Batch scoring configuration and usage
You can use H2O eScorer to perform batch scoring (database scoring). The batch scoring process can be summarized as follows:
- Read the data from the source database
- Make predictions on the data
- Write the results back to the database
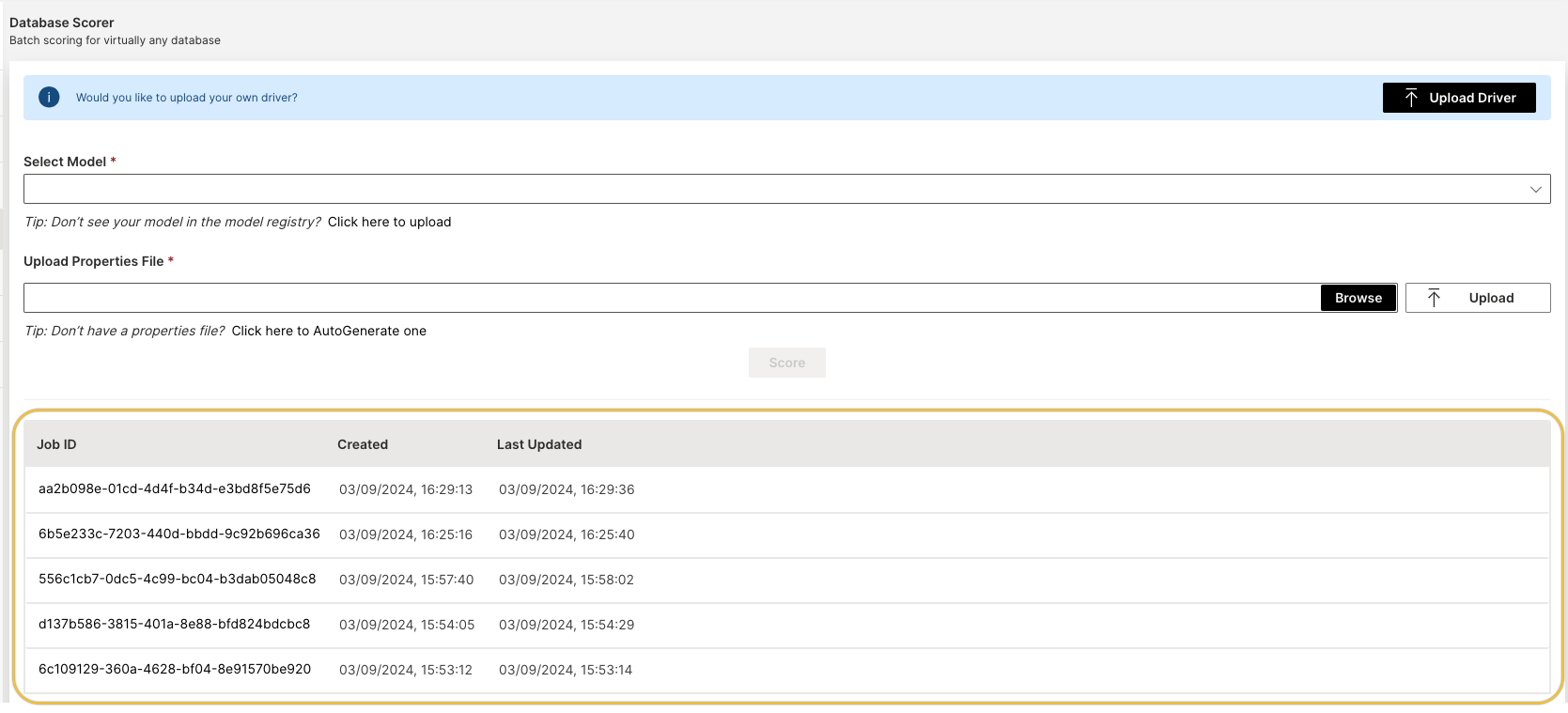
