New Experiments
This page describes how to start a new experiment in Driverless AI.
Note
An experiment setup wizard that guides you through the process of setting up an experiment is also available. For more information, see H2O Driverless AI Experiment Setup Wizard.
Run an experiment by selecting [Click for Actions] button beside the training dataset that you want to use. Click Predict to begin an experiment. Alternatively, you can click the New Experiment -> Standard Setup button on the Experiments page, which prompts you to select a training dataset. (To go to the H2O Driverless AI Experiment Setup Wizard, click New Experiment -> Wizard Setup.) Clicking Standard Setup takes you directly to the dataset list page:
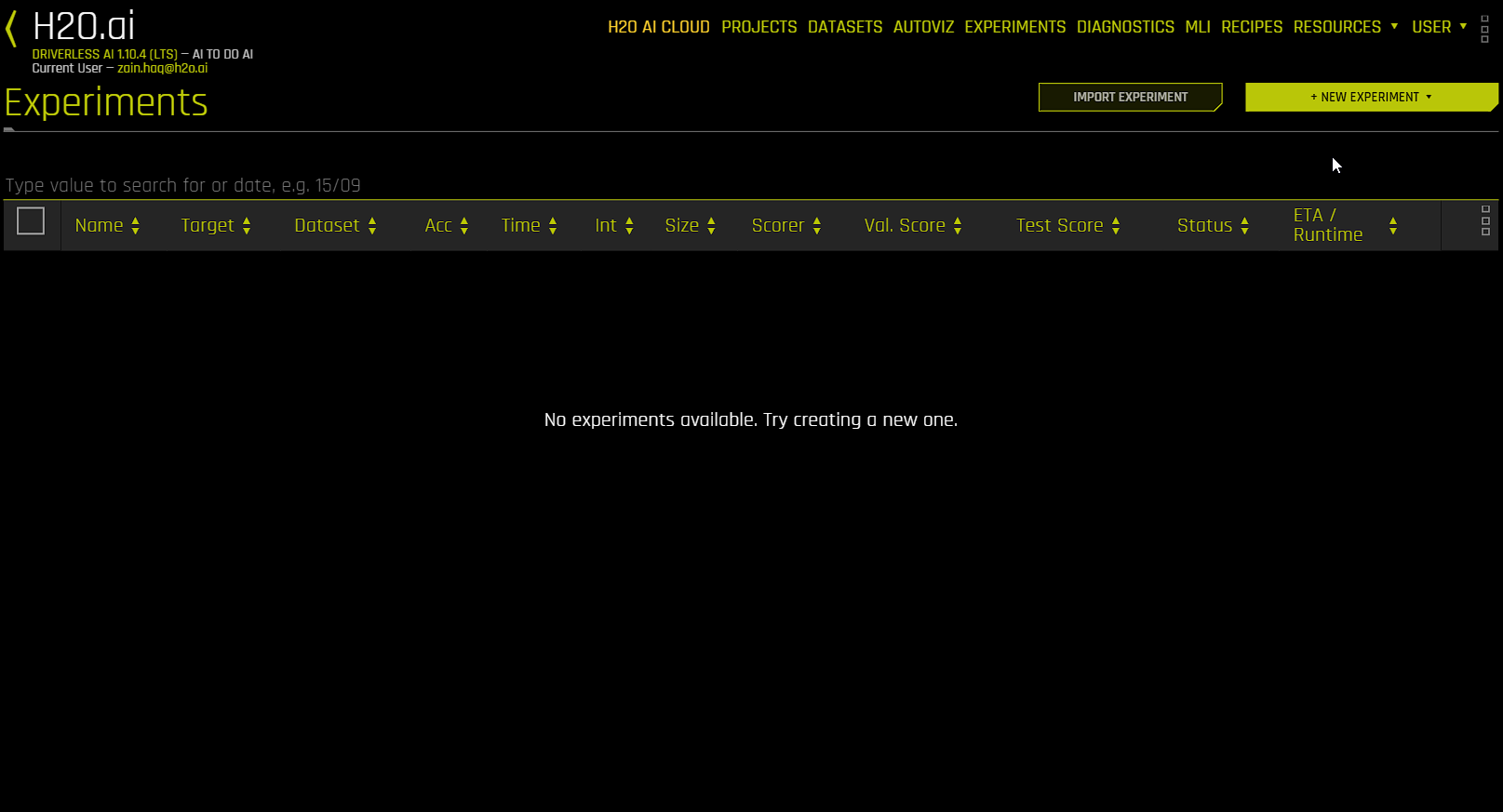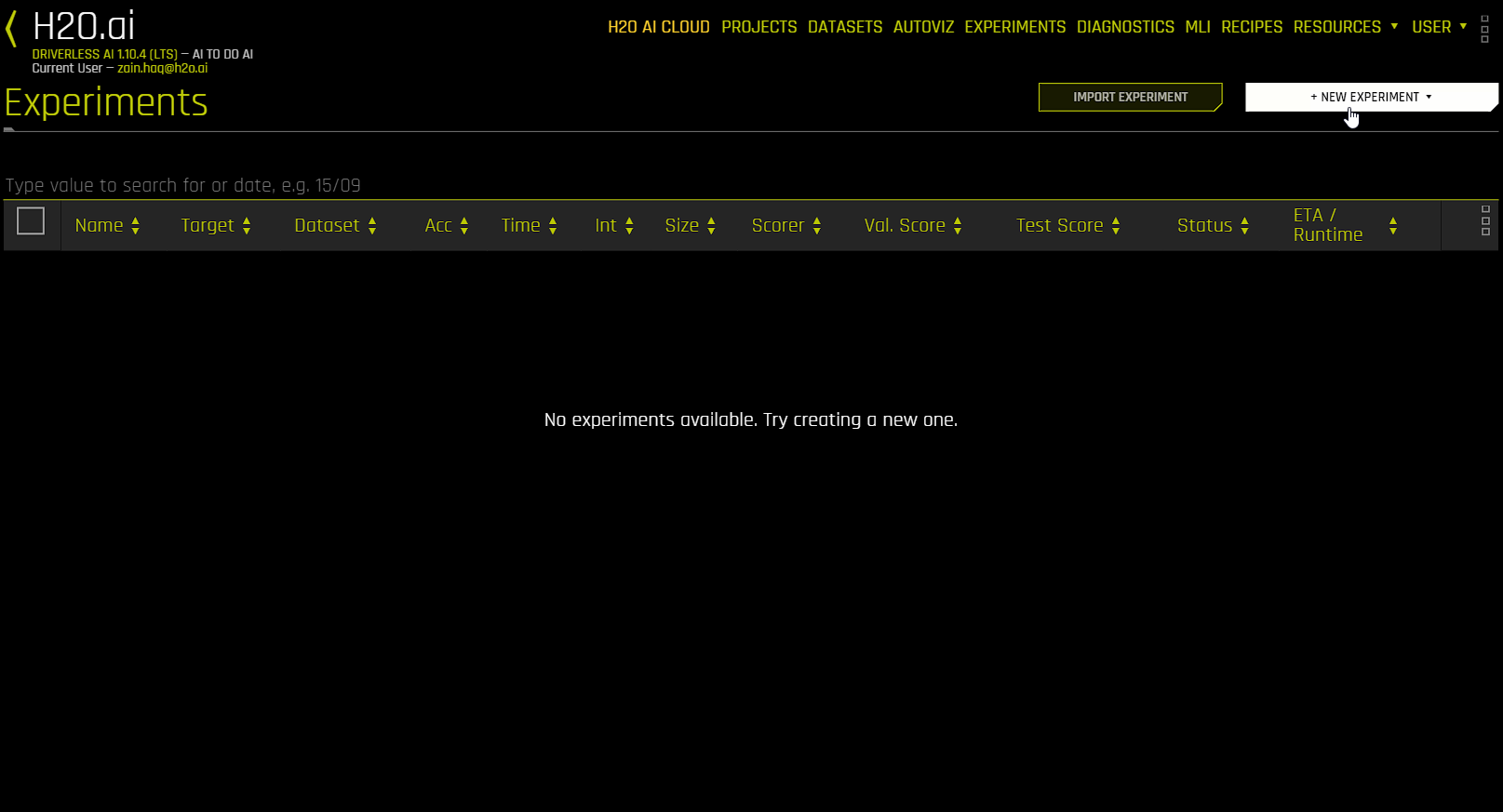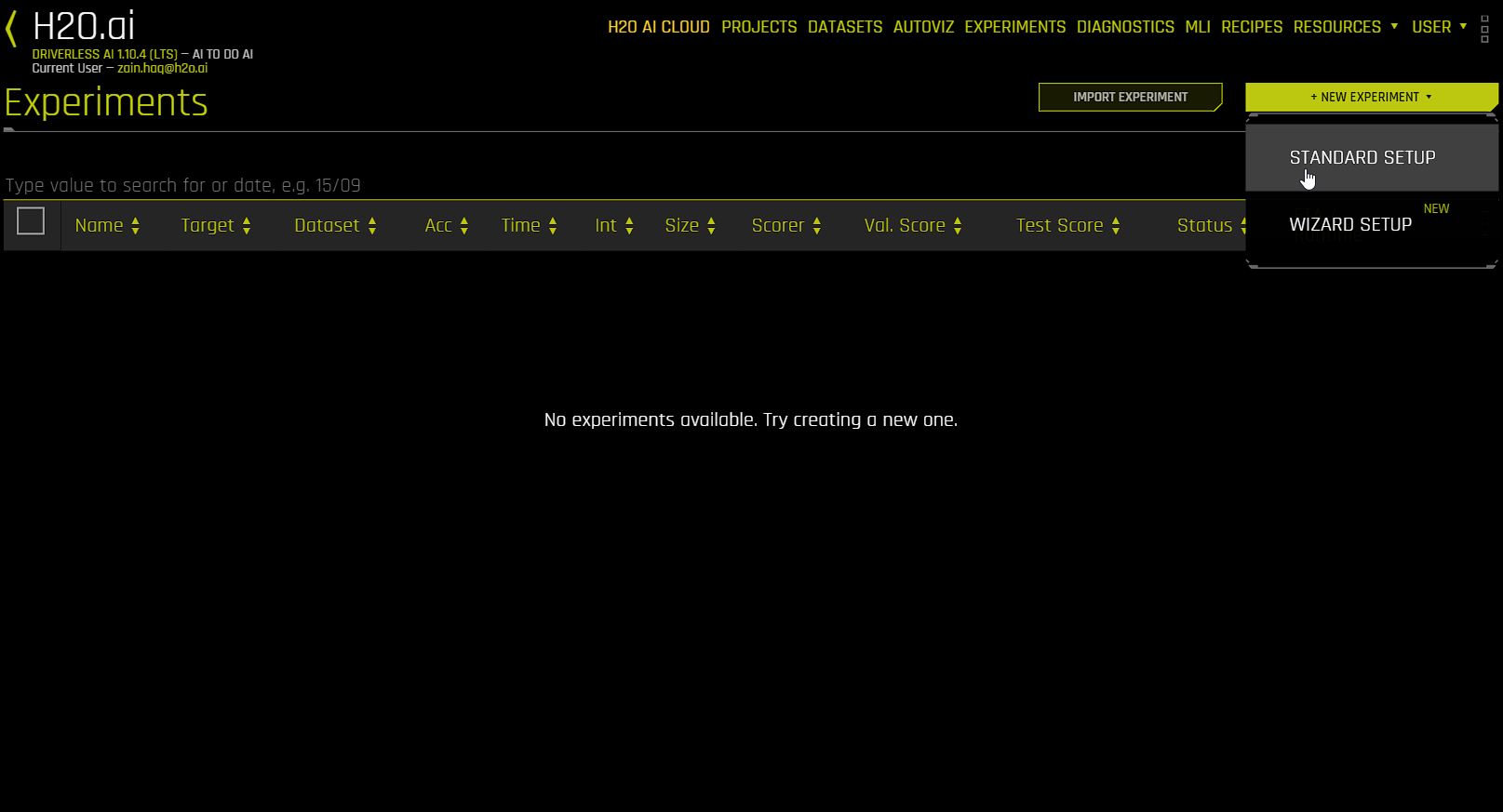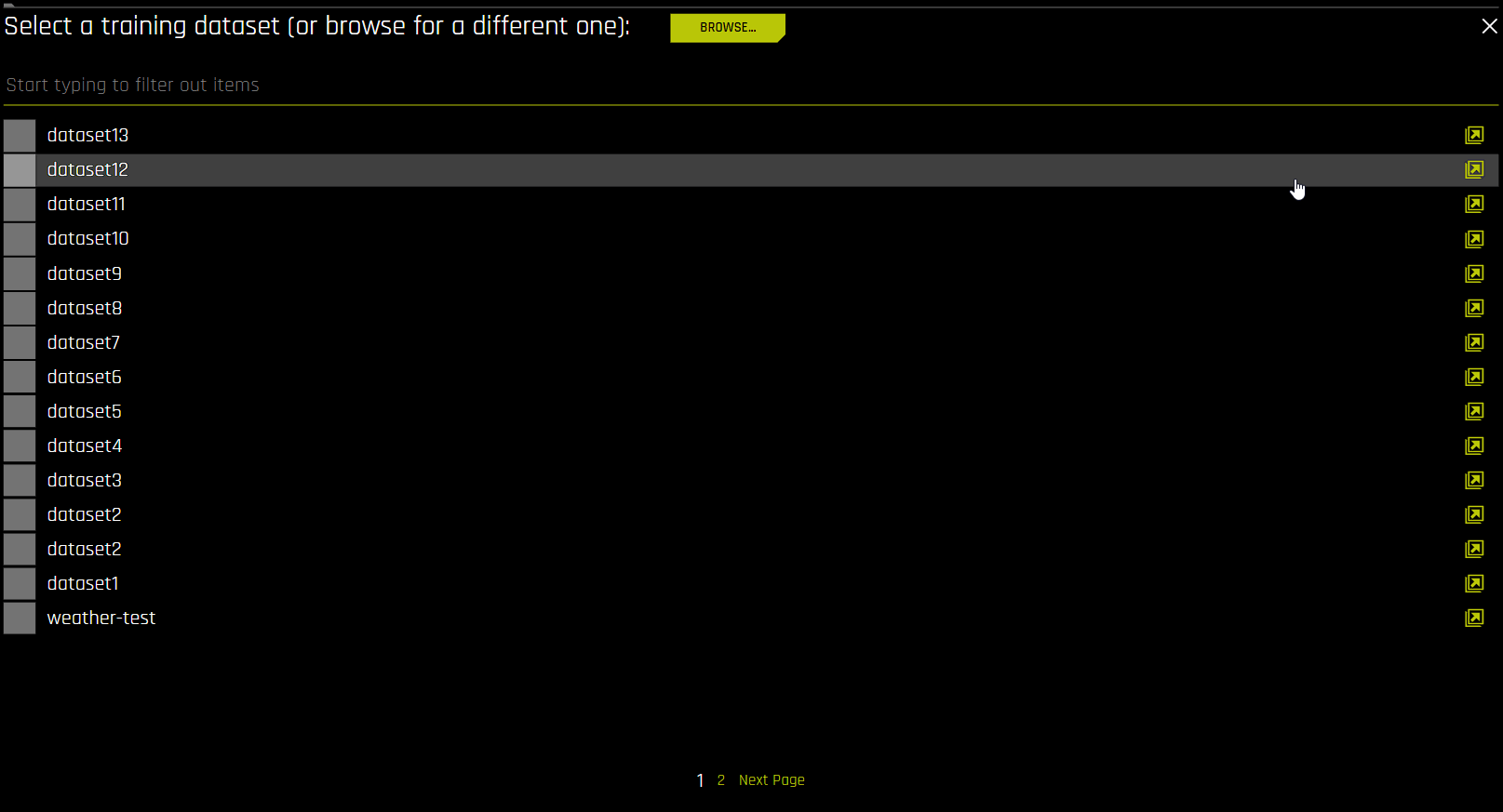
