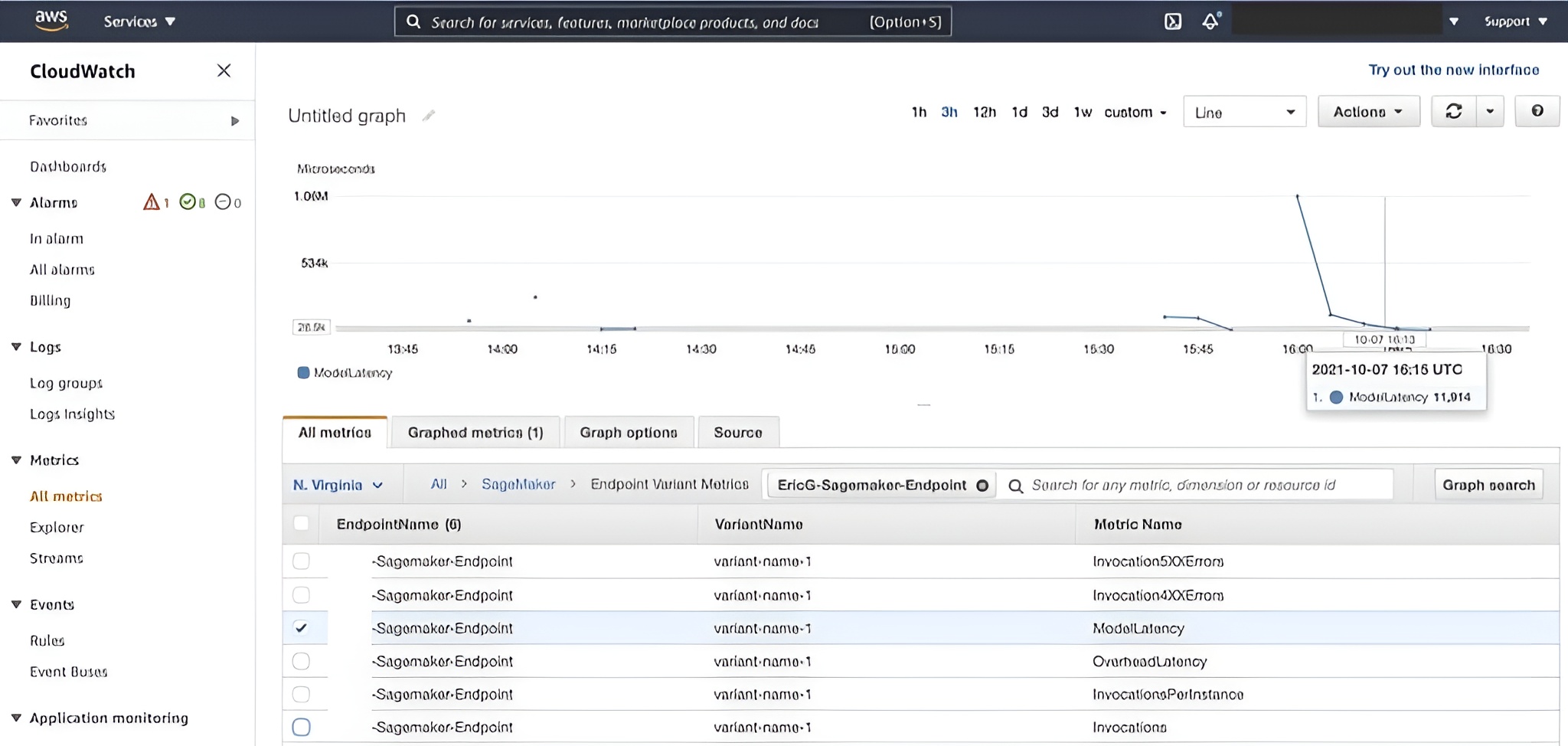
SageMaker batch inference
Batch inference allows you to send input data via an S3 location for inference. The predictions will be written to an S3 location.
Setup steps
Follow the same configuration steps for the SageMaker endpoint. After deploying the endpoint, continue with the following steps.
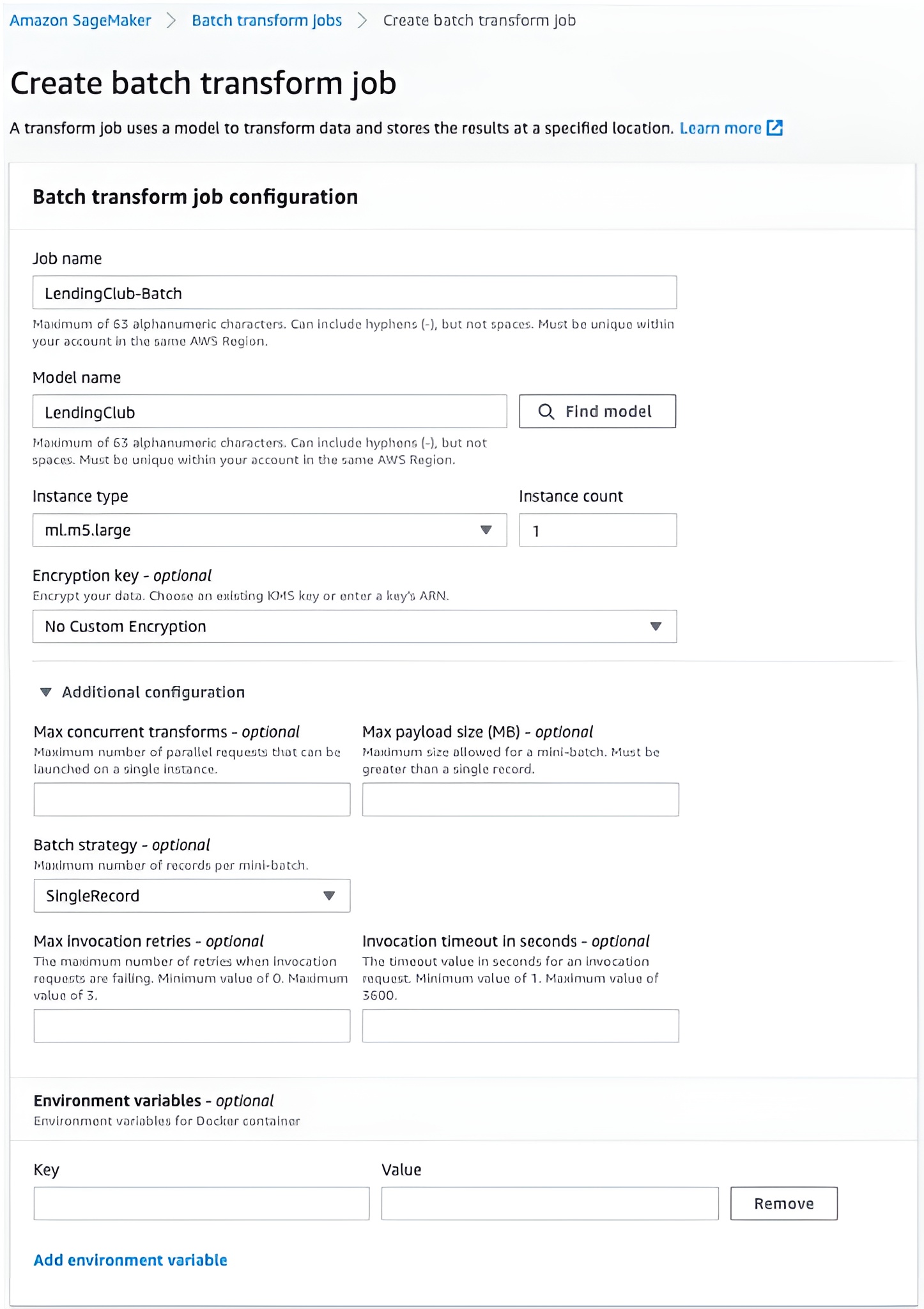
Define batch transformation job
In the SageMaker console, select Inference, then Batch Transform Job. Configure the following settings:
- Job name:
- Model name: Select the model defined in the previous steps
- Instance type and count: Minimum of 2 vCPUs and 8GB memory
- Batch strategy: SingleRecord
- Split type: Line
- Content type: text/csv
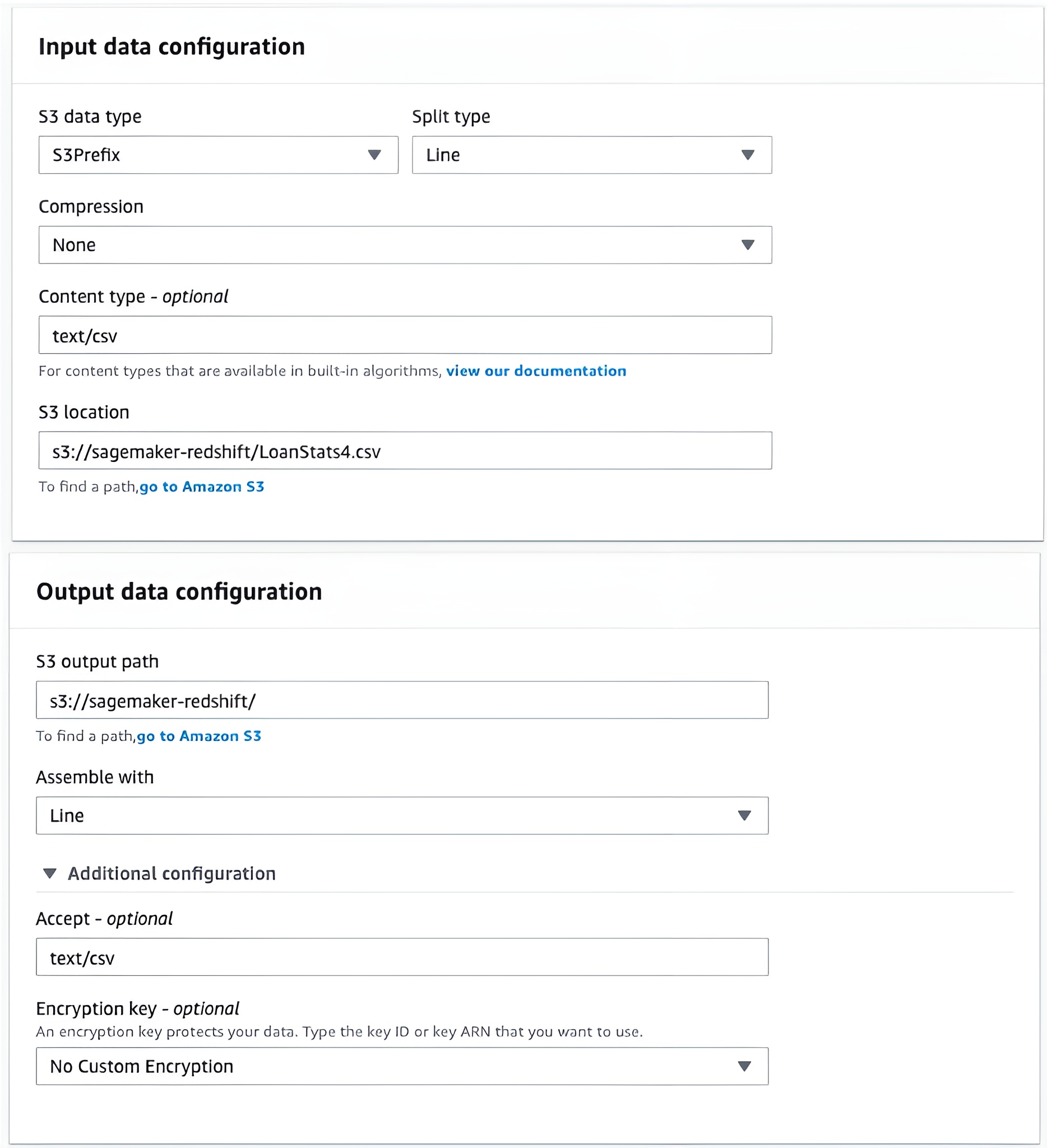
- S3 location (input data): Full S3 location of the CSV file
- S3 location (output data): S3 directory
- Accept: text/csv