To get started with batch scoring (database scoring), do the following:
-
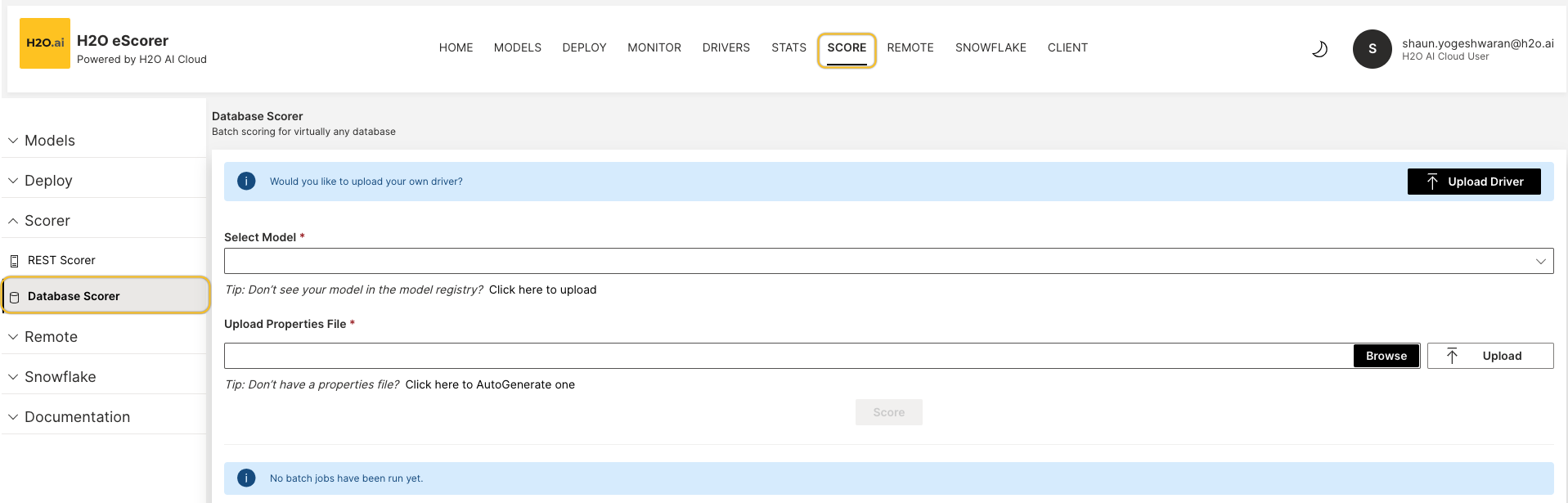
Click on either Scorer or SCORE to open up the Database Scorer:
-
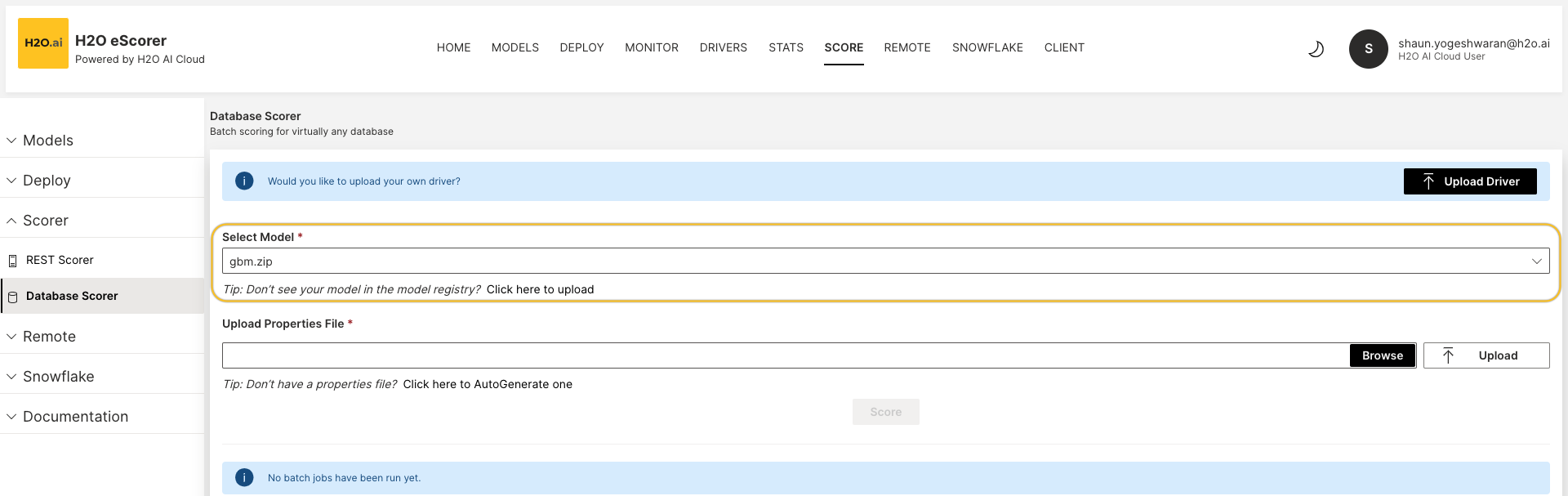
Select your model by exploring the MLOps Model Registry. If you don't see your model, you can navigate to Click here to upload it to upload your model.