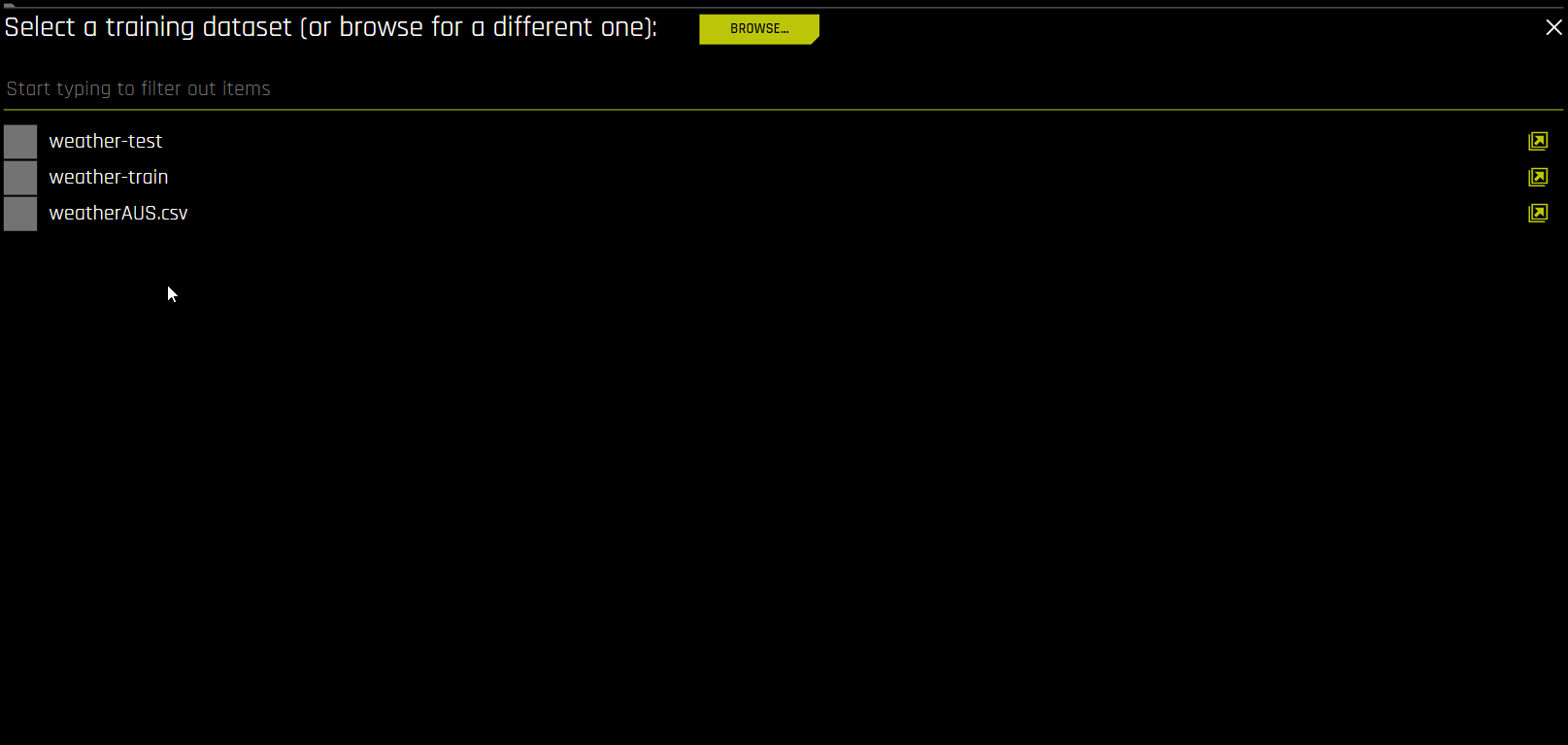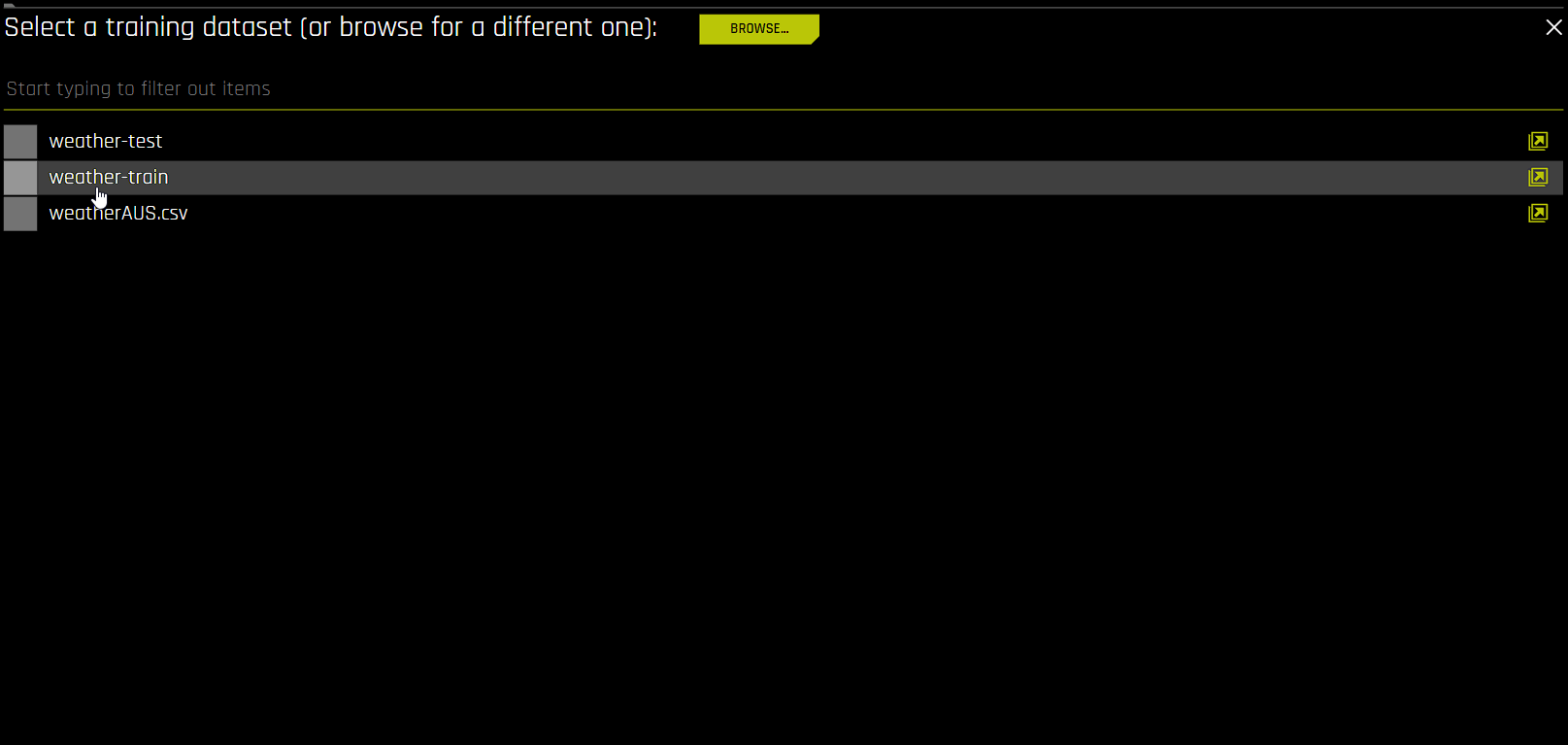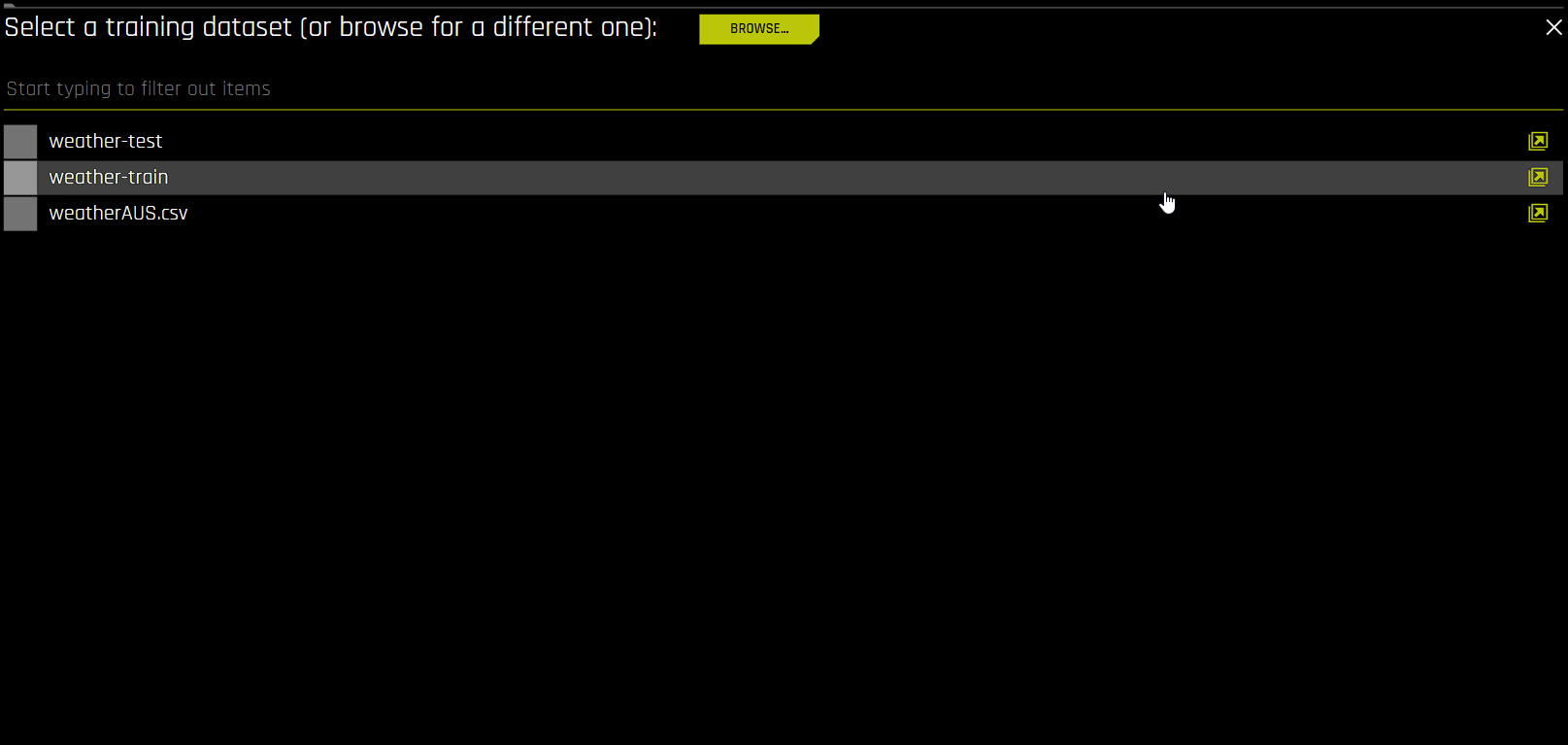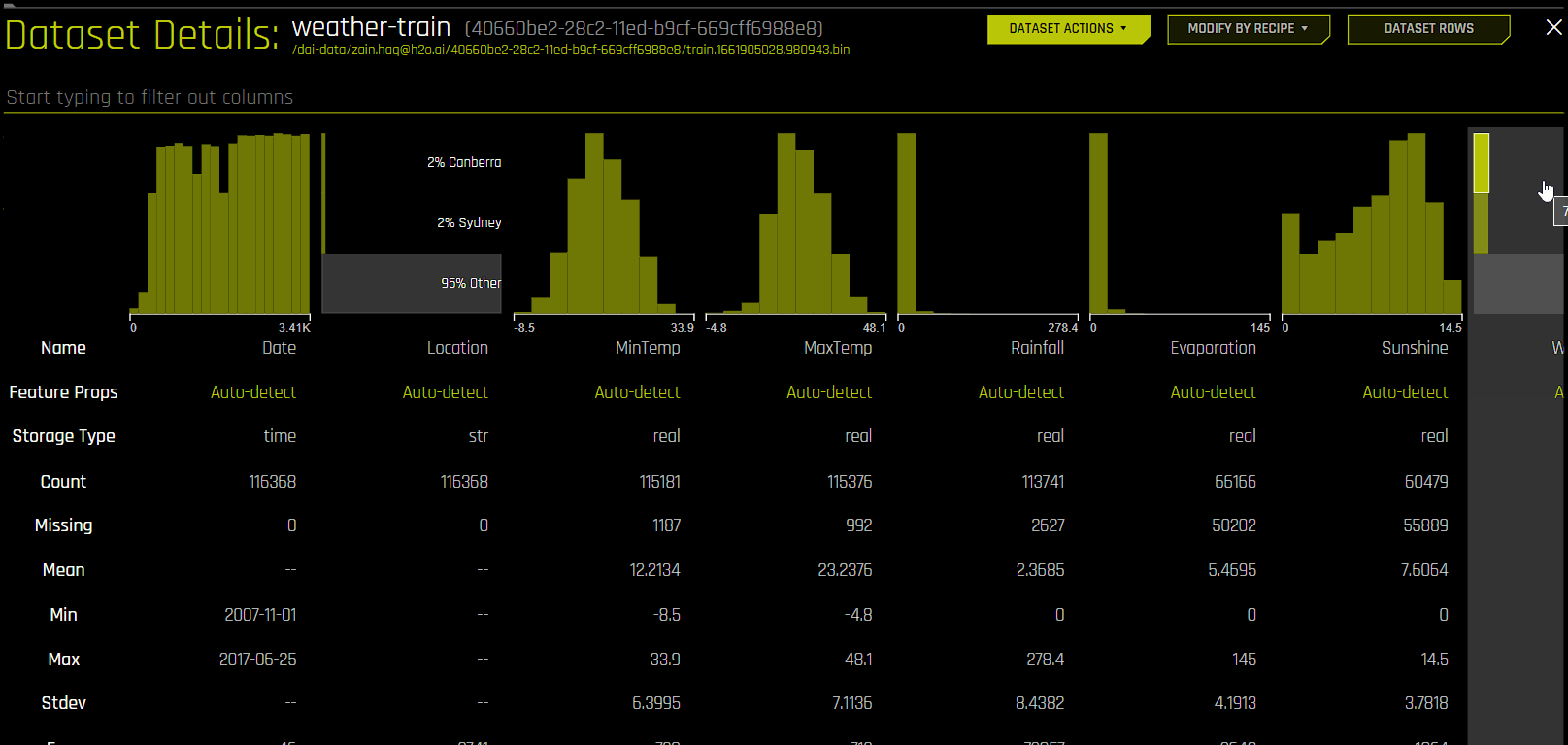
You can also get to the dataset list page from the Experiment Setup page by clicking Training Dataset, Test Dataset, or Validation Dataset. The dataset list page lets you view a list of datasets that are available for selection. You can also click the link icon next to a particular dataset to open the Dataset Details page for that dataset in a new browser tab.
