Scorers
Classification or Regression
GINI (Gini Coefficient)
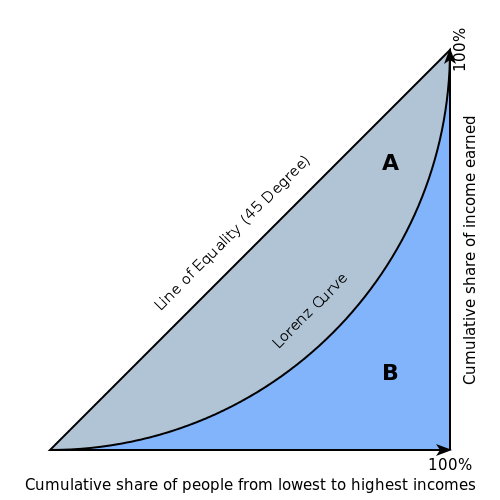
The Gini index is a well-established method to quantify the inequality among values of a frequency distribution, and can be used to measure the quality of a binary classifier. A Gini index of zero expresses perfect equality (or a totally useless classifier), while a Gini index of one expresses maximal inequality (or a perfect classifier).
The Gini index is based on the Lorenz curve. The Lorenz curve plots the true positive rate (y-axis) as a function of percentiles of the population (x-axis).
The Lorenz curve represents a collective of models represented by the classifier. The location on the curve is given by the probability threshold of a particular model. (i.e., Lower probability thresholds for classification typically lead to more true positives, but also to more false positives.)
The Gini index itself is independent of the model and only depends on the Lorenz curve determined by the distribution of the scores (or probabilities) obtained from the classifier.
Regression
R2 (R Squared)
The R2 value represents the degree that the predicted value and the actual value move in unison. The R2 value varies between 0 and 1 where 0 represents no correlation between the predicted and actual value and 1 represents complete correlation.
Calculating the R2 value for linear models is mathematically equivalent to \(1 - SSE/SST\) (or \(1 - \text{residual sum of squares}/\text{total sum of squares}\)). For all other models, this equivalence does not hold, so the \(1 - SSE/SST\) formula cannot be used. In some cases, this formula can produce negative R2 values, which is mathematically impossible for a real number. Because Driverless AI does not necessarily use linear models, the R2 value is calculated using the squared Pearson correlation coefficient.
R2 equation:
Where:
x is the predicted target value
y is the actual target value
MSE (Mean Squared Error)
The MSE metric measures the average of the squares of the errors or deviations. MSE takes the distances from the points to the regression line (these distances are the “errors”) and squaring them to remove any negative signs. MSE incorporates both the variance and the bias of the predictor.
MSE also gives more weight to larger differences. The bigger the error, the more it is penalized. For example, if your correct answers are 2,3,4 and the algorithm guesses 1,4,3, then the absolute error on each one is exactly 1, so squared error is also 1, and the MSE is 1. But if the algorithm guesses 2,3,6, then the errors are 0,0,2, the squared errors are 0,0,4, and the MSE is a higher 1.333. The smaller the MSE, the better the model’s performance. (Tip: MSE is sensitive to outliers. If you want a more robust metric, try mean absolute error (MAE).)
MSE equation:
RMSE (Root Mean Squared Error)
The RMSE metric evaluates how well a model can predict a continuous value. The RMSE units are the same as the predicted target, which is useful for understanding if the size of the error is of concern or not. The smaller the RMSE, the better the model’s performance. (Tip: RMSE is sensitive to outliers. If you want a more robust metric, try mean absolute error (MAE).)
RMSE equation:
Where:
N is the total number of rows (observations) of your corresponding dataframe.
y is the actual target value.
\(\hat{y}\) is the predicted target value.
RMSLE (Root Mean Squared Logarithmic Error)
This metric measures the ratio between actual values and predicted values and takes the log of the predictions and actual values. Use this instead of RMSE if an under-prediction is worse than an over-prediction. You can also use this when you don’t want to penalize large differences when both of the values are large numbers.
RMSLE equation:
Where:
N is the total number of rows (observations) of your corresponding dataframe.
y is the actual target value.
\(\hat{y}\) is the predicted target value.
RMSPE (Root Mean Square Percentage Error)
This metric is the RMSE expressed as a percentage. The smaller the RMSPE, the better the model performance.
RMSPE equation:
MAE (Mean Absolute Error)
The mean absolute error is an average of the absolute errors. The MAE units are the same as the predicted target, which is useful for understanding whether the size of the error is of concern or not. The smaller the MAE the better the model’s performance. (Tip: MAE is robust to outliers. If you want a metric that is sensitive to outliers, try root mean squared error (RMSE).)