-
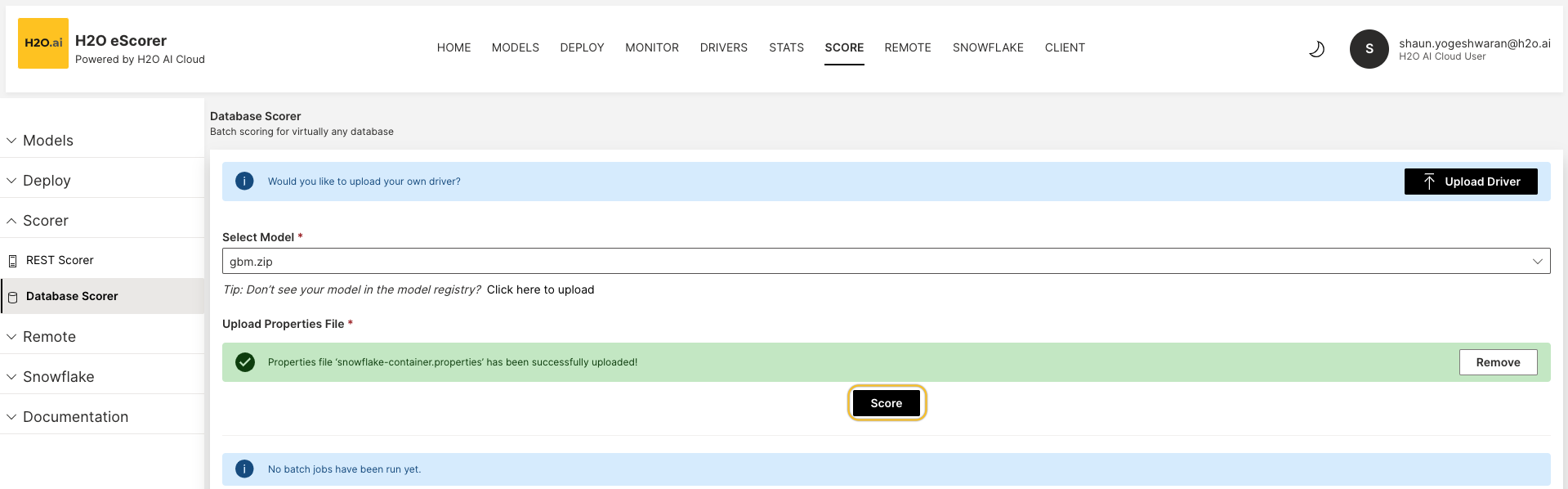
Upload the properties file by browsing through your file directory or AutoGenerating one. Click Upload once complete.
-
Click on Score to proceed with the batch scoring.
-
To view the progress and results of the database scorer job, click on View Job Details.