Note that if your DAI instance has more than 15 datasets, the dataset list page is organized into pages, with each page listing up to 15 datasets.
The Experiment Settings form displays and auto-fills with the selected dataset. Optionally enter a custom name for this experiment. If you do not add a name, Driverless AI will create one for you.
Optionally specify a validation dataset and/or a test dataset.
The validation set is used to tune parameters (models, features, etc.). If a validation dataset is not provided, the training data is used (with holdout splits). If a validation dataset is provided, training data is not used for parameter tuning - only for training. A validation dataset can help to improve the generalization performance on shifting data distributions.
The test dataset is used for the final stage scoring and is the dataset for which model metrics will be computed against. Test set predictions will be available at the end of the experiment. This dataset is not used during training of the modeling pipeline.
Keep in mind that these datasets must have the same number of columns as the training dataset. Also note that if provided, the validation set is not sampled down, so it can lead to large memory usage, even if accuracy=1 (which reduces the train size).
Specify the target (response) column. Note that not all explanatory functionality will be available for multiclass classification scenarios (scenarios with more than two outcomes). When the target column is selected, Driverless AI automatically provides the target column type and the number of rows. If this is a classification problem, then the UI shows unique and frequency statistics (Target Freq/Most Freq) for numerical columns. If this is a regression problem, then the UI shows the dataset mean and standard deviation values.
Notes Regarding Frequency:
For data imported in versions <= 1.0.19, TARGET FREQ and MOST FREQ both represent the count of the least frequent class for numeric target columns and the count of the most frequent class for categorical target columns.
For data imported in versions 1.0.20-1.0.22, TARGET FREQ and MOST FREQ both represent the frequency of the target class (second class in lexicographic order) for binomial target columns; the count of the most frequent class for categorical multinomial target columns; and the count of the least frequent class for numeric multinomial target columns.
For data imported in version 1.0.23 (and later), TARGET FREQ is the frequency of the target class for binomial target columns, and MOST FREQ is the most frequent class for multinomial target columns.
The next step is to set the parameters and settings for the experiment. (Refer to the Experiment Settings section for more information about these settings.) You can set the parameters individually, or you can let Driverless AI infer the parameters and then override any that you disagree with. Available parameters and settings include the following:
Dropped Columns: The columns we do not want to use as predictors such as ID columns, columns with data leakage, etc.
Weight Column: The column that indicates the per row observation weights. If “None” is specified, each row will have an observation weight of 1.
Fold Column: The column that indicates the fold. If “None” is specified, the folds will be determined by Driverless AI. This is set to “Disabled” if a validation set is used.
Time Column: The column that provides a time order, if applicable. If “AUTO” is specified, Driverless AI will auto-detect a potential time order. If “OFF” is specified, auto-detection is disabled. This is set to “Disabled” if a validation set is used.
Specify the Scorer to use for this experiment. The available scorers vary based on whether this is a classification or regression experiment. Scorers include:
Regression: GINI, MAE, MAPE, MER, MSE, R2, RMSE (default), RMSLE, RMSPE, SMAPE, TOPDECILE
Classification: ACCURACY, AUC (default), AUCPR, F05, F1, F2, GINI, LOGLOSS, MACROAUC, MCC
Specify a desired relative Accuracy from 1 to 10
Specify a desired relative Time from 1 to 10
Specify a desired relative Interpretability from 1 to 10
Driverless AI will automatically infer the best settings for Accuracy, Time, and Interpretability and provide you with an experiment preview based on those suggestions. If you adjust these knobs, the experiment preview will automatically update based on the new settings.
Expert Settings (optional):
Optionally specify additional expert settings for the experiment. Refer to the Expert Settings section for more information about these settings. The default values for these options are derived from the environment variables in the config.toml file. Refer to the Setting Environment Variables section for more information.
Additional settings (optional):
Classification or Regression button. Driverless AI automatically determines the problem type based on the response column. Though not recommended, you can override this setting by clicking this button.
Reproducible: This button lets you build an experiment with a random seed and get reproducible results. If this is disabled (default), then results will vary between runs.
Enable GPUs: Specify whether to enable GPUs. (Note that this option is ignored on CPU-only systems.)
After your settings are made, review the Experiment Preview to learn what each of the settings means. Note: When changing the algorithms used via Expert Settings, you may notice that those changes are not applied. Driverless AI determines whether to include models and/or recipes based on a hierarchy of those expert settings. Refer to the Why do my selected algorithms not show up in the Experiment Preview? FAQ for more information.
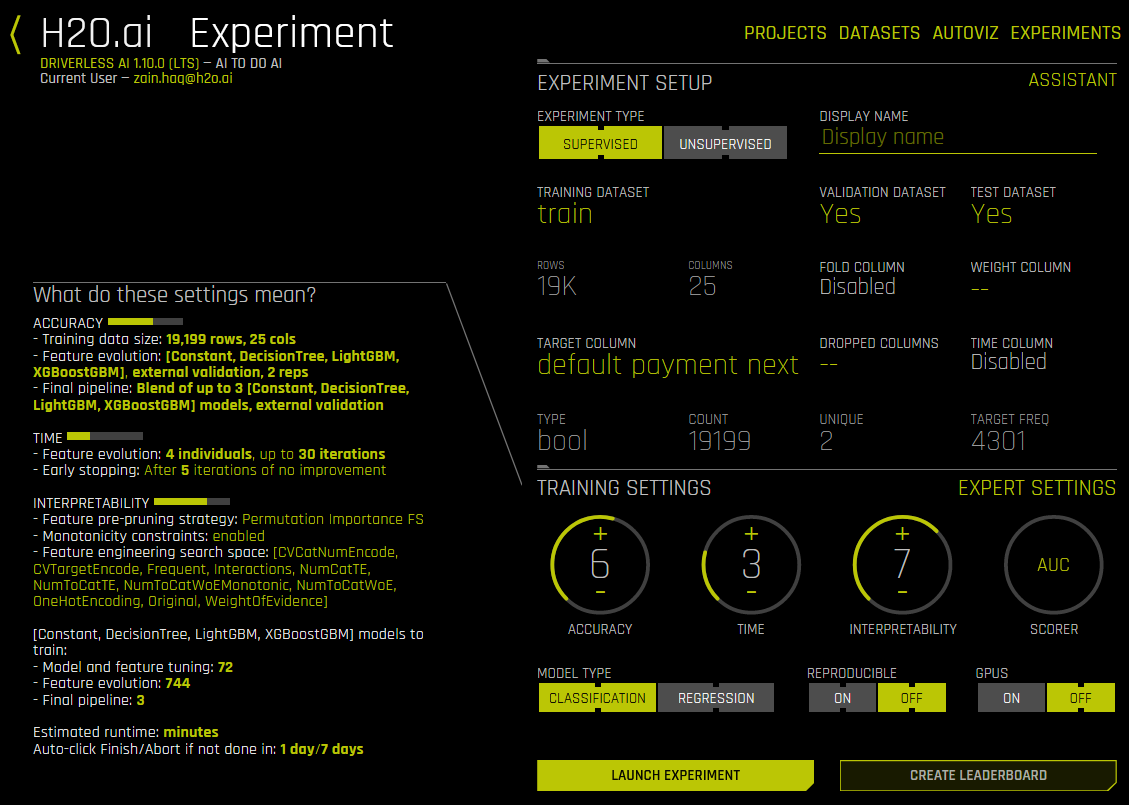
Click Launch Experiment to start the experiment.