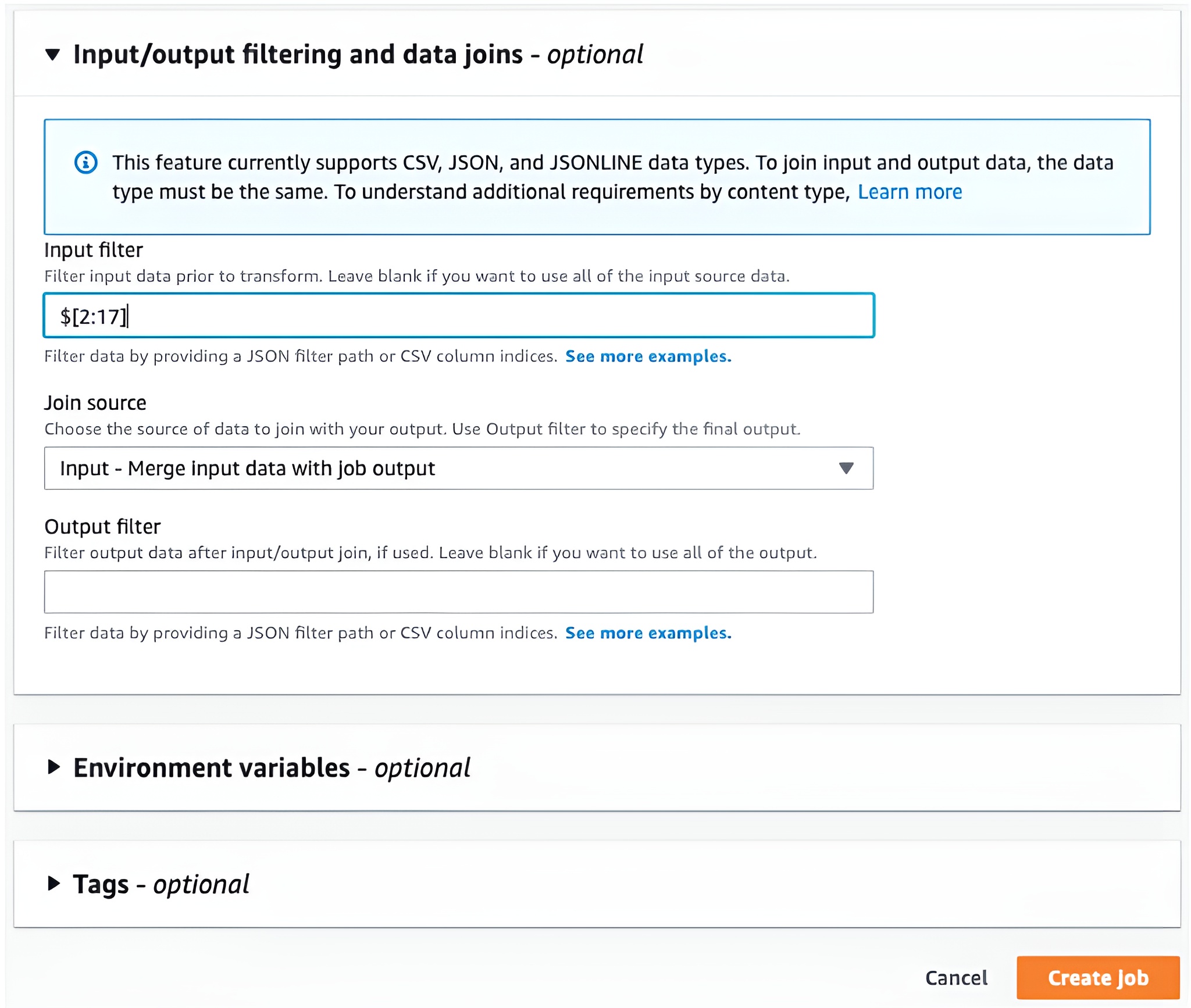
- Input filter: Specify the columns needed for the model (e.g., $[2:17] to select columns 2-17 and drop columns 0, 1, and 18)
- Join source: Input – Merge input data with job output
Click Create Job to start the batch process. Job progress can be monitored in CloudWatch.
File format
Batch inference requires an input file located in S3. The file format should be comma-separated rows, with each line terminated by a newline and no header.
RedShift-SQL
The SageMaker integration enables SQL calls to invoke models that are hosted in the SageMaker Inference Runtime.
Setup steps
The Batch inference uses the same SageMaker configuration steps as the SageMaker Endpoint. Follow those steps to define the ECR image and the endpoint configuration. Once the endpoint is deployed, continue with the following steps.
SQL definition
A SQL function definition must be created to describe the calling parameter types that will be sent from RedShift to SageMaker, the return type, as well as the SageMaker endpoint name and role to use when invoking the call.
Example definition
CREATE MODEL riskmodel
FUNCTION h2oscores ( int, int, int, int, int, int, int, int, int, int, int, int, int, int, int, int, int, int, int)
RETURNS varchar
SAGEMAKER 'H2Oai-Sagemaker-Endpoint'
IAM_ROLE 'arn:aws:iam::nnnnnnnnnn:role/H2Oai-Sagemaker-Role';
Example select / insert
INSERT INTO RESULT (ID, bad_loan_0)
id, h2oscore(loan_amnt, term, int_rate, installment, emp_length, home_ownership,
annual_inc, verification_status, addr_state, dti, delinq_2yrs, inq_last_6mths, pub_rec,
revol_bal, revol_util, total_acc)
from lendingclub ;
Calling the AutoGen function with RedShift-SQL will generate the SQL for creating the model link to SagaMaker and return an example SQL statement for the specific model.
