Size dependency
Overview
A size dependency test in H2O Model Validation is used to analyze the effects of different sizes of training data on the accuracy of a selected model. This test helps in assessing model stability and determining if augmenting the existing training data will improve model accuracy.
H2O Model Validation uses different sampling techniques for the size dependency test based on the selected model type. For independent and identically distributed (IID) models,random sampling is used to create new sub-training samples. On the other hand, for time series models, expanding window sampling is used, which ensures that sub-training samples grow from recent to oldest data points by utilizing time columns.
Before applying the sampling technique, the original training data is split using folds to improve generalization and data balance. For IID models, folds and sub-training samples are created randomly, while for time series models, folds and sub-training samples are created using the time column.
Based on the number of folds, H2O Model Validation retrains the model multiple times by updating its training dataset with new sub-training samples. A scorer is generated for each iteration of the retraining process for further analysis.
Sampling the original training data for a model under random or expanding window sampling can be illustrated in the below image.
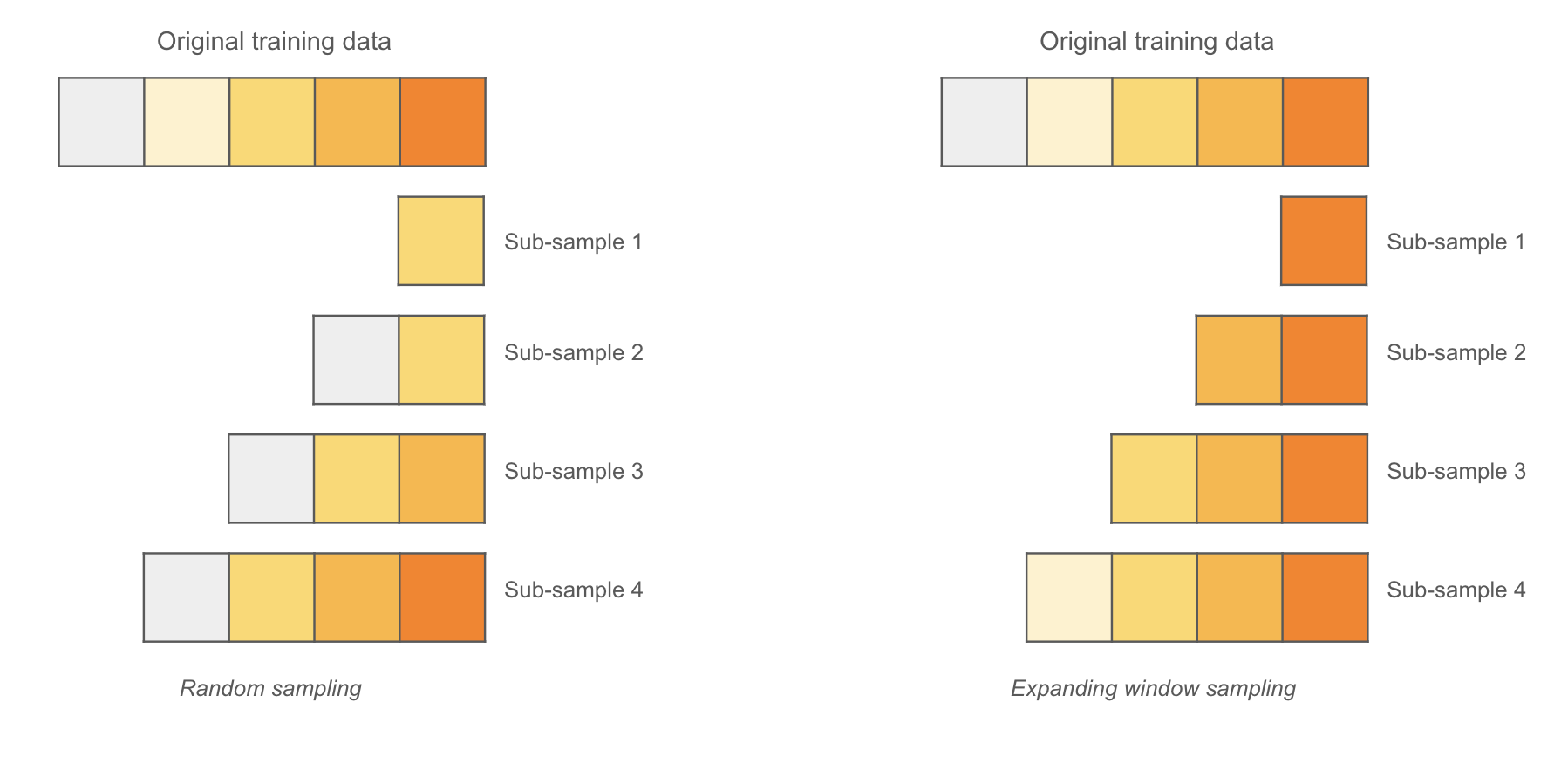
H2O Model Validation provides various settings for the size dependency test.
Overall, the size dependency test in H2O Model Validation allows for a thorough analysis of the impact of training data size on model accuracy, helping in making informed decisions about model stability and potential improvements.
Resources
- To learn how to create a size dependency test, see Create a size dependency test.
- See Settings: Size dependency to learn about all the settings for a size dependency validation test.
- See Metrics: Size dependency to learn about all the metrics for a drift dependency validation test.
- Submit and view feedback for this page
- Send feedback about H2O Model Validation to cloud-feedback@h2o.ai