-
You can click on Download to download the
logfile of your scorer job results. You can also click on View Model Monitor for a live dashboard for model monitoring across models.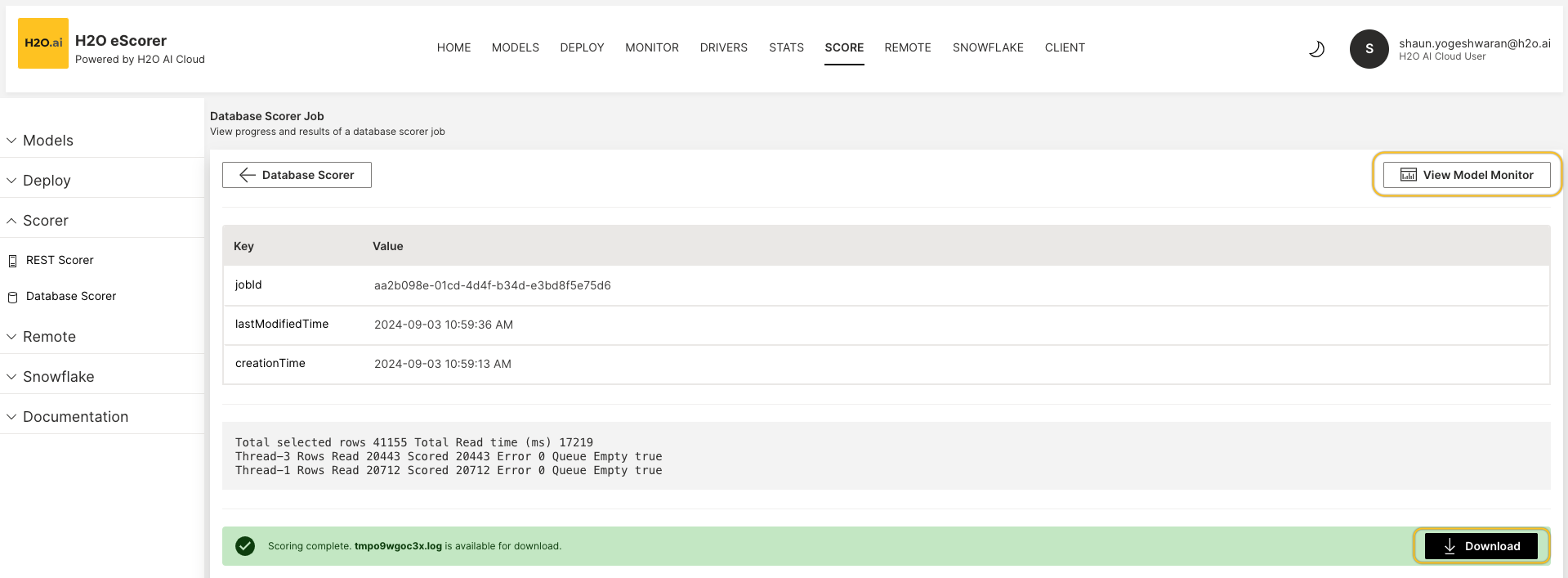 note
notePrevious job runs can be accessed by clicking on any one of your previous entries:
For more in-depth information on database scoring in H2O eScorer, download the H2O eScorer Database Scoring PDF.
Batch scoring tasks require JDBC drivers to connect to the data source to ingest data and record predictions.
For example, to score data from a Snowflake database, you need the snowflake-jdbc-3.9.2.jar driver.
The following sections describe how to auto-generate and use a Properties file to configure your Batch Scorer.
Auto-generate a properties file
The H2O eScorer Wave app lets you automatically generate deployment code for you model with the AutoGen feature.
To generate the model deployment code, click Deploy -> AutoGen and specify a Model and Deployment Type. To confirm your selection, click the Generate button. In this example, a batch scorer properties file called ManagedCloud_Database_Scorer.properties is generated to score the riskmodel.mojo model.
In this example, riskmodel.mojo had already been deployed to the eScorer and made available in the model registry.
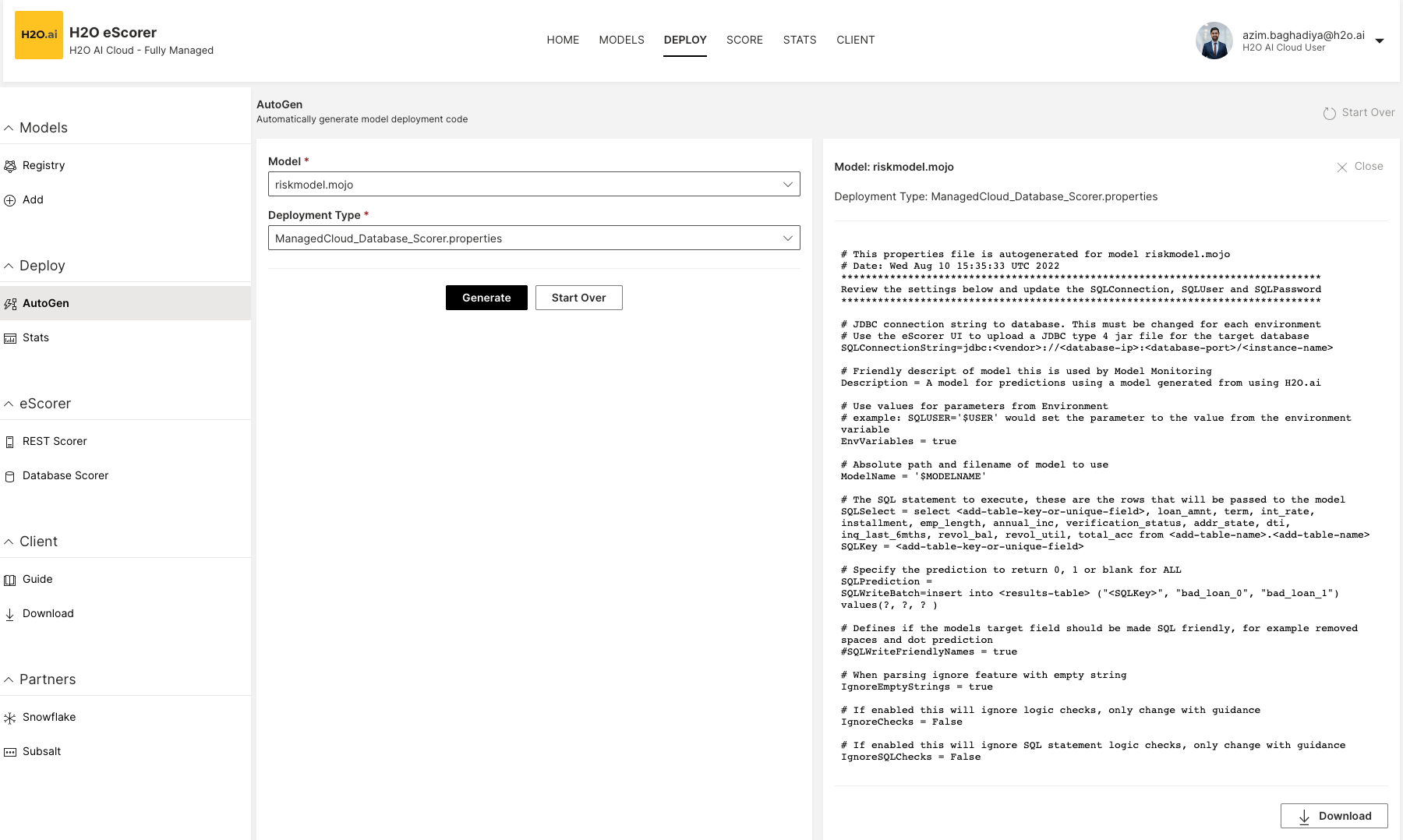
What do the properties mean?
Notice how the model features are auto-generated for the riskmodel.mojo file.
JDBCconnection string for the database:
SQLConnectionString=jdbc:<vendor>://<database-ip>:<database-port>/<instance-name>