MAE equation:
Where:
N is the total number of errors
\(| x_i - x |\) equals the absolute errors.
MAPE (Mean Absolute Percentage Error)
MAPE measures the size of the error in percentage terms. It is calculated as the average of the unsigned percentage error.
MAPE equation:
Because the MAPE measure is in percentage terms, it gives an indication of how large the error is across different scales. Consider the following example:
Actual |
Predicted |
Absolute Error |
Absolute Percentage Error |
|---|---|---|---|
5 |
1 |
4 |
80% |
15,000 |
15,004 |
4 |
0.03% |
Both records have an absolute error of 4, but this error could be considered “small” or “big” when you compare it to the actual value.
SMAPE (Symmetric Mean Absolute Percentage Error)
Unlike the MAPE, which divides the absolute errors by the absolute actual values, the SMAPE divides by the mean of the absolute actual and the absolute predicted values. This is important when the actual values can be 0 or near 0. Actual values near 0 cause the MAPE value to become infinitely high. Because SMAPE includes both the actual and the predicted values, the SMAPE value can never be greater than 200%.
Consider the following example:
Actual |
Predicted |
|---|---|
0.01 |
0.05 |
0.03 |
0.04 |
The MAPE for this data is 216.67% but the SMAPE is only 80.95%.
Both records have an absolute error of 4, but this error could be considered “small” or “big” when you compare it to the actual value.
MER (Median Error Rate or Median Absolute Percentage Error)
MER measures the median size of the error in percentage terms. It is calculated as the median of the unsigned percentage error.
MER equation:
Because the MER is the median, half the scored population has a lower absolute percentage error than the MER, and half the population has a larger absolute percentage error than the MER.
Classification
MCC (Matthews Correlation Coefficient)
The goal of the MCC metric is to represent the confusion matrix of a model as a single number. The MCC metric combines the true positives, false positives, true negatives, and false negatives using the equation described below.
A Driverless AI model will return probabilities, not predicted classes. To convert probabilities to predicted classes, a threshold needs to be defined. Driverless AI iterates over possible thresholds to calculate a confusion matrix for each threshold. It does this to find the maximum MCC value. Driverless AI’s goal is to continue increasing this maximum MCC.
Unlike metrics like Accuracy, MCC is a good scorer to use when the target variable is imbalanced. In the case of imbalanced data, high Accuracy can be found by predicting the majority class. Metrics like Accuracy and F1 can be misleading, especially in the case of imbalanced data, because they do not consider the relative size of the four confusion matrix categories. MCC, on the other hand, takes the proportion of each class into account. The MCC value ranges from -1 to 1 where -1 indicates a classifier that predicts the opposite class from the actual value, 0 means the classifier does no better than random guessing, and 1 indicates a perfect classifier.
MCC equation:
F05, F1, and F2
A Driverless AI model returns probabilities, not predicted classes. To convert probabilities to predicted classes, a threshold needs to be defined. Driverless AI iterates over possible thresholds to calculate a confusion matrix for each threshold. It does this to find the maximum F metric value. Driverless AI’s goal is to continue increasing this maximum F metric.
The F1 score provides a measure for how well a binary classifier can classify positive cases (given a threshold value). The F1 score is calculated from the harmonic mean of the precision and recall. An F1 score of 1 means both precision and recall are perfect and the model correctly identified all the positive cases and didn’t mark a negative case as a positive case. If either precision or recall are very low it will be reflected with a F1 score closer to 0.
F1 equation:
Where:
precision is the positive observations (true positives) the model correctly identified from all the observations it labeled as positive (the true positives + the false positives).
recall is the positive observations (true positives) the model correctly identified from all the actual positive cases (the true positives + the false negatives).
The F0.5 score is the weighted harmonic mean of the precision and recall (given a threshold value). Unlike the F1 score, which gives equal weight to precision and recall, the F0.5 score gives more weight to precision than to recall. More weight should be given to precision for cases where False Positives are considered worse than False Negatives. For example, if your use case is to predict which products you will run out of, you may consider False Positives worse than False Negatives. In this case, you want your predictions to be very precise and only capture the products that will definitely run out. If you predict a product will need to be restocked when it actually doesn’t, you incur cost by having purchased more inventory than you actually need.
F05 equation:
Where:
precision is the positive observations (true positives) the model correctly identified from all the observations it labeled as positive (the true positives + the false positives).
recall is the positive observations (true positives) the model correctly identified from all the actual positive cases (the true positives + the false negatives).