The experiment launches with a randomly generated experiment name. You can change this name at anytime during or after the experiment. Mouse over the name of the experiment to view an edit icon, then type in the desired name.
As the experiment runs, a running status displays in the upper middle portion of the UI. First Driverless AI figures out the backend and determines whether GPUs are running. Then it starts parameter tuning, followed by feature engineering. Finally, Driverless AI builds the scoring pipeline.
Understanding the Experiment Page
In addition to the status, as an experiment is running, the UI also displays the following:
Details about the dataset.
The iteration data (internal validation) for each cross validation fold along with the specified scorer value. Click on a specific iteration or drag to view a range of iterations. Double click in the graph to reset the view. In this graph, each “column” represents one iteration of the experiment. During the iteration, Driverless AI will train \(n\) models. (This is called individuals in the experiment preview.) So for any column, you may see the score value for those \(n\) models for each iteration on the graph.
The variable importance values. To view variable importance for a specific iteration, just select that iteration in the Iteration Data graph. The Variable Importance list will automatically update to show variable importance information for that iteration. Hover over an entry to view more info.
Notes:
Transformed feature names are encoded as follows:
<transformation/gene_details_id>_<transformation_name>:<orig>:<…>:<orig>.<extra>
So in
32_NumToCatTE:BILL_AMT1:EDUCATION:MARRIAGE:SEX.0, for example:
32_is the transformation index for specific transformation parameters.
NumToCatTEis the transformation type.
BILL_AMT1:EDUCATION:MARRIAGE:SEXrepresent original features used.
0represents the likelihood encoding for target[0] after grouping by features (shown here asBILL_AMT1,EDUCATION,MARRIAGEandSEX) and making out-of-fold estimates. For multiclass experiments, this value is > 0. For binary experiments, this value is always 0.
When hovering over an entry, you may notice the term “Internal[…] specification.” This label is used for features that do not need to be translated/explained and ensures that all features are uniquely identified.
The values that display are specific to the variable importance of the model class:
XGBoost and LightGBM: Gains Variable importance. Gain-based importance is calculated from the gains a specific variable brings to the model. In the case of a decision tree, the gain-based importance will sum up the gains that occurred whenever the data was split by the given variable. The gain-based importance is normalized between 0 and 1. If a variable is never used in the model, the gain-based importance will be 0.
GLM: The variable importance is the absolute value of the coefficient for each predictor. The variable importance is normalized between 0 and 1. If a variable is never used in the model, the importance will be 0.
TensorFlow: TensorFlow follows the Gedeon method described in this paper: https://www.ncbi.nlm.nih.gov/pubmed/9327276.
RuleFit: Sums over a feature’s contribution to each rule. Specifically, Driverless AI:
Assigns all features to have zero importance.
Scans through all the rules. If a feature is in that rule, Driverless AI adds its contribution (i.e, the absolute values of a rule’s coefficient ) to its overall feature importance.
Normalizes the importance.
The calculation for the shift of variable importance is determined by the ensemble level:
Ensemble Level = 0: The shift is determined between the last best genetic algorithm (GA) and the single final model.
Ensemble Level >=1: GA individuals used for the final model have variable importance blended with the model’s meta learner weights, and the final model itself has variable importance blended with its final weights. The shift of variable importance is determined between these two final variable importance blends.
This information is reported in the logs or in the GUI if the shift is beyond the absolute magnitude specified by the
max_num_varimp_shift_to_logconfiguration option. The Experiment Summary also includes experiment_features_shift files that contain information about shift.
CPU/Memory information along with Insights (for time-series experiments), Scores, Notifications, Logs, and Trace info. (Note that Trace is used for development/debugging and to show what the system is doing at that moment.)
For classification problems, the lower right section includes a toggle between an ROC curve, Precision-Recall graph, Lift chart, Gains chart, and GPU Usage information (if GPUs are available). For regression problems, the lower right section includes a toggle between a Residuals chart, an Actual vs. Predicted chart, and GPU Usage information (if GPUs are available). (Refer to the Experiment Graphs section for more information.) Upon completion, an Experiment Summary section will populate in the lower right section.
The bottom portion of the experiment screen will show any warnings that Driverless AI encounters. You can hide this pane by clicking the x icon.