Microsoft Azure
The Rest Server can be deployed as a custom container within the Microsoft Azure environment. This allows both H2O-3 and Driverless AI MOJOs to be used within the Azure ecosystem.
Many of the artifacts for deployment can be created using the Rest Server's AutoGen functionality. These include:
| Artifact Name | Description |
|---|---|
Azure_Commands | Azure CLI commands to deploy the container |
Azure_Container | Example Dockerfile for a custom container |
Azure_Serving_Deployment_yml | Deployment YAML for az commands |
Azure_Serving_Endpoint_yml | Endpoint YAML for az commands |
Azure_Start | Custom container entry point |
Additionally, the following Microsoft product-specific artifacts are available:
| Artifact Name | Description |
|---|---|
Excel_PowerQuery | Using ODBC to models in a database UDF |
Excel_WebQuery | Using Excel web query syntax |
Excel_WebService | For Windows environments using a Web Service |
CSharp | C# example of calling the Rest API |
PowerBI | Dashboard integration using Python |
PowerBI_web | Dashboard content example |
Create custom container
Using the Autogen function, the container and the az commands can be created for the specific model.
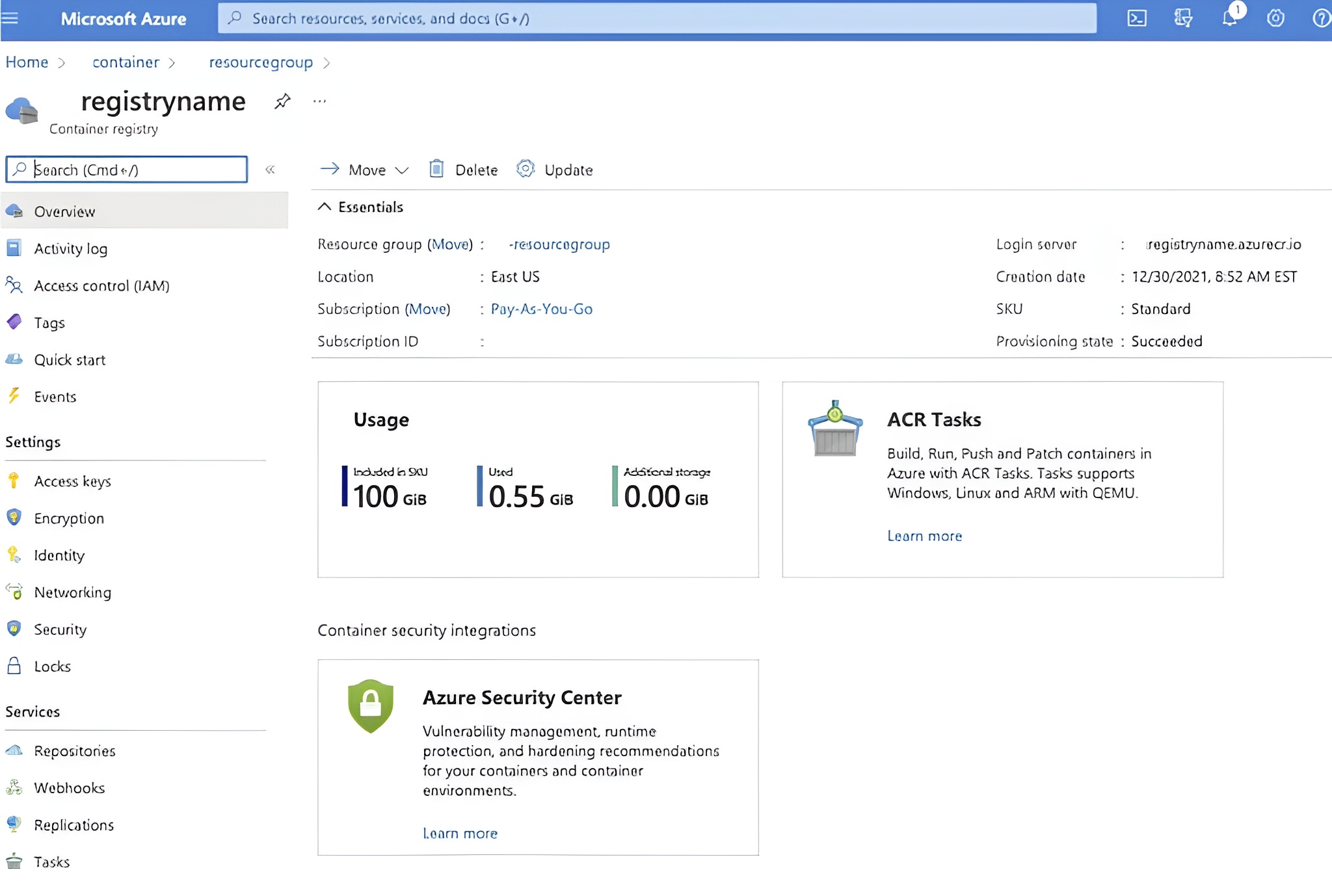
Save image to Azure Container Registry (ACR)
Refer to the Azure ACR documentation for the latest steps in saving the image to ACR. Once a repository has been created, the image can be pushed. For example:
Deploy the container
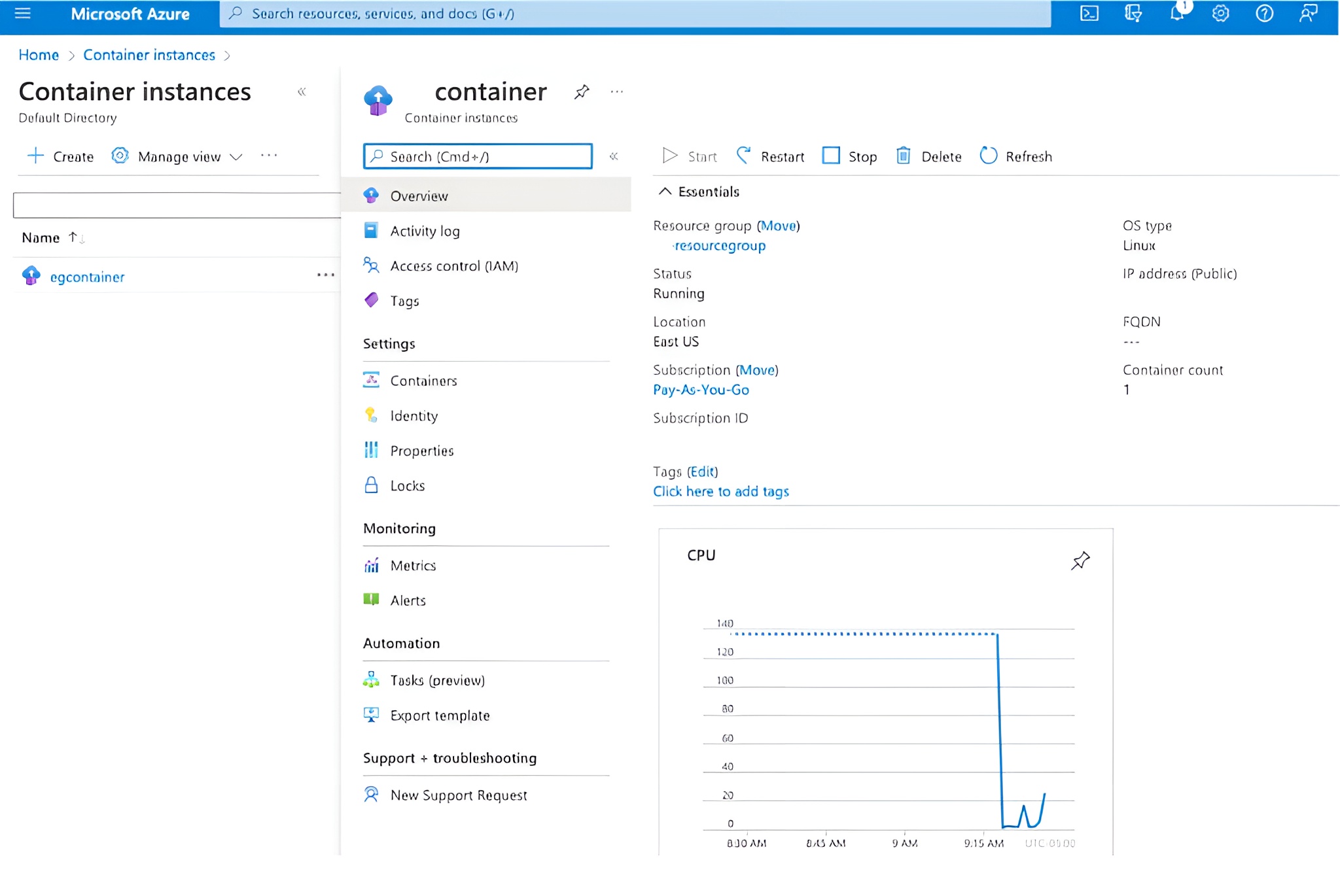
Once the container is in the registry, it can be deployed using either the az commands or the Azure UI.
Monitoring
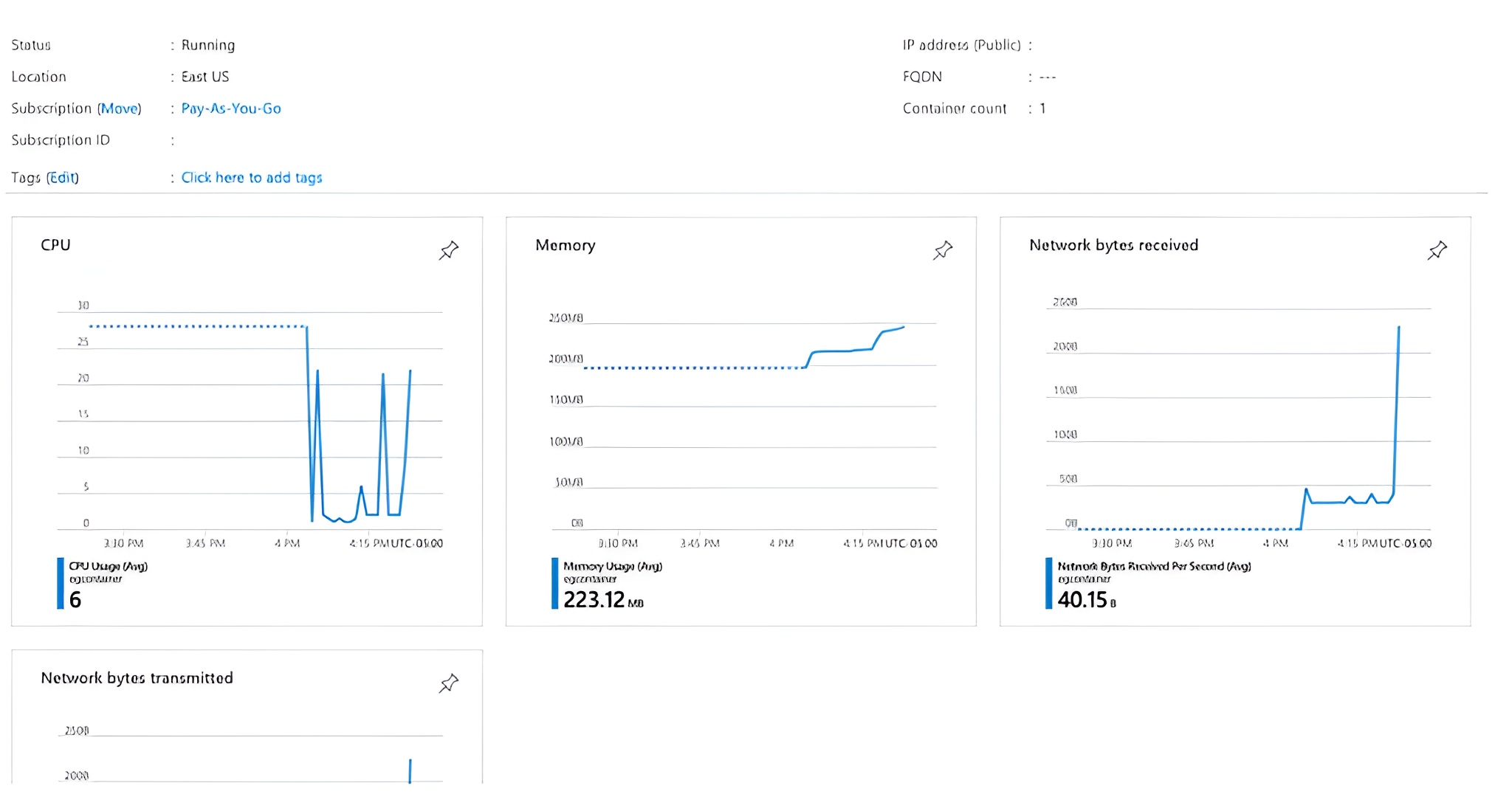
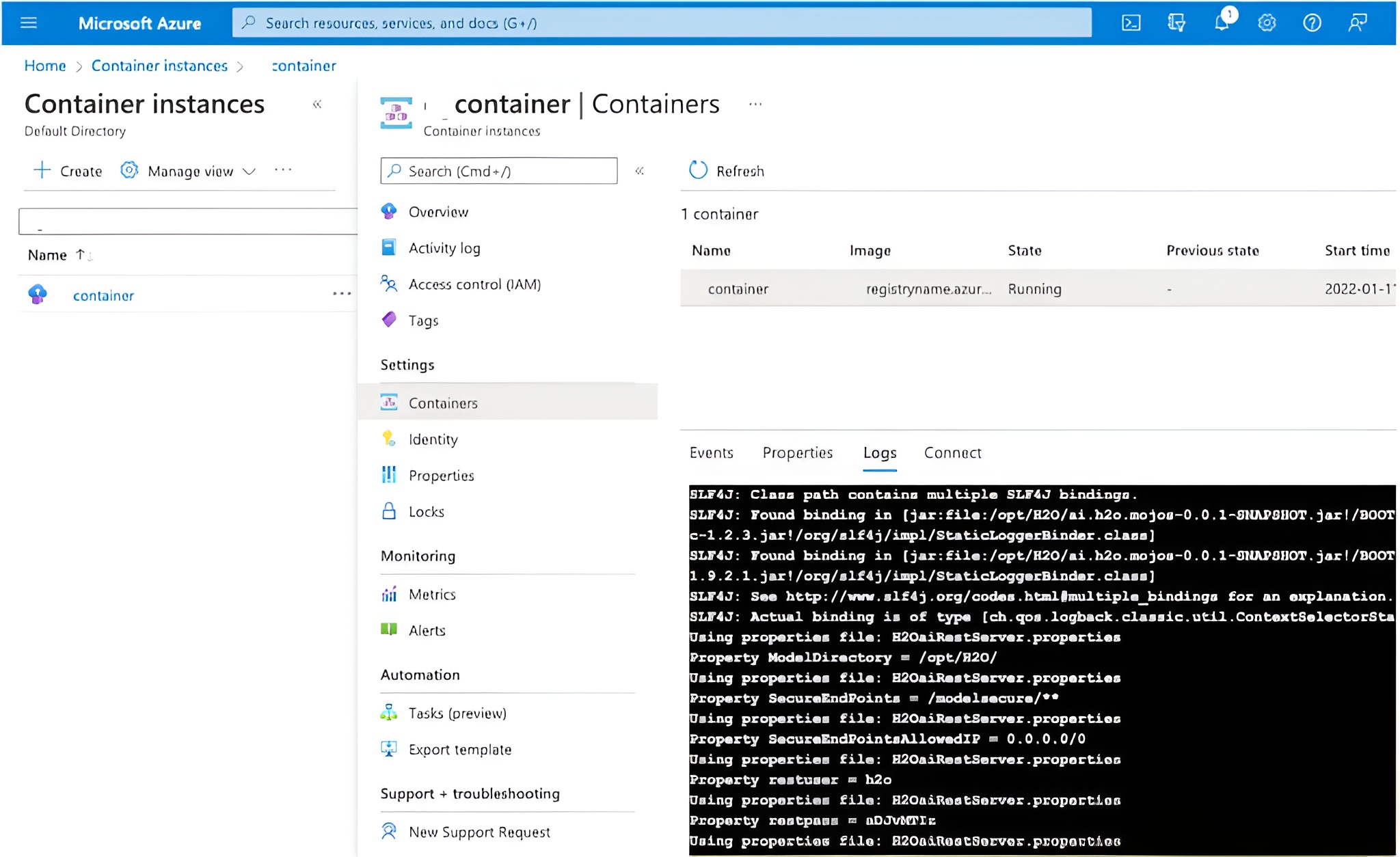
When the container runs, DevOps metrics (CPU, memory, network) will appear in the Azure UI. Additionally, the standard Rest Server logging output will be visible in the Azure UI logs tab for the container.
Advanced configuration options
The Azure environment offers several features that can enhance the deployment of custom containers. Consider the following options:
- Use Azure Data Fabric to distribute models and license artifacts across multiple containers.
- Utilize curated containers and private Python library support in Azure to deploy models.
References
The following links provide helpful references:
- Container Setup: Azure Container Setup
- CLI Reference: Azure CLI Reference
- Azure UI: Managed Online Endpoint Studio
Google Cloud Platform (GCP) App Engine
The following describes the steps to run the REST Server on GCP.
Prerequisites
- Google Cloud SDK
gsutiltool- A GCP project with App Engine enabled
- MOJO REST server JAR file
Set up
Deployment to App Engine uses a flexible custom runtime, allowing you to specify a custom Dockerfile for GCP to build. This approach enables the addition of necessary components to your container and simplifies the transition to GKE deployment.
