Adversarial similarity
Overview
An adversarial similarity test in H2O Model Validation is used to compare two different datasets and determine their similarity or dissimilarity. Instead of comparing individual features, this test leverages decision tree algorithms to find similar or dissimilar rows between the datasets.
To perform the adversarial similarity test, H2O Model Validation combines the training dataset with another dataset with similar columns. A new target column is created in the concatenated dataset, where the rows from the training dataset are assigned 0s, and the rows from the other dataset are assigned 1s. For example, consider the following image, which concatenates the train dataset with the test dataset:
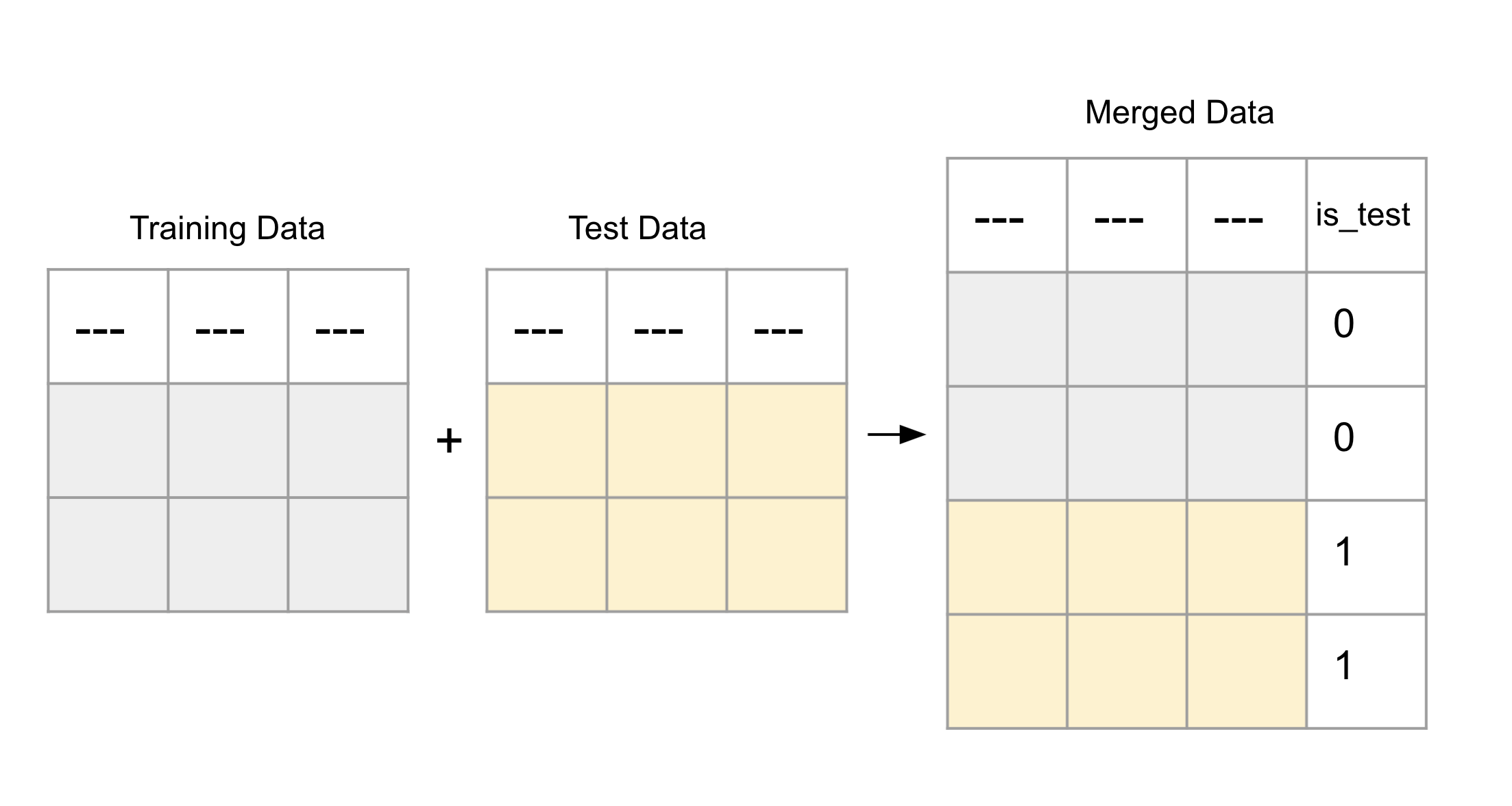
The test generates predicted scores for each row in the concatenated dataset. These scores can be used to analyze the most different or similar rows in the dataset. The scores are represented as area under the curve (AUC) values, where higher scores indicate greater dissimilarity to the training dataset.
H2O Model Validation provides several settings for the adversarial similarity test.
Overall, an adversarial similarity test in H2O Model Validation is a powerful tool for comparing datasets and validating models. It provides insights into the similarity or dissimilarity between datasets, allowing for further analysis and understanding of model performance.
Resources
- To learn how to create an adversarial similarity test, see Create an adversarial similarity test.
- See Settings: Adversarial similarity to learn about all the settings for an adversarial similarity validation test.
- See Metrics: Adversarial similarity to learn about all the metrics for an adversarial similarity validation test.
- Submit and view feedback for this page
- Send feedback about H2O Model Validation to cloud-feedback@h2o.ai