- A description for the model:
Description = A H2O.ai Machine Learning model
- Use Environment Variables to set values for the parameters. For example,
SQLUSER='$USER'sets theSQLUSERparameter with the value from the environment variable.
EnvVariables = true
- Name and path of the Model. Do not change for H2O eScorer.
ModelName = '$MODELNAME'
SELECTSQL statement to get the data that will be scored:
SQLSelect = SELECT <add-table-key-or-unique-field>, loan_amnt, term, int_rate, installment, emp_length, annual_inc, verification_status, addr_state, dti, inq_last_6mths, revol_bal, revol_util, total_acc FROM <add-table-name>.<add-table-name>
- Unique key of the table
SQLKey = <add-table-key-or-unique-field>
- Prediction class to return. One of:
0,1,__blank__(All)
SQLPrediction =
- SQL statement to write the results back to the database
SQLWriteBatch=insert into <results-table> ("<SQLKey>", "bad_loan_0", "bad_loan_1") values(?, ?, ? )
- SQL friendly model target field. For ex: removed spaces and dot predictions
SQLWriteFriendlyNames = false
- Skip features with empty string
IgnoreEmptyStrings = true
- Ignore logic checks (enable with caution)
IgnoreChecks = False
- Ignore SQL statement logic checks (enable with caution)
IgnoreSQLChecks = False
- Change NULL in SQL results to
NA. This depends on the model training and should match it.
SetNullAs = NA
NullCharacters="NA|NULL"
- Return
Shapleycontributions with the Predictions. (SQLWriteBatchmust be set)
ShapPredictContrib = false
- Submit and view feedback for this page
- Send feedback about H2O eScorer to cloud-feedback@h2o.ai