A flexible custom runtime for GCP App Engine requires the following:
- app.yaml file
- Dockerfile
- GCP Bucket for storing models (optional)
The following is an example of a minimal app.yaml file:
Tells GCP we want to specify our own Dockerfile
runtime: custom
# Tells GCP We won't be using one of the standard environments
env: flex
# Which service we want to deploy to
service: default
# Optional bucket where models are stored
env_variables:
MODELS_BUCKET: [BUCKET-NAME]
If this is your first deployment to App Engine for your project, you must deploy to the default service first. If this is not your first deployment, you can specify another service.
An example of a minimal Dockerfile:
# You can specify any base image you want as long as it contains Java 8
FROM openjdk:8-jre
# The default port App Engine relays incoming request on
EXPOSE 8080
# Copy the MOJO REST server Jar file into our Image
COPY src-dir/ai.h2o.mojos-X-X.XX.jar .
# Optional step to copy MOJO file into image
COPY src-dir/pipeline.mojo .
# Required license file for using Driverless AI MOJOs
COPY src-dir/license.sig .
# Specify model bucket environment variable
ENV MODELS_BUCKET [BUCKET NAME]
# Start the REST server
CMD java -Xms5g -Xmx5g -Dai.h2o.mojos.runtime.license.filename=license.sig
-DModelDirectory=$MODELS_BUCKET -jar ai.h2o.mojos-X-X.XX.jar
You can either copy MOJOs directly into the image or upload them to GCP storage. The above assumes the latter approach. Additionally, the above Dockerfile is just a template that you can modify to suit your specific needs.
Create a GCP bucket for models
gsutil mb -p [PROJECT_ID] gs://[BUCKET_NAME]
After creating a models bucket for your project, you can then upload any models you wish to serve using the REST server to this bucket.
Upload models to a GCP bucket
gsutil cp [SOURCE_FILE] gs://[BUCKET_NAME]
Deploy to GCP app engine
To deploy your REST server to App Engine, navigate to the directory that contains your app.yaml and Dockerfile, and run the following command:
Deploy the app
gcloud app deploy --version [APP_VERSION] --project [PROJECT_NAME]
Depending on the size of your image, building the app may take a few minutes. Monitor the build progress by visiting the Cloud Build History page of your project.
Validate deployment
To confirm that the REST server is running correctly:
- Navigate to the App Engine page of your project.
- Select Services and click on your service name.
You should see a page similar to the one shown in the following image: 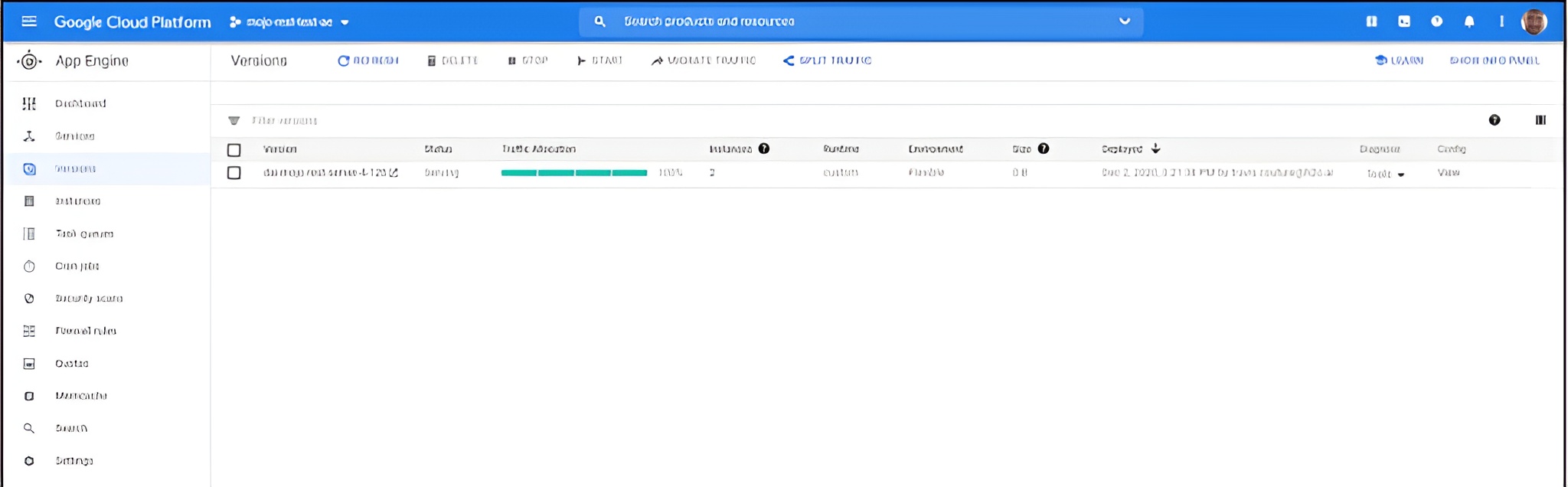
Assuming there are no immediate issues, test the endpoint of your REST server. For additional endpoint options, refer to the MOJO REST Server documentation.
Test model availability
You can check the model availability by sending a curl request to your App Engine endpoint. Run the following command:
curl "https://PROJECT_ID.REGION_ID.r.appspot.com/modelfeatures?name=pipeline.mojo"
If the request is successful, you'll see a response similar to this, depending on the features in your model:
{"result":["Feature 0: term","Feature 1: int_rate","Feature 2:
installment","Feature 3: grade","Feature 4: sub_grade","Feature 5:
emp_title","Feature 6: emp_length","Feature 7: home_ownership","Feature 8:
annual_inc","Feature 9: issue_d","Feature 10: purpose","Feature 11:
title","Feature 12: dti","Feature 13: earliest_cr_line","Feature 14:
inq_last_6mths","Feature 15: revol_bal","Feature 16: revol_util"]}%
REST server health check
You can also check the general health of the REST server with the following curl command:
curl "https://PROJECT_ID.REGION_ID.r.appspot.com/ping"
Resources
Google Kubernetes Engine (GKE)
This section describes the steps to deploy the server using Google Kubernetes Engine.