The F2 score is the weighted harmonic mean of the precision and recall (given a threshold value). Unlike the F1 score, which gives equal weight to precision and recall, the F2 score gives more weight to recall than to precision. More weight should be given to recall for cases where False Negatives are considered worse than False Positives. For example, if your use case is to predict which customers will churn, you may consider False Negatives worse than False Positives. In this case, you want your predictions to capture all of the customers that will churn. Some of these customers may not be at risk for churning, but the extra attention they receive is not harmful. More importantly, no customers actually at risk of churning have been missed.
F2 equation:
Where:
precision is the positive observations (true positives) the model correctly identified from all the observations it labeled as positive (the true positives + the false positives).
recall is the positive observations (true positives) the model correctly identified from all the actual positive cases (the true positives + the false negatives).
Accuracy
In binary classification, Accuracy is the number of correct predictions made as a ratio of all predictions made. In multiclass classification, the set of labels predicted for a sample must exactly match the corresponding set of labels in y_true.
A Driverless AI model will return probabilities, not predicted classes. To convert probabilities to predicted classes, a threshold needs to be defined. Driverless AI iterates over possible thresholds to calculate a confusion matrix for each threshold. It does this to find the maximum Accuracy value. Driverless AI’s goal is to continue increasing this maximum Accuracy.
Accuracy equation:
Logloss
The logarithmic loss metric can be used to evaluate the performance of a binomial or multinomial classifier. Unlike AUC which looks at how well a model can classify a binary target, logloss evaluates how close a model’s predicted values (uncalibrated probability estimates) are to the actual target value. For example, does a model tend to assign a high predicted value like .80 for the positive class, or does it show a poor ability to recognize the positive class and assign a lower predicted value like .50? Logloss can be any value greater than or equal to 0, with 0 meaning that the model correctly assigns a probability of 0% or 100%.
Binary classification equation:
Multiclass classification equation:
Where:
N is the total number of rows (observations) of your corresponding dataframe.
w is the per row user-defined weight (defaults is 1).
C is the total number of classes (C=2 for binary classification).
p is the predicted value (uncalibrated probability) assigned to a given row (observation).
y is the actual target value.
AUC (Area Under the Receiver Operating Characteristic Curve)
This model metric is used to evaluate how well a binary classification model is able to distinguish between true positives and false positives. For multi-class problems, this score is computed by micro-averaging the ROC curves for each class. Use MACROAUC if you prefer the macro average.
An AUC of 1 indicates a perfect classifier, while an AUC of .5 indicates a poor classifier whose performance is no better than random guessing.
AUCPR (Area Under the Precision-Recall Curve)
This model metric is used to evaluate how well a binary classification model is able to distinguish between precision recall pairs or points. These values are obtained using different thresholds on a probabilistic or other continuous-output classifier. AUCPR is an average of the precision-recall weighted by the probability of a given threshold.
The main difference between AUC and AUCPR is that AUC calculates the area under the ROC curve and AUCPR calculates the area under the Precision Recall curve. The Precision Recall curve does not care about True Negatives. For imbalanced data, a large quantity of True Negatives usually overshadows the effects of changes in other metrics like False Positives. The AUCPR will be much more sensitive to True Positives, False Positives, and False Negatives than AUC. As such, AUCPR is recommended over AUC for highly imbalanced data.
MACROAUC (Macro Average of Areas Under the Receiver Operating Characteristic Curves)
For multiclass classification problems, this score is computed by macro-averaging the ROC curves for each class (one per class). The area under the curve is a constant. A MACROAUC of 1 indicates a perfect classifier, while a MACROAUC of .5 indicates a poor classifier whose performance is no better than random guessing. This option is not available for binary classification problems.
Scorer Best Practices - Regression
When deciding which scorer to use in a regression problem, consider the following:
Do you want your scorer to be sensitive to outliers?
What unit should the scorer be in?
Sensitive to Outliers
Certain scorers are more sensitive to outliers. When a scorer is sensitive to outliers, it means that it is important that the model predictions are never exceedingly inaccurate. For example, say you have an experiment predicting the number of days until an event. The graph below shows the absolute error in your predictions.
