Adversarial similarity
Adversarial similarity refers to a validation test that assists in observing similar or dissimilar segments of two different datasets. Observing the feature distribution of two different datasets can indicate similarity or dissimilarity. An adversarial similarity test can be performed rather than going over all the features individually to observe the differences. During an adversarial similarity test, decision tree algorithms are leveraged to find similar or dissimilar rows between the train dataset and any dataset with the same train columns.
An adversarial similarity test sets Gradient Boosted Decision Trees (GBDT) on a dataset obtained by concatenating the train dataset with another dataset (often with similar train columns). In this concatenated dataset, a new target column is created where the rows of the train dataset and the other dataset are assigned 0s and 1s, respectively. For example, consider the following image, which concatenates the train dataset with the test dataset.
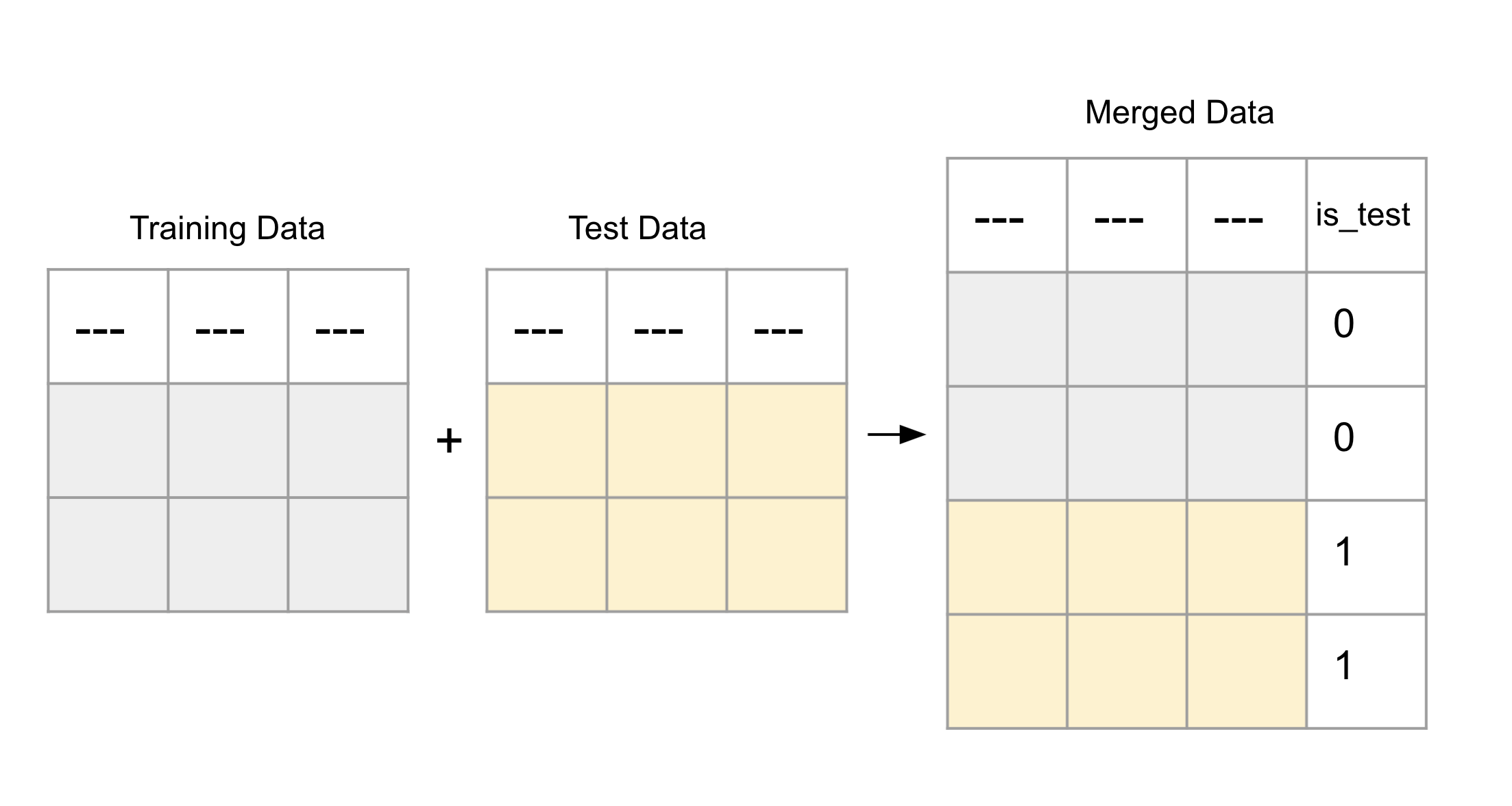
The test generates a predicted score for each row of the concatenated dataset. These scores can be used to further analyze the most different or similar rows of the dataset. The return scores refer to Area Under the Curve (AUC) values. The higher the score, the more dissimilar the row is to the train dataset.
- To learn how to create an adversarial similarity test, see Create an adversarial similarity test.
- See Settings: Adversarial similarity to learn about all the settings for an adversarial similarity validation test.
- See Metrics: Adversarial similarity to learn about all the metrics for an adversarial similarity validation test.
- Submit and view feedback for this page
- Send feedback about H2O Model Validation to cloud-feedback@h2o.ai