Prerequisites
- Google Cloud SDK
- A GCP project with Kubernetes Engine enabled
kubectlinstalled on your machine- MOJO REST server JAR file
Setup
A cluster is needed in order to deploy to GKE.
-
Creating a GKE cluster
You can use an existing cluster or create a new one for your project with the following command:
gcloud container clusters create [CLUSTER NAME] --num-nodes [NUM NODES]
The preceding command creates the cluster in your project’s default region.
-
Getting GKE cluster credentials
Next, run the following command to retrieve the credentials needed to access the target cluster:
gcloud container clusters get-credentials [CLUSTER NAME]
-
Checking cluster connection
The following commands set up kubectl to work with the targeted cluster in GKE and validate that kubectl is configured with the correct cluster:
kubectl cluster-info
kubectl get nodes
Deploying to a GKE cluster
To deploy to the GKE cluster, you need to specify an image for running your containers. Start with a Dockerfile. The example below should get you started, and the only requirement is that the base image must have a Java 8 runtime.
# You can specify any base image you want as long as it contains Java 8
FROM openjdk:8-jre
# The default port App Engine relays incoming requests on
EXPOSE 8080
# Copy the MOJO REST server JAR file into our image
COPY src-dir/ai.h2o.mojos-X-X.XX.jar .
# Optional step to copy the MOJO file into the image
COPY src-dir/pipeline.mojo .
# Required license file for using Driverless AI MOJOs
COPY src-dir/license.sig .
# Start the REST server
CMD java -Xms5g -Xmx5g -Dai.h2o.mojos.runtime.license.filename=license.sig -jar ai.h2o.mojos-X-X.XX.jar
You can now use the above Dockerfile to create an image with GCP’s Cloud Build. The resulting image will be stored in GCP’s Container Registry, allowing you to use it with the GKE cluster. Before proceeding, ensure that the Cloud Build API is enabled for your project.
Building the image with cloud build
gcloud builds submit --tag gcr.io/[PROJECT ID]/mojo-rest-gke
Depending on the final size of your image, the above process could take a while to complete. You should be able to verify a successful build in your terminal or through the Cloud Build History page on the GCP console.
Next, define a Kubernetes Deployment and Service. Start by creating a file named deployment.yaml.
apiVersion: apps/v1
kind: Deployment
metadata:
name: mojo-rest-deployment
spec:
replicas: 1
selector:
matchLabels:
app: mojo-rest-app
template:
metadata:
labels:
app: mojo-rest-app
spec:
containers:
- name: mojo-rest-server
# Our image we built using GCP Cloud Build
image: gcr.io/[PROJECT ID]/mojo-rest-gke
ports:
- containerPort: 8080
env:
- name: PORT
value: "8080"
Then, run the following command to deploy the Deployment to your GKE cluster:
Deploy deployment to GKE
kubectl apply -f deployment.yaml
If the deployment was successful, you should see something similar to the following after running the command below.
Validate deployment
kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
mojo-rest-deployment 1/1 1 1 43s
kubectl get pods
NAME READY STATUS RESTARTS AGE
mojo-rest-deployment-5b9df86fb6-jpvl8 1/1 Running 0 43s
Exposing the deployment
After successfully deploying the MOJO REST server Deployment to your GKE cluster, the next step is to expose it for external access in a reliable way, without needing to manage individual Pods in the Deployment. To do this, create a Service, specifically a LoadBalancer. Define the Service in the service.yaml file as shown:
apiVersion: v1
kind: Service
metadata:
name: mojo-rest-lb
spec:
type: LoadBalancer
selector:
app: mojo-rest-app
ports:
- port: 80
targetPort: 8080
Now, deploy the Service using the same method as the Deployment:
Deploy service to GKE
kubectl apply -f service.yaml
You can verify that the Service was successfully deployed by running the following command:
It might take a few moments for an External IP to be assigned to the Service.
Validate service
kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-
IP PORT(S) AGE
kubernetes ClusterIP 10.3.240.1 <none> 443/TCP
12d
mojo-rest-
lb LoadBalancer 10.3.247.112 35.238.49.112 80:31621/TCP 52s
Testing the MOJO REST server
With the service in place, you can test the MOJO REST server to validate its functionality. Upload a MOJO to the REST server using the following command:
Model upload
curl -u h2oadmin:h2o123 -F "file=@src-dir/pipeline.mojo" "[SERVICE EXTERNAL IP]/modelupload?name=pipeline.mojo&replace=true"
You can change the default file size limit using the following parameters:
--spring.servlet.multipart.max-file-size=[FILE SIZE]
--spring.servlet.multipart.max-request-size=[FILE SIZE]
Testing model availability
curl "[SERVICE EXTERNAL IP]:80/modelfeatures?name=pipeline.mojo"
If the request is successful, you should see a response similar to the following, depending on the features in your model:
{
"result": [
"Feature 0: term",
"Feature 1: int_rate",
"Feature 2: installment",
"Feature 3: grade",
"Feature 4: sub_grade",
"Feature 5: emp_title",
"Feature 6: emp_length",
"Feature 7: home_ownership",
"Feature 8: annual_inc",
"Feature 9: issue_d",
"Feature 10: purpose",
"Feature 11: title",
"Feature 12: dti",
"Feature 13: earliest_cr_line",
"Feature 14: inq_last_6mths",
"Feature 15: revol_bal",
"Feature 16: revol_util"
]
}
REST server health check
You can check the general health of the REST server with the following command:
curl "[SERVICE EXTERNAL IP]:80/ping"
Resources
- Submit and view feedback for this page
- Send feedback about H2O eScorer to cloud-feedback@h2o.ai