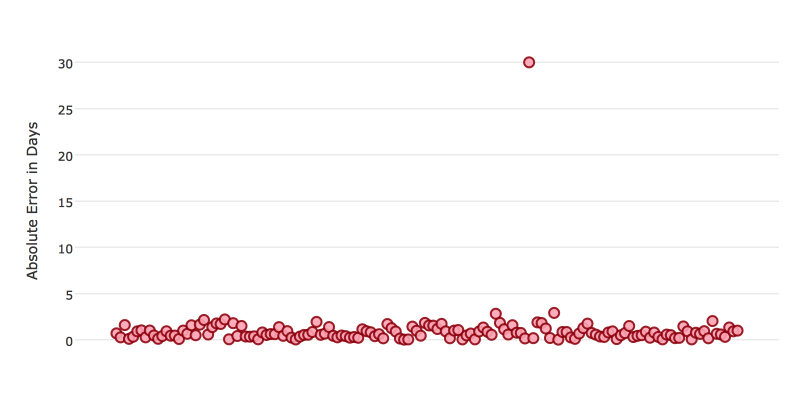
The model is usually very effective, with an absolute error of less than 1 day about 70% of the time. There is one instance, however, where the model performs poorly—one prediction is 30 days off.
Instances like this more heavily penalize scorers that are sensitive to outliers. If these outliers in poor performance are not a concern so long as you typically achieve a very accurate prediction, then select a scorer that is robust to outliers. You can see this reflected in the behavior of the scorers MSE and RMSE.
MSE |
RMSE |
|
|---|---|---|
Outlier |
0.99 |
2.64 |
No Outlier |
0.80 |
1.0 |
Calculating the RMSE and MSE on your error data, the RMSE is more than twice as large as the MSE because RMSE is sensitive to outliers. If you remove the one outlier record from your calculation, RMSE drops down significantly.
Performance Units
Different scorers show the performance of the Driverless AI experiment in different units. This section continues with the previous example where the target is to predict the number of days until an event. Some possible performance units are:
Same as target: The unit of the scorer is in days
ex: MAE = 5 means the model predictions are off by 5 days on average
Percent of target: The unit of the scorer is the percent of days
ex: MAPE = 10% means the model predictions are off by 10 percent on average
Square of target: The unit of the scorer is in days squared
ex: MSE = 25 means the model predictions are off by 5 days on average (square root of 25 = 5)
Comparison
Metric |
Units |
Sensitive to Outliers |
Tip |
|---|---|---|---|
R2 |
Scaled between 0 and 1 |
No |
Use when you want performance scaled between 0 and 1 |
MSE |
Square of target |
Yes |
|
RMSE |
Same as target |
Yes |
|
RMSLE |
Log of target |
Yes |
|
RMSPE |
Percent of target |
Yes |
Use when target values are across different scales |
MAE |
Same as target |
No |
|
MAPE |
Percent of target |
No |
Use when target values are across different scales |
SMAPE |
Percent of target divided by 2 |
No |
Use when target values are close to 0 |
Scorer Best Practices - Classification
When deciding which scorer to use in a classification problem, consider the following:
Do you want the scorer to evaluate the predicted probabilities or the classes that those probabilities can be converted to?
Is your data imbalanced?
Scorer Evaluates Probabilities or Classes
The final output of a Driverless AI model is a predicted probability that a record is in a particular class. The scorer you choose either evaluates how accurate the probability is or how accurate the assigned class is from that probability.
Choosing this depends on the use of the Driverless AI model. Do you want to use the probabilities, or do you want to convert those probabilities into classes? For example, if you are predicting whether a customer will churn, you may take the predicted probabilities and turn them into distinct classes—customers who will churn vs customers who will not churn. If you are predicting the expected loss of revenue, use the predicted probabilities instead (predicted probability of churn * value of customer).
If your use case requires a class assigned to each record, select a scorer that evaluates the model’s performance based on how well it classifies the records. If your use case uses the probabilities, select a scorer that evaluates the model’s performance based on the predicted probability.
Robust to Imbalanced Data
For certain use cases, positive classes may be very rare. In these instances, some scorers can be misleading. For example, if you have a use case where 99% of the records have Class = No, then a model that always predicts No will have 99% accuracy.
For these use cases, it is best to select a metric that does not include True Negatives or considers relative size of the True Negatives like AUCPR or MCC.
Comparison
Metric |
Evaluation Based On |
Tip |
|---|---|---|
MCC |
Class |
All classes are equally weighted |
F1 |
Class |
Equal weight on precision and recall |
F0.5 |
Class |
More weight on precision, less weight on recall |
F2 |
Class |
More weight on recall, less weight on precision |
Accuracy |
Class |
Highly interpretable |
Logloss |
Probability |
Optimizes probabilities |
AUC |
Class |
Optimizes sort order of predictions |
AUCPR |
Class |
Good for imbalanced data |