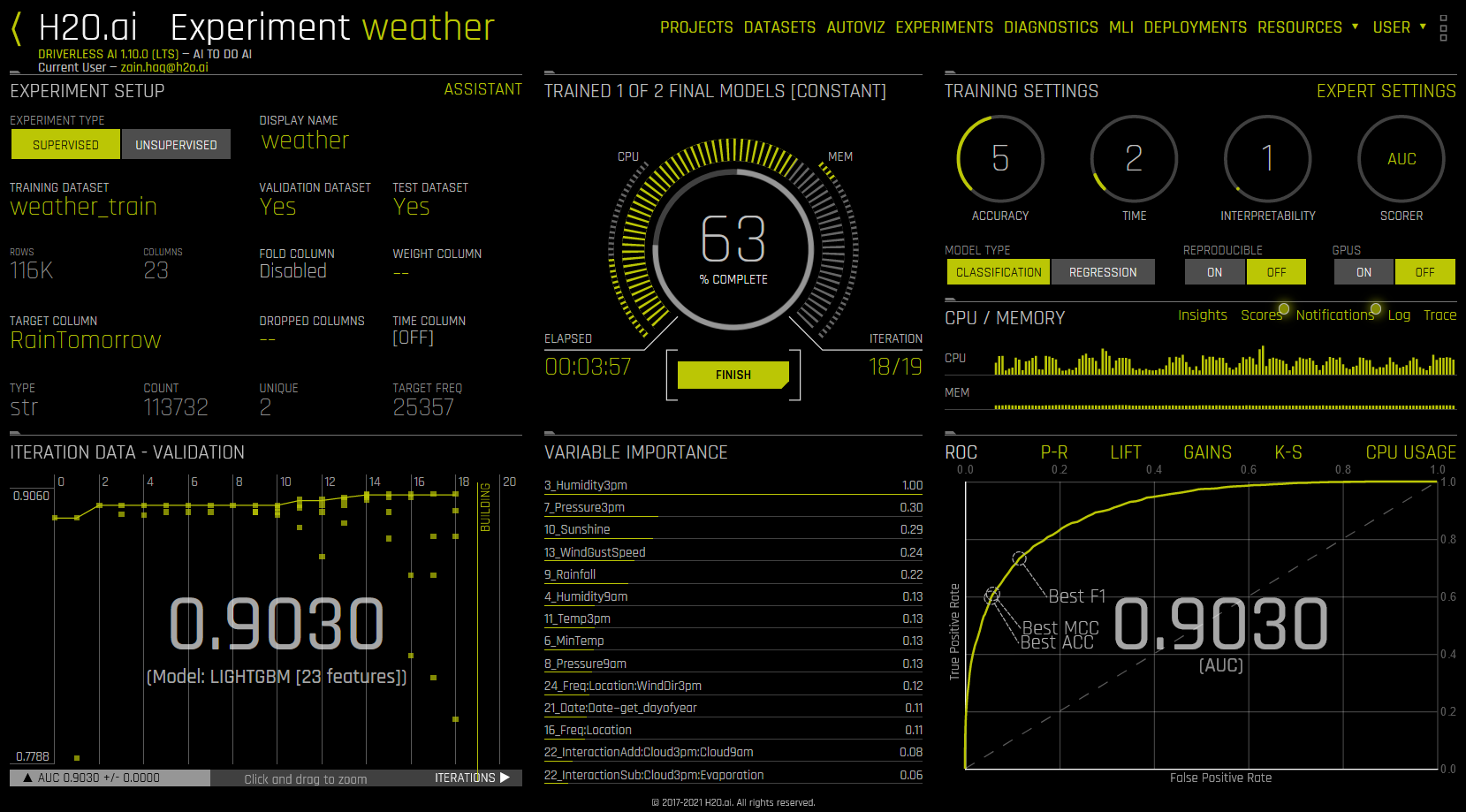
Finishing/Aborting Experiments
You can finish and/or abort experiments that are currently running.
Finish Click the Finish button to stop a running experiment. Driverless AI will end the experiment and then complete the ensembling and the deployment package.
Abort: After clicking Finish, you have the option to click Abort, which terminates the experiment. (You are prompted to confirm the abort.) The status of aborted experiments is displayed on the Experiments page as “Aborted by user”. You can restart aborted experiments by clicking the right side of the experiment, then selecting Restart from Last Checkpoint. This will start a new experiment based on the aborted one. Alternatively, you can started a new experiment based on the aborted one by selecting New / Continue > With Same Settings. For more information, refer to Checkpointing, Rerunning, and Retraining.
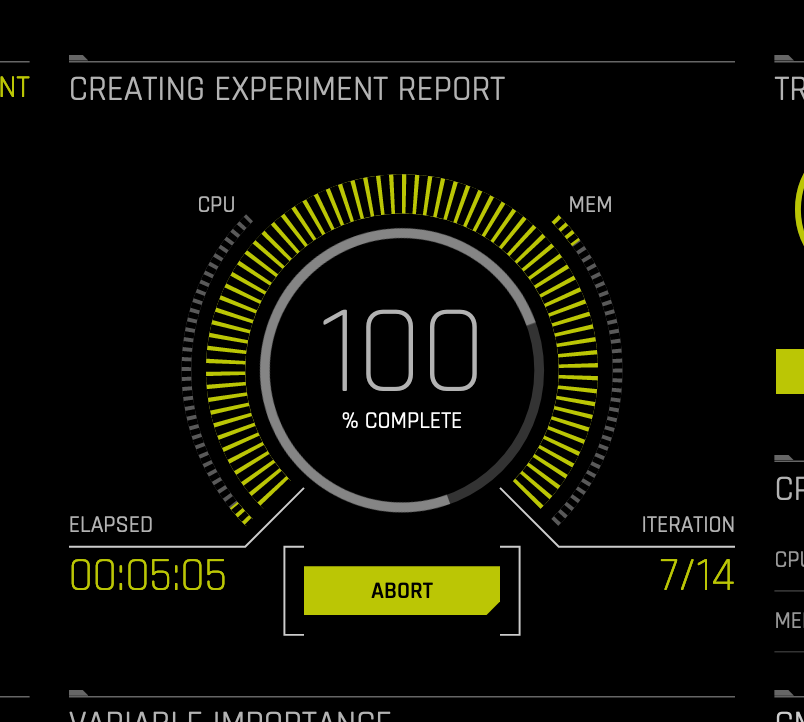
Aborting Experiment Report
The final step that Driverless AI performs during an experiment is to complete the experiment report. During this step, you can click Abort to skip this report.
“Pausing” an Experiment
A trick for “pausing” an experiment is to:
Abort the experiment.
On the Experiments page, select Restart from Last Checkpoint for the aborted experiment.
On the Expert Settings page, specify 0 for the Ensemble level for final modeling pipeline option in the new experiment’s Expert Settings.